TITLE an Approach for the Identification of Targets Specific To
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Datasheet Blank Template
SAN TA C RUZ BI OTEC HNOL OG Y, INC . DIP2A (L-16): sc-67555 BACKGROUND APPLICATIONS DIP2A (Disco-interacting protein 2 homolog A), also known as DIP2, is a 1,571 DIP2A (L-16) is recommended for detection of DIP2A of human origin by amino acid nuclear protein. It is one of three human homologs (DIP2A, DIP2B Western Blotting (starting dilution 1:200, dilution range 1:100-1:1000), and DIP2C) of the Drosophila dip2 (disconnected-interacting protein 2) protein. immunoprecipitation [1-2 µg per 100-500 µg of total protein (1 ml of cell In Drosophila , dip2 interacts with disco, a protein required for neuronal con - lysate)], immunofluorescence (starting dilution 1:50, dilution range 1:50- nections in the visual systems of larvae and adults. The closest vertebrate 1:500) and solid phase ELISA (starting dilution 1:30, dilution range 1:30- homologs to disco are the basonuclin genes. In mice, DIP2 homologs show 1:3000). restricted expression to the brain. This suggests that, similar to the function DIP2A (L-16) is also recommended for detection of DIP2A, also designated of Drosphila dip2, vertebrate DIP2 homologs may play a role in the develop - Disco-interacting protein 2 homolog A, in additional species, including ment of the nervous system. Expressed ubiquitously with highest expression canine. in the brain, DIP2A is thought to function in signaling throughout the central nervous system by providing positional clues for axon patterning and pathfind - Suitable for use as control antibody for DIP2A siRNA (h): sc-62212, DIP2A ing . Four isoforms of DIP2A exist due to alternative splicing events. -

Supplemental Information to Mammadova-Bach Et Al., “Laminin Α1 Orchestrates VEGFA Functions in the Ecosystem of Colorectal Carcinogenesis”
Supplemental information to Mammadova-Bach et al., “Laminin α1 orchestrates VEGFA functions in the ecosystem of colorectal carcinogenesis” Supplemental material and methods Cloning of the villin-LMα1 vector The plasmid pBS-villin-promoter containing the 3.5 Kb of the murine villin promoter, the first non coding exon, 5.5 kb of the first intron and 15 nucleotides of the second villin exon, was generated by S. Robine (Institut Curie, Paris, France). The EcoRI site in the multi cloning site was destroyed by fill in ligation with T4 polymerase according to the manufacturer`s instructions (New England Biolabs, Ozyme, Saint Quentin en Yvelines, France). Site directed mutagenesis (GeneEditor in vitro Site-Directed Mutagenesis system, Promega, Charbonnières-les-Bains, France) was then used to introduce a BsiWI site before the start codon of the villin coding sequence using the 5’ phosphorylated primer: 5’CCTTCTCCTCTAGGCTCGCGTACGATGACGTCGGACTTGCGG3’. A double strand annealed oligonucleotide, 5’GGCCGGACGCGTGAATTCGTCGACGC3’ and 5’GGCCGCGTCGACGAATTCACGC GTCC3’ containing restriction site for MluI, EcoRI and SalI were inserted in the NotI site (present in the multi cloning site), generating the plasmid pBS-villin-promoter-MES. The SV40 polyA region of the pEGFP plasmid (Clontech, Ozyme, Saint Quentin Yvelines, France) was amplified by PCR using primers 5’GGCGCCTCTAGATCATAATCAGCCATA3’ and 5’GGCGCCCTTAAGATACATTGATGAGTT3’ before subcloning into the pGEMTeasy vector (Promega, Charbonnières-les-Bains, France). After EcoRI digestion, the SV40 polyA fragment was purified with the NucleoSpin Extract II kit (Machery-Nagel, Hoerdt, France) and then subcloned into the EcoRI site of the plasmid pBS-villin-promoter-MES. Site directed mutagenesis was used to introduce a BsiWI site (5’ phosphorylated AGCGCAGGGAGCGGCGGCCGTACGATGCGCGGCAGCGGCACG3’) before the initiation codon and a MluI site (5’ phosphorylated 1 CCCGGGCCTGAGCCCTAAACGCGTGCCAGCCTCTGCCCTTGG3’) after the stop codon in the full length cDNA coding for the mouse LMα1 in the pCIS vector (kindly provided by P. -

Gene Symbol Gene Description ACVR1B Activin a Receptor, Type IB
Table S1. Kinase clones included in human kinase cDNA library for yeast two-hybrid screening Gene Symbol Gene Description ACVR1B activin A receptor, type IB ADCK2 aarF domain containing kinase 2 ADCK4 aarF domain containing kinase 4 AGK multiple substrate lipid kinase;MULK AK1 adenylate kinase 1 AK3 adenylate kinase 3 like 1 AK3L1 adenylate kinase 3 ALDH18A1 aldehyde dehydrogenase 18 family, member A1;ALDH18A1 ALK anaplastic lymphoma kinase (Ki-1) ALPK1 alpha-kinase 1 ALPK2 alpha-kinase 2 AMHR2 anti-Mullerian hormone receptor, type II ARAF v-raf murine sarcoma 3611 viral oncogene homolog 1 ARSG arylsulfatase G;ARSG AURKB aurora kinase B AURKC aurora kinase C BCKDK branched chain alpha-ketoacid dehydrogenase kinase BMPR1A bone morphogenetic protein receptor, type IA BMPR2 bone morphogenetic protein receptor, type II (serine/threonine kinase) BRAF v-raf murine sarcoma viral oncogene homolog B1 BRD3 bromodomain containing 3 BRD4 bromodomain containing 4 BTK Bruton agammaglobulinemia tyrosine kinase BUB1 BUB1 budding uninhibited by benzimidazoles 1 homolog (yeast) BUB1B BUB1 budding uninhibited by benzimidazoles 1 homolog beta (yeast) C9orf98 chromosome 9 open reading frame 98;C9orf98 CABC1 chaperone, ABC1 activity of bc1 complex like (S. pombe) CALM1 calmodulin 1 (phosphorylase kinase, delta) CALM2 calmodulin 2 (phosphorylase kinase, delta) CALM3 calmodulin 3 (phosphorylase kinase, delta) CAMK1 calcium/calmodulin-dependent protein kinase I CAMK2A calcium/calmodulin-dependent protein kinase (CaM kinase) II alpha CAMK2B calcium/calmodulin-dependent -

Small Cell Ovarian Carcinoma: Genomic Stability and Responsiveness to Therapeutics
Gamwell et al. Orphanet Journal of Rare Diseases 2013, 8:33 http://www.ojrd.com/content/8/1/33 RESEARCH Open Access Small cell ovarian carcinoma: genomic stability and responsiveness to therapeutics Lisa F Gamwell1,2, Karen Gambaro3, Maria Merziotis2, Colleen Crane2, Suzanna L Arcand4, Valerie Bourada1,2, Christopher Davis2, Jeremy A Squire6, David G Huntsman7,8, Patricia N Tonin3,4,5 and Barbara C Vanderhyden1,2* Abstract Background: The biology of small cell ovarian carcinoma of the hypercalcemic type (SCCOHT), which is a rare and aggressive form of ovarian cancer, is poorly understood. Tumourigenicity, in vitro growth characteristics, genetic and genomic anomalies, and sensitivity to standard and novel chemotherapeutic treatments were investigated in the unique SCCOHT cell line, BIN-67, to provide further insight in the biology of this rare type of ovarian cancer. Method: The tumourigenic potential of BIN-67 cells was determined and the tumours formed in a xenograft model was compared to human SCCOHT. DNA sequencing, spectral karyotyping and high density SNP array analysis was performed. The sensitivity of the BIN-67 cells to standard chemotherapeutic agents and to vesicular stomatitis virus (VSV) and the JX-594 vaccinia virus was tested. Results: BIN-67 cells were capable of forming spheroids in hanging drop cultures. When xenografted into immunodeficient mice, BIN-67 cells developed into tumours that reflected the hypercalcemia and histology of human SCCOHT, notably intense expression of WT-1 and vimentin, and lack of expression of inhibin. Somatic mutations in TP53 and the most common activating mutations in KRAS and BRAF were not found in BIN-67 cells by DNA sequencing. -

BIRC7 Sirna (Human)
For research purposes only, not for human use Product Data Sheet BIRC7 siRNA (Human) Catalog # Source Reactivity Applications CRJ2387 Synthetic H RNAi Description siRNA to inhibit BIRC7 expression using RNA interference Specificity BIRC7 siRNA (Human) is a target-specific 19-23 nt siRNA oligo duplexes designed to knock down gene expression. Form Lyophilized powder Gene Symbol BIRC7 Alternative Names KIAP; LIVIN; MLIAP; RNF50; Baculoviral IAP repeat-containing protein 7; Kidney inhibitor of apoptosis protein; KIAP; Livin; Melanoma inhibitor of apoptosis protein; ML-IAP; RING finger protein 50 Entrez Gene 79444 (Human) SwissProt Q96CA5 (Human) Purity > 97% Quality Control Oligonucleotide synthesis is monitored base by base through trityl analysis to ensure appropriate coupling efficiency. The oligo is subsequently purified by affinity-solid phase extraction. The annealed RNA duplex is further analyzed by mass spectrometry to verify the exact composition of the duplex. Each lot is compared to the previous lot by mass spectrometry to ensure maximum lot-to-lot consistency. Components We offers pre-designed sets of 3 different target-specific siRNA oligo duplexes of human BIRC7 gene. Each vial contains 5 nmol of lyophilized siRNA. The duplexes can be transfected individually or pooled together to achieve knockdown of the target gene, which is most commonly assessed by qPCR or western blot. Our siRNA oligos are also chemically modified (2’-OMe) at no extra charge for increased stability and Application key: E- ELISA, WB- Western blot, IH- Immunohistochemistry, -

Proteomic Profile of Human Spermatozoa in Healthy And
Cao et al. Reproductive Biology and Endocrinology (2018) 16:16 https://doi.org/10.1186/s12958-018-0334-1 REVIEW Open Access Proteomic profile of human spermatozoa in healthy and asthenozoospermic individuals Xiaodan Cao, Yun Cui, Xiaoxia Zhang, Jiangtao Lou, Jun Zhou, Huafeng Bei and Renxiong Wei* Abstract Asthenozoospermia is considered as a common cause of male infertility and characterized by reduced sperm motility. However, the molecular mechanism that impairs sperm motility remains unknown in most cases. In the present review, we briefly reviewed the proteome of spermatozoa and seminal plasma in asthenozoospermia and considered post-translational modifications in spermatozoa of asthenozoospermia. The reduction of sperm motility in asthenozoospermic patients had been attributed to factors, for instance, energy metabolism dysfunction or structural defects in the sperm-tail protein components and the differential proteins potentially involved in sperm motility such as COX6B, ODF, TUBB2B were described. Comparative proteomic analysis open a window to discover the potential pathogenic mechanisms of asthenozoospermia and the biomarkers with clinical significance. Keywords: Proteome, Spermatozoa, Sperm motility, Asthenozoospermia, Infertility Background fertilization failure [4] and it has become clear that iden- Infertility is defined as the lack of ability to achieve a tifying the precise proteins and the pathways involved in clinical pregnancy after one year or more of unprotected sperm motility is needed [5]. and well-timed intercourse with the same partner [1]. It is estimated that around 15% of couples of reproductive age present with infertility, and about half of the infertil- Application of proteomic techniques in male ity is associated with male partner [2, 3]. -

Copy Number Alterations of BCAS1 in Squamous Cell Carcinomas
The Korean Journal of Pathology 2011; 45: 271-275 DOI: 10.4132/KoreanJPathol.2011.45.3.271 Copy Number Alterations of BCAS1 in Squamous Cell Carcinomas Yu Im Kim · Ahwon Lee1 Background: Breast carcinoma amplified sequence 1 BCAS1( ), located in 20q13, is amplified and Jennifer Kim · Bum Hee Lee overexpressed in breast cancers. Even though BCAS1 is expected to be an oncogene candidate, Sung Hak Lee · Suk Woo Nam its contribution to tumorigenesis and copy number status in other malignancies is not reported. To elucidate the role of BCAS1 in squamous cell carcinomas, we investigated the copy number Sug Hyung Lee · Won Sang Park status and expression level of BCAS1 in several squamous cell carcinoma cell lines, normal kera- Nam Jin Yoo · Jung Young Lee tinocytes and primary tumors. Methods: We quantitated BCAS1 gene by real-time polymerase Sang Ho Kim · Su Young Kim chain reaction (PCR). Expression level of BCAS1 was measured by real-time reverse transcrip- tion-PCR and immunoblot. Results: Seven (88%) of 8 squamous cell carcinoma cell lines showed Departments of Pathology and 1Hospital copy number gain of BCAS1 with various degrees. BCAS1 gene in primary tumors (73%) also Pathology, The Catholic University of Korea showed copy number gain. However, expression level did not show a linear correlation with copy College of Medicine, Seoul, Korea number changes. Conclusions: We identified copy number gain of BCAS1 in squamous cell car- cinomas. Due to lack of linear correlation between copy numbers of BCAS1 and its expression Received: March 10, 2010 level, we could not confirm that the overexpression of BCAS1 is a common finding in squamous Accepted: May 24, 2011 cell carcinoma cell lines. -

Genome Wide Association Study of Response to Interval and Continuous Exercise Training: the Predict‑HIIT Study Camilla J
Williams et al. J Biomed Sci (2021) 28:37 https://doi.org/10.1186/s12929-021-00733-7 RESEARCH Open Access Genome wide association study of response to interval and continuous exercise training: the Predict-HIIT study Camilla J. Williams1†, Zhixiu Li2†, Nicholas Harvey3,4†, Rodney A. Lea4, Brendon J. Gurd5, Jacob T. Bonafglia5, Ioannis Papadimitriou6, Macsue Jacques6, Ilaria Croci1,7,20, Dorthe Stensvold7, Ulrik Wislof1,7, Jenna L. Taylor1, Trishan Gajanand1, Emily R. Cox1, Joyce S. Ramos1,8, Robert G. Fassett1, Jonathan P. Little9, Monique E. Francois9, Christopher M. Hearon Jr10, Satyam Sarma10, Sylvan L. J. E. Janssen10,11, Emeline M. Van Craenenbroeck12, Paul Beckers12, Véronique A. Cornelissen13, Erin J. Howden14, Shelley E. Keating1, Xu Yan6,15, David J. Bishop6,16, Anja Bye7,17, Larisa M. Haupt4, Lyn R. Grifths4, Kevin J. Ashton3, Matthew A. Brown18, Luciana Torquati19, Nir Eynon6 and Jef S. Coombes1* Abstract Background: Low cardiorespiratory ftness (V̇O2peak) is highly associated with chronic disease and mortality from all causes. Whilst exercise training is recommended in health guidelines to improve V̇O2peak, there is considerable inter-individual variability in the V̇O2peak response to the same dose of exercise. Understanding how genetic factors contribute to V̇O2peak training response may improve personalisation of exercise programs. The aim of this study was to identify genetic variants that are associated with the magnitude of V̇O2peak response following exercise training. Methods: Participant change in objectively measured V̇O2peak from 18 diferent interventions was obtained from a multi-centre study (Predict-HIIT). A genome-wide association study was completed (n 507), and a polygenic predictor score (PPS) was developed using alleles from single nucleotide polymorphisms= (SNPs) signifcantly associ- –5 ated (P < 1 10 ) with the magnitude of V̇O2peak response. -

The Proximal Signaling Network of the BCR-ABL1 Oncogene Shows a Modular Organization
Oncogene (2010) 29, 5895–5910 & 2010 Macmillan Publishers Limited All rights reserved 0950-9232/10 www.nature.com/onc ORIGINAL ARTICLE The proximal signaling network of the BCR-ABL1 oncogene shows a modular organization B Titz, T Low, E Komisopoulou, SS Chen, L Rubbi and TG Graeber Crump Institute for Molecular Imaging, Institute for Molecular Medicine, Jonsson Comprehensive Cancer Center, California NanoSystems Institute, Department of Molecular and Medical Pharmacology, University of California, Los Angeles, CA, USA BCR-ABL1 is a fusion tyrosine kinase, which causes signaling effects of BCR-ABL1 toward leukemic multiple types of leukemia. We used an integrated transformation. proteomic approach that includes label-free quantitative Oncogene (2010) 29, 5895–5910; doi:10.1038/onc.2010.331; protein complex and phosphorylation profiling by mass published online 9 August 2010 spectrometry to systematically characterize the proximal signaling network of this oncogenic kinase. The proximal Keywords: adaptor protein; BCR-ABL1; phospho- BCR-ABL1 signaling network shows a modular and complex; quantitative mass spectrometry; signaling layered organization with an inner core of three leukemia network; systems biology transformation-relevant adaptor protein complexes (Grb2/Gab2/Shc1 complex, CrkI complex and Dok1/ Dok2 complex). We introduced an ‘interaction direction- ality’ analysis, which annotates static protein networks Introduction with information on the directionality of phosphorylation- dependent interactions. In this analysis, the observed BCR-ABL1 is a constitutively active oncogenic fusion network structure was consistent with a step-wise kinase that arises through a chromosomal translocation phosphorylation-dependent assembly of the Grb2/Gab2/ and causes multiple types of leukemia. It is found in Shc1 and the Dok1/Dok2 complexes on the BCR-ABL1 many cases (B25%) of adult acute lymphoblastic core. -

Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model
Downloaded from http://www.jimmunol.org/ by guest on September 25, 2021 T + is online at: average * The Journal of Immunology , 34 of which you can access for free at: 2016; 197:1477-1488; Prepublished online 1 July from submission to initial decision 4 weeks from acceptance to publication 2016; doi: 10.4049/jimmunol.1600589 http://www.jimmunol.org/content/197/4/1477 Molecular Profile of Tumor-Specific CD8 Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. Waugh, Sonia M. Leach, Brandon L. Moore, Tullia C. Bruno, Jonathan D. Buhrman and Jill E. Slansky J Immunol cites 95 articles Submit online. Every submission reviewed by practicing scientists ? is published twice each month by Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts http://jimmunol.org/subscription Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html http://www.jimmunol.org/content/suppl/2016/07/01/jimmunol.160058 9.DCSupplemental This article http://www.jimmunol.org/content/197/4/1477.full#ref-list-1 Information about subscribing to The JI No Triage! Fast Publication! Rapid Reviews! 30 days* Why • • • Material References Permissions Email Alerts Subscription Supplementary The Journal of Immunology The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2016 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. This information is current as of September 25, 2021. The Journal of Immunology Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. -
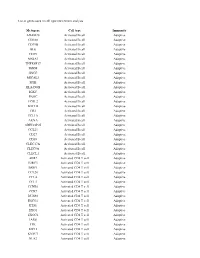
List of Genes Used in Cell Type Enrichment Analysis
List of genes used in cell type enrichment analysis Metagene Cell type Immunity ADAM28 Activated B cell Adaptive CD180 Activated B cell Adaptive CD79B Activated B cell Adaptive BLK Activated B cell Adaptive CD19 Activated B cell Adaptive MS4A1 Activated B cell Adaptive TNFRSF17 Activated B cell Adaptive IGHM Activated B cell Adaptive GNG7 Activated B cell Adaptive MICAL3 Activated B cell Adaptive SPIB Activated B cell Adaptive HLA-DOB Activated B cell Adaptive IGKC Activated B cell Adaptive PNOC Activated B cell Adaptive FCRL2 Activated B cell Adaptive BACH2 Activated B cell Adaptive CR2 Activated B cell Adaptive TCL1A Activated B cell Adaptive AKNA Activated B cell Adaptive ARHGAP25 Activated B cell Adaptive CCL21 Activated B cell Adaptive CD27 Activated B cell Adaptive CD38 Activated B cell Adaptive CLEC17A Activated B cell Adaptive CLEC9A Activated B cell Adaptive CLECL1 Activated B cell Adaptive AIM2 Activated CD4 T cell Adaptive BIRC3 Activated CD4 T cell Adaptive BRIP1 Activated CD4 T cell Adaptive CCL20 Activated CD4 T cell Adaptive CCL4 Activated CD4 T cell Adaptive CCL5 Activated CD4 T cell Adaptive CCNB1 Activated CD4 T cell Adaptive CCR7 Activated CD4 T cell Adaptive DUSP2 Activated CD4 T cell Adaptive ESCO2 Activated CD4 T cell Adaptive ETS1 Activated CD4 T cell Adaptive EXO1 Activated CD4 T cell Adaptive EXOC6 Activated CD4 T cell Adaptive IARS Activated CD4 T cell Adaptive ITK Activated CD4 T cell Adaptive KIF11 Activated CD4 T cell Adaptive KNTC1 Activated CD4 T cell Adaptive NUF2 Activated CD4 T cell Adaptive PRC1 Activated -

A Study of Chemotherapy Resistance in Acute Myeloid Leukemia
A Study of Chemotherapy Resistance in Acute Myeloid Leukemia A DISSERTATION SUBMITTED TO THE FACULTY OF THE GRADUATE SCHOOL OF THE UNIVERSITY OF MINNESOTA BY Susan Kay Rathe IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY David A. Largaespada October, 2013 © Susan Kay Rathe 2013 Acknowledgements Funding: The leukemia research was funded by The Leukemia & Lymphoma Society (grant 7019-04). The MMuFLR workflow was funded by The Children's Cancer Research Fund. University of Minnesota Resources: The BioMedical Genomics Center provided services for gene expression microarray, RNA sequencing, oligo preparation, and Sanger sequencing. The Minnesota Supercomputing Institute maintains the Galaxy Software, as well as provides data management services and training. The Masonic Cancer Center Bioinformatics Core provided guidance in the analysis of the RNA-seq data. The FDA Drug Screen was performed at the Institute for Therapeutics Discovery and Development. Colleagues: First and foremost, I would like to recognize Dr. David Largaespada for his mentorship and the opportunity to continue research he started while a postdoc in Dr. Neal Copeland’s lab. I would also like to thank the many members of the Largaespada lab who provided direct or indirect assistance to my research. Dr. Bin Yin continued Dr. Largaespada’s work on the BXH-2 AML cell lines by making drug resistant derivatives and provided training in cell culture and drug assay techniques. Dr. Won-Il Kim developed the TNM mouse model and provided training in mouse related experimental techniques. Miechaleen Diers did all of the tail vein injections for the AML transplants and assisted with necropsies.