A Case Study with Wikipedia Article Similarity and Controversy
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Online Coaching 47- (9-5- 2019)
5/9/2019 ONLINE COACHING 47- (9-5- 2019) ONLINE COACHING 47- (9-5- 2019) Vaikunda Swamikal,Thycaud Ayya, Moulana Abdul Kalam Azad Name of the candidate * M3 Please watch the following videos and answer the uestions below https://youtu.be/yle3D3jymUk https://youtu.be/HaPmSBNNuBQ https://docs.google.com/forms/d/1nz-Y8a2De8x0GA-kih-188uFr25TutGV6SLP-vynL2A/edit#response=ACYDBNj0t8qs7K-jqT8PoUJI3EdWb8Jx1a… 1/8 5/9/2019 ONLINE COACHING 47- (9-5- 2019) 1.'Samtva Samajam' was founded by 1 point Vaikunda Swamikal Vaghbatanada Chattambi Swamikal V.T.Bhattathiripad 2.Which social reformer criticised the British rule as ' Rule of the white Devils' 1 point Thycaud Ayya Vaghbatanandan Vaikunda Swamikal Ayyankali 3.What is the real name of Vaikunda Swamikal 1 point Komaran Muthukutty Kunjikannan Subarayan 4.Which social reformer introduced consecration of mirror in South India? 1 point Sree Narayana Guru Vaikunda Swamikal Thycaud Ayya Brahananda Sivayogi https://docs.google.com/forms/d/1nz-Y8a2De8x0GA-kih-188uFr25TutGV6SLP-vynL2A/edit#response=ACYDBNj0t8qs7K-jqT8PoUJI3EdWb8Jx1a… 2/8 5/9/2019 ONLINE COACHING 47- (9-5- 2019) 5.What was the name of group formed by Vaikunda Swami to practice a 1 point punctual and ordered life? Ayyavazhi Thuvayal Panthibhojanam Nizhal Thangal Pathi 6.Which social reformer died wells for backward caste people? 1 point Poykayil Yohannan Kuriakose Elias CHavara Ayyankali Vaikunda Swamikal 7.Which is the way of thought that formed by Vaikunda swami 1 point Rajayogam Sivarajayogam Path of the father Chinmudra 8.Which are the -

21. Ramanuja Nutrandhadhi
AmudhanAr’s IrAmAnusa nUtranthAthi Annotated Commentary in English By: "sampradAya prachAra dhurantharar" SrIrangam SrI V. MAdhavakkaNNan Our Sincere Thanks to the following for their contributions to this ebook: Images contribution: Ramanuja Dasargal at www.pbase.com/svami Neduntheru Sri Mukund Srinivasan eBook assembly: sadagopan.org Smt. Kala Lakshminarayanan CONTENTS TITLE PAGE Introduction 1 Paasuram 1 3 Paasuram 2 7 Paasuram 3 10 Paasuram 4 13 Paasuram 5 15 Paasuram 6 17 Paasuram 7 19 Paasuram 8 25 Paasuram 9 28 sadagopan.org Paasuram 10 30 Paasuram 11 33 Paasuram 12 38 Paasuram 13 42 Paasuram 14 45 Paasuram 15 51 Paasuram 16 52 Paasuram 17 57 Paasuram 18 59 Paasuram 19 62 Paasuram 20 65 Paasuram 21 68 Paasuram 22 71 Paasuram 23 74 Paasuram 24 76 Paasuram 25 78 Paasuram 26 81 Paasuram 27 83 CONTENTS CONT’D. TITLE PAGE Paasuram 28 85 Paasuram 29 88 Paasuram 30 90 Paasuram 31 93 Paasuram 32 95 Paasuram 33 97 Paasuram 34 100 Paasuram 35 102 Paasuram 36 105 Paasuram 37 109 Paasuram 38 112 Paasuram 39 115 Paasuram 40 117 Paasuram 41 122 sadagopan.org Paasuram 42 125 Paasuram 43 128 Paasuram 44 134 Paasuram 45 137 Paasuram 46 139 Paasuram 47 144 Paasuram 48 147 Paasuram 49 150 Paasuram 50 153 Paasuram 51 156 Paasuram 52 160 Paasuram 53 162 Paasuram 54 165 CONTENTS CONT’D. TITLE PAGE Paasuram 55 168 Paasuram 56 171 Paasuram 57 174 Paasuram 58 177 Paasuram 59 181 Paasuram 60 184 Paasuram 61 186 Paasuram 62 189 Paasuram 63 192 sadagopan.org Paasuram 64 194 Paasuram 65 197 Paasuram 66 200 Paasuram 67 203 Paasuram 68 207 Paasuram 69 210 Paasuram -

Why I Became a Hindu
Why I became a Hindu Parama Karuna Devi published by Jagannatha Vallabha Vedic Research Center Copyright © 2018 Parama Karuna Devi All rights reserved Title ID: 8916295 ISBN-13: 978-1724611147 ISBN-10: 1724611143 published by: Jagannatha Vallabha Vedic Research Center Website: www.jagannathavallabha.com Anyone wishing to submit questions, observations, objections or further information, useful in improving the contents of this book, is welcome to contact the author: E-mail: [email protected] phone: +91 (India) 94373 00906 Please note: direct contact data such as email and phone numbers may change due to events of force majeure, so please keep an eye on the updated information on the website. Table of contents Preface 7 My work 9 My experience 12 Why Hinduism is better 18 Fundamental teachings of Hinduism 21 A definition of Hinduism 29 The problem of castes 31 The importance of Bhakti 34 The need for a Guru 39 Can someone become a Hindu? 43 Historical examples 45 Hinduism in the world 52 Conversions in modern times 56 Individuals who embraced Hindu beliefs 61 Hindu revival 68 Dayananda Saraswati and Arya Samaj 73 Shraddhananda Swami 75 Sarla Bedi 75 Pandurang Shastri Athavale 75 Chattampi Swamikal 76 Narayana Guru 77 Navajyothi Sree Karunakara Guru 78 Swami Bhoomananda Tirtha 79 Ramakrishna Paramahamsa 79 Sarada Devi 80 Golap Ma 81 Rama Tirtha Swami 81 Niranjanananda Swami 81 Vireshwarananda Swami 82 Rudrananda Swami 82 Swahananda Swami 82 Narayanananda Swami 83 Vivekananda Swami and Ramakrishna Math 83 Sister Nivedita -

6433-6440 E-ISSN:2581-6063 (Online), ISSN:0972-5210
Plant Archives Volume 20 No. 2, 2020 pp. 6433-6440 e-ISSN:2581-6063 (online), ISSN:0972-5210 ETHNO-BOTANICAL SIGNIFICANCE OF HINDU HOLY PLANTS IN KANYAKUMARI DISTRICT, TAMILNADU, INDIA S. Mary Sheeja and J. Lohidas* Scott Christian College (Autonomous) Nagercoil- 629003, Affiliated toManonmaniam Sundaranar University, Abishekapatti, Tirunelveli-627012 (Tamil Nadu), India Associated Professor, (Department of Botany) Scott Christian College (Autonomous) Nagercoil- 629003, Affiliated to Manonmaniam Sundaranar University, Abishekapatti, Tirunelveli-627012 (Tamil Nadu), India. Abstract Ethno-botanical studies carried out in Traditional and medicinal practices of the people in Western Ghats. During this study there are 44 plants belongs to 29 families and 42 genera were identified as medicinal plants were used to treat Blood sugar, Snake bites, Antibacterial, anti microbial, anti viral, Paralysis, Gastrointestinal disorders, Malaria, Head ache, regularize menstrual cycle, Asthma, Chronic ulcers and Antiseptic. The plant parts were used as decoction, powder is mainly used form of medicine in the study area. Plants part of leaves, stem, bark, seed oil, root, seed, flower and rhizome are also agreed by the ethno-botanical researches. Key words: Ethno-botany, Medicinal plants, Western Ghats. all over the world have been recognized for their ethno- Introduction medicinal importance in India about 2000 plants are used Ethno-botanical studies range across space and time medicinal purpose for medicinal healers. The traditional from archeological investigations of the role of plants in knowledge on the herbal drug has been orally transmitted ancient civilizations. It comprises both wild and from one generation to a different generation. domesticated species and is rooted in observation, In Bhagavad Gita, the Hindu holy book, instructs relationship, needs and traditional ways of such knowledge some flowers correspond to specific gods and should only evolves over time, and is therefore always varying and be used for certain days or rituals. -

Perumal Thirumozhi.Pub
We Sincerely Thank : 1. Sri nrusimha seva rasikar, Oppiliappan kOil Sri. V. SaThakOpan svAmi, the Editor-in-Chief of Sundarasimham-ahobilavalli kaimkaryam for editing and hosting this title in his e-books series. 2. Smt.Krishnapriya for the compilation of the source document. 3. Nedumtheru Sri.Mukund Srinivasan for contribution of images. sadagopan.org sadagopan.org sadagopan.org 4. Smt. Jayashree Muralidharan for assembly of the e-book C O N T E N T S Introduction 1 Paasurams and Commentaries 13 Decad 1 15 Decad 2 43 Decad 3 61 Decad 4 72 Decad 5 100 Decad 6 124 sadagopan.org sadagopan.org sadagopan.org Decad 7 142 Decad 8 163 Decad 9 175 Decad 10 187 nigamanam 204 sadagopan.org sadagopan.org sadagopan.org Kulasekhara PerumAL !@ !mEt ramaNjay nm@ KlEckr ~zfvarf `Rqiy epRmaqf tiRemazi KULASEKARA AZHWAR'S PERUMAL THIRUMOZHI × INTRODUCTION -KULASEKARA PERUMAN THIRUNAKSHATHRAM KulasEkarAzhwar was born as a prince to ChEra king Dhidavrathan and nAdhanAyagi in the month of mAsi and the nakshatram of punarpoosam (same as that of Lord Rama). The child when born looked divine and made everyone happier and cheerful. The entire kingdom was in a jubilant mood. The child was named kulasEkaran and when he grew he was taught all sAstrAs, epics, arts, Tamil and Sanskrit and was also given training on fighting, Horse riding, Elephant riding, etc. In each endeavor, he excelled and came out with flying colors. When Dhidavrathan became old, kulasEkaram ascended the throne and sadagopan.org sadagopan.org then ruled like Lord Sri Rama and brought in RamaRajyam to his kingdom. -

Religions Manual Development of New Inter-Religious Tools
This Publication is part of the project Development of new Inter-religious tools. HOLY MEMO Development of new Inter-religious tools Religions Manual Development of new Inter-religious tools HOLY MEMO This Manual is part of the game HOLY MEMO which is created during project Development of new Inter-religious tools Development of new Inter-religious tools is a project financed under Key Action 2, Capacity building in the field of youth under Western Balkans Window by European Commission, within Erasmus + Youth in Action Program. Project partners: NGO Iuventa (Serbia); Associazione TDM 2000 (Italy); Beyond Barriers - Pertej Barrierave (Albania); BEES (Austria); Intercultura Dinan (France); United Societies of Balkans (Greece); Batman Fen Lisesi Mezunları Derneği (Turkey); Föreningen Framtidståget (Sweden); Better Life In Kosova (Kosovo); Crveni Križ NOVO SARAJEVO (Bosnia and Herzegovina); Nvo Prima (Montenegro) "The European Commission support for the production of this publication does not constitute an endorsement of the contents which reflects the views only of the authors, and the Commission cannot be held responsible for any use which may be made of the information contained therein." 1 2 TABLE OF CONTENTS AYYAVAZHI ............................................................................................................................................. 4 BAHA'I FAITH .......................................................................................................................................... 5 BUDDHISM ............................................................................................................................................... -

Andhra Pradesh
STATE DISTRICT BRANCH ADDRESS CENTRE IFSC CONTACT1 CONTACT2 CONTACT3 MICR_CODE BALAJI COMPLEX OPP. RAGHAVA THEATRE JAILKHANA CHITTOOR ROAD CHITTOOR – CIR@FED ANDHRA (ANDHRA 517 001 ANDHRA ERALBANK PRADESH CHITTOOR PRADESH) PRADESH CHITTOOR FDRL0001673 .CO.IN D.NO.6-7-587 0877 - A.K.NILAYAM 2231361 SRIPURAM COLONY TRP@FED ANDHRA ISKCON ROAD ERALBANK PRADESH CHITTOOR TIRUPATI TIRUPATI - 517 501 TIRUPATI FDRL0001683 .CO.IN AYYAPPA TOWERS (PHASE II), D. NO. 5 - 1 - 76, MAIN ROAD, OPP. TWO TOWN POLICE STATION, KAKINADA - 533001, EAST GODAVARI DURGA ANDHRA EAST DISTRICT, ANDHRA PRASADA KNA@FEDERA 0884 PRADESH GODAVARI KAKINADA PRADESH KAKINADA FDRL0001626 RAO K LBANK.CO.IN 2363611 SWAROOP GEORGE P, E DOOR NO: 60506, MAIL:RMD MAIN ROAD, @FEDERA OPP.SHYAMALA LBANK.CO. TALKIES, IN PH NO.: RAJAMUNDRY, 533 0883- ANDHRA EAST 101, ANDHRA RAJAHMUN 2461457(M PRADESH GODAVARI RAJAHMUNDRY PRADESH DRY FDRL0001341 ) 0863 – 2332277, 2332278 6-14-36, 14TH LANE GTR@FED ANDHRA ARUNDELPET ERALBANK PRADESH GUNTUR GUNTUR GUNTUR – 522 002 GUNTUR FDRL0001671 .CO.IN GOPAKUM AR P, E MAIL:HYD @FEDERA P B NO. 230, ORIENT LBANK.CO. ESTATE, ABIDS IN PH NO.: ROAD, HYDERABAD, 040- ANDHRA 500 001, ANDHRA HYDERABA 23205381( PRADESH HYDERABAD HYDERABAD PRADESH D FDRL0001124 CM) GROUND FLOOR, D.NO. 16-11- 20/6/6/1/1, OPP. TV TOWER, GAFOOR BAGH, SALEEM NAGAR COLONY, MALAKPET, HYDERABAD - HYDG@FE ANDHRA HYDERABAD / 500036, ANDHRA HYDERABA 040 DERALBA PRADESH HYDERABAD MALAKPET PRADESH D FDRL0001826 24540022 040 24540000 NK.CO.IN NO 301 III FLOOR 040 DEGA TOWERS 23303305 RAJBHAVAN -
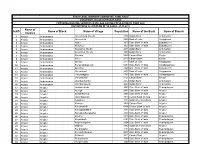
S.NO Name of District Name of Block Name of Village Population Name
STATE LEVEL BANKERS' COMMITTEE, TAMIL NADU CONVENOR: INDIAN OVERSEAS BANK PROVIDING BANKING SERVICES IN VILLAGE HAVING POPULATION OF OVER 2000 DISTRICTWISE ALLOCATION OF VILLAGES -01.11.2011 Name of S.NO Name of Block Name of Village Population Name of the Bank Name of Branch District 1 Ariyalur Andiamadam Anikudichan (South) 2730 Indian Bank Andimadam 2 Ariyalur Andiamadam Athukurichi 5540 Bank of India Alagapuram 3 Ariyalur Andiamadam Ayyur 3619 State Bank of India Edayakurichi 4 Ariyalur Andiamadam Kodukkur 3023 State Bank of India Edayakurichi 5 Ariyalur Andiamadam Koovathur (North) 2491 Indian Bank Andimadam 6 Ariyalur Andiamadam Koovathur (South) 3909 Indian Bank Andimadam 7 Ariyalur Andiamadam Marudur 5520 Canara Bank Elaiyur 8 Ariyalur Andiamadam Melur 2318 Canara Bank Elaiyur 9 Ariyalur Andiamadam Olaiyur 2717 Bank of India Alagapuram 10 Ariyalur Andiamadam Periakrishnapuram 5053 State Bank of India Varadarajanpet 11 Ariyalur Andiamadam Silumbur 2660 State Bank of India Edayakurichi 12 Ariyalur Andiamadam Siluvaicheri 2277 Bank of India Alagapuram 13 Ariyalur Andiamadam Thirukalappur 4785 State Bank of India Varadarajanpet 14 Ariyalur Andiamadam Variyankaval 4125 Canara Bank Elaiyur 15 Ariyalur Andiamadam Vilandai (North) 2012 Indian Bank Andimadam 16 Ariyalur Andiamadam Vilandai (South) 9663 Indian Bank Andimadam 17 Ariyalur Ariyalur Andipattakadu 3083 State Bank of India Reddipalayam 18 Ariyalur Ariyalur Arungal 2868 State Bank of India Ariyalur 19 Ariyalur Ariyalur Edayathankudi 2008 State Bank of India Ariyalur 20 Ariyalur -

Download Download
Article CASTE: A Global Journal on Social Exclusion Vol. 1, No. 1, pp. 125–154 February 2020 brandeis.edu/j-caste ISSN 2639-4928 DOI: 10.26812/caste.v1i1.96 Mirrors of the Soul Performative Egalitarianisms and Genealogies of the Human in Colonial-era Travancore, 1854-1927 Vivek V. Narayan1 (Bluestone Rising Scholar 2019 Award) for Pradeepan Pampirikunnu, with gratitude and in loving memory of an all-too-brief conversation Abstract Scenes of avarna castes (slave and intermediate castes) pondering their reflections recur throughout the history of anti-caste struggle in the princely state of Travancore in colonial-era south India. These scenes represent what I will call performative egalitarianisms, which are repetitive enactments in the performance of everyday lives that embody claims to equality against the dehumanizing caste codes of colonial Travancore. In this paper, I will describe three scenes that represent distinct yet intertwined routes for the flows of egalitarian discourses in colonial Kerala. The concept of equality emerged in Travancore, first, via Enlightenment values of the British Protestant missionaries, or soulful Enlightenment; second, as non-dualistic equality of Narayana Guru, or repurposed Advaita; and third, through the discourses and practices of a Tamil religious cult called Ayya Vazhi, or radical Siddha Saiva. In viewing the flows of egalitarian discourse through the lens of performance, I demonstrate the method of intellectual histories in the repertoire which allows us to investigate how particular conceptual frameworks and discursive modes are transmitted, transformed, and embodied by people for whom these ideas are, quite literally, a matter of life and death. The intentional, productive, and empowering relationship between universals such as equality or humanity and the particular claims of anti-caste struggle in Kerala leads to a politics of practice that I describe as repurposing universals. -

18. Thiru Thevanar Thogai
Our Sincere Thanks to the following for their contributions to this ebook: Images/artwork contribution: ♦ http://www.srivaishnavam.com/ ♦ Ramanuja Daasargal at www.pbase.com/svami ♦ www.prapatti.com ♦ Sow.Chitralekha, Chennai ♦ Sri Lakshminarasimhan Sridhar, Bangalore sadagopan.org sadagopan.org sadagopan.org Tamil Paasurams text provided by - www.ahobilamutt.org eBook assembly: Sri Murali Desikachari Smt. Jayashree Muralidharan C O N T E N T S Introduction 1 PAsurams and Commentaries 3 Taniyan 4 PAsuram 1 5 PAsuram 2 7 sadagopan.org sadagopan.org sadagopan.org PAsuram 3 9 PAsuram 4 11 PAsuram 5 13 PAsuram 6 15 PAsuram 7 16 PAsuram 8 18 PAsuram 9 20 PAsuram 10 22 Divya Desa Kaimkaryam 23 sadagopan.org sadagopan.org sadagopan.org Thirumangai Mannan with Kumudavalli Nacchiyar !@ sadagopan.org sadagopan.org sadagopan.org INTRODUCTION Among the 11 dhivya dEsams of ThirunAngUr, Thiru ThEvanAr Thogai is the fourth in order to receive Thirumangai’s MangaLAsAsanam. Here at the sannidhi of Maadhava PerumAL, Kaliyan foucuses on the superiority of the river MaNNI, the Vaidhika SrI of the residents of ThirutthEvanAr Thogai, the AchAra-anushtAna srEyas of Veda viths, the material prosperity of this dhivya dEsam (Gold, gems, dhana dhAnya samruddhi, fertile groves full of flowers- fruits and the shining, tall golden ramparts around this temple. SrI Maadhava PerumAL (Dhaiva Naayakan) sannidhi is at KeezhaicchAlai and is approximately 4 miles away from SeerkAzhi. PerumAL faces west and blesses us with His darsanam in NinRa ThirukkOlam with Kadal MahaL NacchiyAr under Sobhana VimAnam. The PushkaraNi’s name is Deva SabhA PushkaraNi. Since the dEvAs came together in big assembly (Thogai), the dhivya dEsam got its name as ThEvanAr Thogai.PerumAL is Prathyaksham to Sage Vasishtar. -

Temples Within Chennai City
Temples within Chennai City 1 As the famous Tamil poetess AUVAYYAR says in Her Legendary presentation of cluster of hymns “Kovil illatha ooril kudi irukkathe” Please don’t reside in a place where there is no temple. The Statement of our forefathers is sacrosanct because the temple indicates that the community is graced by the presence of God and that its Citizens form a moral community. A Community identifies and is identified by others with its temples. It has been our ancient endavour to lead a pious life with full dedication to the services of the Lord. Sri Paramacharya of Kanchi Mutt has repeatedly called devotees and stressed the importance of taking care of old temples - which requires enormous power of men and money - instead of constructing new temples in cities. As you may be aware, there are thousands of temples in dilapidated condition and requires constant maintenance work to be undertaken. There are many shiva lingas of ancient temples found under trees and also while digging. In ancient times, these lingas were 'Moolavars' of temples built by several kings. After conquests and devastations by foreign invaders, Indian temples were destructed and the sacred deities were thrown away and many were broken. The left out deities are found later. Of them, some are unidentified. Those who attempt to construct temples for gods are freed from the sins of a thousand births. Those who think of building a temple in their minds are freed from the sins of a hundred births. Those who contribute to the cause of a temple are bestowed with divine virtues and blessings. -

Kanniyakumari
Census of India 2011 TAMIL NADU PART XII-A SERIES-34 DISTRICT CENSUS HANDBOOK KANNIYAKUMARI VILLAGE AND TOWN DIRECTORY DIRECTORATE OF CENSUS OPERATIONS TAMIL NADU CENSUS OF INDIA 2011 TAMIL NADU SERIES 34 PART XII-A DISTRICT CENSUS HANDBOOK KANNIYAKUMARI VILLAGE AND TOWN DIRECTORY Directorate of Census Operations Tamil Nadu 2011 VIVEKANANDA MEMORIAL AND THIRUVALLUVAR STATUE There are two rocks projecting out of the Indian Ocean, south- east of Kanniyakumari temple. These rocks provide an ideal vantage point for visitors desiring to view the land end of India. On one of these rocks, Swami Vivekananda sat in long and deep meditation, when he visited Kanniyakumari in 1892. On this rock, the “Vivekananda Rock Memorial” was built in 1970 with a blend of all the architectural styles of India. A statue of Swami Vivekananda has been installed inside this memorial building. One can also see “Sri Padha Parai”, believed by the devout to be the foot prints of the virgin Goddess Kanniyakumari on this rock. The Thiruvalluvar Statue is a 133 feet tall stone sculpture of the Tamil poet and philosopher, Tiruvalluvar, author of the Thirukkural located adjacent to Vivekananda Rock Memorial. DISTRICT CENSUS HANDBOOK - 2011 CONTENTS Page Foreword i Preface iii Acknowledgements iv History and Scope of the District Census Handbook v Brief History of the District vi Highlights of the District - 2011 Census vii Important Statistics of the District - 2011 Census viii Analytical Note 1 Village and Town Directory 103 Brief Note on Village and Town Directory 105 Section -I Village Directory 111 (a) List of villages merged in towns and outgrowths at 2011 Census 112 (b) C.D.