Downloading the Nucleotide Sequences and Scanning Them Against the Database
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

WO 2013/102674 A2 11 July 2013 (11.07.2013) W P O P C T
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization International Bureau (10) International Publication Number (43) International Publication Date WO 2013/102674 A2 11 July 2013 (11.07.2013) W P O P C T (51) International Patent Classification: (74) Agent: CABINET PLASSERAUD; 235 cours Lafayette, C12N 1/15 (2006.01) F-69006 Lyon (FR). (21) International Application Number: (81) Designated States (unless otherwise indicated, for every PCT/EP20 13/050 126 kind of national protection available): AE, AG, AL, AM, AO, AT, AU, AZ, BA, BB, BG, BH, BN, BR, BW, BY, (22) Date: International Filing BZ, CA, CH, CL, CN, CO, CR, CU, CZ, DE, DK, DM, 4 January 2013 (04.01 .2013) DO, DZ, EC, EE, EG, ES, FI, GB, GD, GE, GH, GM, GT, (25) Filing Language: English HN, HR, HU, ID, IL, IN, IS, JP, KE, KG, KM, KN, KP, KR, KZ, LA, LC, LK, LR, LS, LT, LU, LY, MA, MD, (26) Publication Language: English ME, MG, MK, MN, MW, MX, MY, MZ, NA, NG, NI, (30) Priority Data: NO, NZ, OM, PA, PE, PG, PH, PL, PT, QA, RO, RS, RU, 61/583,559 5 January 2012 (05.01 .2012) US RW, SC, SD, SE, SG, SK, SL, SM, ST, SV, SY, TH, TJ, TM, TN, TR, TT, TZ, UA, UG, US, UZ, VC, VN, ZA, (71) Applicants: NOVARTIS INTERNATIONAL PHAR¬ ZM, ZW. MACEUTICAL LTD.; 13 1 Front Street, Hamilton (BM). GLYKOS FINLAND OY [FI/FI]; Viikinkaari 6, FI- (84) Designated States (unless otherwise indicated, for every 00790 Helsinki (FI). -

Enzymatic Encoding Methods for Efficient Synthesis Of
(19) TZZ__T (11) EP 1 957 644 B1 (12) EUROPEAN PATENT SPECIFICATION (45) Date of publication and mention (51) Int Cl.: of the grant of the patent: C12N 15/10 (2006.01) C12Q 1/68 (2006.01) 01.12.2010 Bulletin 2010/48 C40B 40/06 (2006.01) C40B 50/06 (2006.01) (21) Application number: 06818144.5 (86) International application number: PCT/DK2006/000685 (22) Date of filing: 01.12.2006 (87) International publication number: WO 2007/062664 (07.06.2007 Gazette 2007/23) (54) ENZYMATIC ENCODING METHODS FOR EFFICIENT SYNTHESIS OF LARGE LIBRARIES ENZYMVERMITTELNDE KODIERUNGSMETHODEN FÜR EINE EFFIZIENTE SYNTHESE VON GROSSEN BIBLIOTHEKEN PROCEDES DE CODAGE ENZYMATIQUE DESTINES A LA SYNTHESE EFFICACE DE BIBLIOTHEQUES IMPORTANTES (84) Designated Contracting States: • GOLDBECH, Anne AT BE BG CH CY CZ DE DK EE ES FI FR GB GR DK-2200 Copenhagen N (DK) HU IE IS IT LI LT LU LV MC NL PL PT RO SE SI • DE LEON, Daen SK TR DK-2300 Copenhagen S (DK) Designated Extension States: • KALDOR, Ditte Kievsmose AL BA HR MK RS DK-2880 Bagsvaerd (DK) • SLØK, Frank Abilgaard (30) Priority: 01.12.2005 DK 200501704 DK-3450 Allerød (DK) 02.12.2005 US 741490 P • HUSEMOEN, Birgitte Nystrup DK-2500 Valby (DK) (43) Date of publication of application: • DOLBERG, Johannes 20.08.2008 Bulletin 2008/34 DK-1674 Copenhagen V (DK) • JENSEN, Kim Birkebæk (73) Proprietor: Nuevolution A/S DK-2610 Rødovre (DK) 2100 Copenhagen 0 (DK) • PETERSEN, Lene DK-2100 Copenhagen Ø (DK) (72) Inventors: • NØRREGAARD-MADSEN, Mads • FRANCH, Thomas DK-3460 Birkerød (DK) DK-3070 Snekkersten (DK) • GODSKESEN, -

B Number Gene Name Mrna Intensity Mrna
sample) total list predicted B number Gene name assignment mRNA present mRNA intensity Gene description Protein detected - Membrane protein membrane sample detected (total list) Proteins detected - Functional category # of tryptic peptides # of tryptic peptides # of tryptic peptides detected (membrane b0002 thrA 13624 P 39 P 18 P(m) 2 aspartokinase I, homoserine dehydrogenase I Metabolism of small molecules b0003 thrB 6781 P 9 P 3 0 homoserine kinase Metabolism of small molecules b0004 thrC 15039 P 18 P 10 0 threonine synthase Metabolism of small molecules b0008 talB 20561 P 20 P 13 0 transaldolase B Metabolism of small molecules chaperone Hsp70; DNA biosynthesis; autoregulated heat shock b0014 dnaK 13283 P 32 P 23 0 proteins Cell processes b0015 dnaJ 4492 P 13 P 4 P(m) 1 chaperone with DnaK; heat shock protein Cell processes b0029 lytB 1331 P 16 P 2 0 control of stringent response; involved in penicillin tolerance Global functions b0032 carA 9312 P 14 P 8 0 carbamoyl-phosphate synthetase, glutamine (small) subunit Metabolism of small molecules b0033 carB 7656 P 48 P 17 0 carbamoyl-phosphate synthase large subunit Metabolism of small molecules b0048 folA 1588 P 7 P 1 0 dihydrofolate reductase type I; trimethoprim resistance Metabolism of small molecules peptidyl-prolyl cis-trans isomerase (PPIase), involved in maturation of b0053 surA 3825 P 19 P 4 P(m) 1 GenProt outer membrane proteins (1st module) Cell processes b0054 imp 2737 P 42 P 5 P(m) 5 GenProt organic solvent tolerance Cell processes b0071 leuD 4770 P 10 P 9 0 isopropylmalate -

Molecular Modelling for Enzyme-Inhibition: a Search for a New Treatment for Cataract and New Antimicrobials and Herbicides
Molecular Modelling for Enzyme-Inhibition: A Search for a New Treatment for Cataract and New Antimicrobials and Herbicides A thesis submitted in partial fulfilment of the requirements for the Degree of Doctor of Philosophy in Biochemistry at the University of Canterbury Christchurch New Zealand Blair Gibb Stuart March 2010 Contents CONTENTS ACKNOWLEDGEMENTS 1 ABSTRACT AND PUBLISHED WORK 2 1 INTRODUCTION 6 1.1 Calpain and the cataract hypothesis 6 1.2 Proteases 7 1.3 Calpains 10 1.4 Structure of the eye, cataract and the importance of an anti-cataract drug 14 1.5 The β-strand: important for protease recognition 15 1.6 Computer modelling programs 17 1.7 References 20 2 DEVELOPMENT OF A CALPAIN MODEL FOR DOCKING STUDIES 27 2.1 Introduction 27 2.1.1 Overview of calpain model development 27 2.2 Calpain X-ray crystal structures 28 2.2.1 The first published structures 28 2.2.2 Calpain constructs 1KXR and 1MDW 30 2.3 Exploring the calpain construct 1KXR to develop a viable model for Glide docking experiments 33 2.4 The InducedFit docking model 37 Contents 2.5 Conclusion 37 2.6 References 39 3 MOLECULAR MODELING OF ACYCLIC INHIBITORS 43 3.1 Introduction 43 3.1.1 Natural inhibitors 43 3.1.2 Modified natural inhibitors 45 3.1.3 Lead compound: SJA-6017 46 3.2 Docking studies of known inhibitors 46 3.2.1 Compounds of Inoue et al 46 3.2.2 Docking results for the Inoue et al compounds 50 3.3 Docking Studies of SJA-6017 analogues 58 3.3.1 N-Heterocyclic dipeptides 58 3.3.2 Docking results of N-heterocyclic dipeptides 60 3.4 Docking studies of diazo and -

Product Sheet Info
Master Clone List for NR-19279 ® Vibrio cholerae Gateway Clone Set, Recombinant in Escherichia coli, Plates 1-46 Catalog No. NR-19279 Table 1: Vibrio cholerae Gateway® Clones, Plate 1 (NR-19679) Clone ID Well ORF Locus ID Symbol Product Accession Position Length Number 174071 A02 367 VC2271 ribD riboflavin-specific deaminase NP_231902.1 174346 A03 336 VC1877 lpxK tetraacyldisaccharide 4`-kinase NP_231511.1 174354 A04 342 VC0953 holA DNA polymerase III, delta subunit NP_230600.1 174115 A05 388 VC2085 sucC succinyl-CoA synthase, beta subunit NP_231717.1 174310 A06 506 VC2400 murC UDP-N-acetylmuramate--alanine ligase NP_232030.1 174523 A07 132 VC0644 rbfA ribosome-binding factor A NP_230293.2 174632 A08 322 VC0681 ribF riboflavin kinase-FMN adenylyltransferase NP_230330.1 174930 A09 433 VC0720 phoR histidine protein kinase PhoR NP_230369.1 174953 A10 206 VC1178 conserved hypothetical protein NP_230823.1 174976 A11 213 VC2358 hypothetical protein NP_231988.1 174898 A12 369 VC0154 trmA tRNA (uracil-5-)-methyltransferase NP_229811.1 174059 B01 73 VC2098 hypothetical protein NP_231730.1 174075 B02 82 VC0561 rpsP ribosomal protein S16 NP_230212.1 174087 B03 378 VC1843 cydB-1 cytochrome d ubiquinol oxidase, subunit II NP_231477.1 174099 B04 383 VC1798 eha eha protein NP_231433.1 174294 B05 494 VC0763 GTP-binding protein NP_230412.1 174311 B06 314 VC2183 prsA ribose-phosphate pyrophosphokinase NP_231814.1 174603 B07 108 VC0675 thyA thymidylate synthase NP_230324.1 174474 B08 466 VC1297 asnS asparaginyl-tRNA synthetase NP_230942.2 174933 B09 198 -

Galhenage Thanusha Ranithri Abeynayake
Development of hydrolysates with antioxidant effects from brewers’ spent grain proteins by Galhenage Thanusha Ranithri Abeynayake A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Food Science and Technology Department of Agricultural, Food and Nutritional Science University of Alberta © Galhenage Thanusha Ranithri Abeynayake, 2020 Abstract Brewers’ spent grain (BSG), the most abundant brewing by-product contains up to 24% (w/w) of protein on dry basis. Despite of a rich protein source, it is still mainly used as low value animal feed. This study was conducted to develop hydrolysates with antioxidant effects from BSG proteins by enzymatic hydrolysis, and study BSG peptide antioxidant activities in relation to molecular structures. The BSG proteins were extracted by alkaline method with a protein content of 62.6% (w/w) and a protein recovery of 46.3%. The proteins were then hydrolyzed by selected proteases or protease combinations having different specificities. Resulting hydrolysates were analyzed for their molecular structures such as hydrolysis degree, amino acid composition, molecular weight and conformation, and their antioxidant effects were measured by reducing power, DPPH radical scavenging, ferrous chelating and superoxide radical scavenging assays. Hydrolysates prepared by alcalase and alcalase combined treatments with neutrase, flavourzyme and everlase showed the highest DPPH radical scavenging activities ranged between 72.6-74.9% at the hydrolysate concentration of 1.0 mg/mL. It could be due to specific activity of alcalase to produce amino acid sequences with greater DPPH radical scavenging potential. Similarly, high proton donation ability of the imidazole ring present in the side chain of histidine may have strong ability to scavenge the DPPH radical. -

The Role of Proteases in Plant Development
The Role of Proteases in Plant Development Maribel García-Lorenzo Department of Chemistry, Umeå University Umeå 2007 i Department of Chemistry Umeå University SE - 901 87 Umeå, Sweden Copyright © 2007 by Maribel García-Lorenzo ISBN: 978-91-7264-422-9 Printed in Sweden by VMC-KBC Umeå University, Umeå 2007 ii Organization Document name UMEÅ UNIVERSITY DOCTORAL DISSERTATION Department of Chemistry SE - 901 87 Umeå, Sweden Date of issue October 2007 Author Maribel García-Lorenzo Title The Role of Proteases in Plant Development. Abstract Proteases play key roles in plants, maintaining strict protein quality control and degrading specific sets of proteins in response to diverse environmental and developmental stimuli. Similarities and differences between the proteases expressed in different species may give valuable insights into their physiological roles and evolution. Systematic comparative analysis of the available sequenced genomes of two model organisms led to the identification of an increasing number of protease genes, giving insights about protein sequences that are conserved in the different species, and thus are likely to have common functions in them and the acquisition of new genes, elucidate issues concerning non-functionalization, neofunctionalization and subfunctionalization. The involvement of proteases in senescence and PCD was investigated. While PCD in woody tissues shows the importance of vacuole proteases in the process, the senescence in leaves demonstrate to be a slower and more ordered mechanism starting in the chloroplast where the proteases there localized become important. The light-harvesting complex of Photosystem II is very susceptible to protease attack during leaf senescence. We were able to show that a metallo-protease belonging to the FtsH family is involved on the process in vitro. -

Proteolytic Cleavage—Mechanisms, Function
Review Cite This: Chem. Rev. 2018, 118, 1137−1168 pubs.acs.org/CR Proteolytic CleavageMechanisms, Function, and “Omic” Approaches for a Near-Ubiquitous Posttranslational Modification Theo Klein,†,⊥ Ulrich Eckhard,†,§ Antoine Dufour,†,¶ Nestor Solis,† and Christopher M. Overall*,†,‡ † ‡ Life Sciences Institute, Department of Oral Biological and Medical Sciences, and Department of Biochemistry and Molecular Biology, University of British Columbia, Vancouver, British Columbia V6T 1Z4, Canada ABSTRACT: Proteases enzymatically hydrolyze peptide bonds in substrate proteins, resulting in a widespread, irreversible posttranslational modification of the protein’s structure and biological function. Often regarded as a mere degradative mechanism in destruction of proteins or turnover in maintaining physiological homeostasis, recent research in the field of degradomics has led to the recognition of two main yet unexpected concepts. First, that targeted, limited proteolytic cleavage events by a wide repertoire of proteases are pivotal regulators of most, if not all, physiological and pathological processes. Second, an unexpected in vivo abundance of stable cleaved proteins revealed pervasive, functionally relevant protein processing in normal and diseased tissuefrom 40 to 70% of proteins also occur in vivo as distinct stable proteoforms with undocumented N- or C- termini, meaning these proteoforms are stable functional cleavage products, most with unknown functional implications. In this Review, we discuss the structural biology aspects and mechanisms -
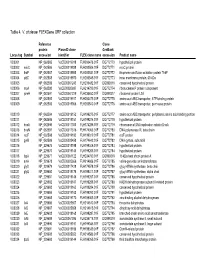
Table 4. V. Cholerae Flexgene ORF Collection
Table 4. V. cholerae FLEXGene ORF collection Reference Clone protein PlasmID clone GenBank Locus tag Symbol accession identifier FLEX clone name accession Product name VC0001 NP_062585 VcCD00019918 FLH200476.01F DQ772770 hypothetical protein VC0002 mioC NP_062586 VcCD00019938 FLH200506.01F DQ772771 mioC protein VC0003 thdF NP_062587 VcCD00019958 FLH200531.01F DQ772772 thiophene and furan oxidation protein ThdF VC0004 yidC NP_062588 VcCD00019970 FLH200545.01F DQ772773 inner membrane protein, 60 kDa VC0005 NP_062589 VcCD00061243 FLH236482.01F DQ899316 conserved hypothetical protein VC0006 rnpA NP_062590 VcCD00025697 FLH214799.01F DQ772774 ribonuclease P protein component VC0007 rpmH NP_062591 VcCD00061229 FLH236450.01F DQ899317 ribosomal protein L34 VC0008 NP_062592 VcCD00019917 FLH200475.01F DQ772775 amino acid ABC transporter, ATP-binding protein VC0009 NP_062593 VcCD00019966 FLH200540.01F DQ772776 amino acid ABC transproter, permease protein VC0010 NP_062594 VcCD00019152 FLH199275.01F DQ772777 amino acid ABC transporter, periplasmic amino acid-binding portion VC0011 NP_062595 VcCD00019151 FLH199274.01F DQ772778 hypothetical protein VC0012 dnaA NP_062596 VcCD00017363 FLH174286.01F DQ772779 chromosomal DNA replication initiator DnaA VC0013 dnaN NP_062597 VcCD00017316 FLH174063.01F DQ772780 DNA polymerase III, beta chain VC0014 recF NP_062598 VcCD00019182 FLH199319.01F DQ772781 recF protein VC0015 gyrB NP_062599 VcCD00025458 FLH174642.01F DQ772782 DNA gyrase, subunit B VC0016 NP_229675 VcCD00019198 FLH199346.01F DQ772783 hypothetical protein -

Intrinsic Evolutionary Constraints on Protease Structure, Enzyme
Intrinsic evolutionary constraints on protease PNAS PLUS structure, enzyme acylation, and the identity of the catalytic triad Andrew R. Buller and Craig A. Townsend1 Departments of Biophysics and Chemistry, The Johns Hopkins University, Baltimore MD 21218 Edited by David Baker, University of Washington, Seattle, WA, and approved January 11, 2013 (received for review December 6, 2012) The study of proteolysis lies at the heart of our understanding of enzyme evolution remain unanswered. Because evolution oper- biocatalysis, enzyme evolution, and drug development. To un- ates through random forces, rationalizing why a particular out- derstand the degree of natural variation in protease active sites, come occurs is a difficult challenge. For example, the hydroxyl we systematically evaluated simple active site features from all nucleophile of a Ser protease was swapped for the thiol of Cys at serine, cysteine and threonine proteases of independent lineage. least twice in evolutionary history (9). However, there is not This convergent evolutionary analysis revealed several interre- a single example of Thr naturally substituting for Ser in the lated and previously unrecognized relationships. The reactive protease catalytic triad, despite its greater chemical similarity rotamer of the nucleophile determines which neighboring amide (9). Instead, the Thr proteases generate their N-terminal nu- can be used in the local oxyanion hole. Each rotamer–oxyanion cleophile through a posttranslational modification: cis-autopro- hole combination limits the location of the moiety facilitating pro- teolysis (10, 11). These facts constitute clear evidence that there ton transfer and, combined together, fixes the stereochemistry of is a strong selective pressure against Thr in the catalytic triad that catalysis. -

Activity-Based Profiling of Proteases
BI83CH11-Bogyo ARI 3 May 2014 11:12 Activity-Based Profiling of Proteases Laura E. Sanman1 and Matthew Bogyo1,2,3 Departments of 1Chemical and Systems Biology, 2Microbiology and Immunology, and 3Pathology, Stanford University School of Medicine, Stanford, California 94305-5324; email: [email protected] Annu. Rev. Biochem. 2014. 83:249–73 Keywords The Annual Review of Biochemistry is online at biochem.annualreviews.org activity-based probes, proteomics, mass spectrometry, affinity handle, fluorescent imaging This article’s doi: 10.1146/annurev-biochem-060713-035352 Abstract Copyright c 2014 by Annual Reviews. All rights reserved Proteolytic enzymes are key signaling molecules in both normal physi- Annu. Rev. Biochem. 2014.83:249-273. Downloaded from www.annualreviews.org ological processes and various diseases. After synthesis, protease activity is tightly controlled. Consequently, levels of protease messenger RNA by Stanford University - Main Campus Lane Medical Library on 08/28/14. For personal use only. and protein often are not good indicators of total protease activity. To more accurately assign function to new proteases, investigators require methods that can be used to detect and quantify proteolysis. In this review, we describe basic principles, recent advances, and applications of biochemical methods to track protease activity, with an emphasis on the use of activity-based probes (ABPs) to detect protease activity. We describe ABP design principles and use case studies to illustrate the ap- plication of ABPs to protease enzymology, discovery and development of protease-targeted drugs, and detection and validation of proteases as biomarkers. 249 BI83CH11-Bogyo ARI 3 May 2014 11:12 gens that contain inhibitory prodomains that Contents must be removed for the protease to become active. -

Identification and Characterization of a Bacterial Glutamic Peptidase
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Copenhagen University Research Information System Identification and characterization of a bacterial glutamic peptidase Jensen, Kenneth; Østergaard, Peter R.; Wilting, Reinhard ; Lassen, Søren F. Published in: BMC Biochemistry DOI: 10.1186/1471-2091-11-47 Publication date: 2010 Document version Publisher's PDF, also known as Version of record Citation for published version (APA): Jensen, K., Østergaard, P. R., Wilting, R., & Lassen, S. F. (2010). Identification and characterization of a bacterial glutamic peptidase. BMC Biochemistry, 11(47). https://doi.org/10.1186/1471-2091-11-47 Download date: 07. Apr. 2020 Jensen et al. BMC Biochemistry 2010, 11:47 http://www.biomedcentral.com/1471-2091/11/47 RESEARCH ARTICLE Open Access Identification and characterization of a bacterial glutamic peptidase Kenneth Jensen1,2*, Peter R Østergaard1, Reinhard Wilting1, Søren F Lassen1 Abstract Background: Glutamic peptidases, from the MEROPS family G1, are a distinct group of peptidases characterized by a catalytic dyad consisting of a glutamate and a glutamine residue, optimal activity at acidic pH and insensitivity towards the microbial derived protease inhibitor, pepstatin. Previously, only glutamic peptidases derived from filamentous fungi have been characterized. Results: We report the first characterization of a bacterial glutamic peptidase (pepG1), derived from the thermoacidophilic bacteria Alicyclobacillus sp. DSM 15716. The amino acid sequence identity between pepG1 and known fungal glutamic peptidases is only 24-30% but homology modeling, the presence of the glutamate/ glutamine catalytic dyad and a number of highly conserved motifs strongly support the inclusion of pepG1 as a glutamic peptidase.