Making Recommendations from Web Archives for “Lost” Web Pages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cryonics Magazine, Q1 2001
SOURCE FEATURES PAGE Fred Chamberlain Glass Transitions: A Project Proposal 3 Mike Perry Interview with Dr. Jerry Lemler, M.D. 13 Austin Esfandiary A Tribute to FM-2030 16 Johnny Boston FM & I 18 Billy H. Seidel the ALCOR adventure 39 Natasha Vita-More Considering Aesthetics 45 Columns Book Review: Affective Computing..................................41 You Only Go Around Twice .................................................42 First Thoughts on Last Matters............................................48 TechNews.......................................................................51 Alcor update - 19 The Global Membership Challenge . 19 Letter from Steve Bridge . 26 President’s Report . 22 “Last-Minute” Calls . 27 Transitions and New Developments . 24 Alcor Membership Status . 37 1st Qtr. 2001 • Cryonics 1 Alcor: the need for a rescue team or even for ingly evident that the leadership of The Origin of Our Name cryonics itself. Symbolically then, Alcor CSC would not support or even would be a “test” of vision as regards life tolerate a rescue team concept. Less In September of 1970 Fred and extension. than one year after the 1970 dinner Linda Chamberlain (the founders of As an acronym, Alcor is a close if meeting, the Chamberlains severed all Alcor) were asked to come up with a not perfect fit with Allopathic Cryogenic ties with CSC and incorporated the name for a rescue team for the now- Rescue. The Chamberlains could have “Rocky Mountain Cryonics Society” defunct Cryonics Society of California forced a five-word string, but these three in the State of Washington. The articles (CSC). In view of our logical destiny seemed sufficient. Allopathy (as opposed and bylaws of this organization (the stars), they searched through star to Homeopathy) is a medical perspective specifically provided for “Alcor catalogs and books on astronomy, wherein any treatment that improves the Members,” who were to be the core of hoping to find a star that could serve as prognosis is valid. -

Serving the Boaters of America PROLOG P/R/C Greg Scotten, SN
Volume 2, Issue 2 May 2012 Marketing and Public Relations, The Art and Science of Creating LINKS (Click on selected Link) a Call to Action and Causing a Change. The United States Power Squadrons PR Contest Forms Boating Safety Centennial Anniversary Articles Cabinet Serving the Boaters of America PROLOG P/R/C Greg Scotten, SN The United States Power Squadrons is Inside this issue: celebrating 100 years of community Jacksonville Sail & Power service on 1 February 2014. Your Squadron to conduct a celebratory USPS Centennial 1 squadron needs to be part of that boat parade on the St. John’s important Centennial event which is a River. national milestone. To celebrate this Bright Ideas 2 national milestone, several projects are The Power Squadrons Flag and underway and a national anniversary Etiquette Committee has designed Importance of 3 a unique boat Ensign, which Squadron Editors web page will post exciting activities and information. The Power Squadrons’ emphasizes the event, and is to be MPR Committee 3 Ship Store will be featuring items with flown on members’ vessels in 2013 Mission the 100th Anniversary Logo. An and 2014. A special new Power anniversary postal commemorative is Squadrons logo has been under discussion. All levels of the distributed and is available on line. organization are planning local 2012 Governing 4 A year long ceremonial activity is community activities. Board planned. At the 2013 Annual The precise anniversary day is Sunday, Meeting Governing Board, full sized anniversary Ensigns will be Hands-on Training 6 2 February 2014. But because the Governing Board at the Annual Meeting presented to each of the thirty- two districts. -

Communicator's Tools
Communicator’s Tools (II): Documentation and web resources ENGLISH FOR SCIENCE AND TECHNOLOGY ““LaLa webweb eses unun mundomundo dede aplicacionesaplicaciones textualestextuales…… hayhay unun grangran conjuntoconjunto dede imimáágenesgenes ee incontablesincontables archivosarchivos dede audio,audio, peropero elel textotexto predominapredomina nono ssóólolo enen cantidad,cantidad, sinosino enen utilizaciutilizacióónn……”” MillMilláánn (2001:(2001: 3535--36)36) Internet • Global computer network of interconnected educational, scientific, business and governmental networks for communication and data exchange. • Purpose: find and locate useful and quality information. Internet • Web acquisition. Some problems – Enormous volume of information – Fast pace of change on web information – Chaos of contents – Complexity and diversification of information – Lack of security – Silence & noise – Source for advertising and money – No assessment criteria Search engines and web directories • Differencies between search engines and directories • Search syntax (Google y Altavista) • Search strategies • Evaluation criteria Search engines • Index millions of web pages • How they work: – They work by storing information about many web pages, which they retrieve from the WWW itself. – Generally use robot crawlers to locate searchable pages on web sites (robots are also called crawlers, spiders, gatherers or harvesters) and mine data available in newsgroups, databases, or open directories. – The contents of each page are analyzed to determine how it should be indexed (for example, words are extracted from the titles, headings, or special fields called meta tags). Data about web pages are stored in an index database for use in later queries. – Some search engines, such as Google, store all or part of the source page (referred to as a cache) as well as information about the web pages. -

How to Choose a Search Engine Or Directory
How to Choose a Search Engine or Directory Fields & File Types If you want to search for... Choose... Audio/Music AllTheWeb | AltaVista | Dogpile | Fazzle | FindSounds.com | Lycos Music Downloads | Lycos Multimedia Search | Singingfish Date last modified AllTheWeb Advanced Search | AltaVista Advanced Web Search | Exalead Advanced Search | Google Advanced Search | HotBot Advanced Search | Teoma Advanced Search | Yahoo Advanced Web Search Domain/Site/URL AllTheWeb Advanced Search | AltaVista Advanced Web Search | AOL Advanced Search | Google Advanced Search | Lycos Advanced Search | MSN Search Search Builder | SearchEdu.com | Teoma Advanced Search | Yahoo Advanced Web Search File Format AllTheWeb Advanced Web Search | AltaVista Advanced Web Search | AOL Advanced Search | Exalead Advanced Search | Yahoo Advanced Web Search Geographic location Exalead Advanced Search | HotBot Advanced Search | Lycos Advanced Search | MSN Search Search Builder | Teoma Advanced Search | Yahoo Advanced Web Search Images AllTheWeb | AltaVista | The Amazing Picture Machine | Ditto | Dogpile | Fazzle | Google Image Search | IceRocket | Ixquick | Mamma | Picsearch Language AllTheWeb Advanced Web Search | AOL Advanced Search | Exalead Advanced Search | Google Language Tools | HotBot Advanced Search | iBoogie Advanced Web Search | Lycos Advanced Search | MSN Search Search Builder | Teoma Advanced Search | Yahoo Advanced Web Search Multimedia & video All TheWeb | AltaVista | Dogpile | Fazzle | IceRocket | Singingfish | Yahoo Video Search Page Title/URL AOL Advanced -

Dean's Line Contents
With the initiation of “Polytechnic" programs in California, DEAN’S LINE a “Learn by Doing” ethic emerged that was copied in countless high schools and junior colleges throughout the Harold B. Schleifer Dean, University Library state. To meet student needs, Cal Poly elevated the level of instruction at several stages along the way. Originally a high school, the institution was gradually transformed into the CAL POLY POMONA CAMPUS HISTORY BOOK equivalent of a junior college, and then to a four-year You probably knew that the cereal magnate W.K. Kellogg founded college, and ultimately, to a university that included our campus, but did you know that Cal Poly Pomona was the graduate-level instruction. home of Snow White’s horse, Prince Charming?” The Library is proud to make available a beautifully illustrated book California State Polytechnic University, Pomona: A Legacy documenting the history of the Cal Poly Pomona ranch and and a Mission, 1938-1989 is an heirloom-quality coffee- campus. California State Polytechnic University, table book with over 30 historical photographs, indexed, Pomona — A Legacy and a Mission 1938-1989 tells and displayed in a generous 9 x 11 inch, 294-page the story of a distinctive American university whose origins date hardcover format. Copies of the book can be obtained for back, in a limited sense, to the Gold Rush of 1849. The family of $100 through the University Library. the author, the late Donald H. Pflueger, Professor Emeritus, educator, historian, diplomat, and author, has kindly and To commemorate and honor the philanthropy of the generously pledged the proceeds of the book to the University Pflueger family, the Library will use the donations to Library. -

Web Archiving Supplementary Guidelines
LIBRARY OF CONGRESS COLLECTIONS POLICY STATEMENTS SUPPLEMENTARY GUIDELINES Web Archiving Contents I. Scope II. Current Practice III. Research Strengths IV. Collecting Policy I. Scope The Library's traditional functions of acquiring, cataloging, preserving and serving collection materials of historical importance to Congress and the American people extend to digital materials, including web sites. The Library acquires and makes permanently accessible born digital works that are playing an increasingly important role in the intellectual, commercial and creative life of the United States. Given the vast size and growing comprehensiveness of the Internet, as well as the short life‐span of much of its content, the Library must: (1) define the scope and priorities for its web collecting, and (2) develop partnerships and cooperative relationships required to continue fulfilling its vital historic mission in order to supplement the Library’s capacity. The contents of a web site may range from ephemeral social media content to digital versions of formal publications that are also available in print. Web archiving preserves as much of the web‐based user experience as technologically possible in order to provide future users accurate snapshots of what particular organizations and individuals presented on the archived sites at particular moments in time, including how the intellectual content (such as text) is framed by the web site implementation. The guidelines in this document apply to the Library’s effort to acquire web sites and related content via harvesting in‐house, through contract services and purchase. It also covers collaborative web archiving efforts with external groups, such as the International Internet Preservation Consortium (IIPC). -

An XML Query Engine for Network-Bound Data
University of Pennsylvania ScholarlyCommons Departmental Papers (CIS) Department of Computer & Information Science December 2002 An XML Query Engine for Network-Bound Data Zachary G. Ives University of Pennsylvania, [email protected] Alon Y. Halevy University of Washington Daniel S. Weld University of Washington Follow this and additional works at: https://repository.upenn.edu/cis_papers Recommended Citation Zachary G. Ives, Alon Y. Halevy, and Daniel S. Weld, "An XML Query Engine for Network-Bound Data", . December 2002. Postprint version. Published in VLDB Journal : The International Journal on Very Large Data Bases, Volume 11, Number 4, December 2002, pages 380-402. The original publication is available at www.springerlink.com. Publisher URL: http://dx.doi.org/10.1007/s00778-002-0078-5 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/cis_papers/121 For more information, please contact [email protected]. An XML Query Engine for Network-Bound Data Abstract XML has become the lingua franca for data exchange and integration across administrative and enterprise boundaries. Nearly all data providers are adding XML import or export capabilities, and standard XML Schemas and DTDs are being promoted for all types of data sharing. The ubiquity of XML has removed one of the major obstacles to integrating data from widely disparate sources –- namely, the heterogeneity of data formats. However, general-purpose integration of data across the wide area also requires a query processor that can query data sources on demand, receive streamed XML data from them, and combine and restructure the data into new XML output -- while providing good performance for both batch-oriented and ad-hoc, interactive queries. -

Web Archiving and You Web Archiving and Us
Web Archiving and You Web Archiving and Us Amy Wickner University of Maryland Libraries Code4Lib 2018 Slides & Resources: https://osf.io/ex6ny/ Hello, thank you for this opportunity to talk about web archives and archiving. This talk is about what stakes the code4lib community might have in documenting particular experiences of the live web. In addition to slides, I’m leading with a list of material, tools, and trainings I read and relied on in putting this talk together. Despite the limited scope of the talk, I hope you’ll each find something of personal relevance to pursue further. “ the process of collecting portions of the World Wide Web, preserving the collections in an archival format, and then serving the archives for access and use International Internet Preservation Coalition To begin, here’s how the International Internet Preservation Consortium or IIPC defines web archiving. Let’s break this down a little. “Collecting portions” means not collecting everything: there’s generally a process of selection. “Archival format” implies that long-term preservation and stewardship are the goals of collecting material from the web. And “serving the archives for access and use” implies a stewarding entity conceptually separate from the bodies of creators and users of archives. It also implies that there is no web archiving without access and use. As we go along, we’ll see examples that both reinforce and trouble these assumptions. A point of clarity about wording: when I say for example “critique,” “question,” or “trouble” as a verb, I mean inquiry rather than judgement or condemnation. we are collectors So, preambles mostly over. -

情報管理 O U R Nal of Information Pr Ocessing and Managemen T December
JOHO KANRI 2009 vol.52 no.9 http://johokanri.jp/ J情報管理 o u r nal of Information Pr ocessing and Managemen t December 世界の知識の図書館を目指すInternet Archive 創設者Brewster Kahleへのインタビュー Internet Archive aims to build a library of world knowledge An interview with the founder, Brewster Kahle 時実 象一1 TOKIZANE Soichi1 1 愛知大学文学部(〒441-8522 愛知県豊橋市町畑町1-1)E-mail : [email protected] 1 Faculty of Letters, Aichi University (1-1 Machihata-cho Toyohashi-shi, Aichi 441-8522) 原稿受理(2009-09-25) (情報管理 52(9), 534-542) 著者抄録 Internet ArchiveはBrewster Kahleによって1996年に設立された非営利団体で,過去のインターネットWebサイトを保存し ているWayback Machineで知られているほか,動画,音楽,音声の電子アーカイブを公開し,またGoogleと同様書籍の電 子化を行っている。Wayback Machineは1996年からの5,000万サイトに対応する1,500億ページのデータを保存・公開し ている。書籍の電子化はScribeと呼ばれる独自開発の撮影機を用い,ボストン公共図書館などと協力して1日1,000冊の ペースで電子化している。電子化したデータを用いて子供たちに本を配るBookmobileという活動も行っている。Kahle氏 はGoogle Book Searchの和解に批判的な意見を述べているほか,孤児著作物の利用促進やOne Laptop Per Child(OLPC)運 動への協力も行っている。 キーワード Webアーカイブ,Wayback Machine,書籍電子化,Google Book Search,新アレキサンドリア図書館,Open Content Alliance,Open Book Alliance 1. はじめに Googleと同様書籍の電子化を行っている。インター ネットが一般に使えるようになったのが1995年で Internet Archive注1)はBrewster Kahle(ケールと発 あるから,Internet Archiveはインターネットとほぼ 音する)によって1996年に設立された非営利団体 同時に誕生したことになる。現在年間運営費は約 である。過去のインターネットW e bサイトを保存 1,000万ドルであり,政府や財団の補助や寄付で運 しているWayback Machine1)で知られているほか, 営している。この(2009年)5月にKahle氏(以下敬 534 JOHO KANRI 世界の知識の図書館を目指すInternet Archive 2009 vol.52 no.9 http://johokanri.jp/ J情報管理 o u r nal of Information Pr ocessing and Managemen t December 称略)を訪ね,インタビューを行ったので報告する A O Lに売却した。その売却益によって翌年I n t e r n e t (写真1)。 Archiveを立ち上げたのである。 K a h l eは1982年 に マ サ チ ュ ー セ ッ ツ 工 科 大 学 (Massachusetts Institute of Technology: MIT)のコン 2. Internet Archiveの事業 ピュータ科学工学科を卒業した。 2000年前エジプトのアレキサンドリアには当時 2.1 Wayback Machine 世界最大の図書館があり,パピルスに書かれた書物 I n t e r n e t A r c h i v eのホームページのU R Lはw w w . -

Web Archives for the Analog Archivist: Using Webpages Archived by the Internet Archive to Improve Processing and Description
Journal of Western Archives Volume 9 Issue 1 Article 6 2018 Web Archives for the Analog Archivist: Using Webpages Archived by the Internet Archive to Improve Processing and Description Aleksandr Gelfand New-York Historical Society, [email protected] Follow this and additional works at: https://digitalcommons.usu.edu/westernarchives Part of the Archival Science Commons Recommended Citation Gelfand, Aleksandr (2018) "Web Archives for the Analog Archivist: Using Webpages Archived by the Internet Archive to Improve Processing and Description," Journal of Western Archives: Vol. 9 : Iss. 1 , Article 6. DOI: https://doi.org/10.26077/4944-b95b Available at: https://digitalcommons.usu.edu/westernarchives/vol9/iss1/6 This Case Study is brought to you for free and open access by the Journals at DigitalCommons@USU. It has been accepted for inclusion in Journal of Western Archives by an authorized administrator of DigitalCommons@USU. For more information, please contact [email protected]. Gelfand: Web Archives for the Analog Archivist Web Archives for the Analog Archivist: Using Webpages Archived by the Internet Archive to Improve Processing and Description Aleksandr Gelfand ABSTRACT Twenty years ago the Internet Archive was founded with the wide-ranging mission of providing universal access to all knowledge. In the two decades since, that organization has captured and made accessible over 150 billion websites. By incorporating the use of Internet Archive's Wayback Machine into their workflows, archivists working primarily with analog records may enhance their ability in such tasks as the construction of a processing plan, the creation of more accurate historical descriptions for finding aids, and potentially be able to provide better reference services to their patrons. -
Wayback Machine Instructions
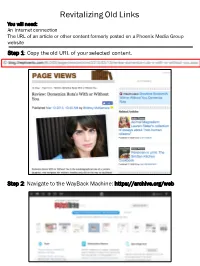
Revitalizing Old Links You will need: An Internet connection The URL of an article or other content formerly posted on a Phoenix Media Group website Step 1: Copy the old URL of your selected content. Step 2: Navigate to the WayBack Machine: https://archive.org/web Step 3: Input the copied URL of your content into the search box on the Wayback Machine home page. Hit Enter or click “Browse History”. Step 4: The WayBack Machine will retrieve a page that displays the original URL of your content, the number of times that content has been captured by the WayBack Machine, and a calendar. If you would like to access the most recently captured version of the content, click the most recent “snapshot” date on the calendar (dates on which the content was captured are marked with blue circles). If the content has been edited or changed and you would like to access an older saved version, navigate through the calendar to your desired “snapshot” date. Select the most recent save date to view the most recently saved Select the year, then version of the month and date to view content. an older version of the content. Black bars indicate years in which the content was captured. Step 5: The WayBack Machine will redirect you to the preserved snapshot of the page from the date you selected. Please note that some original content, such as advertisements, JavaScript or Flash videos, may not be saved. This URL directs to the saved version of the material; replace any outdated links to the content with this URL. -

The Future of Web Citation Practices
City University of New York (CUNY) CUNY Academic Works Publications and Research John Jay College of Criminal Justice 2016 The Future of Web Citation Practices Robin Camille Davis CUNY John Jay College How does access to this work benefit ou?y Let us know! More information about this work at: https://academicworks.cuny.edu/jj_pubs/117 Discover additional works at: https://academicworks.cuny.edu This work is made publicly available by the City University of New York (CUNY). Contact: [email protected] This is an electronic version (preprint) of an article published in Behavioral and Social Sciences Librarian. The article is available online at http://dx.doi.org/10.1080/01639269.2016.1241122 (subscription required). Full citation: Davis, R. “The Future of Web Citation Practices (Internet Connection Column).” Behavioral & Social Sciences Librarian 35.3 (2016): 128-134. Web. Internet Connection The Future of Web Citation Practices Robin Camille Davis Abstract: Citing webpages has been a common practice in scholarly publications for nearly two decades as the Web evolved into a major information source. But over the years, more and more bibliographies have suffered from “reference rot”: cited URLs are broken links or point to a page that no longer contains the content the author originally cited. In this column, I look at several studies showing how reference rot has affected different academic disciplines. I also examine citation styles’ approach to citing web sources. I then turn to emerging web citation practices: Perma, a “freemium” web archiving service specifically for citation; and the Internet Archive, the largest web archive. Introduction There’s a new twist on an old proverb: You cannot step in the same Web twice.