New Added Languages Within EU -2015 and the Rroma' Language
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Indian Origin of Romani People As a Founding Myth in Eastern European Museums Douglas Neander Sambati1
The Indian Origin of Romani people as a Founding Myth 39 Douglas Sambati https://doi.org/10.36572/csm.2019.vol.58.03 The Indian Origin of Romani people as a Founding Myth in Eastern European Museums Douglas Neander Sambati1 Introduction This article analyses three museums – the Muzeum Romské Kultury (MRK) in Brno/Czech Republic, the Muzej Romské Kulture (MRKu) in Belgrade/Serbia, and the Roma Ethnographic Museum (REM) in Tárnow/Poland – and part of its exhibitions which can be considered as elements of the Romani Nationalism. The main objective is to demonstrate how these museum institutions support a broad narrative about a common Indian origin of Gypsy/Romani populations. It will be discussed below how the aforementioned museums – by means of their exhibitions, websites, events or any other kind of official production – support sets of representations which allow a formation of an umbrella rhetoric about the group known, taken and self-ascribed as Gypsies and/or Roma. This discourse, then, is able to shelter all different groups within this population in a holistic manner, based on a narrative formed by essentializations, exoticizations and generalizations. Therefore, the argument will be developed from now onwards by establishing a dialogue of elements which essentialize – in the sense that they imply natural and intrinsic characteristics – some aspects of Roma history and 1 Grupo de Pesquisa Estudos Interdisciplinares de Patrimônio Cultural da UNIVILLE. [email protected] 40 Cadernos de Sociomuseologia, 2019.vol.58.nº14 culture. In plain words, it is possible to find within these museums some specific deliberation which sustains none (or little) doubt that some characteristics are part of a claimed Romani way of life. -

(And Potential) Language and Linguistic Resources on South Asian Languages
CoRSAL Symposium, University of North Texas, November 17, 2017 Existing (and Potential) Language and Linguistic Resources on South Asian Languages Elena Bashir, The University of Chicago Resources or published lists outside of South Asia Digital Dictionaries of South Asia in Digital South Asia Library (dsal), at the University of Chicago. http://dsal.uchicago.edu/dictionaries/ . Some, mostly older, not under copyright dictionaries. No corpora. Digital Media Archive at University of Chicago https://dma.uchicago.edu/about/about-digital-media-archive Hock & Bashir (eds.) 2016 appendix. Lists 9 electronic corpora, 6 of which are on Sanskrit. The 3 non-Sanskrit entries are: (1) the EMILLE corpus, (2) the Nepali national corpus, and (3) the LDC-IL — Linguistic Data Consortium for Indian Languages Focus on Pakistan Urdu Most work has been done on Urdu, prioritized at government institutions like the Center for Language Engineering at the University of Engineering and Technology in Lahore (CLE). Text corpora: http://cle.org.pk/clestore/index.htm (largest is a 1 million word Urdu corpus from the Urdu Digest. Work on Essential Urdu Linguistic Resources: http://www.cle.org.pk/eulr/ Tagset for Urdu corpus: http://cle.org.pk/Publication/papers/2014/The%20CLE%20Urdu%20POS%20Tagset.pdf Urdu OCR: http://cle.org.pk/clestore/urduocr.htm Sindhi Sindhi is the medium of education in some schools in Sindh Has more institutional backing and consequent research than other languages, especially Panjabi. Sindhi-English dictionary developed jointly by Jennifer Cole at the University of Illinois Urbana- Champaign and Sarmad Hussain at CLE (http://182.180.102.251:8081/sed1/homepage.aspx). -

Some Principles of the Use of Macro-Areas Language Dynamics &A
Online Appendix for Harald Hammarstr¨om& Mark Donohue (2014) Some Principles of the Use of Macro-Areas Language Dynamics & Change Harald Hammarstr¨om& Mark Donohue The following document lists the languages of the world and their as- signment to the macro-areas described in the main body of the paper as well as the WALS macro-area for languages featured in the WALS 2005 edi- tion. 7160 languages are included, which represent all languages for which we had coordinates available1. Every language is given with its ISO-639-3 code (if it has one) for proper identification. The mapping between WALS languages and ISO-codes was done by using the mapping downloadable from the 2011 online WALS edition2 (because a number of errors in the mapping were corrected for the 2011 edition). 38 WALS languages are not given an ISO-code in the 2011 mapping, 36 of these have been assigned their appropri- ate iso-code based on the sources the WALS lists for the respective language. This was not possible for Tasmanian (WALS-code: tsm) because the WALS mixes data from very different Tasmanian languages and for Kualan (WALS- code: kua) because no source is given. 17 WALS-languages were assigned ISO-codes which have subsequently been retired { these have been assigned their appropriate updated ISO-code. In many cases, a WALS-language is mapped to several ISO-codes. As this has no bearing for the assignment to macro-areas, multiple mappings have been retained. 1There are another couple of hundred languages which are attested but for which our database currently lacks coordinates. -

Pashto, Waneci, Ormuri. Sociolinguistic Survey of Northern
SOCIOLINGUISTIC SURVEY OF NORTHERN PAKISTAN VOLUME 4 PASHTO, WANECI, ORMURI Sociolinguistic Survey of Northern Pakistan Volume 1 Languages of Kohistan Volume 2 Languages of Northern Areas Volume 3 Hindko and Gujari Volume 4 Pashto, Waneci, Ormuri Volume 5 Languages of Chitral Series Editor Clare F. O’Leary, Ph.D. Sociolinguistic Survey of Northern Pakistan Volume 4 Pashto Waneci Ormuri Daniel G. Hallberg National Institute of Summer Institute Pakistani Studies of Quaid-i-Azam University Linguistics Copyright © 1992 NIPS and SIL Published by National Institute of Pakistan Studies, Quaid-i-Azam University, Islamabad, Pakistan and Summer Institute of Linguistics, West Eurasia Office Horsleys Green, High Wycombe, BUCKS HP14 3XL United Kingdom First published 1992 Reprinted 2004 ISBN 969-8023-14-3 Price, this volume: Rs.300/- Price, 5-volume set: Rs.1500/- To obtain copies of these volumes within Pakistan, contact: National Institute of Pakistan Studies Quaid-i-Azam University, Islamabad, Pakistan Phone: 92-51-2230791 Fax: 92-51-2230960 To obtain copies of these volumes outside of Pakistan, contact: International Academic Bookstore 7500 West Camp Wisdom Road Dallas, TX 75236, USA Phone: 1-972-708-7404 Fax: 1-972-708-7433 Internet: http://www.sil.org Email: [email protected] REFORMATTING FOR REPRINT BY R. CANDLIN. CONTENTS Preface.............................................................................................................vii Maps................................................................................................................ -

MR. SHOAIB ISMAIL MANGRORIA “Premier” of Pakistan the MEMON | ISSUE 04.1 INTRODUCTION
ISSUE 04.1 | JULY 2015 THETHE MEMONMEMONWORLD MEMON ORGANISATION NEWSLETTER WMO RAMADAN EDITION Serving Mankind RAMADAN KAREEM Middle East Chapter - iftar camp 13TH AGM - COLOMBO Welcome to WMO MR. SHOAIB ISMAIL MANGRORIA “Premier” Of Pakistan THE MEMON | ISSUE 04.1 INTRODUCTION THETHE MEMONMEMON INTRODUCTION World Memon Organisation - Serving Mankind I stood undaunted during the Gujarat I am getting together a group of young- riots and rehabilitated my aicted sters in the Big Apple to do community brothers and sisters. I walked in neck work. I organise events to promote deep waters to build homes for flood brotherhood and sports every month in victims in Sindh. I drove to shelters in Dubai. I ran the Mumbai marathon to Durban with medical supplies to treat fund a worthy cause. the injured in the Xenophobic attacks. I am the youth wing of WMO. I am a member of WMO. We are the future of Mankind. We uplift mankind I was knighted by the Queen of I build homes. I educate children. I England for my extensive charitable provide a brighter future and make this work. I was awarded the “Presidential world a better place. Order of Meritorious Service” by the President of the Republic of Botswana I donate to WMO. for my exceptional generosity and We uphold Mankind. philanthropy. I was honoured by the Premier of Pakistan for my dedication I sent blankets to shivering children in and passion towards community work. the winter of war torn Syria. I collected funds for relief packages to be delivered I am WMO. in flood ravaged Malawi. -

Languages of Kohistan. Sociolinguistic Survey of Northern
SOCIOLINGUISTIC SURVEY OF NORTHERN PAKISTAN VOLUME 1 LANGUAGES OF KOHISTAN Sociolinguistic Survey of Northern Pakistan Volume 1 Languages of Kohistan Volume 2 Languages of Northern Areas Volume 3 Hindko and Gujari Volume 4 Pashto, Waneci, Ormuri Volume 5 Languages of Chitral Series Editor Clare F. O’Leary, Ph.D. Sociolinguistic Survey of Northern Pakistan Volume 1 Languages of Kohistan Calvin R. Rensch Sandra J. Decker Daniel G. Hallberg National Institute of Summer Institute Pakistani Studies of Quaid-i-Azam University Linguistics Copyright © 1992 NIPS and SIL Published by National Institute of Pakistan Studies, Quaid-i-Azam University, Islamabad, Pakistan and Summer Institute of Linguistics, West Eurasia Office Horsleys Green, High Wycombe, BUCKS HP14 3XL United Kingdom First published 1992 Reprinted 2002 ISBN 969-8023-11-9 Price, this volume: Rs.300/- Price, 5-volume set: Rs.1500/- To obtain copies of these volumes within Pakistan, contact: National Institute of Pakistan Studies Quaid-i-Azam University, Islamabad, Pakistan Phone: 92-51-2230791 Fax: 92-51-2230960 To obtain copies of these volumes outside of Pakistan, contact: International Academic Bookstore 7500 West Camp Wisdom Road Dallas, TX 75236, USA Phone: 1-972-708-7404 Fax: 1-972-708-7433 Internet: http://www.sil.org Email: [email protected] REFORMATTING FOR REPRINT BY R. CANDLIN. CONTENTS Preface............................................................................................................viii Maps................................................................................................................. -

Language Documentation and Description
Language Documentation and Description ISSN 1740-6234 ___________________________________________ This article appears in: Language Documentation and Description, vol 17. Editor: Peter K. Austin Countering the challenges of globalization faced by endangered languages of North Pakistan ZUBAIR TORWALI Cite this article: Torwali, Zubair. 2020. Countering the challenges of globalization faced by endangered languages of North Pakistan. In Peter K. Austin (ed.) Language Documentation and Description 17, 44- 65. London: EL Publishing. Link to this article: http://www.elpublishing.org/PID/181 This electronic version first published: July 2020 __________________________________________________ This article is published under a Creative Commons License CC-BY-NC (Attribution-NonCommercial). The licence permits users to use, reproduce, disseminate or display the article provided that the author is attributed as the original creator and that the reuse is restricted to non-commercial purposes i.e. research or educational use. See http://creativecommons.org/licenses/by-nc/4.0/ ______________________________________________________ EL Publishing For more EL Publishing articles and services: Website: http://www.elpublishing.org Submissions: http://www.elpublishing.org/submissions Countering the challenges of globalization faced by endangered languages of North Pakistan Zubair Torwali Independent Researcher Summary Indigenous communities living in the mountainous terrain and valleys of the region of Gilgit-Baltistan and upper Khyber Pakhtunkhwa, northern -
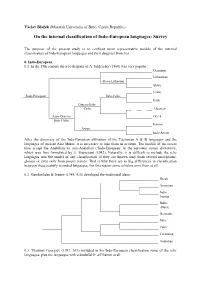
Internal Classification of Indo-European Languages: Survey
Václav Blažek (Masaryk University of Brno, Czech Republic) On the internal classification of Indo-European languages: Survey The purpose of the present study is to confront most representative models of the internal classification of Indo-European languages and their daughter branches. 0. Indo-European 0.1. In the 19th century the tree-diagram of A. Schleicher (1860) was very popular: Germanic Lithuanian Slavo-Lithuaian Slavic Celtic Indo-European Italo-Celtic Italic Graeco-Italo- -Celtic Albanian Aryo-Graeco- Greek Italo-Celtic Iranian Aryan Indo-Aryan After the discovery of the Indo-European affiliation of the Tocharian A & B languages and the languages of ancient Asia Minor, it is necessary to take them in account. The models of the recent time accept the Anatolian vs. non-Anatolian (‘Indo-European’ in the narrower sense) dichotomy, which was first formulated by E. Sturtevant (1942). Naturally, it is difficult to include the relic languages into the model of any classification, if they are known only from several inscriptions, glosses or even only from proper names. That is why there are so big differences in classification between these scantily recorded languages. For this reason some scholars omit them at all. 0.2. Gamkrelidze & Ivanov (1984, 415) developed the traditional ideas: Greek Armenian Indo- Iranian Balto- -Slavic Germanic Italic Celtic Tocharian Anatolian 0.3. Vladimir Georgiev (1981, 363) included in his Indo-European classification some of the relic languages, plus the languages with a doubtful IE affiliation at all: Tocharian Northern Balto-Slavic Germanic Celtic Ligurian Italic & Venetic Western Illyrian Messapic Siculian Greek & Macedonian Indo-European Central Phrygian Armenian Daco-Mysian & Albanian Eastern Indo-Iranian Thracian Southern = Aegean Pelasgian Palaic Southeast = Hittite; Lydian; Etruscan-Rhaetic; Elymian = Anatolian Luwian; Lycian; Carian; Eteocretan 0.4. -

Correlation of the Burushaski Pronominal System with Indo-European and Phonological and Grammatical Evidence for a Genetic Relationship
Correlation of the Burushaski Pronominal System with Indo-European and Phonological and Grammatical Evidence for a Genetic Relationship Ilija Çasule Macquarie University The Burushaski personal and demonstrative pronominal system is correlated in its entirety with Indo-European. This close correlation, together with the extensive grammatical correspondences in the nominal and verbal systems (given as an addendum), advances significantly the hypothesis of the genetic affiliation of Burushaski with Indo-European. The article includes a comprehensive discussion of the Burushaski-Indo-European phonological and lexical correspondences. It proposes that Burushaski is an Indo- European language which at some stage of its development was in contact with an agglutinative system. 1. Introduction 1.1. Brief overview of sources and previous studies Being a language with undetermined genetic affiliation, Burushaski has attracted considerable interest, especially in the last twenty years, but also earlier. There have been many attempts to relate it to languages as diverse as Basque, Nubian, Dravidian, various Caucasic as well as Yeniseian languages, Sino-Tibetan and Sumerian (for a brief overview, see Bashir 2000:1-3). These endeavors have failed mostly because of unsystematic or inconsistent correspondences, incorrect internal reconstruction, excessive semantic latitude and incoherent semantic fields, root etymologizing and especially lack of grammatical and derivational evidence. Burushaski is spoken by around 90,000 people (Berger 1990:567) in the Karakoram area in North-West Pakistan at the junction of three linguistic families — the Indo- European (Indo-Aryan and Iranian), the Sino-Tibetan and the Turkic. Its dialectal differentiation is minor. There are Volume 40, Number 1 & 2, Spring/Summer 2012 60 Ilija Çasule three very closely related dialects: Hunza and Nager with minimal differences, and the Yasin dialect, which exhibits differential traits, but is still mutually intelligible with the former two. -

Proposal for a Gujarati Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Gujarati Root Zone LGR Neo-Brahmi Generation Panel Proposal for a Gujarati Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-03-06 Document version: 3.6 Authors: Neo-Brahmi Generation Panel [NBGP] 1 General Information/ Overview/ Abstract The purpose of this document is to give an overview of the proposed Gujarati LGR in the XML format and the rationale behind the design decisions taken. It includes a discussion of relevant features of the script, the communities or languages using it, the process and methodology used and information on the contributors. The formal specification of the LGR can be found in the accompanying XML document: proposal-gujarati-lgr-06mar19-en.xml Labels for testing can be found in the accompanying text document: gujarati-test-labels-06mar19-en.txt 2 Script for which the LGR is proposed ISO 15924 Code: Gujr ISO 15924 Key N°: 320 ISO 15924 English Name: Gujarati Latin transliteration of native script name: gujarâtî Native name of the script: ગજુ રાતી Maximal Starting Repertoire (MSR) version: MSR-4 1 Proposal for a Gujarati Root Zone LGR Neo-Brahmi Generation Panel 3 Background on the Script and the Principal Languages Using it1 Gujarati (ગજુ રાતી) [also sometimes written as Gujerati, Gujarathi, Guzratee, Guujaratee, Gujrathi, and Gujerathi2] is an Indo-Aryan language native to the Indian state of Gujarat. It is part of the greater Indo-European language family. It is so named because Gujarati is the language of the Gujjars. Gujarati's origins can be traced back to Old Gujarati (circa 1100– 1500 AD). -

Offprint From: Journal of the Gypsy Lore Society, Fifth Series, 9: 89-116
Offprint from: Journal of the Gypsy Lore Society, fifth series, 9: 89-116. 1999. JOHANN RÜDIGER AND THE STUDY OF ROMANI IN 18TH CENTURY GERMANY Yaron Matras University of Manchester Abstract Rüdiger’s contribution is acknowledged as an original piece of empirical research As the first consice grammatical description of a Romani dialect as well as the first serious attempt at a comparative investigation of the language, it provided the foundation for Romani linguistics. At the same time his work is described as largely intuitive and at times analytically naive. A comparison of the linguistic material is drawn with other contemporary sources, highlighting the obscure origin of the term ‘Sinte’ now used as a self-appellation by Romani-speaking populations of Germany and adjoining regions. 1. Introduction Several different scholars have been associated with laying the foundations for Romani linguistics. Among them are August Pott, whose comparative grammar and dictionary (1844/1845) constituted the first comprehensive contribution to the language, Franz Miklosich, whose twelve-part survey of Romani dialects (1872-1889) was the first contrastive empirical investigation, and John Sampson, whose monograph on Welsh Romani (1926) is still looked upon today as the most focused and systematic attempt at an historical discussion of the language. Heinrich Grellmann is usually given credit for disseminating the theory of the Indian origin of the Romani language, if not for discovering this origin himself. It is Grellmann who is cited at most length and most frequently on this matter. Rüdiger’s contribution from 1782 entitled Von der Sprache und Herkunft der Zigeuner aus Indien (‘On the language and Indian origin of the Gypsies’), which preceded Grellmann’s book, is usually mentioned only in passing, perhaps since it has only recently become more widely available in a reprint (Buske Publishers, Hamburg, 1990) and only in the German original, printed in old German characters. -

Map by Steve Huffman; Data from World Language Mapping System
Svalbard Greenland Jan Mayen Norwegian Norwegian Icelandic Iceland Finland Norway Swedish Sweden Swedish Faroese FaroeseFaroese Faroese Faroese Norwegian Russia Swedish Swedish Swedish Estonia Scottish Gaelic Russian Scottish Gaelic Scottish Gaelic Latvia Latvian Scots Denmark Scottish Gaelic Danish Scottish Gaelic Scottish Gaelic Danish Danish Lithuania Lithuanian Standard German Swedish Irish Gaelic Northern Frisian English Danish Isle of Man Northern FrisianNorthern Frisian Irish Gaelic English United Kingdom Kashubian Irish Gaelic English Belarusan Irish Gaelic Belarus Welsh English Western FrisianGronings Ireland DrentsEastern Frisian Dutch Sallands Irish Gaelic VeluwsTwents Poland Polish Irish Gaelic Welsh Achterhoeks Irish Gaelic Zeeuws Dutch Upper Sorbian Russian Zeeuws Netherlands Vlaams Upper Sorbian Vlaams Dutch Germany Standard German Vlaams Limburgish Limburgish PicardBelgium Standard German Standard German WalloonFrench Standard German Picard Picard Polish FrenchLuxembourgeois Russian French Czech Republic Czech Ukrainian Polish French Luxembourgeois Polish Polish Luxembourgeois Polish Ukrainian French Rusyn Ukraine Swiss German Czech Slovakia Slovak Ukrainian Slovak Rusyn Breton Croatian Romanian Carpathian Romani Kazakhstan Balkan Romani Ukrainian Croatian Moldova Standard German Hungary Switzerland Standard German Romanian Austria Greek Swiss GermanWalser CroatianStandard German Mongolia RomanschWalser Standard German Bulgarian Russian France French Slovene Bulgarian Russian French LombardRomansch Ladin Slovene Standard