Introducing a Dark Web Archival Framework
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Evolving Threat the Deep Web
8 An Evolving Threat The Deep Web Learning Objectives distribute 1. Explain the differences between the deep web and darknets.or 2. Understand how the darknets are accessed. 3. Discuss the hidden wiki and how it is useful to criminals. 4. Understand the anonymity offered by the deep web. 5. Discuss the legal issues associated withpost, use of the deep web and the darknets. The action aimed to stop the sale, distribution and promotion of illegal and harmful items, including weapons and drugs, which were being sold on online ‘dark’ marketplaces. Operation Onymous, coordinated by Europol’s Europeancopy, Cybercrime Centre (EC3), the FBI, the U.S. Immigration and Customs Enforcement (ICE), Homeland Security Investigations (HSI) and Eurojust, resulted in 17 arrests of vendors andnot administrators running these online marketplaces and more than 410 hidden services being taken down. In addition, bitcoins worth approximately USD 1 million, EUR 180,000 Do in cash, drugs, gold and silver were seized. —Europol, 20141 143 Copyright ©2018 by SAGE Publications, Inc. This work may not be reproduced or distributed in any form or by any means without express written permission of the publisher. 144 Cyberspace, Cybersecurity, and Cybercrime THINK ABOUT IT 8.1 Surface Web and Deep Web Google, Facebook, and any website you can What Would You Do? find via traditional search engines (Internet Explorer, Chrome, Firefox, etc.) are all located 1. The deep web offers users an anonym- on the surface web. It is likely that when you ity that the surface web cannot provide. use the Internet for research and/or social What would you do if you knew that purposes you are using the surface web. -

A Framework for Identifying Host-Based Artifacts in Dark Web Investigations
Dakota State University Beadle Scholar Masters Theses & Doctoral Dissertations Fall 11-2020 A Framework for Identifying Host-based Artifacts in Dark Web Investigations Arica Kulm Dakota State University Follow this and additional works at: https://scholar.dsu.edu/theses Part of the Databases and Information Systems Commons, Information Security Commons, and the Systems Architecture Commons Recommended Citation Kulm, Arica, "A Framework for Identifying Host-based Artifacts in Dark Web Investigations" (2020). Masters Theses & Doctoral Dissertations. 357. https://scholar.dsu.edu/theses/357 This Dissertation is brought to you for free and open access by Beadle Scholar. It has been accepted for inclusion in Masters Theses & Doctoral Dissertations by an authorized administrator of Beadle Scholar. For more information, please contact [email protected]. A FRAMEWORK FOR IDENTIFYING HOST-BASED ARTIFACTS IN DARK WEB INVESTIGATIONS A dissertation submitted to Dakota State University in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Cyber Defense November 2020 By Arica Kulm Dissertation Committee: Dr. Ashley Podhradsky Dr. Kevin Streff Dr. Omar El-Gayar Cynthia Hetherington Trevor Jones ii DISSERTATION APPROVAL FORM This dissertation is approved as a credible and independent investigation by a candidate for the Doctor of Philosophy in Cyber Defense degree and is acceptable for meeting the dissertation requirements for this degree. Acceptance of this dissertation does not imply that the conclusions reached by the candidate are necessarily the conclusions of the major department or university. Student Name: Arica Kulm Dissertation Title: A Framework for Identifying Host-based Artifacts in Dark Web Investigations Dissertation Chair: Date: 11/12/20 Committee member: Date: 11/12/2020 Committee member: Date: Committee member: Date: Committee member: Date: iii ACKNOWLEDGMENT First, I would like to thank Dr. -

Web Archiving Supplementary Guidelines
LIBRARY OF CONGRESS COLLECTIONS POLICY STATEMENTS SUPPLEMENTARY GUIDELINES Web Archiving Contents I. Scope II. Current Practice III. Research Strengths IV. Collecting Policy I. Scope The Library's traditional functions of acquiring, cataloging, preserving and serving collection materials of historical importance to Congress and the American people extend to digital materials, including web sites. The Library acquires and makes permanently accessible born digital works that are playing an increasingly important role in the intellectual, commercial and creative life of the United States. Given the vast size and growing comprehensiveness of the Internet, as well as the short life‐span of much of its content, the Library must: (1) define the scope and priorities for its web collecting, and (2) develop partnerships and cooperative relationships required to continue fulfilling its vital historic mission in order to supplement the Library’s capacity. The contents of a web site may range from ephemeral social media content to digital versions of formal publications that are also available in print. Web archiving preserves as much of the web‐based user experience as technologically possible in order to provide future users accurate snapshots of what particular organizations and individuals presented on the archived sites at particular moments in time, including how the intellectual content (such as text) is framed by the web site implementation. The guidelines in this document apply to the Library’s effort to acquire web sites and related content via harvesting in‐house, through contract services and purchase. It also covers collaborative web archiving efforts with external groups, such as the International Internet Preservation Consortium (IIPC). -

Monitoring the Dark Web and Securing Onion Services
City University of New York (CUNY) CUNY Academic Works Publications and Research Queensborough Community College 2017 Monitoring the Dark Web and Securing Onion Services John Schriner CUNY Queensborough Community College How does access to this work benefit ou?y Let us know! More information about this work at: https://academicworks.cuny.edu/qb_pubs/41 Discover additional works at: https://academicworks.cuny.edu This work is made publicly available by the City University of New York (CUNY). Contact: [email protected] Monitoring the Dark Web Schriner 1 John Schriner Monitoring the Dark Web Contrary to what one may expect to read with a title like Monitoring the Dark Web, this paper will focus less on how law enforcement works to monitor hidden web sites and services and focus more on how academics and researchers monitor this realm. The paper is divided into three parts: Part One discusses Tor research and how onion services work; Part Two discusses tools that researchers use to monitor the dark web; Part Three tackles the technological, ethical, and social interests at play in securing the dark web. Part One: Tor is Research-Driven Tor (an acronym for 'the onion router' now stylized simply 'Tor') is an anonymity network in which a user of the Tor Browser connects to a website via three hops: a guard node, a middle relay, and an exit node. The connection is encrypted with three layers, stripping a layer at each hop towards its destination server. No single node has the full picture of the connection along the circuit: the guard knows only your IP but not where the destination is; the middle node knows the guard and the exit node; the exit node knows only the middle node and the final destination. -

Web Archiving and You Web Archiving and Us
Web Archiving and You Web Archiving and Us Amy Wickner University of Maryland Libraries Code4Lib 2018 Slides & Resources: https://osf.io/ex6ny/ Hello, thank you for this opportunity to talk about web archives and archiving. This talk is about what stakes the code4lib community might have in documenting particular experiences of the live web. In addition to slides, I’m leading with a list of material, tools, and trainings I read and relied on in putting this talk together. Despite the limited scope of the talk, I hope you’ll each find something of personal relevance to pursue further. “ the process of collecting portions of the World Wide Web, preserving the collections in an archival format, and then serving the archives for access and use International Internet Preservation Coalition To begin, here’s how the International Internet Preservation Consortium or IIPC defines web archiving. Let’s break this down a little. “Collecting portions” means not collecting everything: there’s generally a process of selection. “Archival format” implies that long-term preservation and stewardship are the goals of collecting material from the web. And “serving the archives for access and use” implies a stewarding entity conceptually separate from the bodies of creators and users of archives. It also implies that there is no web archiving without access and use. As we go along, we’ll see examples that both reinforce and trouble these assumptions. A point of clarity about wording: when I say for example “critique,” “question,” or “trouble” as a verb, I mean inquiry rather than judgement or condemnation. we are collectors So, preambles mostly over. -

情報管理 O U R Nal of Information Pr Ocessing and Managemen T December
JOHO KANRI 2009 vol.52 no.9 http://johokanri.jp/ J情報管理 o u r nal of Information Pr ocessing and Managemen t December 世界の知識の図書館を目指すInternet Archive 創設者Brewster Kahleへのインタビュー Internet Archive aims to build a library of world knowledge An interview with the founder, Brewster Kahle 時実 象一1 TOKIZANE Soichi1 1 愛知大学文学部(〒441-8522 愛知県豊橋市町畑町1-1)E-mail : [email protected] 1 Faculty of Letters, Aichi University (1-1 Machihata-cho Toyohashi-shi, Aichi 441-8522) 原稿受理(2009-09-25) (情報管理 52(9), 534-542) 著者抄録 Internet ArchiveはBrewster Kahleによって1996年に設立された非営利団体で,過去のインターネットWebサイトを保存し ているWayback Machineで知られているほか,動画,音楽,音声の電子アーカイブを公開し,またGoogleと同様書籍の電 子化を行っている。Wayback Machineは1996年からの5,000万サイトに対応する1,500億ページのデータを保存・公開し ている。書籍の電子化はScribeと呼ばれる独自開発の撮影機を用い,ボストン公共図書館などと協力して1日1,000冊の ペースで電子化している。電子化したデータを用いて子供たちに本を配るBookmobileという活動も行っている。Kahle氏 はGoogle Book Searchの和解に批判的な意見を述べているほか,孤児著作物の利用促進やOne Laptop Per Child(OLPC)運 動への協力も行っている。 キーワード Webアーカイブ,Wayback Machine,書籍電子化,Google Book Search,新アレキサンドリア図書館,Open Content Alliance,Open Book Alliance 1. はじめに Googleと同様書籍の電子化を行っている。インター ネットが一般に使えるようになったのが1995年で Internet Archive注1)はBrewster Kahle(ケールと発 あるから,Internet Archiveはインターネットとほぼ 音する)によって1996年に設立された非営利団体 同時に誕生したことになる。現在年間運営費は約 である。過去のインターネットW e bサイトを保存 1,000万ドルであり,政府や財団の補助や寄付で運 しているWayback Machine1)で知られているほか, 営している。この(2009年)5月にKahle氏(以下敬 534 JOHO KANRI 世界の知識の図書館を目指すInternet Archive 2009 vol.52 no.9 http://johokanri.jp/ J情報管理 o u r nal of Information Pr ocessing and Managemen t December 称略)を訪ね,インタビューを行ったので報告する A O Lに売却した。その売却益によって翌年I n t e r n e t (写真1)。 Archiveを立ち上げたのである。 K a h l eは1982年 に マ サ チ ュ ー セ ッ ツ 工 科 大 学 (Massachusetts Institute of Technology: MIT)のコン 2. Internet Archiveの事業 ピュータ科学工学科を卒業した。 2000年前エジプトのアレキサンドリアには当時 2.1 Wayback Machine 世界最大の図書館があり,パピルスに書かれた書物 I n t e r n e t A r c h i v eのホームページのU R Lはw w w . -

Dark Web Monitoring
Dark Web Monitoring: What You Should Know You may see ads for identity theft services claiming that they will look for your Social Security number, credit card numbers, or other personal information for sale on the “dark web.” Do you know what these services do if they find it? In a survey commissioned by Consumer Federation of America, 36 percent of people who have seen these “dark web monitoring” ads believed that these services could remove their personal information from the dark web, and 37 percent thought they could prevent the information that’s sold on the dark web from being used. In reality, neither is true! Here is what you need to know about the dark web, how identity theft services work, and what you can do if your personal information is in danger. What is the dark web? Picture the internet as an iceberg. The part above the water is the “surface web,” where you can find webpages using search engines such as Google or Bing. The part of the iceberg under the water is the “deep web.” Search engines won’t bring you to the pages here. This is where you are when you sign into your bank account online with your username and password. It’s where the content is beyond paywalls. It’s where you communicate with other people through social media, chat services and messaging platforms. The deep web also houses large databases and many other things. It is a significantly bigger chunk of the internet than the surface web. The “dark web” is a small part of the deep web. -

Exploration of Ultimate Dark Web Anonymization, Privacy, and Security Revanth S1, Praveen Kumar Pandey2 1, 2Department of MCA, Jain University
International Journal for Research in Applied Science & Engineering Technology (IJRASET) ISSN: 2321-9653; IC Value: 45.98; SJ Impact Factor: 7.429 Volume 8 Issue IV Apr 2020- Available at www.ijraset.com Exploration of ultimate Dark Web Anonymization, Privacy, and Security Revanth S1, Praveen Kumar Pandey2 1, 2Department of MCA, Jain University Abstract: The ultimate Dark web will review the emerging research conducted to study and identify the ins and outs of the dark web. The world is facing a lot of issues day-by-day especially on the internet. Now I have a question here, do you think is working with the internet attains knowledge or it pretends to be a part of the business. Keep the business part aside, we all know that internet is a great tool for communication. Is internet is definitely giving privacy, safety and security. Does anyone have a brief idea about the dark web for all these queries we don’t have any accurate solution. Through this survey, I outlined some of the major concepts and their dependencies the primary usage of the dark web and some of the survey experiences are further documented in this paper. Keywords: Darkweb, Security, Anonymity, Privacy, Cryptocurrencies, Blockchains, Tails, Qubes, Tor network. I. INTRODUCTION The Internet is the world's strongest and widest power. Without the internet more than the world’s 85% of the tasks will get struggled because the earth is totally dependent on network chains. Internet helps in worlds most of the leading departments like Research Centres, Hospitals, Corporate Industries, Education Institutions etc., So, with this evergreen technology, we definitely need to think about our privacy and security as a most prior concern. -

Web Archives for the Analog Archivist: Using Webpages Archived by the Internet Archive to Improve Processing and Description
Journal of Western Archives Volume 9 Issue 1 Article 6 2018 Web Archives for the Analog Archivist: Using Webpages Archived by the Internet Archive to Improve Processing and Description Aleksandr Gelfand New-York Historical Society, [email protected] Follow this and additional works at: https://digitalcommons.usu.edu/westernarchives Part of the Archival Science Commons Recommended Citation Gelfand, Aleksandr (2018) "Web Archives for the Analog Archivist: Using Webpages Archived by the Internet Archive to Improve Processing and Description," Journal of Western Archives: Vol. 9 : Iss. 1 , Article 6. DOI: https://doi.org/10.26077/4944-b95b Available at: https://digitalcommons.usu.edu/westernarchives/vol9/iss1/6 This Case Study is brought to you for free and open access by the Journals at DigitalCommons@USU. It has been accepted for inclusion in Journal of Western Archives by an authorized administrator of DigitalCommons@USU. For more information, please contact [email protected]. Gelfand: Web Archives for the Analog Archivist Web Archives for the Analog Archivist: Using Webpages Archived by the Internet Archive to Improve Processing and Description Aleksandr Gelfand ABSTRACT Twenty years ago the Internet Archive was founded with the wide-ranging mission of providing universal access to all knowledge. In the two decades since, that organization has captured and made accessible over 150 billion websites. By incorporating the use of Internet Archive's Wayback Machine into their workflows, archivists working primarily with analog records may enhance their ability in such tasks as the construction of a processing plan, the creation of more accurate historical descriptions for finding aids, and potentially be able to provide better reference services to their patrons. -
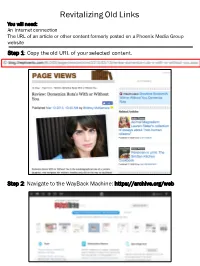
Wayback Machine Instructions
Revitalizing Old Links You will need: An Internet connection The URL of an article or other content formerly posted on a Phoenix Media Group website Step 1: Copy the old URL of your selected content. Step 2: Navigate to the WayBack Machine: https://archive.org/web Step 3: Input the copied URL of your content into the search box on the Wayback Machine home page. Hit Enter or click “Browse History”. Step 4: The WayBack Machine will retrieve a page that displays the original URL of your content, the number of times that content has been captured by the WayBack Machine, and a calendar. If you would like to access the most recently captured version of the content, click the most recent “snapshot” date on the calendar (dates on which the content was captured are marked with blue circles). If the content has been edited or changed and you would like to access an older saved version, navigate through the calendar to your desired “snapshot” date. Select the most recent save date to view the most recently saved Select the year, then version of the month and date to view content. an older version of the content. Black bars indicate years in which the content was captured. Step 5: The WayBack Machine will redirect you to the preserved snapshot of the page from the date you selected. Please note that some original content, such as advertisements, JavaScript or Flash videos, may not be saved. This URL directs to the saved version of the material; replace any outdated links to the content with this URL. -

Cybercrime in the Deep Web Black Hat EU, Amsterdam 2015
Cybercrime in the Deep Web Black Hat EU, Amsterdam 2015 Introduction The Deep Web is any Internet content that, for various reasons, cannot be or is not indexed by search engines like Google. This definition thus includes dynamic web pages, blocked sites (like those where you need to answer a CAPTCHA to access), unlinked sites, private sites (like those that require login credentials), non-HTML/contextual/scripted content, and limited-access networks. Limited-access networks cover sites with domain names that have been registered on Domain Name System (DNS) roots that are not managed by the Internet Corporation for Assigned Names and Numbers (ICANN), like .BIT domains, sites that are running on standard DNS but have non-standard top-level domains, and finally, darknets. Darknets are sites hosted on infrastructure that requires specific software like Tor before it can be accessed. Much of the public interest in the Deep Web lies in the activities that happen inside darknets. What are the Uses of the Deep Web? A smart person buying recreational drugs online will not want to type keywords in a regular browser. He/she will need to go online anonymously, using an infrastructure that will never lead interested parties to his IP address or physical location. Drug sellers as well, will not want to set up shop in online locations where law enforcement can easily determine, for instance, who registered that domain or where the site’s IP address exists in the real world. There are many other reasons apart from buying drugs why people would want to remain anonymous, or to set up sites that could not be traced back to a physical location or entity. -

The Future of Web Citation Practices
City University of New York (CUNY) CUNY Academic Works Publications and Research John Jay College of Criminal Justice 2016 The Future of Web Citation Practices Robin Camille Davis CUNY John Jay College How does access to this work benefit ou?y Let us know! More information about this work at: https://academicworks.cuny.edu/jj_pubs/117 Discover additional works at: https://academicworks.cuny.edu This work is made publicly available by the City University of New York (CUNY). Contact: [email protected] This is an electronic version (preprint) of an article published in Behavioral and Social Sciences Librarian. The article is available online at http://dx.doi.org/10.1080/01639269.2016.1241122 (subscription required). Full citation: Davis, R. “The Future of Web Citation Practices (Internet Connection Column).” Behavioral & Social Sciences Librarian 35.3 (2016): 128-134. Web. Internet Connection The Future of Web Citation Practices Robin Camille Davis Abstract: Citing webpages has been a common practice in scholarly publications for nearly two decades as the Web evolved into a major information source. But over the years, more and more bibliographies have suffered from “reference rot”: cited URLs are broken links or point to a page that no longer contains the content the author originally cited. In this column, I look at several studies showing how reference rot has affected different academic disciplines. I also examine citation styles’ approach to citing web sources. I then turn to emerging web citation practices: Perma, a “freemium” web archiving service specifically for citation; and the Internet Archive, the largest web archive. Introduction There’s a new twist on an old proverb: You cannot step in the same Web twice.