Putting Language on the Map in the European Refugee Response
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Language Specific Peculiarities Document for Kurmanji Kurdish As
Language Specific Peculiarities Document for Kurmanji Kurdish as Spoken in Turkey 1. Special handling of dialects Kurmanji Kurdish is a major branch of modern Kurdish, which belongs to the Iranian group of languages. Kurdish is largely a spoken language with a limited but growing body of modern literature. There are many dialectal varieties of Kurdish spread over a wide area of Turkey, Iraq, Syria, Iran, Armenia and Azerbaijan. There are, in addition, different classifications of Kurdish languages and Kurdish peoples that align dialectal choice with tribal affinity. Linguistic and Kurdish scholars usually describe modern Kurdish as having two closely related major branches: Kurmanji (the northern branch) and Sorani (the southern branch). They are not mutually intelligible (see Thackston (2006) p. vii). The Kurdish Institute summarizes the situation as follows: “Kurdish has two regional standards, namely Kurmanji in Turkey, and Sorani farther east and south. Roughly half of Kurdish speakers live in Turkey.” (see http://www.institutkurde.org/en/ and also http://www.blueglobetranslations.com/about- kurdish-kurmanji-language.html). Within the larger region there are two other languages often associated with ethnic Kurds. These are Dimili (also known as Zazaki) and Gorani. Although sometimes classified as sub-dialects of Kurdish (e.g., Kurdish Language - Britannica Online Encyclopedia), these languages belong to a different group of Iranian languages (see for example, http://kurds_history.enacademic.com/346/Kurmanji). Although Kurmanji Kurdish is spoken across a range of countries, it has the advantage of being spoken by around 60-80% of Kurds and is considered a regional standard. The majority of Kurmanji speakers live in Turkey, making it the ideal country for collection of audio data (see for example, http://linguakurd.blogfa.com/post-106.aspx). -

Cultural and Language Incentive Program – Bonus (CLIP-B) Program Information and Instructions
Cultural and Language Incentive Program – Bonus (CLIP-B) Program Information and Instructions 1. Purpose. The purpose of the Culture and Language Incentive Program – Bonus (CLIP-B) program is to promote the study of languages and cultural studies that are of importance to the Army. 2. Cadet Eligibility. Only contracted Cadets in good standing may request CLIP-B payment. Any classes taken prior to contracting are not eligible for payment. Classes taken during the same term the Cadet contracted are eligible. 3. Eligible Languages. Languages identified in the Department of Defense Strategic Language List and the U.S. Army ALARACT 236/2013 provide the foundation of what languages will be authorized for CLIP-B payment. Commonly taught and known languages such as Spanish, German, and French are dominant in the force and will not earn any CLIP-B payment. CLIP-B authorized languages are broken down into four levels to define payment values. a. Level-I. (1) Languages. Portuguese (Brazilian and European) (2) CLIP-B payment value. $100 per semester credit hour or $67 per quarter hour. b. Level-II. (1) Languages. Indonesian; Javanese; Malay (Malaysian); Swahil (2) CLIP-B payment value. $150 per semester credit hour or $100 per quarter hour. c. Level-III. (1) Languages. Amharic; Azerbaijani; Baluchi; Bengali; Burmese; Cebuano; Georgian; Hausa; Hebrew (Modern only); Hindi; Igbo; Kurdish; Kurmanji; Maguindinao; Maranao; Pashto or Pashtun; Pashto-Afghan; Pashto-Peshwari; Persian-Dari; Persian-Farsi; Punjabi; Russian; Serbo-Croatian; Somali; Sorani; Tagalog; Tajik; Tausug; Thai; Turkish; Turkmen; Ukrainian; Urdu; Uzbek; Vietnamese; Yakan; Yoruba (2) CLIP-B payment value. $200 per semester credit hour or $134 per quarter hour. -

Variation in the Ergative Pattern of Kurmanji Songül Gündoğdu, Muş
Variation in the Ergative Pattern of Kurmanji Songül Gündoğdu, Muş Alparslan University, Muş, Turkey LANGUAGE KEYWORDS: Northern Kurdish (Kurmanji) AREA KEYWORDS: Middle East (Turkey) ABSTRACT (ENGLISH) Kurdish-Kurmanji (or Northern Kurdish) belongs to the Iranian branch of the Indo-European language family. This study is dedicated to a deeper understanding of a specific grammatical feature typical of Kurmanji: the ergative structure. Based on the example of this core structure, and with empirical evidence from the Kurmanji dialect of Muş in Turkey, I will discuss the issues of variation and change in Kurmanji, more precisely the ongoing shift from ergative to nominative-accusative structures. The causes for such a fundamental shift, however, are not easy to define. The close historical vicinity to Turkish and Armenian might be a trigger for the shift; another trigger is language-internal (diachronic) change. In sum, the investigated variation sheds light on a fascinating grammatical change in a language that is also sociopolitically in a situation of constant change, movement, and upheaval. ABSTRACT (DEUTSCH) Kurdisch-Kurmanci (oder Nordkurdisch) gehört zum iranischen Zweig der indoeuropäischen Sprachfamilie. Eine zentrale und charakteristische grammatische Struktur dieser Sprache ist der Ergativ; ihm ist der vorliegende Beitrag gewidmet. Am Beispiel des Ergativ werde ich Variation und Wandel im Kurmanci diskutieren und insbesondere auf den Dialekt von Muş (Türkei) eingehen. Dabei zeigt sich, dass sich derzeit im Kurmanci der Wandel von einer Ergativ- zu einer Nominativ-Akkusativ-Sprache vollzieht. Die Ursachen für einen derart grundlegenden Wandel sind nicht leicht zu benennen. Ein Grund mag in der schon historisch engen Nachbarschaft zum Türkischen und Armenischen liegen; ein anderer Grund mag im sprach-internen (diachronen) Wandel des Kurmanci selbst zu finden sein. -

Abstracts Electronic Edition
Societas Iranologica Europaea Institute of Oriental Manuscripts of the State Hermitage Museum Russian Academy of Sciences Abstracts Electronic Edition Saint-Petersburg 2015 http://ecis8.orientalstudies.ru/ Eighth European Conference of Iranian Studies. Abstracts CONTENTS 1. Abstracts alphabeticized by author(s) 3 A 3 B 12 C 20 D 26 E 28 F 30 G 33 H 40 I 45 J 48 K 50 L 64 M 68 N 84 O 87 P 89 R 95 S 103 T 115 V 120 W 125 Y 126 Z 130 2. Descriptions of special panels 134 3. Grouping according to timeframe, field, geographical region and special panels 138 Old Iranian 138 Middle Iranian 139 Classical Middle Ages 141 Pre-modern and Modern Periods 144 Contemporary Studies 146 Special panels 147 4. List of participants of the conference 150 2 Eighth European Conference of Iranian Studies. Abstracts Javad Abbasi Saint-Petersburg from the Perspective of Iranian Itineraries in 19th century Iran and Russia had critical and challenging relations in 19th century, well known by war, occupation and interfere from Russian side. Meantime 19th century was the era of Iranian’s involvement in European modernism and their curiosity for exploring new world. Consequently many Iranians, as official agents or explorers, traveled to Europe and Russia, including San Petersburg. Writing their itineraries, these travelers left behind a wealthy literature about their observations and considerations. San Petersburg, as the capital city of Russian Empire and also as a desirable station for travelers, was one of the most important destination for these itinerary writers. The focus of present paper is on the descriptions of these travelers about the features of San Petersburg in a comparative perspective. -

153 Natasha Abner (University of Michigan)
Natasha Abner (University of Michigan) LSA40 Carlo Geraci (Ecole Normale Supérieure) Justine Mertz (University of Paris 7, Denis Diderot) Jessica Lettieri (Università degli studi di Torino) Shi Yu (Ecole Normale Supérieure) A handy approach to sign language relatedness We use coded phonetic features and quantitative methods to probe potential historical relationships among 24 sign languages. Lisa Abney (Northwestern State University of Louisiana) ANS16 Naming practices in alcohol and drug recovery centers, adult daycares, and nursing homes/retirement facilities: A continuation of research The construction of drug and alcohol treatment centers, adult daycare centers, and retirement facilities has increased dramatically in the United States in the last thirty years. In this research, eleven categories of names for drug/alcohol treatment facilities have been identified while eight categories have been identified for adult daycare centers. Ten categories have become apparent for nursing homes and assisted living facilities. These naming choices function as euphemisms in many cases, and in others, names reference morphemes which are perceived to reference a higher social class than competitor names. Rafael Abramovitz (Massachusetts Institute of Technology) P8 Itai Bassi (Massachusetts Institute of Technology) Relativized Anaphor Agreement Effect The Anaphor Agreement Effect (AAE) is a generalization that anaphors do not trigger phi-agreement covarying with their binders (Rizzi 1990 et. seq.) Based on evidence from Koryak (Chukotko-Kamchan) anaphors, we argue that the AAE should be weakened and be stated as a generalization about person agreement only. We propose a theory of the weakened AAE, which combines a modification of Preminger (2019)'s AnaphP-encapsulation proposal as well as converging evidence from work on the internal syntax of pronouns (Harbour 2016, van Urk 2018). -

Revisiting Kurdish Dialect Geography: Preliminary Findings from the Manchester Database
Revisiting Kurdish dialect geography: Preliminary findings from the Manchester Database June 2017 Yaron Matras University of Manchester Introduction: Database method and Persian). Bilingual speakers were asked to translate the phrases into their local Kurdish dialect. Sessions were and scope recorded and transcribed into templates in which each phrase was pre-tagged for anticipated structures. The data My aim in this paper is to describe preliminary findings was imported into an open-source database (utilising from work carried out between 2011-2017 as part of a MySQL and PHP web interface software), which was made collaborative project on ‘Structural and typological accessible online. It allows the user to filter transcribed variation in the dialects of Kurdish’, based at the phrases by content (Kurdish forms), English elicitation University of Manchester. The project’s objectives were to phrase, tags, and speaker’s place of origin. create a reference database covering the main areas in A pilot questionnaire was tested in 2011-2012. It which dialects of Kurdish are spoken, to assess typological contained around 200 items, of which around half were variation (with particular consideration to possible individual lexemes and function words. The items had been contact influences), and to investigate the role of verb selected based on an assessment of structural variation in semantics in the volatility of the ergative construction in samples of connected speech from around 50 recorded Kurmanji/Bahdini. This paper presents initial findings interviews of up to 40 minutes each with speakers from pertaining to the distribution of structural features, dialect various locations in Turkey, Iraq, and Iran, and based on geography, and dialect classification. -

Ossetian Guard the Mountain Passages of the Roman Empire
INDO-EUROPEAN LANGUAGES AD. The Latinophones were spread into small groups of people appointed by the Romans to Ossetian guard the mountain passages of the Roman Empire. They turned into nomadic life out of necessity. Typical among those people were “the BELA HETTICH Hepeirotes”, or the inhabitants of Hepeiros, the University of North Dakota mainland in the northwest corner of Greece, the descendants of the ancient Mollossoi and Haones. Ossetian, a language of the Northeastern group of the Indo-Iranian branch of the Indo- After the fall of the Roman Empire, the European stock of languages, has not received as much linguistic attention as it deserves. A latinophones abandoned the lowland city centers th th and inhabited the mountain and forested areas, few major studies on Ossetian were written in the 19 and 20 centuries, most of them in where they resumed-again-nomadic life. The Russian. While these works are a solid foundation in the study of Ossetian, its description Hepeirotes nomads reached the maximum of their is not complete. economic development in the 17th century A.D. The present work, written in English, offers Ossetian to a wider international audience. Despite their wealth, they maintained a low preference for their personal education and the Relying on new developments in linguistic theory, it reexamines phenomena in the education of their children. They maintained that inflectional morphology of Ossetian. all the nomads needed was only some ability to The preliminary chapter on phonology provides an overview of the phonemic inventory read and write and to carry out some arithmetical of Ossetian. -

Persian and Tajik
DEMO : Purchase from www.A-PDF.com to remove the watermark CHAPTER EIGHT PERSIAN AND TAJIK Gernot Wind/uhr and Jo hn R Perry 1 INTRODUCTION 1 .1 Overview The fo cus of this chapter is Modern Standard Persian and Modern Standard Tajik. Both evolved from Early New Persian. We stern Persian has typologically shifted differently from modern Tajik which has retained a considerable number of Early Eastern Persian fe atures, on the one hand, and has also assimilated a strong typologically Turkic com ponent, on the other hand. In spite of their divergence, both languages continue to share much of their underlying fe atures, and are discussed jointly in this chapter. 1.1.1 Historical background Persian has been the dominant language of Iranian lands and adjacent regions for over a millennium. From the tenth century onward it was the language of literary culture, as well the lingua franca in large parts of West, South, and Central Asia until the mid nineteenth century. It began with the political domination of these areas by Persian speaking dynasties, first the Achaemenids (c. 558-330 BCE), then the Sassanids (224-65 1 CE), along with their complex political-cultural and ideological Perso-Iranianate con structs, and the establishment of Persian-speaking colonies throughout the empires and beyond. The advent of Islam (since 651 CE) represents a crucial shift in the history of Iran and thus of Persian. It resulted in the emergence of a double-focused Perso-Islamic construct, in which, after Arabic in the first Islamic centuries, Persian reasserted itself as the dominant high register linguistic medium, and extended its dominance into fo rmerly non-Persian and non-Iranian-speaking territories in the East and Central Asia. -

Information-Theoretic Causal Inference of Lexical Flow
Information-theoretic causal inference of lexical flow Johannes Dellert language Language Variation 4 science press Language Variation Editors: John Nerbonne, Martijn Wieling In this series: 1. Côté, Marie-Hélène, Remco Knooihuizen and John Nerbonne (eds.). The future of dialects. 2. Schäfer, Lea. Sprachliche Imitation: Jiddisch in der deutschsprachigen Literatur (18.–20. Jahrhundert). 3. Juskan, Martin. Sound change, priming, salience: Producing and perceiving variation in Liverpool English. 4. Dellert, Johannes. Information-theoretic causal inference of lexical flow. ISSN: 2366-7818 Information-theoretic causal inference of lexical flow Johannes Dellert language science press Dellert, Johannes. 2019. Information-theoretic causal inference of lexical flow (Language Variation 4). Berlin: Language Science Press. This title can be downloaded at: http://langsci-press.org/catalog/book/233 © 2019, Johannes Dellert Published under the Creative Commons Attribution 4.0 Licence (CC BY 4.0): http://creativecommons.org/licenses/by/4.0/ ISBN: 978-3-96110-143-6 (Digital) 978-3-96110-144-3 (Hardcover) ISSN: 2366-7818 DOI:10.5281/zenodo.3247415 Source code available from www.github.com/langsci/233 Collaborative reading: paperhive.org/documents/remote?type=langsci&id=233 Cover and concept of design: Ulrike Harbort Typesetting: Johannes Dellert Proofreading: Amir Ghorbanpour, Aniefon Daniel, Barend Beekhuizen, David Lukeš, Gereon Kaiping, Jeroen van de Weijer, Fonts: Linux Libertine, Libertinus Math, Arimo, DejaVu Sans Mono Typesetting software:Ǝ X LATEX Language Science Press Unter den Linden 6 10099 Berlin, Germany langsci-press.org Storage and cataloguing done by FU Berlin Contents Preface vii Acknowledgments xi 1 Introduction 1 2 Foundations: Historical linguistics 7 2.1 Language relationship and family trees ............. -

Form & Position of Nominal Modifiers in Indo-Iranian
WECOL 06, 29.OCTOBER‘06 R.K. LARSON – FORM & POSITION OF NOMINAL MODIFIERS IN INDO-IRANIAN Form & Position of Nominal Modifiers in Indo-Iranian 1.0 Ezafe: A Brief Snapshot Ezafe occurs in Mod. Persian (Farsi), Kurdish (Sorani, Kurmanji), Zazaki (Dimili) Richard Larson (Stony Brook University) and Hawrami (Gorani). The pattern shows increasing complexity in that order: Nominal modifiers in Indo-Iranian languages show an (apparently parametric) 1.1 Farsi (Samiian 1994; Ghomeshi 1997; Ghozati 2000; alternation in form & position. In Western Indo-Iranian (WI-I) (Farsi, Kurdish, Kahnemuyipour 2000; Samvelian 2005) Zazaki, Hawrami), modifiers standardly occur postnominally and “link” to N via an Ezafe particle (Ez), which is either invariant (Farsi, Sorani), or inflects for !- Farsi demonstratives and numerals are prenominal: (1a,b) features (Kurmanji, Zazaki, Hawrami). The modifiers show no agreement (1a-d). (1) a. on mard b. sé tá dokhtar (1) a. otâq - é besyar kucik that man three CL daughters room-EZ very small !very small room' (Farsi) But N modifiers/complements are always postnominal and linked to N by Ezafe. b. minál - i pcúk - i bash Farsi shows the simplest form of Ezafe; the only variation is phonological (é/yé): children-EZ small-EZ good good, small children" (Kurdish: Sorani) (2) Modifiers & complements of Ns a. otâq - é besyar kucik c. çav-ê res room-EZ very small 'very small room' (AP) eye-EZ(M) black b. del - é sang !the black eye" (Kurdish: Kurmanji) heart-EZ stone ‘stone heart‘ (NP) d. çav-ên sor c. xune - yé [kenar - é dærya] eye-EZ(P) red house-EZ next - EZ sea ‘house on the beach' (PP) !the red eyes" (indicates great anger) (Kurdish: Kurmanji) d. -

Chapter 21 Kurdish Ergin Öpengin University of Kurdistan-Hewlêr
Chapter 21 Kurdish Ergin Öpengin University of Kurdistan-Hewlêr This chapter provides an overview of the influence of Arabic on Kurdish, espe- cially on its Northern and Central varieties spoken mainly in Turkey–Syria–Iraq and Iraq–Iran, respectively. It summarizes and critically assesses the limited re- search on the contact-induced changes in the phonology and syntax of Kurdish, and proposes several new dimensions in the morphology and syntax, in addition to providing a first treatment of lexical convergence in Kurdish through borrow- ings from Arabic. 1 Kurdish and its speech community Kurdish is a Northwestern Iranian language spoken by 25 to 30 million speakers in a contiguous area of western Iran, northern Iraq, eastern Turkey and north- eastern Syria. There are also scattered enclaves of Kurdish speakers in central Anatolia, the Caucasus, northeastern Iran (Khorasan province) and Central Asia, with a large European diaspora population. The three major varieties of Kurdish are: (i) Southern Kurdish, spoken under various names near the city of Kerman- shah in Iran and across the border in Iraq; (ii) Central Kurdish (also known as Sorani), one of the official languages of the autonomous Kurdish region inIraq, also spoken by a large population in western Iran along the Iraqi border; (iii) Northern Kurdish (also known as Kurmanji), spoken by the Kurds of Turkey, Syria and the northwestern perimeter of Iraq, in the province of West Azerbaijan in northwestern Iran and in pockets in the west of Armenia (cf. Haig & Öpengin 2014 for a discussion on defining “Kurdish”). Of these three, the largest group in terms of speaker numbers is Northern Kurdish. -
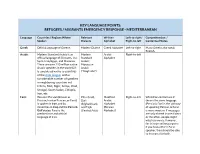
Key Language Points: Refugees / Migrants Emergency Response - Mediterranean
KEY LANGUAGE POINTS: REFUGEES / MIGRANTS EMERGENCY RESPONSE - MEDITERRANEAN Language Countries / Regions Where Relevant Written Left-to-right/ Comprehension / Spoken Dialects Alphabet Right-to-left Contextual Notes Greek Official language of Greece. Modern Dialect Greek Alphabet Left-to-right Many Greeks also speak English. Arabic Modern Standard Arabic is an Modern Arabic Right-to-left official language of 28 states, incl. Standard Alphabet Syria, Iraq, Egypt, and Morocco. Arabic; There are over 290 million native Moroccan Arabic speakers in the world & it Arabic is considered native to countries (“Maghrebi”) of the Arab League, with a considerable number of speakers in neighboring countries incl. Eritrea, Mali, Niger, Kenya, Chad, Senegal, South Sudan, Ethiopia, Iran, etc. Farsi Western Persian (known as Pārsi (Iran), Modified Right-to-left While Farsi & Dari are in Persian, Iranian Persian, or Farsi) Dari Arabic theory the same language is spoken in Iran, and by (Afghanistan), Alphabet (Persian), Dari is the ‘old way’ minorities in Iraq and the Persian and Tajik (Persian of speaking Persian, & Farsi Gulf states. Farsi is the (Central Asia) Alphabet) is more modern. If messages predominant and official are only shared in one dialect language of Iran. or the other, people might miss key words. However, for interpretation purposes – if you have a Dari / Farsi speaker, they should be able to interpret for both. Dari Eastern Persian (known as Dari Dari is a dialect Modified Right-to-left Dari is spoken by about 50% Persian, Afghan Persian, or Dari) of Farsi. Arabic of the Afghan population. is spoken in Afghanistan, where it Alphabet is one of the two official (Persian languages (along with Pashto).