Using a Web Archiving Service 20170831-Final.Pdf (PDF, 150.78KB)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Link ? Rot: URI Citation Durability in 10 Years of Ausweb Proceedings
Link? Rot. URI Citation Durability in 10 Years of AusWeb Proceedings. Link? Rot. URI Citation Durability in 10 Years of AusWeb Proceedings. Baden Hughes [HREF1], Research Fellow, Department of Computer Science and Software Engineering [HREF2] , The University of Melbourne [HREF3], Victoria, 3010, Australia. [email protected] Abstract The AusWeb conference has played a significant role in promoting and advancing research in web technologies in Australia over the last decade. Papers contributed to AusWeb are highly connected to the web in general, to digital libraries and to other conference sites in particular, owing to the publication of proceedings in HTML and full support for hyperlink based referencing. Authors have exploited this medium progressively more effectively, with the vast majority of references for AusWeb papers now being URIs as opposed to more traditional citation forms. The objective of this paper is to examine the reliability of URI citations in 10 years worth of AusWeb proceedings, particularly to determine the durability of such references, and to classify their causes of unavailability. Introduction The AusWeb conference has played a significant role in promoting and advancing research in web technologies in Australia over the last decade. In addition, the AusWeb forum serves as a point of reflection for practitioners engaged in web infrastructure, content and policy development; allowing the distillation of best practice in the management of web services particularly in higher educational institutions in the Australasian region. Papers contributed to AusWeb are highly connected to the web in general, to digital libraries and to other conference sites in particular, owing to the publication of proceedings in HTML and full support for hyperlink based referencing. -

Modeling Popularity and Reliability of Sources in Multilingual Wikipedia
information Article Modeling Popularity and Reliability of Sources in Multilingual Wikipedia Włodzimierz Lewoniewski * , Krzysztof W˛ecel and Witold Abramowicz Department of Information Systems, Pozna´nUniversity of Economics and Business, 61-875 Pozna´n,Poland; [email protected] (K.W.); [email protected] (W.A.) * Correspondence: [email protected] Received: 31 March 2020; Accepted: 7 May 2020; Published: 13 May 2020 Abstract: One of the most important factors impacting quality of content in Wikipedia is presence of reliable sources. By following references, readers can verify facts or find more details about described topic. A Wikipedia article can be edited independently in any of over 300 languages, even by anonymous users, therefore information about the same topic may be inconsistent. This also applies to use of references in different language versions of a particular article, so the same statement can have different sources. In this paper we analyzed over 40 million articles from the 55 most developed language versions of Wikipedia to extract information about over 200 million references and find the most popular and reliable sources. We presented 10 models for the assessment of the popularity and reliability of the sources based on analysis of meta information about the references in Wikipedia articles, page views and authors of the articles. Using DBpedia and Wikidata we automatically identified the alignment of the sources to a specific domain. Additionally, we analyzed the changes of popularity and reliability in time and identified growth leaders in each of the considered months. The results can be used for quality improvements of the content in different languages versions of Wikipedia. -

Cultural Anthropology and the Infrastructure of Publishing
CULTURAL ANTHROPOLOGY AND THE INFRASTRUCTURE OF PUBLISHING TIMOTHY W. ELFENBEIN Society for Cultural Anthropology This essay is based on an interview conducted by Matt Thompson, portions of which originally appeared on the blog Savage Minds the week after Cultural Anthropology relaunched as an open-access journal.1 Herein, I elaborate on my original comments to provide a nuts-and-bolts account of what has gone into the journal’s transition. I am particularly concerned to lay bare the publishing side of this endeavor—of what it means for a scholarly society to take on publishing responsibilities—since the challenges of pub- lishing, and the labor and infrastructure involved, are invisible to most authors and readers. Matt Thompson: When did the Society for Cultural Anthropology (SCA) de- cide to go the open-access route and what was motivating them? Tim Elfenbein: Cultural Anthropology was one of the first American Anthropo- logical Association (AAA) journals to start its own website. Kim and Mike Fortun were responsible for the initial site. They wanted to know what extra materials they could put on a website that would supplement the journal’s articles. That experience helped germinate the idea that there was more that the journal could do itself. The Fortuns are also heavily involved in science and technology studies 2 (STS), where discussions about open access have been occurring for a long time. When Anne Allison and Charlie Piot took over as editors of the journal in 2011, they continued to push for an open-access alternative in our publishing program. Although the SCA and others had been making the argument for transitioning at CULTURAL ANTHROPOLOGY, Vol. -

Wikipedia and Medicine: Quantifying Readership, Editors, and the Significance of Natural Language
JOURNAL OF MEDICAL INTERNET RESEARCH Heilman & West Original Paper Wikipedia and Medicine: Quantifying Readership, Editors, and the Significance of Natural Language James M Heilman1, BSc, MD, CCFP(EM); Andrew G West2, PhD, MS Eng 1Faculty of Medicine, Department of Emergency Medicine, University of British Columbia, Vancouver, BC, Canada 2Verisign Labs (Verisign, Inc.), Reston, VA, United States Corresponding Author: James M Heilman, BSc, MD, CCFP(EM) Faculty of Medicine Department of Emergency Medicine University of British Columbia 2194 Health Sciences Mall, Unit 317 Vancouver, BC, V6T1Z3 Canada Phone: 1 4158306381 Fax: 1 6048226061 Email: [email protected] Abstract Background: Wikipedia is a collaboratively edited encyclopedia. One of the most popular websites on the Internet, it is known to be a frequently used source of health care information by both professionals and the lay public. Objective: This paper quantifies the production and consumption of Wikipedia's medical content along 4 dimensions. First, we measured the amount of medical content in both articles and bytes and, second, the citations that supported that content. Third, we analyzed the medical readership against that of other health care websites between Wikipedia's natural language editions and its relationship with disease prevalence. Fourth, we surveyed the quantity/characteristics of Wikipedia's medical contributors, including year-over-year participation trends and editor demographics. Methods: Using a well-defined categorization infrastructure, we identified medically pertinent English-language Wikipedia articles and links to their foreign language equivalents. With these, Wikipedia can be queried to produce metadata and full texts for entire article histories. Wikipedia also makes available hourly reports that aggregate reader traffic at per-article granularity. -

Web Archiving Supplementary Guidelines
LIBRARY OF CONGRESS COLLECTIONS POLICY STATEMENTS SUPPLEMENTARY GUIDELINES Web Archiving Contents I. Scope II. Current Practice III. Research Strengths IV. Collecting Policy I. Scope The Library's traditional functions of acquiring, cataloging, preserving and serving collection materials of historical importance to Congress and the American people extend to digital materials, including web sites. The Library acquires and makes permanently accessible born digital works that are playing an increasingly important role in the intellectual, commercial and creative life of the United States. Given the vast size and growing comprehensiveness of the Internet, as well as the short life‐span of much of its content, the Library must: (1) define the scope and priorities for its web collecting, and (2) develop partnerships and cooperative relationships required to continue fulfilling its vital historic mission in order to supplement the Library’s capacity. The contents of a web site may range from ephemeral social media content to digital versions of formal publications that are also available in print. Web archiving preserves as much of the web‐based user experience as technologically possible in order to provide future users accurate snapshots of what particular organizations and individuals presented on the archived sites at particular moments in time, including how the intellectual content (such as text) is framed by the web site implementation. The guidelines in this document apply to the Library’s effort to acquire web sites and related content via harvesting in‐house, through contract services and purchase. It also covers collaborative web archiving efforts with external groups, such as the International Internet Preservation Consortium (IIPC). -

Web Archiving and You Web Archiving and Us
Web Archiving and You Web Archiving and Us Amy Wickner University of Maryland Libraries Code4Lib 2018 Slides & Resources: https://osf.io/ex6ny/ Hello, thank you for this opportunity to talk about web archives and archiving. This talk is about what stakes the code4lib community might have in documenting particular experiences of the live web. In addition to slides, I’m leading with a list of material, tools, and trainings I read and relied on in putting this talk together. Despite the limited scope of the talk, I hope you’ll each find something of personal relevance to pursue further. “ the process of collecting portions of the World Wide Web, preserving the collections in an archival format, and then serving the archives for access and use International Internet Preservation Coalition To begin, here’s how the International Internet Preservation Consortium or IIPC defines web archiving. Let’s break this down a little. “Collecting portions” means not collecting everything: there’s generally a process of selection. “Archival format” implies that long-term preservation and stewardship are the goals of collecting material from the web. And “serving the archives for access and use” implies a stewarding entity conceptually separate from the bodies of creators and users of archives. It also implies that there is no web archiving without access and use. As we go along, we’ll see examples that both reinforce and trouble these assumptions. A point of clarity about wording: when I say for example “critique,” “question,” or “trouble” as a verb, I mean inquiry rather than judgement or condemnation. we are collectors So, preambles mostly over. -

Web Archiving for Academic Institutions
University of San Diego Digital USD Digital Initiatives Symposium Apr 23rd, 1:00 PM - 4:00 PM Web Archiving for Academic Institutions Lori Donovan Internet Archive Mary Haberle Internet Archive Follow this and additional works at: https://digital.sandiego.edu/symposium Donovan, Lori and Haberle, Mary, "Web Archiving for Academic Institutions" (2018). Digital Initiatives Symposium. 4. https://digital.sandiego.edu/symposium/2018/2018/4 This Workshop is brought to you for free and open access by Digital USD. It has been accepted for inclusion in Digital Initiatives Symposium by an authorized administrator of Digital USD. For more information, please contact [email protected]. Web Archiving for Academic Institutions Presenter 1 Title Senior Program Manager, Archive-It Presenter 2 Title Web Archivist Session Type Workshop Abstract With the advent of the internet, content that institutional archivists once preserved in physical formats is now web-based, and new avenues for information sharing, interaction and record-keeping are fundamentally changing how the history of the 21st century will be studied. Due to the transient nature of web content, much of this information is at risk. This half-day workshop will cover the basics of web archiving, help attendees identify content of interest to them and their communities, and give them an opportunity to interact with tools that assist with the capture and preservation of web content. Attendees will gain hands-on web archiving skills, insights into selection and collecting policies for web archives and how to apply what they've learned in the workshop to their own organizations. Location KIPJ Room B Comments Lori Donovan works with partners and the Internet Archive’s web archivists and engineering team to develop the Archive-It service so that it meets the needs of memory institutions. -

情報管理 O U R Nal of Information Pr Ocessing and Managemen T December
JOHO KANRI 2009 vol.52 no.9 http://johokanri.jp/ J情報管理 o u r nal of Information Pr ocessing and Managemen t December 世界の知識の図書館を目指すInternet Archive 創設者Brewster Kahleへのインタビュー Internet Archive aims to build a library of world knowledge An interview with the founder, Brewster Kahle 時実 象一1 TOKIZANE Soichi1 1 愛知大学文学部(〒441-8522 愛知県豊橋市町畑町1-1)E-mail : [email protected] 1 Faculty of Letters, Aichi University (1-1 Machihata-cho Toyohashi-shi, Aichi 441-8522) 原稿受理(2009-09-25) (情報管理 52(9), 534-542) 著者抄録 Internet ArchiveはBrewster Kahleによって1996年に設立された非営利団体で,過去のインターネットWebサイトを保存し ているWayback Machineで知られているほか,動画,音楽,音声の電子アーカイブを公開し,またGoogleと同様書籍の電 子化を行っている。Wayback Machineは1996年からの5,000万サイトに対応する1,500億ページのデータを保存・公開し ている。書籍の電子化はScribeと呼ばれる独自開発の撮影機を用い,ボストン公共図書館などと協力して1日1,000冊の ペースで電子化している。電子化したデータを用いて子供たちに本を配るBookmobileという活動も行っている。Kahle氏 はGoogle Book Searchの和解に批判的な意見を述べているほか,孤児著作物の利用促進やOne Laptop Per Child(OLPC)運 動への協力も行っている。 キーワード Webアーカイブ,Wayback Machine,書籍電子化,Google Book Search,新アレキサンドリア図書館,Open Content Alliance,Open Book Alliance 1. はじめに Googleと同様書籍の電子化を行っている。インター ネットが一般に使えるようになったのが1995年で Internet Archive注1)はBrewster Kahle(ケールと発 あるから,Internet Archiveはインターネットとほぼ 音する)によって1996年に設立された非営利団体 同時に誕生したことになる。現在年間運営費は約 である。過去のインターネットW e bサイトを保存 1,000万ドルであり,政府や財団の補助や寄付で運 しているWayback Machine1)で知られているほか, 営している。この(2009年)5月にKahle氏(以下敬 534 JOHO KANRI 世界の知識の図書館を目指すInternet Archive 2009 vol.52 no.9 http://johokanri.jp/ J情報管理 o u r nal of Information Pr ocessing and Managemen t December 称略)を訪ね,インタビューを行ったので報告する A O Lに売却した。その売却益によって翌年I n t e r n e t (写真1)。 Archiveを立ち上げたのである。 K a h l eは1982年 に マ サ チ ュ ー セ ッ ツ 工 科 大 学 (Massachusetts Institute of Technology: MIT)のコン 2. Internet Archiveの事業 ピュータ科学工学科を卒業した。 2000年前エジプトのアレキサンドリアには当時 2.1 Wayback Machine 世界最大の図書館があり,パピルスに書かれた書物 I n t e r n e t A r c h i v eのホームページのU R Lはw w w . -

Web Archiving in the UK: Current
CITY UNIVERSITY LONDON Web Archiving in the UK: Current Developments and Reflections for the Future Aquiles Ratti Alencar Brayner January 2011 Submitted in partial fulfillment of the requirements for the degree of MSc in Library Science Supervisor: Lyn Robinson 1 Abstract This work presents a brief overview on the history of Web archiving projects in some English speaking countries, paying particular attention to the development and main problems faced by the UK Web Archive Consortium (UKWAC) and UK Web Archive partnership in Britain. It highlights, particularly, the changeable nature of Web pages through constant content removal and/or alteration and the evolving technological innovations brought recently by Web 2.0 applications, discussing how these factors have an impact on Web archiving projects. It also examines different collecting approaches, harvesting software limitations and how the current copyright and deposit regulations in the UK covering digital contents are failing to support Web archive projects in the country. From the perspective of users’ access, this dissertation offers an analysis of UK Web archive interfaces identifying their main drawbacks and suggesting how these could be further improved in order to better respond to users’ information needs and access to archived Web content. 2 Table of Contents Abstract 2 Acknowledgements 5 Introduction 6 Part I: Current situation of Web archives 9 1. Development in Web archiving 10 2. Web archiving: approaches and models 14 3. Harvesting and preservation of Web content 19 3.1 The UK Web space 19 3.2 The changeable nature of Web pages 20 3.3 The evolution of Web 2.0 applications 23 4. -

Librarians and Link Rot: a Comparative Analysis with Some Methodological Considerations
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Faculty Publications, UNL Libraries Libraries at University of Nebraska-Lincoln 10-15-2003 Librarians and Link Rot: A Comparative Analysis with Some Methodological Considerations David C. Tyler University of Nebraska-Lincoln, [email protected] Beth McNeil University of Nebraska-Lincoln, [email protected] Follow this and additional works at: https://digitalcommons.unl.edu/libraryscience Part of the Library and Information Science Commons Tyler, David C. and McNeil, Beth, "Librarians and Link Rot: A Comparative Analysis with Some Methodological Considerations" (2003). Faculty Publications, UNL Libraries. 62. https://digitalcommons.unl.edu/libraryscience/62 This Article is brought to you for free and open access by the Libraries at University of Nebraska-Lincoln at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in Faculty Publications, UNL Libraries by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. David C. Tyler and Beth McNeil 615 Librarians and Link Rot: A Comparative Analysis with Some Methodological Considerations David C. Tyler and Beth McNeil abstract: The longevity of printed guides to resources on the web is a topic of some concern to all librarians. This paper attempts to determine whether guides created by specialist librarians perform better than randomly assembled lists of resources (assembled solely for the purpose of web studies), commercially created guides (‘Best of the web’-type publications), and guides prepared by specialists in library science and other fields. The paper also attempts to determine whether the characteristics of included web resources have an impact on guides’ longevity. Lastly, the paper addresses methodological issues of concern to this and similar studies. -

Web Archives for the Analog Archivist: Using Webpages Archived by the Internet Archive to Improve Processing and Description
Journal of Western Archives Volume 9 Issue 1 Article 6 2018 Web Archives for the Analog Archivist: Using Webpages Archived by the Internet Archive to Improve Processing and Description Aleksandr Gelfand New-York Historical Society, [email protected] Follow this and additional works at: https://digitalcommons.usu.edu/westernarchives Part of the Archival Science Commons Recommended Citation Gelfand, Aleksandr (2018) "Web Archives for the Analog Archivist: Using Webpages Archived by the Internet Archive to Improve Processing and Description," Journal of Western Archives: Vol. 9 : Iss. 1 , Article 6. DOI: https://doi.org/10.26077/4944-b95b Available at: https://digitalcommons.usu.edu/westernarchives/vol9/iss1/6 This Case Study is brought to you for free and open access by the Journals at DigitalCommons@USU. It has been accepted for inclusion in Journal of Western Archives by an authorized administrator of DigitalCommons@USU. For more information, please contact [email protected]. Gelfand: Web Archives for the Analog Archivist Web Archives for the Analog Archivist: Using Webpages Archived by the Internet Archive to Improve Processing and Description Aleksandr Gelfand ABSTRACT Twenty years ago the Internet Archive was founded with the wide-ranging mission of providing universal access to all knowledge. In the two decades since, that organization has captured and made accessible over 150 billion websites. By incorporating the use of Internet Archive's Wayback Machine into their workflows, archivists working primarily with analog records may enhance their ability in such tasks as the construction of a processing plan, the creation of more accurate historical descriptions for finding aids, and potentially be able to provide better reference services to their patrons. -
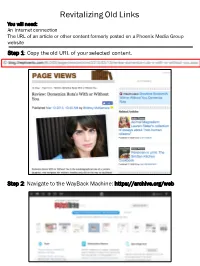
Wayback Machine Instructions
Revitalizing Old Links You will need: An Internet connection The URL of an article or other content formerly posted on a Phoenix Media Group website Step 1: Copy the old URL of your selected content. Step 2: Navigate to the WayBack Machine: https://archive.org/web Step 3: Input the copied URL of your content into the search box on the Wayback Machine home page. Hit Enter or click “Browse History”. Step 4: The WayBack Machine will retrieve a page that displays the original URL of your content, the number of times that content has been captured by the WayBack Machine, and a calendar. If you would like to access the most recently captured version of the content, click the most recent “snapshot” date on the calendar (dates on which the content was captured are marked with blue circles). If the content has been edited or changed and you would like to access an older saved version, navigate through the calendar to your desired “snapshot” date. Select the most recent save date to view the most recently saved Select the year, then version of the month and date to view content. an older version of the content. Black bars indicate years in which the content was captured. Step 5: The WayBack Machine will redirect you to the preserved snapshot of the page from the date you selected. Please note that some original content, such as advertisements, JavaScript or Flash videos, may not be saved. This URL directs to the saved version of the material; replace any outdated links to the content with this URL.