An XML Query Engine for Network-Bound Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cryonics Magazine, Q1 2001
SOURCE FEATURES PAGE Fred Chamberlain Glass Transitions: A Project Proposal 3 Mike Perry Interview with Dr. Jerry Lemler, M.D. 13 Austin Esfandiary A Tribute to FM-2030 16 Johnny Boston FM & I 18 Billy H. Seidel the ALCOR adventure 39 Natasha Vita-More Considering Aesthetics 45 Columns Book Review: Affective Computing..................................41 You Only Go Around Twice .................................................42 First Thoughts on Last Matters............................................48 TechNews.......................................................................51 Alcor update - 19 The Global Membership Challenge . 19 Letter from Steve Bridge . 26 President’s Report . 22 “Last-Minute” Calls . 27 Transitions and New Developments . 24 Alcor Membership Status . 37 1st Qtr. 2001 • Cryonics 1 Alcor: the need for a rescue team or even for ingly evident that the leadership of The Origin of Our Name cryonics itself. Symbolically then, Alcor CSC would not support or even would be a “test” of vision as regards life tolerate a rescue team concept. Less In September of 1970 Fred and extension. than one year after the 1970 dinner Linda Chamberlain (the founders of As an acronym, Alcor is a close if meeting, the Chamberlains severed all Alcor) were asked to come up with a not perfect fit with Allopathic Cryogenic ties with CSC and incorporated the name for a rescue team for the now- Rescue. The Chamberlains could have “Rocky Mountain Cryonics Society” defunct Cryonics Society of California forced a five-word string, but these three in the State of Washington. The articles (CSC). In view of our logical destiny seemed sufficient. Allopathy (as opposed and bylaws of this organization (the stars), they searched through star to Homeopathy) is a medical perspective specifically provided for “Alcor catalogs and books on astronomy, wherein any treatment that improves the Members,” who were to be the core of hoping to find a star that could serve as prognosis is valid. -

Serving the Boaters of America PROLOG P/R/C Greg Scotten, SN
Volume 2, Issue 2 May 2012 Marketing and Public Relations, The Art and Science of Creating LINKS (Click on selected Link) a Call to Action and Causing a Change. The United States Power Squadrons PR Contest Forms Boating Safety Centennial Anniversary Articles Cabinet Serving the Boaters of America PROLOG P/R/C Greg Scotten, SN The United States Power Squadrons is Inside this issue: celebrating 100 years of community Jacksonville Sail & Power service on 1 February 2014. Your Squadron to conduct a celebratory USPS Centennial 1 squadron needs to be part of that boat parade on the St. John’s important Centennial event which is a River. national milestone. To celebrate this Bright Ideas 2 national milestone, several projects are The Power Squadrons Flag and underway and a national anniversary Etiquette Committee has designed Importance of 3 a unique boat Ensign, which Squadron Editors web page will post exciting activities and information. The Power Squadrons’ emphasizes the event, and is to be MPR Committee 3 Ship Store will be featuring items with flown on members’ vessels in 2013 Mission the 100th Anniversary Logo. An and 2014. A special new Power anniversary postal commemorative is Squadrons logo has been under discussion. All levels of the distributed and is available on line. organization are planning local 2012 Governing 4 A year long ceremonial activity is community activities. Board planned. At the 2013 Annual The precise anniversary day is Sunday, Meeting Governing Board, full sized anniversary Ensigns will be Hands-on Training 6 2 February 2014. But because the Governing Board at the Annual Meeting presented to each of the thirty- two districts. -

Communicator's Tools
Communicator’s Tools (II): Documentation and web resources ENGLISH FOR SCIENCE AND TECHNOLOGY ““LaLa webweb eses unun mundomundo dede aplicacionesaplicaciones textualestextuales…… hayhay unun grangran conjuntoconjunto dede imimáágenesgenes ee incontablesincontables archivosarchivos dede audio,audio, peropero elel textotexto predominapredomina nono ssóólolo enen cantidad,cantidad, sinosino enen utilizaciutilizacióónn……”” MillMilláánn (2001:(2001: 3535--36)36) Internet • Global computer network of interconnected educational, scientific, business and governmental networks for communication and data exchange. • Purpose: find and locate useful and quality information. Internet • Web acquisition. Some problems – Enormous volume of information – Fast pace of change on web information – Chaos of contents – Complexity and diversification of information – Lack of security – Silence & noise – Source for advertising and money – No assessment criteria Search engines and web directories • Differencies between search engines and directories • Search syntax (Google y Altavista) • Search strategies • Evaluation criteria Search engines • Index millions of web pages • How they work: – They work by storing information about many web pages, which they retrieve from the WWW itself. – Generally use robot crawlers to locate searchable pages on web sites (robots are also called crawlers, spiders, gatherers or harvesters) and mine data available in newsgroups, databases, or open directories. – The contents of each page are analyzed to determine how it should be indexed (for example, words are extracted from the titles, headings, or special fields called meta tags). Data about web pages are stored in an index database for use in later queries. – Some search engines, such as Google, store all or part of the source page (referred to as a cache) as well as information about the web pages. -

How to Choose a Search Engine Or Directory
How to Choose a Search Engine or Directory Fields & File Types If you want to search for... Choose... Audio/Music AllTheWeb | AltaVista | Dogpile | Fazzle | FindSounds.com | Lycos Music Downloads | Lycos Multimedia Search | Singingfish Date last modified AllTheWeb Advanced Search | AltaVista Advanced Web Search | Exalead Advanced Search | Google Advanced Search | HotBot Advanced Search | Teoma Advanced Search | Yahoo Advanced Web Search Domain/Site/URL AllTheWeb Advanced Search | AltaVista Advanced Web Search | AOL Advanced Search | Google Advanced Search | Lycos Advanced Search | MSN Search Search Builder | SearchEdu.com | Teoma Advanced Search | Yahoo Advanced Web Search File Format AllTheWeb Advanced Web Search | AltaVista Advanced Web Search | AOL Advanced Search | Exalead Advanced Search | Yahoo Advanced Web Search Geographic location Exalead Advanced Search | HotBot Advanced Search | Lycos Advanced Search | MSN Search Search Builder | Teoma Advanced Search | Yahoo Advanced Web Search Images AllTheWeb | AltaVista | The Amazing Picture Machine | Ditto | Dogpile | Fazzle | Google Image Search | IceRocket | Ixquick | Mamma | Picsearch Language AllTheWeb Advanced Web Search | AOL Advanced Search | Exalead Advanced Search | Google Language Tools | HotBot Advanced Search | iBoogie Advanced Web Search | Lycos Advanced Search | MSN Search Search Builder | Teoma Advanced Search | Yahoo Advanced Web Search Multimedia & video All TheWeb | AltaVista | Dogpile | Fazzle | IceRocket | Singingfish | Yahoo Video Search Page Title/URL AOL Advanced -

Dean's Line Contents
With the initiation of “Polytechnic" programs in California, DEAN’S LINE a “Learn by Doing” ethic emerged that was copied in countless high schools and junior colleges throughout the Harold B. Schleifer Dean, University Library state. To meet student needs, Cal Poly elevated the level of instruction at several stages along the way. Originally a high school, the institution was gradually transformed into the CAL POLY POMONA CAMPUS HISTORY BOOK equivalent of a junior college, and then to a four-year You probably knew that the cereal magnate W.K. Kellogg founded college, and ultimately, to a university that included our campus, but did you know that Cal Poly Pomona was the graduate-level instruction. home of Snow White’s horse, Prince Charming?” The Library is proud to make available a beautifully illustrated book California State Polytechnic University, Pomona: A Legacy documenting the history of the Cal Poly Pomona ranch and and a Mission, 1938-1989 is an heirloom-quality coffee- campus. California State Polytechnic University, table book with over 30 historical photographs, indexed, Pomona — A Legacy and a Mission 1938-1989 tells and displayed in a generous 9 x 11 inch, 294-page the story of a distinctive American university whose origins date hardcover format. Copies of the book can be obtained for back, in a limited sense, to the Gold Rush of 1849. The family of $100 through the University Library. the author, the late Donald H. Pflueger, Professor Emeritus, educator, historian, diplomat, and author, has kindly and To commemorate and honor the philanthropy of the generously pledged the proceeds of the book to the University Pflueger family, the Library will use the donations to Library. -

1St Ontology
THE PURPOSE OF AN ONTOLOGY • To provide a comprehensive description of a certain concept and its relations to other concepts in the same ontology or another ontology WHAT IS AN ONTOLOGY? • Usually an ontology is described as a tree and why should we use it? • But a network is better since more relations can be used cc Per Flensburg 2 1 2 CLASSICAL EXAMPLE BUT WHAT ABOUT THIS? Vehicle Vehicle Land- Water- Land- Water- Airvehicles Airvehicles vehicles vehicles vehicles vehicles Helicopters Airplanes Baloons Helicopters Airplanes Baloons Propeller- Rocket- Jetplanes Passenger- Freight- Sports- Military- planes planes planes planes planes planes Two Four Subsonic- Supersonic- One engine Reconnaissa Bomb- Pursuit- engines engines planes planes nceplanes planes planes cc Per Flensburg 3 cc Per Flensburg 4 3 4 CONFUSING? CLASSICAL EXAMPLE Vehicle Travelling ground • Every level is guided by a principle for distinguish between the Land- Water- Airvehicles objects below. vehicles vehicles • They seem not to be consistent. Lifting principle • This is hidden in a tree diagram, but in a network it can be Helicopters Airplanes Baloons described, since a node in a network has more than one Used for connection. Passenger- Freight- Sports- Military- planes planes planes planes • So let’s see what are the principles in our examples! Used for Reconnaissa Bomb- Pursuit- nceplanes planes planes cc Per Flensburg 5 cc Per Flensburg 6 5 6 BUT WHAT ABOUT THIS? CF A DATA MODEL Vehicle Travelling ground Airplanes Object Land- Water- Airvehicles vehicles vehicles -

Searching Heterogeneous and Distributed Databases: a Case Study from the Maritime Archaeology Community
ResearchOnline@JCU This file is part of the following reference: Hardy, Dianna Lynn (2008) Searching heterogeneous and distributed databases: a case study from the maritime archaeology community. Masters (Research) thesis, James Cook University. Access to this file is available from: http://eprints.jcu.edu.au/1849 Every reasonable effort has been made to gain permission and acknowledge the owner of copyright material. If you are a copyright owner who has been ommitted or incorrectly acknowledged, please contact [email protected] and quote http://eprints.jcu.edu.au/1849 Searching Heterogeneous and Distributed Databases: A Case Study from the Maritime Archaeology Community Thesis submitted by Dianna Lynn HARDY Bachelor of Arts - Computer Science, Graduate Diploma - Archaeology In partial fulfillment of the Degree of Master of Social Science by Research at James Cook University. Archaeology, School of Anthropology, Archaeology and Sociology James Cook University March 2008 Statement of Access I, the undersigned, the author of this thesis, understand that James Cook University will make it available for use within the University library and, by microfilm or other photographic means, allow access to users in other approved libraries. All users consulting this thesis will have to sign the following statement: “In consulting this thesis I agree not to copy or closely paraphrase it in whole or in part without written consent of the author; and to make proper written acknowledgement for any assistance which I have obtained from it”. Beyond this, I do not wish to place any restrictions on access to this thesis. …………………………………… …………………………… (signature) (date) ii Statement on Sources DECLARATION I declare that this thesis is my own work and has not been submitted in any form for another degree or diploma at any university or other institution of tertiary education. -
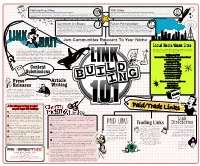
Link Directories at Your Own Risk
Networking Sites: Wiki Sites: Not to be confused with Social News sites, Networking sites (www.LinkedIn.com, www.Facebook.com, etc) often Many major sites today have added wiki pages with user-edited content. Some may use nofollow, so do your allow links in their profile pages. While it may not carry much link juice, it wouldn't hurt to have some set up for research before spending a lot of time to get a link on a wiki page. your website. Comment On Blogs: Forum Participation: While not as effective as it once was (thanks to that pesky There's a forum for every niche out there, get involved in discussions "nofollow" tag), blog commenting on a regular basis still holds some and link back to quality content on your site that visitors will find weight. If you want links on .edu and .org pages, look for blogs on those useful. Whenever commenting on a forum (or blog) have something VALUABLE type sites (same goes for forums). Surf blogs and comment on a to add to the discussion. Don't just drop a link and run - in case you didn't regular basis. know, that’s called SPAM! LINK Join Communities Relevant To Your Niche BAIT Social Media/News Sites Also known as viral marketing, link bait is anything on a site (content, tools, video, Very popular today - getting your content on quality social media sites a diagram about link building stratagies, etc.) that makes people want to link to it. help rankings and traffic! (Some do use the nofollow attribute). -

The Learn@WU Learning Environment1
The Learn@WU Learning Environment1 Georg Alberer, Peter Alberer, Thomas Enzi, Günther Ernst, Karin Mayrhofer, Gustaf Neumann, Robert Rieder, Bernd Simon Vienna University of Economics and Business Administration Department of Information Systems, New Media Augasse 2-6, A-1090 Vienna, Austria Abstract: This paper is an experience report describing the Learn@WU learning environment, which to our knowledge is one of the largest operational learning environments in higher education. The platform, which is entirely based on open source components, enjoys heavy usage by about 4,000 WU freshmen each year. At present, the learning environment supports 18 high-enrollment courses and contains more than 20,000 – mainly interactive – learning resources. The learning platform has reached a high level of user adoption and is among the top 20 web sites in Austria. This paper describes the overall project as well as the design principles and basic components of the platform. Finally, user adoption figures are presented and discussed. Keywords: E-Learning, Learning Environment, Learning Management, Experience Report 1 Introduction The Vienna University of Economics and Business Administration (German: Wirtschaftsuniversität Wien, abbreviated WU) is one of the largest business schools worldwide. It has a total of more than 25,000 students, and more than 4,000 freshmen enrolled for the academic year starting in October 2002. Each semester, approximately 2,000 courses are offered at the WU. In the fall of 2002/2003, six new degree programs (Business Administration, International Business Administration, Economics, Business and Economics, Business Education and Information Systems) were introduced in parallel to replace the degree programs taught to date. -

(12) United States Patent (10) Patent No.: US 7,133,862 B2 Hubert Et Al
US007133862B2 (12) United States Patent (10) Patent No.: US 7,133,862 B2 Hubert et al. (45) Date of Patent: Nov. 7, 2006 (54) SYSTEM WITH USER DIRECTED 5,940,614 A 8, 1999 Allen et al. ................. 717/120 ENRICHMENT AND IMPORTFEXPORT 6,092,074. A 7/2000 Rodkin et al. ... 707/102 CONTROL 6,138,129 A * 10/2000 Combs .......................... 707/6 6,161,124. A 12/2000 Takagawa et al. .......... TO9,203 (75) Inventors: Laurence Hubert, St Bernard du 6.256,623 B1 7/2001 Jones ............................ 707/3 Touvet (FR); Nicolas Guerin, Grenoble 6,594,662 B1* 7/2003 Sieffert et al. ................ 707/10 (FR) FOREIGN PATENT DOCUMENTS (73) Assignee: Xerox Corporation, Stamford, CT (US) EP O 986 010 A2 3, 2000 EP 1 087 306 A2 3, 2001 *) Notice: Subject to anyy disclaimer, the term of this WO WOOOf 67159 A2 11/2000 patent is extended or adjusted under 35 WO WO O1/31479 A1 5, 2001 U.S.C. 154(b) by 582 days. OTHER PUBLICATIONS (21) Appl. No.: 09/683,237 U.S. Appl. No. 09/746,917 “Recommender System and Method”. (22) Filed: Dec. 5, 2001 filed Dec. 22, 2000. Alexa Internet, "Alexa What's Related for Netscape Navigator'. (65) Prior Publication Data available on the Internet Apr. 2001 at http://www.alexa.com/ prod Serv/netscape.html. US 2003 FOO612OO A1 Mar. 27, 2003 Alexa Internet, "Alexa Related Links for Microsoft IE', available on the Internet Apr. 2001 at http://www.alexa.com/prod serv/msie. Related U.S. Application Data html. Autonomy, Technology White Paper, available on the Internet Apr. -

Weblog Resources
FAQ: Weblog resources [Up: Robot Wisdom Weblog] [Robot Wisdom home page] Weblog resources FAQ Jorn Barger, September 1999 What is a weblog? A weblog (sometimes called a blog or a newspage or a filter) is a webpage where a weblogger (sometimes called a blogger, or a pre-surfer) 'logs' all the other webpages she finds interesting. The format is normally to add the newest entry at the top of the page, so that repeat visitors can catch up by simply reading down the page until they reach a link they saw on their last visit. (This causes some minor, unavoidable confusions when the logger comments on an earlier link that the visitor hasn't reached yet.) Wasn't the name 'weblog' already taken for server-logs/ http-logs/ usage-logs/ logfiles? Yeah, well... how many different names do they need, anyway??? (And if you can think of a better name than 'weblog', just start using it and see if it catches on. It's all Darwinian.) Where can I find a listing of weblogs? So many new ones are being started that no complete list exists. The most complete lists currently are: http://www.eatonweb.com/portal/index.shtml http://dmoz.org/Computers/Internet/WWW/Web_Logs/ You can add your own here: http://www.egroups.com/wdb? method=reportRows&listname=weblogs&tbl=1 http://www.robotwisdom.com/weblogs/ (1 of 8)6/20/2005 1:27:56 PM FAQ: Weblog resources Ranked by how often they're linked from other sites: http://beebo.org/metalog/ratings/ Which ones have updated most recently: http://www.linkwatcher.com/ and http:// subhonker2.userland.com/weblogMonitor/ A utility that creates a custom surfmenu of weblogs. -

DATA MINING the WEB Uncovering Patterns in Web Content, Structure, and Usage
SPH SPH JWDD053-FM JWDD053-Markov March 8, 2007 22:51 Char Count= 0 DATA MINING THE WEB Uncovering Patterns in Web Content, Structure, and Usage ZDRAVKO MARKOV AND DANIEL T. LAROSE Central Connecticut State University New Britain, CT WILEY-INTERSCIENCE A JOHN WILEY & SONS, INC., PUBLICATION iii SPH SPH JWDD053-FM JWDD053-Markov March 8, 2007 22:51 Char Count= 0 vi SPH SPH JWDD053-FM JWDD053-Markov March 8, 2007 22:51 Char Count= 0 DATA MINING THE WEB i SPH SPH JWDD053-FM JWDD053-Markov March 8, 2007 22:51 Char Count= 0 ii SPH SPH JWDD053-FM JWDD053-Markov March 8, 2007 22:51 Char Count= 0 DATA MINING THE WEB Uncovering Patterns in Web Content, Structure, and Usage ZDRAVKO MARKOV AND DANIEL T. LAROSE Central Connecticut State University New Britain, CT WILEY-INTERSCIENCE A JOHN WILEY & SONS, INC., PUBLICATION iii SPH SPH JWDD053-FM JWDD053-Markov March 8, 2007 22:51 Char Count= 0 Copyright C 2007 by John Wiley & Sons, Inc. All rights reserved. Published by John Wiley & Sons, Inc., Hoboken, New Jersey Published simultaneously in Canada No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning, or otherwise, except as permitted under Section 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, Inc., 222 Rosewood Drive, Danvers, MA 01923, 978-750-8400, fax 978-750-4470, or on the web at www.copyright.com.