23 from Image to Translation: Processing the Endangered Nyushu Script
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Verb-Stem Variations in Showu Rgyalrong*
Studies on Sino-Tibetan Languages, 269-296 2004-8-004-001-000004-2 Verb-Stem Variations in Showu rGyalrong* Jackson T.-S. Sun Academia Sinica The richest verbal system among the rGyalrongic cluster of languages in Tibeto-Burman is found in the Showu dialect of rGyalrong. Drawing on first-hand field data, this paper provides an account of the elaborate morphological patterns in Showu verb-stem formation. Unlike many other rGyalrongic members, Showu possesses non-alternating verbs with invariant stems throughout the paradigm. On the other hand, a good number of basic verbs distinguish a second (or past) stem while many transitive verbs show an additional third (or nonpast singular transitive) stem. Both vocalic, consonantal, and suprasegmental modifications play a role in the formation of the second and third stems. After treating Showu stem variations and their functional distribution, a comparison is made with the more innovative stem-alternating patterns in the Caodeng and Dazang dialects of rGyalrong. Key words: Tibeto-Burman, rGyalrongic, verbal morphology, stem formation 1. Introduction In opening my contribution to this volume in honor of Professor Gong Hwang- cherng’s eminent accomplishments in Sino-Tibetan linguistics, I would like to gratefully acknowledge my intellectual debt to Professor Gong’s influence on my research on Tibeto-Burman languages over the years. Particularly inspiring for me has been his important discovery of a system of vocalic alternations in Tangut which functions to form derived verb stems utilized to index a singular speech-act participant * This research was funded by the National Science Council (ROC) grants 89-2411-H-001-005 and 89-2411-H-001-088. -

The Neolithic Ofsouthern China-Origin, Development, and Dispersal
The Neolithic ofSouthern China-Origin, Development, and Dispersal ZHANG CHI AND HSIAO-CHUN HUNG INTRODUCTION SANDWICHED BETWEEN THE YELLOW RIVER and Mainland Southeast Asia, southern China1 lies centrally within eastern Asia. This geographical area can be divided into three geomorphological terrains: the middle and lower Yangtze allu vial plain, the Lingnan (southern Nanling Mountains)-Fujian region,2 and the Yungui Plateau3 (Fig. 1). During the past 30 years, abundant archaeological dis coveries have stimulated a rethinking of the role ofsouthern China in the prehis tory of China and Southeast Asia. This article aims to outline briefly the Neolithic cultural developments in the middle and lower Yangtze alluvial plain, to discuss cultural influences over adjacent regions and, most importantly, to examine the issue of southward population dispersal during this time period. First, we give an overview of some significant prehistoric discoveries in south ern China. With the discovery of Hemudu in the mid-1970s as the divide, the history of archaeology in this region can be divided into two phases. The first phase (c. 1920s-1970s) involved extensive discovery, when archaeologists un earthed Pleistocene human remains at Yuanmou, Ziyang, Liujiang, Maba, and Changyang, and Palaeolithic industries in many caves. The major Neolithic cul tures, including Daxi, Qujialing, Shijiahe, Majiabang, Songze, Liangzhu, and Beiyinyangying in the middle and lower Yangtze, and several shell midden sites in Lingnan, were also discovered in this phase. During the systematic research phase (1970s to the present), ongoing major ex cavation at many sites contributed significantly to our understanding of prehis toric southern China. Additional early human remains at Wushan, Jianshi, Yun xian, Nanjing, and Hexian were recovered together with Palaeolithic assemblages from Yuanmou, the Baise basin, Jianshi Longgu cave, Hanzhong, the Li and Yuan valleys, Dadong and Jigongshan. -

Languages of Southeast Asia
Jiarong Horpa Zhaba Amdo Tibetan Guiqiong Queyu Horpa Wu Chinese Central Tibetan Khams Tibetan Muya Huizhou Chinese Eastern Xiangxi Miao Yidu LuobaLanguages of Southeast Asia Northern Tujia Bogaer Luoba Ersu Yidu Luoba Tibetan Mandarin Chinese Digaro-Mishmi Northern Pumi Yidu LuobaDarang Deng Namuyi Bogaer Luoba Geman Deng Shixing Hmong Njua Eastern Xiangxi Miao Tibetan Idu-Mishmi Idu-Mishmi Nuosu Tibetan Tshangla Hmong Njua Miju-Mishmi Drung Tawan Monba Wunai Bunu Adi Khamti Southern Pumi Large Flowery Miao Dzongkha Kurtokha Dzalakha Phake Wunai Bunu Ta w an g M o np a Gelao Wunai Bunu Gan Chinese Bumthangkha Lama Nung Wusa Nasu Wunai Bunu Norra Wusa Nasu Xiang Chinese Chug Nung Wunai Bunu Chocangacakha Dakpakha Khamti Min Bei Chinese Nupbikha Lish Kachari Ta se N a ga Naxi Hmong Njua Brokpake Nisi Khamti Nung Large Flowery Miao Nyenkha Chalikha Sartang Lisu Nung Lisu Southern Pumi Kalaktang Monpa Apatani Khamti Ta se N a ga Wusa Nasu Adap Tshangla Nocte Naga Ayi Nung Khengkha Rawang Gongduk Tshangla Sherdukpen Nocte Naga Lisu Large Flowery Miao Northern Dong Khamti Lipo Wusa NasuWhite Miao Nepali Nepali Lhao Vo Deori Luopohe Miao Ge Southern Pumi White Miao Nepali Konyak Naga Nusu Gelao GelaoNorthern Guiyang MiaoLuopohe Miao Bodo Kachari White Miao Khamti Lipo Lipo Northern Qiandong Miao White Miao Gelao Hmong Njua Eastern Qiandong Miao Phom Naga Khamti Zauzou Lipo Large Flowery Miao Ge Northern Rengma Naga Chang Naga Wusa Nasu Wunai Bunu Assamese Southern Guiyang Miao Southern Rengma Naga Khamti Ta i N u a Wusa Nasu Northern Huishui -

Supplementary Materials
Supplementary Materials: Linsheng Zhong 1, 2 and Dongjun Chen 1, 2, * 1 Institute of Geographic Sciences and Natural Resources Research, Chinese Academy of Sciences, Beijing 100101, China 2 College of Resources and Environment, University of Chinese Academy of Sciences, Beijing 100049, China * Correspondence: [email protected] 272 Individual Relevant Core Articles 1. Bai Qinfeng, Huo Zhiguo, He Nan, et al. Analysis of human body comfort index of 20 tourist cities in China. J. Chinese Journal of Ecology. 2009, 28(8): 173–178. 2. Bao Jigang, Deng Lizi. Impact of climate on vacation–oriented second home demand: a comparative study of Tengchong and Xishuangbanna. J. Tropical Geography. 2018, 38(5): 606–616. 3. Cai Bifan, Meng Minghao, Chen Guisong. Construction of the performance evaluation system for rural tourism region and its application. J. Tourism Forum. 2009, 2(5): 81–88. 4. Cai Meng, Ge Linsi, Ding Yue. Research progress on countermeasures for tourism emission reduction in overseas. J. Ecological Economy. 2014, 30(10): 28–33. 5. Cao Hui, Zhang Xiaoping, Chen Pingliu. The appraising of tourism climate resource in Fuzhou National Forest Park. J. Issues of Forestry Economics. 2007, (1): 36–39. 6. Cao Kaijun, Yang Zhaoping, Meng Xianyong, et al. An evaluation of tourism climatic suitability in Altay Prefecture. J. Journal of Glaciology and Geocryology. 2015, 37(5): 1420–1427. 7. Cao Weihong, He Yuanqing, Li Zongsheng, et al. A correlation analysis between climatic comfort degree and monthly variation of tourists in Lijiang. J. Scientia Geographica Sinica. 2012, 32(12): 1459– 1464. 8. Cao Weihong, He Yuanqing, Li Zongsheng, et al. -

Origins of Vowel Pharyngealization in Hongyan Qiang*
Linguistics of the Tibeto-Burman Area Volume 29.2 — October 2006 ORIGINS OF VOWEL PHARYNGEALIZATION IN HONGYAN QIANG* Jonathan Evans Institute of Linguistics, Academia Sinica Hongyan, a variety of Northern Qiang (Tibeto-Burman, China) has four plain vowel monophthongs /i, u, ə, a/. Vowels may be lengthened, rhotacized, or pharyngealized, resulting in fourteen short and ten long vowel phonemes. No other varieties of Qiang have been described with pharyngealization, although the other suprasegmental effects are common throughout Northern Qiang. This paper explores how the distinctions which in Hongyan are made by differences in pharyngealization are phonologized in other varieties of Northern and Southern Qiang. Comparisons are drawn with processes in other Qiangic languages and with Proto-Tibeto- Burman reconstructions, in order to explore possible routes of development of pharyngealization; the most plausible source of pharyngealization seen thus far is retraction of vowels following PTB *-w-. Keywords: Qiang, pharyngealization, brightening, Tibeto-Burman. * Special thanks to the suggestions and help of David Bradley, Zev Handel, Randy LaPolla, James Matisoff, John Ohala, and Jackson Sun. They do not necessarily agree with all of the conclusions drawn herein. Thanks to Chenglong Huang, linguist and native Qiang speaker, for providing Ronghong Yadu data, analysis, and discussion. This research was supported by my home institution, and by a grant from the National Science Council of Taiwan (94-2411-H-001-071). 95 96 Jonathan Evans 1. INTRODUCTION TO HONGYAN Qiang (羌) is a Tibeto-Burman language spoken in the Aba Tibetan and Qiang Autonomous Prefecture (啊壩藏族羌藏族自治州) of Sichuan Province, China. It has been divided into two major dialects, Northern (NQ) and Southern (SQ) by H. -

Education: Still Searching for Utopia?; the UNESCO Courier; Vol.:1; 2018
THE UNESCO CourierJanuary-March 2018 Education: Still searching for Utopia? United Nations Educational, Scientific and Cultural Organization Our contributors John H. Matthews Anna Creed Jean-Paul Agon Cathy Nolan Brendan O’Malley Robert Badinter United States Alan Tormaid Campbell France United Kingdom Toril Rokseth Norway Marco Dormino Italy Dalia Al-Najjar Palestine Zeinab Badawi United Kingdom, Sudan Lily Dai China Kailash Satyarthi India Jean Winand Tawakkol Karman Belgium Yemen Fernando M. Reimers Luc Ngwé Ada Yonath Venezuela Cameroon Israel @ Alvaro Cabrera Jimenez / Shutterstock 2018 • n° 1 • Published since 1948 Language Editors: Information and reproduction rights: Arabic: Anissa Barrak [email protected] The UNESCO Courier is published quarterly Chinese: Sun Min and China Translation and 7, place de Fontenoy, 75352 Paris 07 SP, France by the United Nations Educational, Scientific Publishing House © UNESCO 2018 and Cultural Organization. It promotes the English: Shiraz Sidhva ISSN 2220-2285 • e-ISSN 2220-2293 ideals of UNESCO by sharing ideas on issues of French: Régis Meyran international concern relevant to its mandate. Russian: Marina Yaloyan The UNESCO Courier is published thanks to the Spanish: Lucía Iglesias Kuntz Periodical available in Open Access under the generous support of the People’s Republic of China. Translation (English): Peter Coles, Cathy Nolan, Attribution-ShareAlike 3.0 IGO (CC-BY-SA 3.0 IGO) licence Director of Publication: Éric Falt Olivia Fuller (http://creativecommons.org/licenses/by-sa/3.0/ igo/). Executive Director: Vincent Defourny Design: Corinne Hayworth By using the content of this publication, the users accept Editorial Director: Jasmina Šopova Cover image : © Eva Vázquez to be bound by the terms of use of the UNESCO Open Access Repository (www.unesco. -

Reconsidering the Diachrony of Tone in Rma1
Journal of the Southeast Asian Linguistics Society JSEALS Vol. 13.1 (2020): 53-85 ISSN: 1836-6821, DOI: http://hdl.handle.net/10524/52460 University of Hawaiʼi Press RECONSIDERING THE DIACHRONY OF TONE IN RMA1 Nathaniel A. Sims University of California Santa Barbara [email protected] Abstract Prior work has suggested that proto-Rma was a non-tonal language and that tonal varieties underwent tonogenesis (Liú 1998, Evans 2001a-b). This paper re-examines the different arguments for the tonogenesis hypothesis and puts forward subgroup-internal and subgroup- external evidence for an alternative scenario in which tone, or its phonetic precursors, was present at the stage of proto-Rma. The subgroup-internal evidence comes from regular correspondences between tonal varieties. These data allow us to put forward a working hypothesis that proto-Rma had a two-way tonal contrast. Furthermore, existing accounts of how tonogenesis occurred in the tonal varieties are shown to be problematic. The subgroup-external evidence comes from regular tonal correspondences to two closely related tonal Trans- Himalayan subgroups: Prinmi, a modern language, and Tangut, a mediaeval language attested by written records from the 11th to 16th centuries. Regular correspondences among the tonal categories of these three subgroups, combined with the Rma-internal evidence, allow us to more confidently reconstruct tone for proto-Rma. Keywords: Tonogenesis, Trans-Himalayan (Sino-Tibetan), Rma, Prinmi, Tangut, Historical linguistics ISO 639-3 codes: qxs, pmi, pmj, txg 1. Introduction This paper addresses the diachrony of tone in Rma,2 a group of northeastern Trans-Himalayan3 language varieties spoken in 四川 Sìchuān, China. -
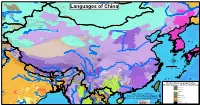
Map by Steve Huffman Data from World Language Mapping System 16
Mandarin Chinese Evenki Oroqen Tuva China Buriat Russian Southern Altai Oroqen Mongolia Buriat Oroqen Russian Evenki Russian Evenki Mongolia Buriat Kalmyk-Oirat Oroqen Kazakh China Buriat Kazakh Evenki Daur Oroqen Tuva Nanai Khakas Evenki Tuva Tuva Nanai Languages of China Mongolia Buriat Tuva Manchu Tuva Daur Nanai Russian Kazakh Kalmyk-Oirat Russian Kalmyk-Oirat Halh Mongolian Manchu Salar Korean Ta tar Kazakh Kalmyk-Oirat Northern UzbekTuva Russian Ta tar Uyghur SalarNorthern Uzbek Ta tar Northern Uzbek Northern Uzbek RussianTa tar Korean Manchu Xibe Northern Uzbek Uyghur Xibe Uyghur Uyghur Peripheral Mongolian Manchu Dungan Dungan Dungan Dungan Peripheral Mongolian Dungan Kalmyk-Oirat Manchu Russian Manchu Manchu Kyrgyz Manchu Manchu Manchu Northern Uzbek Manchu Manchu Manchu Manchu Manchu Korean Kyrgyz Northern Uzbek West Yugur Peripheral Mongolian Ainu Sarikoli West Yugur Manchu Ainu Jinyu Chinese East Yugur Ainu Kyrgyz Ta jik i Sarikoli East Yugur Sarikoli Sarikoli Northern Uzbek Wakhi Wakhi Kalmyk-Oirat Wakhi Kyrgyz Kalmyk-Oirat Wakhi Kyrgyz Ainu Tu Wakhi Wakhi Khowar Tu Wakhi Uyghur Korean Khowar Domaaki Khowar Tu Bonan Bonan Salar Dongxiang Shina Chilisso Kohistani Shina Balti Ladakhi Japanese Northern Pashto Shina Purik Shina Brokskat Amdo Tibetan Northern Hindko Kashmiri Purik Choni Ladakhi Changthang Gujari Kashmiri Pahari-Potwari Gujari Japanese Bhadrawahi Zangskari Kashmiri Baima Ladakhi Pangwali Mandarin Chinese Churahi Dogri Pattani Gahri Japanese Chambeali Tinani Bhattiyali Gaddi Kanashi Tinani Ladakhi Northern Qiang -

Phonetics and Phonology of Nyagrong Minyag: an Endangered Language of Western China
UNIVERSITY OF HAWAI‘I AT MĀNOA PHD DISSERTATION The Phonetics and Phonology of Nyagrong Minyag, an Endangered Language of Western China John R. Van Way 2018 A DISSERTATION SUBMITTED TO THE UHM GRADUATE DIVISION IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY IN LINGUISTICS DISSERTATION COMMITTEE: Lyle Campbell, Chairperson Victoria Anderson Bradley McDonnell Jonathan Evans Daisuke Takagi Dedicated to the people of Nyagrong khatChO Acknowledgments Funding for research and projects that have led to this dissertation has been awarded by the Endan- gered Languages Documentation Program, the Bilinski Foundation, the Firebird Foundation, and the National Science Foundation East Asia and Pacific Summer Institute. This work would not have been possible without the generous support of these funding agencies. My deepest appreciation goes to Bkrashis Bzangpo, who shared his language with me and em- barked on this journey of language documentation with me. Without his patience, kindness and generosity, this project would not have been possible. I thank the members of Bkrashis’s family who lent their time and support to his project. And I thank the many speakers of Nyagrong Minyag who gave their voices to this project. I would like to thank the many teachers who have inspired, encouraged and supported the re- search and writing of this dissertation. First, I would like to acknowledge my mentor and advisor, Lyle Campbell, who taught me so much about linguistics, fieldwork and language documentation. His support has helped me in myriad ways throughout the journey of graduate school—coursework, funding applications, research, fieldwork, writing, etc. Lyle has inspired me to be the best mentorI can to my own students. -

Papers in Southeast Asian Linguistics No. 14: Tibeto-Bvrman Languages of the Himalayas
PACIFIC LINGUISTICS Series A-86 PAPERS IN SOUTHEAST ASIAN LINGUISTICS NO. 14: TIBETO-BVRMAN LANGUAGES OF THE HIMALAYAS edited by David Bradley Department of Linguistics Research School of Pacific and Asian Studies THE AUSTRALIAN NATIONAL UNIVERSITY Bradley, D. editor. Papers in Southeast Asian Linguistics No. 14:. A-86, vi + 232 (incl. 4 maps) pages. Pacific Linguistics, The Australian National University, 1997. DOI:10.15144/PL-A86.cover ©1997 Pacific Linguistics and/or the author(s). Online edition licensed 2015 CC BY-SA 4.0, with permission of PL. A sealang.net/CRCL initiative. Pacific Linguistics specialises in publishing linguistic material relating to languages of East Asia, Southeast Asia and the Pacific. Linguistic and anthropological manuscripts related to other areas, and to general theoretical issues, are also considered on a case by case basis. Manuscripts are published in one of four series: SERIES A: Occasional Papers SERIES C: Books SERIES B: Monographs SERIES D: Special Publications FOUNDING EDITOR: S.A. Wurm EDITORIAL BOARD: M.D. Ross and D.T. Tryon (Managing Editors), T.E. Dutton, N.P. Himmelmann, A.K. Pawley EDITORIAL ADVISERS: B.W. Bender KA. McElhanon University of Hawaii Summer Institute of Linguistics David Bradley H.P. McKaughan La Trobe University University of Hawaii Michael G. Clyne P. Miihlhausler Monash University Universityof Adelaide S.H. Elbert G.N. O'Grady University of Hawaii University of Victoria, B.C. K.J. Franklin KL. Pike Summer Institute of Linguistics Summer Institute of Linguistics W.W.Glover E.C. Polome Summer Institute of Linguistics University of Texas G.W.Grace Gillian Sankoff University of Hawaii University of Pennsylvania M.A.K. -

Proto-Tibeto-Burman Grain Crops
Rice (2011) 4:134–141 DOI 10.1007/s12284-011-9074-y Proto-Tibeto-Burman Grain Crops David Bradley Received: 09 October 2011 /Accepted: 06 December 2011 /Published online: 14 January 2012 # Springer Science+Business Media, LLC 2012 Introduction later wheat, introduced about 4000 years BP. The location and date of rice domestication(s) is contested, as other The Tibeto-Burman (TB) languages are spread over the speakers will certainly discuss. entire Himalayan region, from Kashmir in the west, across Even for grains first domesticated elsewhere, it is not northern South Asia, southwestern China and northern unreasonable for there to have been Proto-TB etyma (cog- mainland Southeast Asia, in a wide variety of ecological nate words) if they were introduced early enough. This zones from very high altitude to tropical. They include over paper will explore some of the etyma that we would expect 200 languages falling into four major subgroups (Western, to find among TB groups for the grain crops domesticated in Central, Sal, Eastern), with various additional smaller sub- the area, including rice, millets including Setaria, Panicum groups (Bradley 2002). Much ink has been spilled in the and Eleusine coracana as well as buckwheat, Job’s tears and linguistic literature about the original homeland of the early older introduced crops such as sorghum, wheat and barley. Tibeto-Burman groups, but it is clear that this must have been somewhere south and west of the early Chinese civi- lization in the upper Yellow River valley. One frequent Results hypothesis is that the area of greatest genetic linguistic diversity within a language group is the point of origin; on The standard list of the five basic crops of the Chinese is this criterion, this would be in the mountains of northeastern seen in Table 1; this includes four grain crops discussed in India, southeastern Tibet and northern Burma, where the Sagart (1999:176–183). -

The Diversity of the Tibeto-Burman Language Family and the Linguistic Ancestry of Chinese
BULLETIN OF CHINESE LINGUISTICS 1.2:211-270, 2007 The Diversity of the Tibeto-Burman Language Family and the Linguistic Ancestry of Chinese George van DRIEM rb r.;;i~li.~~'*f'' ~-:4£.. ~- jf:a T ~ '17o a :.:r 7f" J 7f7 ~-.... ;;p - _,YJ BULLETIN OF CHINESE LINGUISTICS Volume 1 Number 2 ISSN: 1933-6985, June 2007 Li Fang-Kuei Society for Chinese Linguistics Center for Chinese Linguistics, HKUST BULLETIN OF CHINESE LINGUISTICS 1.2:211-270, 2007 The Diversity of the Tibeto-Burman Language Family and the Linguistic Ancestry of Chinese* George van DRIEM Leiden University 1. Japhetic, Atactic, Turanian and lndo-Chinese In mediaeval Europe, most scholars came to terms with the world's linguistic diversity within the framework of a Biblical belief system. Even at the end of the eighteenth century, pious scholars such as Sir William Jones believed that the myth of the Tower ofBabel explained how 'the language ofNoah' had been 'lost irretrievably' (1793: 489). Another Biblical view attempted to explain the world's linguistic stocks as deriving from Noah's three sons after the deluge had abated in the well-known Judreo-Christian myth of the ark. The descendants of Shem populated the earth with Semitic speaking peoples, whereas the descendants of Ham today spoke 'Scythian' languages, whilst all other languages derived from the progeny of Noah's eldest son Japhet. The Semitic languages most notably include Hebrew, the language of the Old Testament. The Semitic language family is known today as Afroasiatic. Scythian or 'Scythisch' is a language family first identified in Leiden by Marcus van Boxhom (1647), although van Boxhom did not invoke Biblical mythology in any of his own writings.