Insieme Di Caratteri Universale E Alml « Riferimenti
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Technical Reference Manual for the Standardization of Geographical Names United Nations Group of Experts on Geographical Names
ST/ESA/STAT/SER.M/87 Department of Economic and Social Affairs Statistics Division Technical reference manual for the standardization of geographical names United Nations Group of Experts on Geographical Names United Nations New York, 2007 The Department of Economic and Social Affairs of the United Nations Secretariat is a vital interface between global policies in the economic, social and environmental spheres and national action. The Department works in three main interlinked areas: (i) it compiles, generates and analyses a wide range of economic, social and environmental data and information on which Member States of the United Nations draw to review common problems and to take stock of policy options; (ii) it facilitates the negotiations of Member States in many intergovernmental bodies on joint courses of action to address ongoing or emerging global challenges; and (iii) it advises interested Governments on the ways and means of translating policy frameworks developed in United Nations conferences and summits into programmes at the country level and, through technical assistance, helps build national capacities. NOTE The designations employed and the presentation of material in the present publication do not imply the expression of any opinion whatsoever on the part of the Secretariat of the United Nations concerning the legal status of any country, territory, city or area or of its authorities, or concerning the delimitation of its frontiers or boundaries. The term “country” as used in the text of this publication also refers, as appropriate, to territories or areas. Symbols of United Nations documents are composed of capital letters combined with figures. ST/ESA/STAT/SER.M/87 UNITED NATIONS PUBLICATION Sales No. -

1. Introduction
ISO/IEC JTC1/SC2/WG2 N4162 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Revised proposal to encode Latin letters used in the Former Soviet Union Authors: Nurlan Joomagueldinov, Karl Pentzlin, Ilya Yevlampiev Status: Expert Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Date: 2012-01-29 Supersedes: L2/11-360, WG2 N4162 – Two characters were added for Komi-Permyak (LATIN CAPITAL/SMALL LETTER ZE WITH DESCENDER). – The LATIN SMALL LETTER CAUCASIAN LONG S was disunified from U+017F LATIN SMALL LETTER LONG S (see the remark in the list of proposed characters at U+AB89). – Some issues raised in L2/11-422 are addressed in the text (especially, section 2.1.1 "Descender vs. cedilla" was added). Terminology used in this document: "Descender" refers to the specially formed appendage on letters like the one in the already encoded letter U+A790 LATIN CAPITAL LETTER N WITH DESCENDER. "Typographical descender" refers to the part of a letter below the baseline, thus resembling the term "descender" as used in typography. 1. Introduction In the wake of the October Revolution of 1917 in Russia, alphabetization of the people living in the then formed Soviet Union became an important point of the political agenda. At that time, some languages spoken in the Soviet Union had no standardized orthography at all, while others (especially in areas where the Islam was the predominant religion) used the Arabic script. As most of these orthographies did not reflect the phonetics of these languages very well, and as the Arabic script was considered unnecessarily difficult by some due to its structure, for most of the non-Slavic languages it was decided to design new orthographies from scratch. -

5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721
Internet Engineering Task Force (IETF) P. Faltstrom, Ed. Request for Comments: 5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721 The Unicode Code Points and Internationalized Domain Names for Applications (IDNA) Abstract This document specifies rules for deciding whether a code point, considered in isolation or in context, is a candidate for inclusion in an Internationalized Domain Name (IDN). It is part of the specification of Internationalizing Domain Names in Applications 2008 (IDNA2008). Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 5741. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at http://www.rfc-editor.org/info/rfc5892. Copyright Notice Copyright (c) 2010 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License. -

Centc304 N932
CEN/TC304 N932 Source: Secretariat Date: 15 Dec 1999 Title: European Fallback Rules, ballot Mailed: 15 Dec 1999 Status: TC-enquiry: DEADLINE 1st March 2000 Action required: Respond before 1 March 2000 * Notes: This is a TC-enquiry, to establish the suitability of N932 to be sent for Formal vote as prENV. National member body officers, responsible for CEN/TC304 issues are asked to fill in this form and send it to the TC-secretariat before 1 March 2000. Comments in any form will be forwarded to the CEN/TC 304 Project Team of European Fallback Rules. The PT will before the next plenary of TC304 in April 2000 produce a disposition of comments and a revised draft. The PT will produce a disposition of comments and plans to ask the TC304 plenary in November to approve a revised draft to be sent for Formal Vote. Comments from affiliated members of CEN and liaisons are welcome and will be considered. Country:______________________________ Approves without comments ___ Approves with comments ___ Disapproves with comments ___ Date:_______________ Signature_____________________________________(National Member Body officer) Name:__________________________________ EUROPEAN PRESTANDARD DRAFT PRÉNORME EUROPÉENNE prENV_____ EUROPÄISCHE VORNORM ICS: 35.040 Descriptors: Data processing, information interchange, text processing, text communication, graphic characters, character sets, representation of characters, coded character sets, conversion, fallback English version Information Technology European fallback rules Technologies de l'information- Informations technologies Character repertoire and coding transformations: Character repertoire and coding transformations: European fallback rules - Nº 1 European fallback rules - Nº 1 This draft ENV is submitted to CEN members for Formal Vote. It has been drawn up by the Technical Committee CEN/TC 304. -

Kyrillische Schrift Für Den Computer
Hanna-Chris Gast Kyrillische Schrift für den Computer Benennung der Buchstaben, Vergleich der Transkriptionen in Bibliotheken und Standesämtern, Auflistung der Unicodes sowie Tastaturbelegung für Windows XP Inhalt Seite Vorwort ................................................................................................................................................ 2 1 Kyrillische Schriftzeichen mit Benennung................................................................................... 3 1.1 Die Buchstaben im Russischen mit Schreibschrift und Aussprache.................................. 3 1.2 Kyrillische Schriftzeichen anderer slawischer Sprachen.................................................... 9 1.3 Veraltete kyrillische Schriftzeichen .................................................................................... 10 1.4 Die gebräuchlichen Sonderzeichen ..................................................................................... 11 2 Transliterationen und Transkriptionen (Umschriften) .......................................................... 13 2.1 Begriffe zum Thema Transkription/Transliteration/Umschrift ...................................... 13 2.2 Normen und Vorschriften für Bibliotheken und Standesämter....................................... 15 2.3 Tabellarische Übersicht der Umschriften aus dem Russischen ....................................... 21 2.4 Transliterationen veralteter kyrillischer Buchstaben ....................................................... 25 2.5 Transliterationen bei anderen slawischen -

Alphabets, Letters and Diacritics in European Languages (As They Appear in Geography)
1 Vigleik Leira (Norway): [email protected] Alphabets, Letters and Diacritics in European Languages (as they appear in Geography) To the best of my knowledge English seems to be the only language which makes use of a "clean" Latin alphabet, i.d. there is no use of diacritics or special letters of any kind. All the other languages based on Latin letters employ, to a larger or lesser degree, some diacritics and/or some special letters. The survey below is purely literal. It has nothing to say on the pronunciation of the different letters. Information on the phonetic/phonemic values of the graphic entities must be sought elsewhere, in language specific descriptions. The 26 letters a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z may be considered the standard European alphabet. In this article the word diacritic is used with this meaning: any sign placed above, through or below a standard letter (among the 26 given above); disregarding the cases where the resulting letter (e.g. å in Norwegian) is considered an ordinary letter in the alphabet of the language where it is used. Albanian The alphabet (36 letters): a, b, c, ç, d, dh, e, ë, f, g, gj, h, i, j, k, l, ll, m, n, nj, o, p, q, r, rr, s, sh, t, th, u, v, x, xh, y, z, zh. Missing standard letter: w. Letters with diacritics: ç, ë. Sequences treated as one letter: dh, gj, ll, rr, sh, th, xh, zh. -

Unicode Alphabets for L ATEX
Unicode Alphabets for LATEX Specimen Mikkel Eide Eriksen March 11, 2020 2 Contents MUFI 5 SIL 21 TITUS 29 UNZ 117 3 4 CONTENTS MUFI Using the font PalemonasMUFI(0) from http://mufi.info/. Code MUFI Point Glyph Entity Name Unicode Name E262 � OEligogon LATIN CAPITAL LIGATURE OE WITH OGONEK E268 � Pdblac LATIN CAPITAL LETTER P WITH DOUBLE ACUTE E34E � Vvertline LATIN CAPITAL LETTER V WITH VERTICAL LINE ABOVE E662 � oeligogon LATIN SMALL LIGATURE OE WITH OGONEK E668 � pdblac LATIN SMALL LETTER P WITH DOUBLE ACUTE E74F � vvertline LATIN SMALL LETTER V WITH VERTICAL LINE ABOVE E8A1 � idblstrok LATIN SMALL LETTER I WITH TWO STROKES E8A2 � jdblstrok LATIN SMALL LETTER J WITH TWO STROKES E8A3 � autem LATIN ABBREVIATION SIGN AUTEM E8BB � vslashura LATIN SMALL LETTER V WITH SHORT SLASH ABOVE RIGHT E8BC � vslashuradbl LATIN SMALL LETTER V WITH TWO SHORT SLASHES ABOVE RIGHT E8C1 � thornrarmlig LATIN SMALL LETTER THORN LIGATED WITH ARM OF LATIN SMALL LETTER R E8C2 � Hrarmlig LATIN CAPITAL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C3 � hrarmlig LATIN SMALL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C5 � krarmlig LATIN SMALL LETTER K LIGATED WITH ARM OF LATIN SMALL LETTER R E8C6 UU UUlig LATIN CAPITAL LIGATURE UU E8C7 uu uulig LATIN SMALL LIGATURE UU E8C8 UE UElig LATIN CAPITAL LIGATURE UE E8C9 ue uelig LATIN SMALL LIGATURE UE E8CE � xslashlradbl LATIN SMALL LETTER X WITH TWO SHORT SLASHES BELOW RIGHT E8D1 æ̊ aeligring LATIN SMALL LETTER AE WITH RING ABOVE E8D3 ǽ̨ aeligogonacute LATIN SMALL LETTER AE WITH OGONEK AND ACUTE 5 6 CONTENTS -

Characters for Classical Latin
Characters for Classical Latin David J. Perry version 13, 2 July 2020 Introduction The purpose of this document is to identify all characters of interest to those who work with Classical Latin, no matter how rare. Epigraphers will want many of these, but I want to collect any character that is needed in any context. Those that are already available in Unicode will be so identified; those that may be available can be debated; and those that are clearly absent and should be proposed can be proposed; and those that are so rare as to be unencodable will be known. If you have any suggestions for additional characters or reactions to the suggestions made here, please email me at [email protected] . No matter how rare, let’s get all possible characters on this list. Version 6 of this document has been updated to reflect the many characters of interest to Latinists encoded as of Unicode version 13.0. Characters are indicated by their Unicode value, a hexadecimal number, and their name printed IN SMALL CAPITALS. Unicode values may be preceded by U+ to set them off from surrounding text. Combining diacritics are printed over a dotted cir- cle ◌ to show that they are intended to be used over a base character. For more basic information about Unicode, see the website of The Unicode Consortium, http://www.unicode.org/ or my book cited below. Please note that abbreviations constructed with lines above or through existing let- ters are not considered separate characters except in unusual circumstances, nor are the space-saving ligatures found in Latin inscriptions unless they have a unique grammatical or phonemic function (which they normally don’t). -

CEN WORKSHOP Agreementfinal Draft for CWA/MES:1998
CEN WORKSHOP AGREEMENTFinal draft for CWA/MES:1998 1998-11-18 English version Information technology – Multilingual European Subsets in ISO/IEC 10646-1 Technologies de l’information – Informationstechnologie – Jeux partiels européens multilingues Mehrsprachige europäische Untermengen dans l’ISO/CEI 10646-1 in ISO/IEC 10646-1 This CEN Workshop Agreement has been drafted and approved by a Workshop of representatives of interested parties, whose names and affiliations can be obtained from the CEN/ISSS Secretariat. The formal process followed by the Workshop in the development of this Workshop Agreement has been endorsed by the National Members of CEN, but neither the National Members of CEN nor the CEN Central Secretariat can be held accountable for the technical content of this CEN Workshop Agreement or for possible conflicts with standards or legislation. This CEN Workshop Agreement can in no way be held as being an official standard developed by CEN and its Members. This CEN Workshop Agreement is publicly available, as a reference document, from the CEN Members National Standard Bodies. CEN Members are the National Standards Bodies of Austria, Belgium, the Czech Republic, Denmark, Finland, France, Germany, Greece, Iceland, Ireland, Italy, Luxembourg, the Netherlands, Norway, Portugal, Spain, Sweden, Switzerland and the United Kingdom. CEN EUROPEAN COMMITTEE FOR STANDARDIZATION COMITÉ EUROPÉEN DE NORMALISATION EUROPÄISCHES KOMITEE FÜR NORMUNG Central Secretariat: rue de Stassart 36, B-1050 Brussels © CEN 1998 All rights of exploitation in any form and by any means reserved worldwide for CEN national Members Ref.No. CWA/MES:1998 E Information technology – Page 2 Multilingual European Subsets in ISO/IEC 10646-1 Final Draft for CWA/MES:1998 Contents Foreword 3 Introduction 4 1. -
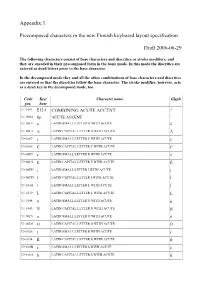
Appendix 3. Precomposed Characters in the New Finnish Keyboard Layout
Appendix 3. Precomposed characters in the new Finnish keyboard layout specification Draft 2006-06-29 The following characters consist of base characters and diacritics or stroke modifiers, and they are encoded in their precomposed form in the basic mode. In this mode the diacritics are entered as dead letters prior to the base character. In the decomposed mode they and all the other combinations of base characters and diacritics are entered so that the diacritics follow the base character. The stroke modifier, however, acts as a dead key in the decomposed mode, too. Code Key/ Character name Glyph pos. base U+0301 E12-1 COMBINING ACUTE ACCENT U+00B4 Sp. ACUTE ACCENT ´ U+00E1 a LATIN SMALL LETTER A WITH ACUTE á U+00C1 A LATIN CAPITAL LETTER A WITH ACUTE Á U+0107 c LATIN SMALL LETTER C WITH ACUTE U+0106 C LATIN CAPITAL LETTER C WITH ACUTE U+00E9 e LATIN SMALL LETTER E WITH ACUTE é U+00C9 E LATIN CAPITAL LETTER E WITH ACUTE É U+00ED i LATIN SMALL LETTER I WITH ACUTE í U+00CD I LATIN CAPITAL LETTER I WITH ACUTE Í U+013A l LATIN SMALL LETTER L WITH ACUTE U+0139 L LATIN CAPITAL LETTER L WITH ACUTE U+0144 n LATIN SMALL LETTER N WITH ACUTE U+0143 N LATIN CAPITAL LETTER N WITH ACUTE U+00F3 o LATIN SMALL LETTER O WITH ACUTE ó U+00D3 O LATIN CAPITAL LETTER O WITH ACUTE Ó U+0155 r LATIN SMALL LETTER R WITH ACUTE U+0154 R LATIN CAPITAL LETTER R WITH ACUTE U+015B s LATIN SMALL LETTER S WITH ACUTE U+015A S LATIN CAPITAL LETTER S WITH ACUTE U+00FA u LATIN SMALL LETTER U WITH ACUTE ú U+00DA U LATIN CAPITAL LETTER U WITH ACUTE Ú U+1E83 w LATIN SMALL LETTER W WITH ACUTE 3 U+1E82 W LATIN CAPITAL LETTER W WITH ACUTE 2 U+00FD y LATIN SMALL LETTER Y WITH ACUTE U+00DD Y LATIN CAPITAL LETTER Y WITH ACUTE U+017A z LATIN SMALL LETTER Z WITH ACUTE # U+0179 Z LATIN CAPITAL LETTER Z WITH ACUTE " U+01FD æ LATIN SMALL LETTER AE WITH ACUTE / U+01FC Æ LATIN CAPITAL LETTER AE WITH ACUTE . -

1 Symbols (2286)
1 Symbols (2286) USV Symbol Macro(s) Description 0009 \textHT <control> 000A \textLF <control> 000D \textCR <control> 0022 ” \textquotedbl QUOTATION MARK 0023 # \texthash NUMBER SIGN \textnumbersign 0024 $ \textdollar DOLLAR SIGN 0025 % \textpercent PERCENT SIGN 0026 & \textampersand AMPERSAND 0027 ’ \textquotesingle APOSTROPHE 0028 ( \textparenleft LEFT PARENTHESIS 0029 ) \textparenright RIGHT PARENTHESIS 002A * \textasteriskcentered ASTERISK 002B + \textMVPlus PLUS SIGN 002C , \textMVComma COMMA 002D - \textMVMinus HYPHEN-MINUS 002E . \textMVPeriod FULL STOP 002F / \textMVDivision SOLIDUS 0030 0 \textMVZero DIGIT ZERO 0031 1 \textMVOne DIGIT ONE 0032 2 \textMVTwo DIGIT TWO 0033 3 \textMVThree DIGIT THREE 0034 4 \textMVFour DIGIT FOUR 0035 5 \textMVFive DIGIT FIVE 0036 6 \textMVSix DIGIT SIX 0037 7 \textMVSeven DIGIT SEVEN 0038 8 \textMVEight DIGIT EIGHT 0039 9 \textMVNine DIGIT NINE 003C < \textless LESS-THAN SIGN 003D = \textequals EQUALS SIGN 003E > \textgreater GREATER-THAN SIGN 0040 @ \textMVAt COMMERCIAL AT 005C \ \textbackslash REVERSE SOLIDUS 005E ^ \textasciicircum CIRCUMFLEX ACCENT 005F _ \textunderscore LOW LINE 0060 ‘ \textasciigrave GRAVE ACCENT 0067 g \textg LATIN SMALL LETTER G 007B { \textbraceleft LEFT CURLY BRACKET 007C | \textbar VERTICAL LINE 007D } \textbraceright RIGHT CURLY BRACKET 007E ~ \textasciitilde TILDE 00A0 \nobreakspace NO-BREAK SPACE 00A1 ¡ \textexclamdown INVERTED EXCLAMATION MARK 00A2 ¢ \textcent CENT SIGN 00A3 £ \textsterling POUND SIGN 00A4 ¤ \textcurrency CURRENCY SIGN 00A5 ¥ \textyen YEN SIGN 00A6 -

Psftx-Centos-8.2/Pancyrillic.F16.Psfu Linux Console Font Codechart
psftx-centos-8.2/pancyrillic.f16.psfu Linux console font codechart Glyphs 0x000 to 0x0FF 0 1 2 3 4 5 6 7 8 9 A B C D E F 0x00_ 0x01_ 0x02_ 0x03_ 0x04_ 0x05_ 0x06_ 0x07_ 0x08_ 0x09_ 0x0A_ 0x0B_ 0x0C_ 0x0D_ 0x0E_ 0x0F_ Page 1 Glyphs 0x100 to 0x1FF 0 1 2 3 4 5 6 7 8 9 A B C D E F 0x10_ 0x11_ 0x12_ 0x13_ 0x14_ 0x15_ 0x16_ 0x17_ 0x18_ 0x19_ 0x1A_ 0x1B_ 0x1C_ 0x1D_ 0x1E_ 0x1F_ Page 2 Font information 0x018 U+2191 UPWARDS ARROW Filename: psftx-centos-8.2/pancyrillic.f16.psfu 0x019 U+2193 DOWNWARDS ARROW PSF version: 1 0x01A U+2192 RIGHTWARDS ARROW Glyph size: 8 × 16 pixels Glyph count: 512 0x01B U+2190 LEFTWARDS ARROW Unicode font: Yes (mapping table present) 0x01C U+2039 SINGLE LEFT-POINTING ANGLE QUOTATION MARK Unicode mappings 0x01D U+2040 CHARACTER TIE 0x000 U+FFFD REPLACEMENT CHARACTER 0x01E U+25B2 BLACK UP-POINTING 0x001 U+2022 BULLET TRIANGLE 0x01F U+25BC BLACK DOWN-POINTING 0x002 U+25C6 BLACK DIAMOND, TRIANGLE U+2666 BLACK DIAMOND SUIT 0x020 U+0020 SPACE 0x003 U+2320 TOP HALF INTEGRAL 0x021 U+0021 EXCLAMATION MARK 0x004 U+2321 BOTTOM HALF INTEGRAL 0x022 U+0022 QUOTATION MARK 0x005 U+2013 EN DASH 0x023 U+0023 NUMBER SIGN 0x006 U+2014 EM DASH 0x024 U+0024 DOLLAR SIGN 0x007 U+2026 HORIZONTAL ELLIPSIS 0x025 U+0025 PERCENT SIGN 0x008 U+201A SINGLE LOW-9 QUOTATION MARK 0x026 U+0026 AMPERSAND 0x009 U+201E DOUBLE LOW-9 0x027 U+0027 APOSTROPHE QUOTATION MARK 0x00A U+2018 LEFT SINGLE QUOTATION 0x028 U+0028 LEFT PARENTHESIS MARK 0x029 U+0029 RIGHT PARENTHESIS 0x00B U+2019 RIGHT SINGLE QUOTATION MARK 0x02A U+002A ASTERISK 0x00C U+201C LEFT DOUBLE