Web Archiving Programs in the U.S
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Web Archiving Supplementary Guidelines
LIBRARY OF CONGRESS COLLECTIONS POLICY STATEMENTS SUPPLEMENTARY GUIDELINES Web Archiving Contents I. Scope II. Current Practice III. Research Strengths IV. Collecting Policy I. Scope The Library's traditional functions of acquiring, cataloging, preserving and serving collection materials of historical importance to Congress and the American people extend to digital materials, including web sites. The Library acquires and makes permanently accessible born digital works that are playing an increasingly important role in the intellectual, commercial and creative life of the United States. Given the vast size and growing comprehensiveness of the Internet, as well as the short life‐span of much of its content, the Library must: (1) define the scope and priorities for its web collecting, and (2) develop partnerships and cooperative relationships required to continue fulfilling its vital historic mission in order to supplement the Library’s capacity. The contents of a web site may range from ephemeral social media content to digital versions of formal publications that are also available in print. Web archiving preserves as much of the web‐based user experience as technologically possible in order to provide future users accurate snapshots of what particular organizations and individuals presented on the archived sites at particular moments in time, including how the intellectual content (such as text) is framed by the web site implementation. The guidelines in this document apply to the Library’s effort to acquire web sites and related content via harvesting in‐house, through contract services and purchase. It also covers collaborative web archiving efforts with external groups, such as the International Internet Preservation Consortium (IIPC). -

Web Archiving and You Web Archiving and Us
Web Archiving and You Web Archiving and Us Amy Wickner University of Maryland Libraries Code4Lib 2018 Slides & Resources: https://osf.io/ex6ny/ Hello, thank you for this opportunity to talk about web archives and archiving. This talk is about what stakes the code4lib community might have in documenting particular experiences of the live web. In addition to slides, I’m leading with a list of material, tools, and trainings I read and relied on in putting this talk together. Despite the limited scope of the talk, I hope you’ll each find something of personal relevance to pursue further. “ the process of collecting portions of the World Wide Web, preserving the collections in an archival format, and then serving the archives for access and use International Internet Preservation Coalition To begin, here’s how the International Internet Preservation Consortium or IIPC defines web archiving. Let’s break this down a little. “Collecting portions” means not collecting everything: there’s generally a process of selection. “Archival format” implies that long-term preservation and stewardship are the goals of collecting material from the web. And “serving the archives for access and use” implies a stewarding entity conceptually separate from the bodies of creators and users of archives. It also implies that there is no web archiving without access and use. As we go along, we’ll see examples that both reinforce and trouble these assumptions. A point of clarity about wording: when I say for example “critique,” “question,” or “trouble” as a verb, I mean inquiry rather than judgement or condemnation. we are collectors So, preambles mostly over. -

情報管理 O U R Nal of Information Pr Ocessing and Managemen T December
JOHO KANRI 2009 vol.52 no.9 http://johokanri.jp/ J情報管理 o u r nal of Information Pr ocessing and Managemen t December 世界の知識の図書館を目指すInternet Archive 創設者Brewster Kahleへのインタビュー Internet Archive aims to build a library of world knowledge An interview with the founder, Brewster Kahle 時実 象一1 TOKIZANE Soichi1 1 愛知大学文学部(〒441-8522 愛知県豊橋市町畑町1-1)E-mail : [email protected] 1 Faculty of Letters, Aichi University (1-1 Machihata-cho Toyohashi-shi, Aichi 441-8522) 原稿受理(2009-09-25) (情報管理 52(9), 534-542) 著者抄録 Internet ArchiveはBrewster Kahleによって1996年に設立された非営利団体で,過去のインターネットWebサイトを保存し ているWayback Machineで知られているほか,動画,音楽,音声の電子アーカイブを公開し,またGoogleと同様書籍の電 子化を行っている。Wayback Machineは1996年からの5,000万サイトに対応する1,500億ページのデータを保存・公開し ている。書籍の電子化はScribeと呼ばれる独自開発の撮影機を用い,ボストン公共図書館などと協力して1日1,000冊の ペースで電子化している。電子化したデータを用いて子供たちに本を配るBookmobileという活動も行っている。Kahle氏 はGoogle Book Searchの和解に批判的な意見を述べているほか,孤児著作物の利用促進やOne Laptop Per Child(OLPC)運 動への協力も行っている。 キーワード Webアーカイブ,Wayback Machine,書籍電子化,Google Book Search,新アレキサンドリア図書館,Open Content Alliance,Open Book Alliance 1. はじめに Googleと同様書籍の電子化を行っている。インター ネットが一般に使えるようになったのが1995年で Internet Archive注1)はBrewster Kahle(ケールと発 あるから,Internet Archiveはインターネットとほぼ 音する)によって1996年に設立された非営利団体 同時に誕生したことになる。現在年間運営費は約 である。過去のインターネットW e bサイトを保存 1,000万ドルであり,政府や財団の補助や寄付で運 しているWayback Machine1)で知られているほか, 営している。この(2009年)5月にKahle氏(以下敬 534 JOHO KANRI 世界の知識の図書館を目指すInternet Archive 2009 vol.52 no.9 http://johokanri.jp/ J情報管理 o u r nal of Information Pr ocessing and Managemen t December 称略)を訪ね,インタビューを行ったので報告する A O Lに売却した。その売却益によって翌年I n t e r n e t (写真1)。 Archiveを立ち上げたのである。 K a h l eは1982年 に マ サ チ ュ ー セ ッ ツ 工 科 大 学 (Massachusetts Institute of Technology: MIT)のコン 2. Internet Archiveの事業 ピュータ科学工学科を卒業した。 2000年前エジプトのアレキサンドリアには当時 2.1 Wayback Machine 世界最大の図書館があり,パピルスに書かれた書物 I n t e r n e t A r c h i v eのホームページのU R Lはw w w . -

Web Archives for the Analog Archivist: Using Webpages Archived by the Internet Archive to Improve Processing and Description
Journal of Western Archives Volume 9 Issue 1 Article 6 2018 Web Archives for the Analog Archivist: Using Webpages Archived by the Internet Archive to Improve Processing and Description Aleksandr Gelfand New-York Historical Society, [email protected] Follow this and additional works at: https://digitalcommons.usu.edu/westernarchives Part of the Archival Science Commons Recommended Citation Gelfand, Aleksandr (2018) "Web Archives for the Analog Archivist: Using Webpages Archived by the Internet Archive to Improve Processing and Description," Journal of Western Archives: Vol. 9 : Iss. 1 , Article 6. DOI: https://doi.org/10.26077/4944-b95b Available at: https://digitalcommons.usu.edu/westernarchives/vol9/iss1/6 This Case Study is brought to you for free and open access by the Journals at DigitalCommons@USU. It has been accepted for inclusion in Journal of Western Archives by an authorized administrator of DigitalCommons@USU. For more information, please contact [email protected]. Gelfand: Web Archives for the Analog Archivist Web Archives for the Analog Archivist: Using Webpages Archived by the Internet Archive to Improve Processing and Description Aleksandr Gelfand ABSTRACT Twenty years ago the Internet Archive was founded with the wide-ranging mission of providing universal access to all knowledge. In the two decades since, that organization has captured and made accessible over 150 billion websites. By incorporating the use of Internet Archive's Wayback Machine into their workflows, archivists working primarily with analog records may enhance their ability in such tasks as the construction of a processing plan, the creation of more accurate historical descriptions for finding aids, and potentially be able to provide better reference services to their patrons. -
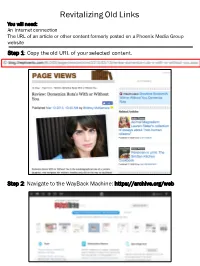
Wayback Machine Instructions
Revitalizing Old Links You will need: An Internet connection The URL of an article or other content formerly posted on a Phoenix Media Group website Step 1: Copy the old URL of your selected content. Step 2: Navigate to the WayBack Machine: https://archive.org/web Step 3: Input the copied URL of your content into the search box on the Wayback Machine home page. Hit Enter or click “Browse History”. Step 4: The WayBack Machine will retrieve a page that displays the original URL of your content, the number of times that content has been captured by the WayBack Machine, and a calendar. If you would like to access the most recently captured version of the content, click the most recent “snapshot” date on the calendar (dates on which the content was captured are marked with blue circles). If the content has been edited or changed and you would like to access an older saved version, navigate through the calendar to your desired “snapshot” date. Select the most recent save date to view the most recently saved Select the year, then version of the month and date to view content. an older version of the content. Black bars indicate years in which the content was captured. Step 5: The WayBack Machine will redirect you to the preserved snapshot of the page from the date you selected. Please note that some original content, such as advertisements, JavaScript or Flash videos, may not be saved. This URL directs to the saved version of the material; replace any outdated links to the content with this URL. -

The Future of Web Citation Practices
City University of New York (CUNY) CUNY Academic Works Publications and Research John Jay College of Criminal Justice 2016 The Future of Web Citation Practices Robin Camille Davis CUNY John Jay College How does access to this work benefit ou?y Let us know! More information about this work at: https://academicworks.cuny.edu/jj_pubs/117 Discover additional works at: https://academicworks.cuny.edu This work is made publicly available by the City University of New York (CUNY). Contact: [email protected] This is an electronic version (preprint) of an article published in Behavioral and Social Sciences Librarian. The article is available online at http://dx.doi.org/10.1080/01639269.2016.1241122 (subscription required). Full citation: Davis, R. “The Future of Web Citation Practices (Internet Connection Column).” Behavioral & Social Sciences Librarian 35.3 (2016): 128-134. Web. Internet Connection The Future of Web Citation Practices Robin Camille Davis Abstract: Citing webpages has been a common practice in scholarly publications for nearly two decades as the Web evolved into a major information source. But over the years, more and more bibliographies have suffered from “reference rot”: cited URLs are broken links or point to a page that no longer contains the content the author originally cited. In this column, I look at several studies showing how reference rot has affected different academic disciplines. I also examine citation styles’ approach to citing web sources. I then turn to emerging web citation practices: Perma, a “freemium” web archiving service specifically for citation; and the Internet Archive, the largest web archive. Introduction There’s a new twist on an old proverb: You cannot step in the same Web twice. -

The Dbpedia Wayback Machine ∗
The DBpedia Wayback Machine ∗ Javier D. Fernández Patrik Schneider Jürgen Umbrich Vienna University of Vienna University of Vienna University of Economics and Business, Economics and Business, Economics and Business, Vienna, Austria Vienna, Austria Vienna, Austria [email protected] [email protected] [email protected] ABSTRACT Web and provides these time-preserved website snapshots DBpedia is one of the biggest and most important focal point for open use. The wayback mechanism offers access to the of the Linked Open Data movement. However, in spite of its history of a document and enables several new use cases and multiple services, it lacks a wayback mechanism to retrieve supports different research areas. For instance, one can ex- historical versions of resources at a given timestamp in the tract historical data and capture the “Zeitgeist” of a culture, past, thus preventing systems to work on the full history or use the data to study evolutionary patterns. Previous of RDF documents. In this paper, we present a framework works on providing time-travel mechanism in DBpedia, such that serves this mechanism and is publicly offered through as [6], focus on archiving different snapshots of the dumps and serve these by means of the memento protocol (RFC a Web UI and a RESTful API, following the Linked Open 4 Data principles. 7089) , an HTTP content negotiation to navigate trough available snapshots. Although thisa perfectly merges the ex- isting time-travel solution for WWW and DBpedia dumps, 1. INTRODUCTION it is certainly restricted to pre-fetched versions than must DBpedia is one of the biggest cross-domain datasets in be archived beforehand. -

Partnership Opportunities with the Internet Archive Web Archiving in Libraries October 21, 2020
Partnership Opportunities with the Internet Archive Web archiving in libraries October 21, 2020 Karl-Rainer Blumenthal Web Archivist, Internet Archive Web archiving is the process of collecting, preserving, and enabling access to web-published materials. Average lifespan of a webpage 92 days WEB ARCHIVING crawler replay app W/ARC WEB ARCHIVING TECHNOLOGY Brozzler Heritrix ARC HTTrack WARC warcprox wget Wayback Machine OpenWayback pywb wab.ac oldweb.today WEB ARCHIVING TECHNOLOGY Brozzler Heritrix ARC HTTrack WARC warcprox wget Archive-It Wayback Machine NetarchiveSuite (DK/FR) OpenWayback PANDAS (AUS) pywb Web Curator (UK/NZ) wab.ac Webrecorder oldweb.today WEB ARCHIVING The Wayback Machine The largest publicly available web archive in existence. https://archive.org/web/ > 300 Billion Web Pages > 100 million websites > 150 languages ~ 1 billion URLs added per week WEB ARCHIVING The Wayback Machine The largest publicly available web archive in existence. https://archive.org/web/ > 300 Billion Web Pages > 100 million websites > 150 languages ~ 1 billion URLs added per week WEB ARCHIVING The Wayback Machine Limitations: Lightly curated Completeness Temporal cohesion Access: No full-text search No descriptive metadata Access by URL only ARCHIVE-IT Archive-It https://archive-it.org Curator controlled > 700 partner organizations ~ 2 PB of web data collected Full text and metadata searchable APIs for archives, metadata, search, &c. ARCHIVE-IT COLLECTIONS ARCHIVE-IT PARTNERS WEB ARCHIVES AS DATA WEB ARCHIVES AS DATA WEB ARCHIVES AS DATA WEB ARCHIVES AS DATA WEB ARCHIVES AS (GOV) DATA WEB ARCHIVE ACCESSIBILITY WEB ARCHIVE ACCESSIBILITY WEB ARCHIVING COLLABORATION FDLP Libraries WEB ARCHIVING COLLABORATION FDLP Libraries Archive-It partners THANKS <3 ...and keep in touch! Karl-Rainer Blumenthal Web Archivist, Internet Archive [email protected] [email protected] Partnership Opportunities with Internet Archive Andrea Mills – Digitization Program Manager, Internet Archive 1. -

Functionalities of Web Archives
University of South Florida Scholar Commons School of Information Faculty Publications School of Information 3-2012 Functionalities of Web Archives Authors: Jinfang Niu The functionalities that are important to the users of web archives range from basic searching and browsing to advanced personalized and customized services, data mining, and website reconstruction. The uthora examined ten of the most established English language web archives to determine which functionalities each of the archives supported, and how they compared. A functionality checklist was designed, based on use cases created by the International Internet Preservation Consortium (IIPC), and the findings of two related user studies. The functionality review was conducted, along with a comprehensive literature review of web archiving methods, in preparation for the development of a web archiving course for Library and Information School students. This paper describes the functionalities used in the checklist, the extent to which those functionalities are implemented by the various archives, and discusses the author's findings. Follow this and additional works at: http://scholarcommons.usf.edu/si_facpub Part of the Archival Science Commons Scholar Commons Citation Niu, Jinfang, "Functionalities of Web Archives" (2012). School of Information Faculty Publications. 309. http://scholarcommons.usf.edu/si_facpub/309 This Article is brought to you for free and open access by the School of Information at Scholar Commons. It has been accepted for inclusion in School of Information Faculty Publications by an authorized administrator of Scholar Commons. For more information, please contact [email protected]. D‐Lib Magazine March/April 2012 Volume 18, Number 3/4 Functionalities of Web Archives Jinfang Niu University of South Florida [email protected] doi:10.1045/march2012‐niu2 Abstract The functionalities that are important to the users of web archives range from basic searching and browsing to advanced personalized and customized services, data mining, and website reconstruction. -

Using Wayback Machine for Research
Using Wayback Machine for Research Nicholas Taylor Repository Development Group What Is the WAYBACK MACHINE? WABAC Machine? Internet Archive’s Wayback Machine not one, but many Wayback Machines . open source software to “replay” web archives . rewrites links to point to archived resources . allows for temporal navigation within archive . used by many web archiving institutions . 33 out of 62 initiatives listed on Wikipedia Government of Canada Web Archive Government of Canada Web Archive Portuguese Web Archive Web Archive Singapore Web Archive Singapore Catalonian Web Archive Catalonian Web Archive California Digital Library Web Archiving Service Harvard University Web Archive Collection Service Common LIMITATIONS AND WORKAROUNDS limitation: banner displaces page elements workaround: hide the banner limitation: AJAX-enabled sites limitation: AJAX-enabled sites workaround: disable JavaScript limitation: nav menu link errors workaround: insert live site URL in archive workaround: insert live site URL in archive workaround: insert live site URL in archive limitation: no full-text search workaround: none yet, but R&D ongoing Basic MECHANICS structure of a Wayback Machine URL http://webarchiveqr.loc.gov/loc_sites/20120131201510/http://www.loc.gov/index.html Wayback Machine URL collection date/timestamp URL of archived (YYYYMMDDHHMMSS) resource URL-based access URL-based access date wildcarding date wildcarding document wildcarding document wildcarding document wildcarding Strategies for FINDING MISSING RESOURCES removed or moved? . don’t start with the archive . missing resources have often just moved (Klein & Nelson, 2010) . Synchronicity for Firefox helps find new location . scrapes archived version for “fingerprint” keywords; uses them to query search engines MementoFox MementoFox find archived content now at a new URL . -

Internet Archive Open Libraries Proposal Macarthur Foundation 100&Change Internet Archive 100&Change
Internet Archive Open Libraries Proposal MacArthur Foundation 100&Change Internet Archive 100&Change Table of Contents A. OVERVIEW 5 Executive Summary 6 Location for Proposed Project 8 Detailed Project Plan 9 B. COMMUNITY ENGAGEMENT 31 Stakeholder Identification 32 Inclusiveness 34 Persons With Disabilities 35 Stakeholder Engagement 36 Stakeholder Influence 38 C. SCALABILITY OF THE PROJECT 40 Planning for Scale 41 Scaling Technologies 41 Expanding Diversity 42 The Credibility of the Proposed Solution 43 Support for the Change 44 Advantage of the Proposed Solution 45 Ease of Transferring and Applying the Solution at Scale 47 Organizational Capacity to Implement at Scale 49 Financial Sustainability of the Proposed Solution 50 2 Internet Archive 100&Change D. MONITORING, EVALUATION, AND LEARNING 52 MONITORING 53 Results 53 Tracking 55 Milestones 57 EVALUATIONS 60 Changes for Beneficiaries 60 Data Sources 62 Methodology 63 Gender Analysis 65 LEARNING 66 Findings 66 Dissemination 68 E. ADDITIONAL INFORMATION 70 Detailed Budget Narrative 71 Project Risk Management 73 F. FINANCIAL STRENGTH AND STABILITY 76 G. TECHNICAL 81 Technical Explanation 82 Conclusion 86 3 Internet Archive 100&Change H. ANCILLARY MATERIALS 87 Evidence of Engagement 88 Biographies of Key Staff 187 Bibliography 226 * Website: http://openlibraries.online 4 A. Overview Internet Archive 100&Change Executive Summary Looking for a trusted source of information? For millions of citizens there’s only one place to head: their local library—society’s great equalizer, where Wi-Fi, computers, and knowledge are offered for free, to anyone entering the door. Yet, due to distance, time, cost or disability, people in marginalized populations are too often denied access to physical books. -

Reference Rot: an Emerging Threat to Transparency in Political Science
The Profession ......................................................................................................................................................................................................................................................................................................................... Reference Rot: An Emerging Threat to Transparency in Political Science Aaron L. Gertler, Independent Scholar John G. Bullock, University of Texas at Austin ABSTRACT Transparency of research is a large concern in political science, and the practice of publishing links to datasets and other online resources is one of the main methods by which political scientists promote transparency. But the method cannot work if the links don’t, and very often, they don’t. We show that most of the URLs ever published in the American Political Science Review no longer work as intended. The problem is severe in recent as well as in older articles; for example, more than one-fourth of links published in the APSR in 2013 were broken by the end of 2014. We conclude that “reference rot” limits the transparency and reproducibility of political science research. We also describe practices that scholars can adopt to combat the problem: when possible, they should archive data in trustworthy repositories, use links that incorporate persistent digital identifiers, and create archival versions of the webpages to which they link. he past decade has given rise to unprecedented con- repositories, use links that incorporate persistent digital identifi-