Preserving State Government Digital Information Minnesota Historical Society
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Harvesting Strategies for a National Domain France Lasfargues, Clément Oury, Bert Wendland
Legal deposit of the French Web: harvesting strategies for a national domain France Lasfargues, Clément Oury, Bert Wendland To cite this version: France Lasfargues, Clément Oury, Bert Wendland. Legal deposit of the French Web: harvesting strategies for a national domain. International Web Archiving Workshop, Sep 2008, Aarhus, Denmark. hal-01098538 HAL Id: hal-01098538 https://hal-bnf.archives-ouvertes.fr/hal-01098538 Submitted on 26 Dec 2014 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution| 4.0 International License Legal deposit of the French Web: harvesting strategies for a national domain France Lasfargues, Clément Oury, and Bert Wendland Bibliothèque nationale de France Quai François Mauriac 75706 Paris Cedex 13 {france.lasfargues, clement.oury, bert.wendland}@bnf.fr ABSTRACT 1. THE FRENCH CONTEXT According to French Copyright Law voted on August 1st, 2006, the Bibliothèque nationale de France (“BnF”, or “the Library”) is 1.1 Defining the scope of the legal deposit in charge of collecting and preserving the French Internet. The On August 1st, 2006, a new Copyright law was voted by the Library has established a “mixed model” of Web archiving, which French Parliament. -

Web Archiving Supplementary Guidelines
LIBRARY OF CONGRESS COLLECTIONS POLICY STATEMENTS SUPPLEMENTARY GUIDELINES Web Archiving Contents I. Scope II. Current Practice III. Research Strengths IV. Collecting Policy I. Scope The Library's traditional functions of acquiring, cataloging, preserving and serving collection materials of historical importance to Congress and the American people extend to digital materials, including web sites. The Library acquires and makes permanently accessible born digital works that are playing an increasingly important role in the intellectual, commercial and creative life of the United States. Given the vast size and growing comprehensiveness of the Internet, as well as the short life‐span of much of its content, the Library must: (1) define the scope and priorities for its web collecting, and (2) develop partnerships and cooperative relationships required to continue fulfilling its vital historic mission in order to supplement the Library’s capacity. The contents of a web site may range from ephemeral social media content to digital versions of formal publications that are also available in print. Web archiving preserves as much of the web‐based user experience as technologically possible in order to provide future users accurate snapshots of what particular organizations and individuals presented on the archived sites at particular moments in time, including how the intellectual content (such as text) is framed by the web site implementation. The guidelines in this document apply to the Library’s effort to acquire web sites and related content via harvesting in‐house, through contract services and purchase. It also covers collaborative web archiving efforts with external groups, such as the International Internet Preservation Consortium (IIPC). -

Web Archiving Environmental Scan
Web Archiving Environmental Scan The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Truman, Gail. 2016. Web Archiving Environmental Scan. Harvard Library Report. Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:25658314 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA Web Archiving Environmental Scan Harvard Library Report January 2016 Prepared by Gail Truman The Harvard Library Report “Web Archiving Environmental Scan” is licensed under a Creative Commons Attribution 4.0 International License. Prepared by Gail Truman, Truman Technologies Reviewed by Andrea Goethals, Harvard Library and Abigail Bordeaux, Library Technology Services, Harvard University Revised by Andrea Goethals in July 2017 to correct the number of dedicated web archiving staff at the Danish Royal Library This report was produced with the generous support of the Arcadia Fund. Citation: Truman, Gail. 2016. Web Archiving Environmental Scan. Harvard Library Report. Table of Contents Executive Summary ............................................................................................................................ 3 Introduction ...................................................................................................................................... -
![User Manual [Pdf]](https://docslib.b-cdn.net/cover/9268/user-manual-pdf-1099268.webp)
User Manual [Pdf]
Heritrix User Manual Internet Archive Kristinn Sigur#sson Michael Stack Igor Ranitovic Table of Contents 1. Introduction ............................................................................................................ 1 2. Installing and running Heritrix .................................................................................... 2 2.1. Obtaining and installing Heritrix ...................................................................... 2 2.2. Running Heritrix ........................................................................................... 3 2.3. Security Considerations .................................................................................. 7 3. Web based user interface ........................................................................................... 7 4. A quick guide to running your first crawl job ................................................................ 8 5. Creating jobs and profiles .......................................................................................... 9 5.1. Crawl job .....................................................................................................9 5.2. Profile ....................................................................................................... 10 6. Configuring jobs and profiles ................................................................................... 11 6.1. Modules (Scope, Frontier, and Processors) ....................................................... 12 6.2. Submodules .............................................................................................. -

Web Archiving and You Web Archiving and Us
Web Archiving and You Web Archiving and Us Amy Wickner University of Maryland Libraries Code4Lib 2018 Slides & Resources: https://osf.io/ex6ny/ Hello, thank you for this opportunity to talk about web archives and archiving. This talk is about what stakes the code4lib community might have in documenting particular experiences of the live web. In addition to slides, I’m leading with a list of material, tools, and trainings I read and relied on in putting this talk together. Despite the limited scope of the talk, I hope you’ll each find something of personal relevance to pursue further. “ the process of collecting portions of the World Wide Web, preserving the collections in an archival format, and then serving the archives for access and use International Internet Preservation Coalition To begin, here’s how the International Internet Preservation Consortium or IIPC defines web archiving. Let’s break this down a little. “Collecting portions” means not collecting everything: there’s generally a process of selection. “Archival format” implies that long-term preservation and stewardship are the goals of collecting material from the web. And “serving the archives for access and use” implies a stewarding entity conceptually separate from the bodies of creators and users of archives. It also implies that there is no web archiving without access and use. As we go along, we’ll see examples that both reinforce and trouble these assumptions. A point of clarity about wording: when I say for example “critique,” “question,” or “trouble” as a verb, I mean inquiry rather than judgement or condemnation. we are collectors So, preambles mostly over. -

Web Archiving for Academic Institutions
University of San Diego Digital USD Digital Initiatives Symposium Apr 23rd, 1:00 PM - 4:00 PM Web Archiving for Academic Institutions Lori Donovan Internet Archive Mary Haberle Internet Archive Follow this and additional works at: https://digital.sandiego.edu/symposium Donovan, Lori and Haberle, Mary, "Web Archiving for Academic Institutions" (2018). Digital Initiatives Symposium. 4. https://digital.sandiego.edu/symposium/2018/2018/4 This Workshop is brought to you for free and open access by Digital USD. It has been accepted for inclusion in Digital Initiatives Symposium by an authorized administrator of Digital USD. For more information, please contact [email protected]. Web Archiving for Academic Institutions Presenter 1 Title Senior Program Manager, Archive-It Presenter 2 Title Web Archivist Session Type Workshop Abstract With the advent of the internet, content that institutional archivists once preserved in physical formats is now web-based, and new avenues for information sharing, interaction and record-keeping are fundamentally changing how the history of the 21st century will be studied. Due to the transient nature of web content, much of this information is at risk. This half-day workshop will cover the basics of web archiving, help attendees identify content of interest to them and their communities, and give them an opportunity to interact with tools that assist with the capture and preservation of web content. Attendees will gain hands-on web archiving skills, insights into selection and collecting policies for web archives and how to apply what they've learned in the workshop to their own organizations. Location KIPJ Room B Comments Lori Donovan works with partners and the Internet Archive’s web archivists and engineering team to develop the Archive-It service so that it meets the needs of memory institutions. -

情報管理 O U R Nal of Information Pr Ocessing and Managemen T December
JOHO KANRI 2009 vol.52 no.9 http://johokanri.jp/ J情報管理 o u r nal of Information Pr ocessing and Managemen t December 世界の知識の図書館を目指すInternet Archive 創設者Brewster Kahleへのインタビュー Internet Archive aims to build a library of world knowledge An interview with the founder, Brewster Kahle 時実 象一1 TOKIZANE Soichi1 1 愛知大学文学部(〒441-8522 愛知県豊橋市町畑町1-1)E-mail : [email protected] 1 Faculty of Letters, Aichi University (1-1 Machihata-cho Toyohashi-shi, Aichi 441-8522) 原稿受理(2009-09-25) (情報管理 52(9), 534-542) 著者抄録 Internet ArchiveはBrewster Kahleによって1996年に設立された非営利団体で,過去のインターネットWebサイトを保存し ているWayback Machineで知られているほか,動画,音楽,音声の電子アーカイブを公開し,またGoogleと同様書籍の電 子化を行っている。Wayback Machineは1996年からの5,000万サイトに対応する1,500億ページのデータを保存・公開し ている。書籍の電子化はScribeと呼ばれる独自開発の撮影機を用い,ボストン公共図書館などと協力して1日1,000冊の ペースで電子化している。電子化したデータを用いて子供たちに本を配るBookmobileという活動も行っている。Kahle氏 はGoogle Book Searchの和解に批判的な意見を述べているほか,孤児著作物の利用促進やOne Laptop Per Child(OLPC)運 動への協力も行っている。 キーワード Webアーカイブ,Wayback Machine,書籍電子化,Google Book Search,新アレキサンドリア図書館,Open Content Alliance,Open Book Alliance 1. はじめに Googleと同様書籍の電子化を行っている。インター ネットが一般に使えるようになったのが1995年で Internet Archive注1)はBrewster Kahle(ケールと発 あるから,Internet Archiveはインターネットとほぼ 音する)によって1996年に設立された非営利団体 同時に誕生したことになる。現在年間運営費は約 である。過去のインターネットW e bサイトを保存 1,000万ドルであり,政府や財団の補助や寄付で運 しているWayback Machine1)で知られているほか, 営している。この(2009年)5月にKahle氏(以下敬 534 JOHO KANRI 世界の知識の図書館を目指すInternet Archive 2009 vol.52 no.9 http://johokanri.jp/ J情報管理 o u r nal of Information Pr ocessing and Managemen t December 称略)を訪ね,インタビューを行ったので報告する A O Lに売却した。その売却益によって翌年I n t e r n e t (写真1)。 Archiveを立ち上げたのである。 K a h l eは1982年 に マ サ チ ュ ー セ ッ ツ 工 科 大 学 (Massachusetts Institute of Technology: MIT)のコン 2. Internet Archiveの事業 ピュータ科学工学科を卒業した。 2000年前エジプトのアレキサンドリアには当時 2.1 Wayback Machine 世界最大の図書館があり,パピルスに書かれた書物 I n t e r n e t A r c h i v eのホームページのU R Lはw w w . -
Getting Started in Web Archiving
Submitted on: 13.06.2017 Getting Started in Web Archiving Abigail Grotke Library Services, Digital Collections Management and Services Division, Library of Congress, Washington, D.C., United States. E-mail address: [email protected] This work is made available under the terms of the Creative Commons Attribution 4.0 International License: http://creativecommons.org/licenses/by/4.0 Abstract: This purpose of this paper is to provide general information about how organizations can get started in web archiving, for both those who are developing new web archiving programs and for libraries that are just beginning to explore the possibilities. The paper includes an overview of considerations when establishing a web archiving program, including typical approaches that national libraries take when preserving the web. These include: collection development, legal issues, tools and approaches, staffing, and whether to do work in-house or outsource some or most of the work. The paper will introduce the International Internet Preservation Consortium and the benefits of collaboration when building web archives. Keywords: web archiving, legal deposit, collaboration 1 BACKGROUND In the more than twenty five years since the World Wide Web was invented, it has been woven into everyday life—a platform by which a huge number of individuals and more traditional publishers distribute information and communicate with one another around the world. While the size of the web can be difficult to articulate, it is generally understood that it is large and ever-changing and that content is continuously added and removed. With so much global cultural heritage being documented online, librarians, archivists, and others are increasingly becoming aware of the need to preserve this valuable resource for future generations. -

Incremental Crawling with Heritrix
Incremental crawling with Heritrix Kristinn Sigurðsson National and University Library of Iceland Arngrímsgötu 3 107 Reykjavík Iceland [email protected] Abstract. The Heritrix web crawler aims to be the world's first open source, extensible, web-scale, archival-quality web crawler. It has however been limited in its crawling strategies to snapshot crawling. This paper reports on work to add the ability to conduct incremental crawls to its capabilities. We first discuss the concept of incremental crawling as opposed to snapshot crawling and then the possible ways to design an effective incremental strategy. An overview is given of the implementation that we did, its limits and strengths are discussed. We then report on the results of initial experimentation with the new software which have gone well. Finally, we discuss issues that remain unresolved and possible future improvements. 1 Introduction With an increasing number of parties interested in crawling the World Wide Web, for a variety of reasons, a number of different crawl types have emerged. The development team at Internet Archive [12] responsible for the Heritrix web crawler, have highlighted four distinct variations [1], broad , focused, continuous and experimental crawling. Broad and focused crawls are in many ways similar, the primary difference being that broad crawls emphasize capturing a large scope1, whereas focused crawling calls for a more complete coverage of a smaller scope. Both approaches use a snapshot strategy , which involves crawling the scope once and once only. Of course, crawls are repeatable but only by starting again from the seeds. No information from past crawls is used in new ones, except possibly some changes to the configuration made by the operator, to avoid crawler traps etc. -

Web Archives for the Analog Archivist: Using Webpages Archived by the Internet Archive to Improve Processing and Description
Journal of Western Archives Volume 9 Issue 1 Article 6 2018 Web Archives for the Analog Archivist: Using Webpages Archived by the Internet Archive to Improve Processing and Description Aleksandr Gelfand New-York Historical Society, [email protected] Follow this and additional works at: https://digitalcommons.usu.edu/westernarchives Part of the Archival Science Commons Recommended Citation Gelfand, Aleksandr (2018) "Web Archives for the Analog Archivist: Using Webpages Archived by the Internet Archive to Improve Processing and Description," Journal of Western Archives: Vol. 9 : Iss. 1 , Article 6. DOI: https://doi.org/10.26077/4944-b95b Available at: https://digitalcommons.usu.edu/westernarchives/vol9/iss1/6 This Case Study is brought to you for free and open access by the Journals at DigitalCommons@USU. It has been accepted for inclusion in Journal of Western Archives by an authorized administrator of DigitalCommons@USU. For more information, please contact [email protected]. Gelfand: Web Archives for the Analog Archivist Web Archives for the Analog Archivist: Using Webpages Archived by the Internet Archive to Improve Processing and Description Aleksandr Gelfand ABSTRACT Twenty years ago the Internet Archive was founded with the wide-ranging mission of providing universal access to all knowledge. In the two decades since, that organization has captured and made accessible over 150 billion websites. By incorporating the use of Internet Archive's Wayback Machine into their workflows, archivists working primarily with analog records may enhance their ability in such tasks as the construction of a processing plan, the creation of more accurate historical descriptions for finding aids, and potentially be able to provide better reference services to their patrons. -
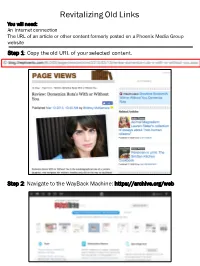
Wayback Machine Instructions
Revitalizing Old Links You will need: An Internet connection The URL of an article or other content formerly posted on a Phoenix Media Group website Step 1: Copy the old URL of your selected content. Step 2: Navigate to the WayBack Machine: https://archive.org/web Step 3: Input the copied URL of your content into the search box on the Wayback Machine home page. Hit Enter or click “Browse History”. Step 4: The WayBack Machine will retrieve a page that displays the original URL of your content, the number of times that content has been captured by the WayBack Machine, and a calendar. If you would like to access the most recently captured version of the content, click the most recent “snapshot” date on the calendar (dates on which the content was captured are marked with blue circles). If the content has been edited or changed and you would like to access an older saved version, navigate through the calendar to your desired “snapshot” date. Select the most recent save date to view the most recently saved Select the year, then version of the month and date to view content. an older version of the content. Black bars indicate years in which the content was captured. Step 5: The WayBack Machine will redirect you to the preserved snapshot of the page from the date you selected. Please note that some original content, such as advertisements, JavaScript or Flash videos, may not be saved. This URL directs to the saved version of the material; replace any outdated links to the content with this URL. -

Adaptive Revisiting with Heritrix Master Thesis (30 Credits/60 ECTS)
University of Iceland Faculty of Engineering Department of Computer Science Adaptive Revisiting with Heritrix Master Thesis (30 credits/60 ECTS) by Kristinn Sigurðsson May 2005 Supervisors: Helgi Þorbergsson, PhD Þorsteinn Hallgrímsson Útdráttur á íslensku Veraldarvefurinn geymir sívaxandi hluta af þekkingu og menningararfi heimsins. Þar sem Vefurinn er einnig sífellt að breytast þá er nú unnið ötullega að því að varðveita innihald hans á hverjum tíma. Þessi vinna er framlenging á skylduskila lögum sem hafa í síðustu aldir stuðlað að því að varðveita prentað efni. Fyrstu þrír kaflarnir lýsa grundvallar erfiðleikum við það að safna Vefnum og kynnir hugbúnaðinn Heritrix, sem var smíðaður til að vinna það verk. Fyrsti kaflinn einbeitir sér að ástæðunum og bakgrunni þessarar vinnu en kaflar tvö og þrjú beina kastljósinu að tæknilegri þáttum. Markmið verkefnisins var að þróa nýja tækni til að safna ákveðnum hluta af Vefnum sem er álitinn breytast ört og vera í eðli sínu áhugaverður. Seinni kaflar fjalla um skilgreininu á slíkri aðferðafræði og hvernig hún var útfærð í Heritrix. Hluti þessarar umfjöllunar beinist að því hvernig greina má breytingar í skjölum. Að lokum er fjallað um fyrstu reynslu af nýja hugbúnaðinum og sjónum er beint að þeim þáttum sem þarfnast frekari vinnu eða athygli. Þar sem markmiðið með verkefninu var að leggja grunnlínur fyrir svona aðferðafræði og útbúa einfalda og stöðuga útfærsla þá inniheldur þessi hluti margar hugmyndir um hvað mætti gera betur. Keywords Web crawling, web archiving, Heritrix, Internet, World Wide Web, legal deposit, electronic legal deposit. i Abstract The World Wide Web contains an increasingly significant amount of the world’s knowledge and heritage.