Finding Drug Targeting Mechanisms with Genetic Evidence for Parkinson’S Disease
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model
Downloaded from http://www.jimmunol.org/ by guest on September 25, 2021 T + is online at: average * The Journal of Immunology , 34 of which you can access for free at: 2016; 197:1477-1488; Prepublished online 1 July from submission to initial decision 4 weeks from acceptance to publication 2016; doi: 10.4049/jimmunol.1600589 http://www.jimmunol.org/content/197/4/1477 Molecular Profile of Tumor-Specific CD8 Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. Waugh, Sonia M. Leach, Brandon L. Moore, Tullia C. Bruno, Jonathan D. Buhrman and Jill E. Slansky J Immunol cites 95 articles Submit online. Every submission reviewed by practicing scientists ? is published twice each month by Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts http://jimmunol.org/subscription Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html http://www.jimmunol.org/content/suppl/2016/07/01/jimmunol.160058 9.DCSupplemental This article http://www.jimmunol.org/content/197/4/1477.full#ref-list-1 Information about subscribing to The JI No Triage! Fast Publication! Rapid Reviews! 30 days* Why • • • Material References Permissions Email Alerts Subscription Supplementary The Journal of Immunology The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2016 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. This information is current as of September 25, 2021. The Journal of Immunology Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. -
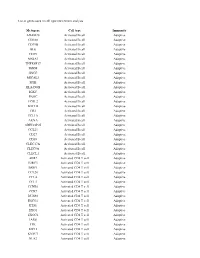
List of Genes Used in Cell Type Enrichment Analysis
List of genes used in cell type enrichment analysis Metagene Cell type Immunity ADAM28 Activated B cell Adaptive CD180 Activated B cell Adaptive CD79B Activated B cell Adaptive BLK Activated B cell Adaptive CD19 Activated B cell Adaptive MS4A1 Activated B cell Adaptive TNFRSF17 Activated B cell Adaptive IGHM Activated B cell Adaptive GNG7 Activated B cell Adaptive MICAL3 Activated B cell Adaptive SPIB Activated B cell Adaptive HLA-DOB Activated B cell Adaptive IGKC Activated B cell Adaptive PNOC Activated B cell Adaptive FCRL2 Activated B cell Adaptive BACH2 Activated B cell Adaptive CR2 Activated B cell Adaptive TCL1A Activated B cell Adaptive AKNA Activated B cell Adaptive ARHGAP25 Activated B cell Adaptive CCL21 Activated B cell Adaptive CD27 Activated B cell Adaptive CD38 Activated B cell Adaptive CLEC17A Activated B cell Adaptive CLEC9A Activated B cell Adaptive CLECL1 Activated B cell Adaptive AIM2 Activated CD4 T cell Adaptive BIRC3 Activated CD4 T cell Adaptive BRIP1 Activated CD4 T cell Adaptive CCL20 Activated CD4 T cell Adaptive CCL4 Activated CD4 T cell Adaptive CCL5 Activated CD4 T cell Adaptive CCNB1 Activated CD4 T cell Adaptive CCR7 Activated CD4 T cell Adaptive DUSP2 Activated CD4 T cell Adaptive ESCO2 Activated CD4 T cell Adaptive ETS1 Activated CD4 T cell Adaptive EXO1 Activated CD4 T cell Adaptive EXOC6 Activated CD4 T cell Adaptive IARS Activated CD4 T cell Adaptive ITK Activated CD4 T cell Adaptive KIF11 Activated CD4 T cell Adaptive KNTC1 Activated CD4 T cell Adaptive NUF2 Activated CD4 T cell Adaptive PRC1 Activated -

A Molecular Switch from STAT2-IRF9 to ISGF3 Underlies Interferon-Induced Gene Transcription
ARTICLE https://doi.org/10.1038/s41467-019-10970-y OPEN A molecular switch from STAT2-IRF9 to ISGF3 underlies interferon-induced gene transcription Ekaterini Platanitis 1, Duygu Demiroz1,5, Anja Schneller1,5, Katrin Fischer1, Christophe Capelle1, Markus Hartl 1, Thomas Gossenreiter 1, Mathias Müller2, Maria Novatchkova3,4 & Thomas Decker 1 Cells maintain the balance between homeostasis and inflammation by adapting and inte- grating the activity of intracellular signaling cascades, including the JAK-STAT pathway. Our 1234567890():,; understanding of how a tailored switch from homeostasis to a strong receptor-dependent response is coordinated remains limited. Here, we use an integrated transcriptomic and proteomic approach to analyze transcription-factor binding, gene expression and in vivo proximity-dependent labelling of proteins in living cells under homeostatic and interferon (IFN)-induced conditions. We show that interferons (IFN) switch murine macrophages from resting-state to induced gene expression by alternating subunits of transcription factor ISGF3. Whereas preformed STAT2-IRF9 complexes control basal expression of IFN-induced genes (ISG), both type I IFN and IFN-γ cause promoter binding of a complete ISGF3 complex containing STAT1, STAT2 and IRF9. In contrast to the dogmatic view of ISGF3 formation in the cytoplasm, our results suggest a model wherein the assembly of the ISGF3 complex occurs on DNA. 1 Max Perutz Labs (MPL), University of Vienna, Vienna 1030, Austria. 2 Institute of Animal Breeding and Genetics, University of Veterinary Medicine Vienna, Vienna 1210, Austria. 3 Institute of Molecular Biotechnology of the Austrian Academy of Sciences (IMBA), Vienna 1030, Austria. 4 Research Institute of Molecular Pathology (IMP), Vienna Biocenter (VBC), Vienna 1030, Austria. -

CD38, CD157, and RAGE As Molecular Determinants for Social Behavior
cells Review CD38, CD157, and RAGE as Molecular Determinants for Social Behavior Haruhiro Higashida 1,2,* , Minako Hashii 1,3, Yukie Tanaka 4, Shigeru Matsukawa 5, Yoshihiro Higuchi 6, Ryosuke Gabata 1, Makoto Tsubomoto 1, Noriko Seishima 1, Mitsuyo Teramachi 1, Taiki Kamijima 1, Tsuyoshi Hattori 7, Osamu Hori 7 , Chiharu Tsuji 1, Stanislav M. Cherepanov 1 , Anna A. Shabalova 1, Maria Gerasimenko 1, Kana Minami 1, Shigeru Yokoyama 1, Sei-ichi Munesue 8, Ai Harashima 8, Yasuhiko Yamamoto 8, Alla B. Salmina 1,2 and Olga Lopatina 2 1 Department of Basic Research on Social Recognition and Memory, Research Center for Child Mental Development, Kanazawa University, Kanazawa 920-8640, Japan; [email protected] (M.H.); [email protected] (R.G.); [email protected] (M.T.); [email protected] (N.S.); [email protected] (M.T.); [email protected] (T.K.); [email protected] (C.T.); [email protected] (S.M.C.); [email protected] (A.A.S.); [email protected] (M.G.); minami-k@staff.kanazawa-u.ac.jp (K.M.); [email protected] (S.Y.) 2 Laboratory of Social Brain Study, Research Institute of Molecular Medicine and Pathobiochemistry, Krasnoyarsk State Medical University named after Prof. V.F. Voino-Yasenetsky, Krasnoyarsk 660022, Russia; [email protected] (A.B.S.); [email protected] (O.L.) 3 Division of Molecular Genetics and Clinical Research, National Hospital Organization Nanao Hospital, Nanao 926-0841, Japan 4 Molecular Biology and Chemistry, Faculty of Medical Science, University of Fukui, Fukui -

32-6317: BST1 Human Description Product Info
9853 Pacific Heights Blvd. Suite D. San Diego, CA 92121, USA Tel: 858-263-4982 Email: [email protected] 32-6317: BST1 Human Bone Marrow Stromal Cell Antigen 1, ADP-Ribosyl Cyclase 2, Bone Marrow Stromal Antigen 1, Cyclic ADP- Alternative Ribose Hydrolase 2, NAD(+) Nucleosidase, CADPr Hydrolase 2, ADP-Ribosyl Cyclase/Cyclic ADP-Ribose Name : Hydrolase 2, CD157 Antigen, EC 3.2.2.6, CD157, BST-1, ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 2, ADP-ribosyl cyclase 2, Bone marrow stromal antigen 1, Cyclic ADP-ribose hydrolase 2, cADPr hydrolase 2. Description Source: Sf9, Baculovirus cells. Sterile filtered colorless solution. BST1 (Bone Marrow Stromal Cell Antigen 1), is a GPI (glycosylphosphatidylinositol) anchored membrane protein which is part of the CD38 family. BST1 was initially recognized as a bone marrow stromal cell molecule. BST1 is an ectoenzyme sharing more than a few features with ADP-ribosyl cyclase CD38. BST1 together with CD38, exhibit both DP-ribosyl cyclase and cyclinc ADP ribose hydrolase activities. BST1 participates in rheumatoid arthritis due to its enhanced expression in RA-derived bone marrow stromal cell lines. Moreover, BST1 is expressed by cells of the myeloid lineage and could perform as a receptor with a signal transduction capability. BST1 produced in Sf9 Baculovirus cells is a single, glycosylated polypeptide chain containing 267 amino acids (33-293a.a.) and having a molecular mass of 30.5kDa. (Molecular size on SDS-PAGE will appear at approximately 40-57kDa).BST1 is expressed with a 6 amino acid His tag at C-Terminus and purified by proprietary chromatographic techniques. -

929 Ectoenzymes and Innate Immunity: the Role of Human CD157
[Frontiers in Bioscience 14, 929-943, January 1, 2009] Ectoenzymes and innate immunity: the role of human CD157 in leukocyte trafficking Ada Funaro1,2, Erika Ortolan1,2, Paola Bovino1, Nicola Lo Buono1, Giulia Nacci1, Rossella Parrotta1, Enza Ferrero1,2, Fabio Malavasi1,2 1 Department of Genetics, Biology and Biochemistry, and 2Research Center on Experimental Medicine (CeRMS), University of Torino Medical School, Via Santena 19, 10126 Torino, Italy TABLE OF CONTENTS 1. Abstract 2. Introduction 3. CD157 and the ADPRC gene family 3.1. Phylogenetic analysis 3.2. CD157 and CD38 gene structure and regulation 3.3. Gene modifications underlie differences in NADase/ADPRC protein topology 3.4. CD157 protein structure 3.5. CD157 tissue distribution 3.6. CD157 expression during inflammation 4. CD157 functions 4.1. Enzymatic functions 4.2. Immunoregulatory functions 5. Role of CD157 in leukocyte trafficking. 5.1. Role of CD157 in neutrophil polarization 5.2. Functional and molecular interactions between CD157 and the CD11b/CD18 complex 5.3. Receptorial activities of CD157 on vascular endothelial cells 5.4. Role of CD157 in neutrophil transendothelial migration 5.5. Role of CD157 in neutrophil adhesion and chemotaxis 5.6. The Paroxysmal Nocturnal Hemoglobinuria (PNH) disease model 6. Summary and perspectives 7. Acknowledgments 8. References 1. ABSTRACT 2. INTRODUCTION CD157 is a glycosylphosphatidylinositol- CD157/BST-1 was originally identified as a anchored molecule encoded by a member of the surface molecule highly expressed by human bone marrow CD38/ADP-ribosyl cyclase gene family, involved in the (BM) stromal cell lines derived from patients with metabolism of NAD. Expressed mainly by cells of the rheumatoid arthritis (RA) (1). -
![Anti-CD157 / BST1 Antibody [SY11B5] (ARG65543)](https://docslib.b-cdn.net/cover/3019/anti-cd157-bst1-antibody-sy11b5-arg65543-763019.webp)
Anti-CD157 / BST1 Antibody [SY11B5] (ARG65543)
Product datasheet [email protected] ARG65543 Package: 100 μg anti-CD157 / BST1 antibody [SY11B5] Store at: -20°C Summary Product Description Mouse Monoclonal antibody [SY11B5] recognizes CD157 / BST1 Tested Reactivity Hu, NHuPrm Tested Application FACS, IHC-Fr, IP, WB Specificity The mouse monoclonal antibody SY11B5 recognizes CD157, an approximately 45 kDa GPIanchored protein expressed mainly on monocytes, macrophages, granulocytes and bone marrow stromal cells. Host Mouse Clonality Monoclonal Clone SY11B5 Isotype IgG1 Target Name CD157 / BST1 Species Human Immunogen Human CD157 Conjugation Un-conjugated Alternate Names cADPr hydrolase 2; ADP-ribosyl cyclase 2; Cyclic ADP-ribose hydrolase 2; BST-1; Bone marrow stromal antigen 1; CD157; ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 2; CD antigen CD157; EC 3.2.2.6 Application Instructions Application table Application Dilution FACS 1 - 12 µg/ml IHC-Fr 5 - 10 µg/ml IP Assay-dependent WB Assay-dependent Application Note WB: Under non-reducing condition. * The dilutions indicate recommended starting dilutions and the optimal dilutions or concentrations should be determined by the scientist. Properties Form Liquid Purification Purified from hybridoma culture supernatant by protein-A affinity chromatography. Purity > 95% (by SDS-PAGE) Buffer PBS (pH 7.4) and 15 mM Sodium azide Preservative 15 mM Sodium azide www.arigobio.com 1/2 Concentration 1 mg/ml Storage instruction For continuous use, store undiluted antibody at 2-8°C for up to a week. For long-term storage, aliquot and store at -20°C or below. Storage in frost free freezers is not recommended. Avoid repeated freeze/thaw cycles. Suggest spin the vial prior to opening. -

Multiomics of Azacitidine-Treated AML Cells Reveals Variable And
Multiomics of azacitidine-treated AML cells reveals variable and convergent targets that remodel the cell-surface proteome Kevin K. Leunga, Aaron Nguyenb, Tao Shic, Lin Tangc, Xiaochun Nid, Laure Escoubetc, Kyle J. MacBethb, Jorge DiMartinob, and James A. Wellsa,1 aDepartment of Pharmaceutical Chemistry, University of California, San Francisco, CA 94143; bEpigenetics Thematic Center of Excellence, Celgene Corporation, San Francisco, CA 94158; cDepartment of Informatics and Predictive Sciences, Celgene Corporation, San Diego, CA 92121; and dDepartment of Informatics and Predictive Sciences, Celgene Corporation, Cambridge, MA 02140 Contributed by James A. Wells, November 19, 2018 (sent for review August 23, 2018; reviewed by Rebekah Gundry, Neil L. Kelleher, and Bernd Wollscheid) Myelodysplastic syndromes (MDS) and acute myeloid leukemia of DNA methyltransferases, leading to loss of methylation in (AML) are diseases of abnormal hematopoietic differentiation newly synthesized DNA (10, 11). It was recently shown that AZA with aberrant epigenetic alterations. Azacitidine (AZA) is a DNA treatment of cervical (12, 13) and colorectal (14) cancer cells methyltransferase inhibitor widely used to treat MDS and AML, can induce interferon responses through reactivation of endoge- yet the impact of AZA on the cell-surface proteome has not been nous retroviruses. This phenomenon, termed viral mimicry, is defined. To identify potential therapeutic targets for use in com- thought to induce antitumor effects by activating and engaging bination with AZA in AML patients, we investigated the effects the immune system. of AZA treatment on four AML cell lines representing different Although AZA treatment has demonstrated clinical benefit in stages of differentiation. The effect of AZA treatment on these AML patients, additional therapeutic options are needed (8, 9). -

Integrated Weighted Gene Co-Expression Network Analysis Identi Ed That TLR2 and CD40 Are Related to Coronary Artery Disease
Integrated weighted gene co-expression network analysis identied that TLR2 and CD40 are related to coronary artery disease Bin Qi Liuzhou People's Hospital Jian-Hong Chen Liuzhou People's Hospital Lin Tao Liuzhou People's Hospital Chuan-Meng Zhu Liuzhou People's Hospital Yong Wang Liuzhou People's Hospital Guo-Xiong Deng The First People's of Nanning Liu Miao ( [email protected] ) LiuZhou People's Hospital https://orcid.org/0000-0001-6642-7005 Research article Keywords: Gene Expression Omnibus, Integrated weighted gene co-expression network analysis (WGCNA), Functional enrichment, Functional validation and prognostic analysis. Posted Date: October 7th, 2020 DOI: https://doi.org/10.21203/rs.3.rs-86115/v1 License: This work is licensed under a Creative Commons Attribution 4.0 International License. Read Full License Page 1/16 Abstract Background: The current research attempted to identify possible hub genes and pathways of coronary artery disease (CAD) and to detect the possible mechanisms. Methods: Array data from GSE90074 were downloaded from the Gene Expression Omnibus (GEO) database. Integrated weighted gene co-expression network analysis (WGCNA) was performed to analyze the gene module and clinical characteristics. Gene Ontology annotation, Disease Ontology and the Kyoto Encyclopedia of Genes and Genomes (KEGG) pathway enrichment analyses were performed by clusterProler and the DOSE package in R. A protein-protein interaction (PPI) network was established using Cytoscape software, and signicant modules were analyzed using Molecular Complex Detection to identify hub genes. Then, further functional validation of hub genes in other microarrays and population samples was performed, and survival analysis was performed to investigate the prognosis. -

Identification of Stage-Specific Surface Markers in Early B Cell
Identification of Stage-Specific Surface Markers in Early B Cell Development Provides Novel Tools for Identification of Progenitor Populations This information is current as of September 28, 2021. Christina T. Jensen, Stefan Lang, Rajesh Somasundaram, Shamit Soneji and Mikael Sigvardsson J Immunol published online 25 July 2016 http://www.jimmunol.org/content/early/2016/07/23/jimmun ol.1600297 Downloaded from Supplementary http://www.jimmunol.org/content/suppl/2016/07/23/jimmunol.160029 Material 7.DCSupplemental http://www.jimmunol.org/ Why The JI? Submit online. • Rapid Reviews! 30 days* from submission to initial decision • No Triage! Every submission reviewed by practicing scientists • Fast Publication! 4 weeks from acceptance to publication by guest on September 28, 2021 *average Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2016 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. Published July 25, 2016, doi:10.4049/jimmunol.1600297 The Journal of Immunology Identification of Stage-Specific Surface Markers in Early B Cell Development Provides Novel Tools for Identification of Progenitor Populations Christina T. Jensen,* Stefan Lang,* Rajesh Somasundaram,† Shamit Soneji,* and Mikael Sigvardsson*,† Whereas the characterization of B lymphoid progenitors has been facilitated by the identification of lineage- and stage-specific surface markers, the continued identification of differentially expressed proteins increases our capacity to explore normal and malignant B cell development. -

DNA Methylation 101: What Is Important to Know About DNA Methylation and Its Role in SLE Risk and Disease Heterogeneity
Review Lupus Sci Med: first published as 10.1136/lupus-2018-000285 on 25 July 2018. Downloaded from DNA methylation 101: what is important to know about DNA methylation and its role in SLE risk and disease heterogeneity Cristina M Lanata, Sharon A Chung, Lindsey A Criswell To cite: Lanata CM, Chung SA, ABSTRACT in gene regulation that lead to disease, and Criswell LA. DNA methylation SLE is a complex autoimmune disease that results from it has been hypothesised as a mechanism 101: what is important to the interplay of genetics, epigenetics and environmental contributing to the missing heritability of know about DNA methylation exposures. DNA methylation is an epigenetic mechanism and its role in SLE risk and SLE. Among all the epigenetic modifica- that regulates gene expression and tissue differentiation. disease heterogeneity. tions, DNA methylation perturbations have Among all the epigenetic modifications, DNA methylation Lupus Science & Medicine been the most widely studied in SLE.4 DNA perturbations have been the most widely studied in 2018;5:e000285. doi:10.1136/ methylation can be transmitted from parent lupus-2018-000285 SLE. It mediates processes relevant to SLE, including 5 lymphocyte development, X-chromosome inactivation to daughter cells, indicating that this form and the suppression of endogenous retroviruses. The of epigenetic modification could represent a Received 18 June 2018 establishment of most DNA methylation marks occurs molecular mediator capable of propagating Accepted 25 June 2018 in utero; however, a small percentage of epigenetic marks the memory of past cellular perturbations.6 In are dynamic and can change throughout a person’s this review, we summarise the current under- lifetime and in relation to exposures. -

Natural Killer Cell-Based Immunotherapy for Acute Myeloid Leukemia
Xu and Niu J Hematol Oncol (2020) 13:167 https://doi.org/10.1186/s13045-020-00996-x REVIEW Open Access Natural killer cell-based immunotherapy for acute myeloid leukemia Jing Xu and Ting Niu* Abstract Despite considerable progress has been achieved in the treatment of acute myeloid leukemia over the past decades, relapse remains a major problem. Novel therapeutic options aimed at attaining minimal residual disease-negative complete remission are expected to reduce the incidence of relapse and prolong survival. Natural killer cell-based immunotherapy is put forward as an option to tackle the unmet clinical needs. There have been an increasing num- ber of therapeutic dimensions ranging from adoptive NK cell transfer, chimeric antigen receptor-modifed NK cells, antibodies, cytokines to immunomodulatory drugs. In this review, we will summarize diferent forms of NK cell-based immunotherapy for AML based on preclinical investigations and clinical trials. Keywords: Acute myeloid leukemia, Natural killer cells, Immunotherapy, Adoptive NK cell transfer, Chimeric antigen receptor-modifed NK cells, Antibodies, Cytokines Background cells and substances in the immune system play pivotal Acute myeloid leukemia (AML) is a clinically and geneti- roles in detecting and destroying pathogen-infected or cally heterogeneous disease with unsatisfactory out- neoplastically transformed cells. But they become less comes. Over the last few years, considerable progress has potent in cancer elimination when malignant cells dis- been achieved in the treatment of AML with the devel- play the loss of antigenicity and/or immunogenicity and opment and implementation of new drugs [1, 2]. How- are surrounded by an immunosuppressive microenvi- ever, allogeneic hematopoietic cell transplantation (HCT) ronment [6].