Classification of Eastern Iranian Languages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

(And Potential) Language and Linguistic Resources on South Asian Languages
CoRSAL Symposium, University of North Texas, November 17, 2017 Existing (and Potential) Language and Linguistic Resources on South Asian Languages Elena Bashir, The University of Chicago Resources or published lists outside of South Asia Digital Dictionaries of South Asia in Digital South Asia Library (dsal), at the University of Chicago. http://dsal.uchicago.edu/dictionaries/ . Some, mostly older, not under copyright dictionaries. No corpora. Digital Media Archive at University of Chicago https://dma.uchicago.edu/about/about-digital-media-archive Hock & Bashir (eds.) 2016 appendix. Lists 9 electronic corpora, 6 of which are on Sanskrit. The 3 non-Sanskrit entries are: (1) the EMILLE corpus, (2) the Nepali national corpus, and (3) the LDC-IL — Linguistic Data Consortium for Indian Languages Focus on Pakistan Urdu Most work has been done on Urdu, prioritized at government institutions like the Center for Language Engineering at the University of Engineering and Technology in Lahore (CLE). Text corpora: http://cle.org.pk/clestore/index.htm (largest is a 1 million word Urdu corpus from the Urdu Digest. Work on Essential Urdu Linguistic Resources: http://www.cle.org.pk/eulr/ Tagset for Urdu corpus: http://cle.org.pk/Publication/papers/2014/The%20CLE%20Urdu%20POS%20Tagset.pdf Urdu OCR: http://cle.org.pk/clestore/urduocr.htm Sindhi Sindhi is the medium of education in some schools in Sindh Has more institutional backing and consequent research than other languages, especially Panjabi. Sindhi-English dictionary developed jointly by Jennifer Cole at the University of Illinois Urbana- Champaign and Sarmad Hussain at CLE (http://182.180.102.251:8081/sed1/homepage.aspx). -

Linguistics Development Team
Development Team Principal Investigator: Prof. Pramod Pandey Centre for Linguistics / SLL&CS Jawaharlal Nehru University, New Delhi Email: [email protected] Paper Coordinator: Prof. K. S. Nagaraja Department of Linguistics, Deccan College Post-Graduate Research Institute, Pune- 411006, [email protected] Content Writer: Prof. K. S. Nagaraja Prof H. S. Ananthanarayana Content Reviewer: Retd Prof, Department of Linguistics Osmania University, Hyderabad 500007 Paper : Historical and Comparative Linguistics Linguistics Module : Indo-Aryan Language Family Description of Module Subject Name Linguistics Paper Name Historical and Comparative Linguistics Module Title Indo-Aryan Language Family Module ID Lings_P7_M1 Quadrant 1 E-Text Paper : Historical and Comparative Linguistics Linguistics Module : Indo-Aryan Language Family INDO-ARYAN LANGUAGE FAMILY The Indo-Aryan migration theory proposes that the Indo-Aryans migrated from the Central Asian steppes into South Asia during the early part of the 2nd millennium BCE, bringing with them the Indo-Aryan languages. Migration by an Indo-European people was first hypothesized in the late 18th century, following the discovery of the Indo-European language family, when similarities between Western and Indian languages had been noted. Given these similarities, a single source or origin was proposed, which was diffused by migrations from some original homeland. This linguistic argument is supported by archaeological and anthropological research. Genetic research reveals that those migrations form part of a complex genetical puzzle on the origin and spread of the various components of the Indian population. Literary research reveals similarities between various, geographically distinct, Indo-Aryan historical cultures. The Indo-Aryan migrations started in approximately 1800 BCE, after the invention of the war chariot, and also brought Indo-Aryan languages into the Levant and possibly Inner Asia. -

Pashto, Waneci, Ormuri. Sociolinguistic Survey of Northern
SOCIOLINGUISTIC SURVEY OF NORTHERN PAKISTAN VOLUME 4 PASHTO, WANECI, ORMURI Sociolinguistic Survey of Northern Pakistan Volume 1 Languages of Kohistan Volume 2 Languages of Northern Areas Volume 3 Hindko and Gujari Volume 4 Pashto, Waneci, Ormuri Volume 5 Languages of Chitral Series Editor Clare F. O’Leary, Ph.D. Sociolinguistic Survey of Northern Pakistan Volume 4 Pashto Waneci Ormuri Daniel G. Hallberg National Institute of Summer Institute Pakistani Studies of Quaid-i-Azam University Linguistics Copyright © 1992 NIPS and SIL Published by National Institute of Pakistan Studies, Quaid-i-Azam University, Islamabad, Pakistan and Summer Institute of Linguistics, West Eurasia Office Horsleys Green, High Wycombe, BUCKS HP14 3XL United Kingdom First published 1992 Reprinted 2004 ISBN 969-8023-14-3 Price, this volume: Rs.300/- Price, 5-volume set: Rs.1500/- To obtain copies of these volumes within Pakistan, contact: National Institute of Pakistan Studies Quaid-i-Azam University, Islamabad, Pakistan Phone: 92-51-2230791 Fax: 92-51-2230960 To obtain copies of these volumes outside of Pakistan, contact: International Academic Bookstore 7500 West Camp Wisdom Road Dallas, TX 75236, USA Phone: 1-972-708-7404 Fax: 1-972-708-7433 Internet: http://www.sil.org Email: [email protected] REFORMATTING FOR REPRINT BY R. CANDLIN. CONTENTS Preface.............................................................................................................vii Maps................................................................................................................ -

ARTICLE Development of a Gold-Standard Pashto Dataset and a Segmentation App Yan Han and Marek Rychlik
ARTICLE Development of a Gold-standard Pashto Dataset and a Segmentation App Yan Han and Marek Rychlik ABSTRACT The article aims to introduce a gold-standard Pashto dataset and a segmentation app. The Pashto dataset consists of 300 line images and corresponding Pashto text from three selected books. A line image is simply an image consisting of one text line from a scanned page. To our knowledge, this is one of the first open access datasets which directly maps line images to their corresponding text in the Pashto language. We also introduce the development of a segmentation app using textbox expanding algorithms, a different approach to OCR segmentation. The authors discuss the steps to build a Pashto dataset and develop our unique approach to segmentation. The article starts with the nature of the Pashto alphabet and its unique diacritics which require special considerations for segmentation. Needs for datasets and a few available Pashto datasets are reviewed. Criteria of selection of data sources are discussed and three books were selected by our language specialist from the Afghan Digital Repository. The authors review previous segmentation methods and introduce a new approach to segmentation for Pashto content. The segmentation app and results are discussed to show readers how to adjust variables for different books. Our unique segmentation approach uses an expanding textbox method which performs very well given the nature of the Pashto scripts. The app can also be used for Persian and other languages using the Arabic writing system. The dataset can be used for OCR training, OCR testing, and machine learning applications related to content in Pashto. -

Counterfactual-Hando
Third International Conference on Iranian Linguistics 11th-13th September 2009, Paris, Sorbonne Nouvelle Arseniy Vydrin Institute of Linguistic Studies St.Petersburg, Russia [email protected] Counterfactual mood in Iron Ossetic Ossetic1 (Northeastern Iranian): Iron, Digor dialects. Spoken mostly in The Republic of North Ossetia-Alania, about 500000 native speakers. 1. Counterfactual meaning Counterfactual meaning can be defined as the meaning which is contrary to the actual state of affairs. Conditional constructions with irreal condition are the easiest way to express the counterfactual meaning. For example, Persian: (1) Agar tabar-rā az dast-aš na-geferte1 bud2-and if axe-OBL PREP hand-ENCL.3SG NEG-take.PLUPERF1,2-3PL hame-ye mā-rā tekke pāre karde1 bud2-and all-EZF we-OBL piece piece do.PLUPERF1,2-3PL ‘If they hadn’t taken the axe from him we would have been hacked to pieces’ (S. Hedāyat. Katja). Couterfactual is considered to be the core meaning of the semantic domain of irrealis [Plungian 2005]. However, as shown in [Lazard 1998; Van Linden and Verstraete 2008], very few languages have a narrow dedicated marker for expressing only counterfactuality. In most languages, counterfactual meaning is a part of the semantic repertoire of some other “broad” markers, primarily associated with the domain of possibility / probability or past (including, according to Lazard, such values as prospective, desiderative, debitive, inceptive, evidentiality, habitual, subjunctive and optative). Most of the Iranian languages: past habitual, imperfect or pluperfect markers. Among languages which possess a dedicated counterfactual marker Lazard cites Turkana (Nilotic), Ewondo (Bantu), Yoruba and classic Nahuatl. Van Linden and Verstraete add Chukchi (Chukotko-Kamchatkan), Hua (Trans–New Guinea), Ika (Chibchan-Paezan), Kolyma Yukaghir, Martuthunira (Pama-Nyungan) and Somali (Cushitic). -

The Iranian Reflexes of Proto-Iranian *Ns
The Iranian Reflexes of Proto-Iranian *ns Martin Joachim Kümmel, Friedrich-Schiller-Universität Jena [email protected] Abstract1 The obvious cognates of Avestan tąθra- ‘darkness’ in the other Iranian languages generally show no trace of the consonant θ; they all look like reflexes of *tār°. Instead of assuming a different word formation for the non-Avestan words, I propose a solution uniting the obviously corresponding words under a common preform, starting from Proto-Iranian *taNsra-: Before a sonorant *ns was preserved as ns in Avestan (feed- ing the change of tautosyllabic *sr > *θr) but changed to *nh elsewhere, followed by *anhr > *ã(h)r. A parallel case of apparent variation can be explained similarly, namely Avestan pąsnu- ‘ashes’ and its cog- nates. Finally, the general development of Proto-Indo-Iranian *ns in Iranian and its relative chronology is discussed, including word-final *ns, where it is argued that the Avestan accusative plural of a-stems can be derived from *-āns. Keywords: Proto-Iranian, nasals, sibilant, sound change, variation, chronology 1. Introduction The aim of this paper is to discuss some details of the development of the Proto- Iranian (PIr) cluster *ns in the Iranian languages. Before we proceed to do so, it will be useful to recall the most important facts concerning the history of dental-alveolar sibilants in Iranian. 1) PIr had inherited a sibilant *s identical to Old Indo-Aryan (Sanskrit/Vedic) s from Proto-Indo-Iranian (PIIr) *s. This sibilant changed to Common Iranian (CIr) h in most environments, while its voiced allophone z remained stable all the time. -

Language Documentation and Description
Language Documentation and Description ISSN 1740-6234 ___________________________________________ This article appears in: Language Documentation and Description, vol 17. Editor: Peter K. Austin Countering the challenges of globalization faced by endangered languages of North Pakistan ZUBAIR TORWALI Cite this article: Torwali, Zubair. 2020. Countering the challenges of globalization faced by endangered languages of North Pakistan. In Peter K. Austin (ed.) Language Documentation and Description 17, 44- 65. London: EL Publishing. Link to this article: http://www.elpublishing.org/PID/181 This electronic version first published: July 2020 __________________________________________________ This article is published under a Creative Commons License CC-BY-NC (Attribution-NonCommercial). The licence permits users to use, reproduce, disseminate or display the article provided that the author is attributed as the original creator and that the reuse is restricted to non-commercial purposes i.e. research or educational use. See http://creativecommons.org/licenses/by-nc/4.0/ ______________________________________________________ EL Publishing For more EL Publishing articles and services: Website: http://www.elpublishing.org Submissions: http://www.elpublishing.org/submissions Countering the challenges of globalization faced by endangered languages of North Pakistan Zubair Torwali Independent Researcher Summary Indigenous communities living in the mountainous terrain and valleys of the region of Gilgit-Baltistan and upper Khyber Pakhtunkhwa, northern -

The Socio Linguistic Situation and Language Policy of the Autonomous Region of Mountainous Badakhshan: the Case of the Tajik Language*
THE SOCIO LINGUISTIC SITUATION AND LANGUAGE POLICY OF THE AUTONOMOUS REGION OF MOUNTAINOUS BADAKHSHAN: THE CASE OF THE TAJIK LANGUAGE* Leila Dodykhudoeva Institute Of Linguistics, Russian Academy Of Sciences The paper deals with the problem of closely related languages of the Eastern and Western Iranian origin that coexist in a close neighbourhood in a rather compact area of one region of Republic Tajikistan. These are a group of "minor" Pamir languages and state language of Tajikistan - Tajik. The population of the Autonomous Region of Mountainous Badakhshan speaks different Pamir languages. They are: Shughni, Rushani, Khufi, Bartangi, Roshorvi, Sariqoli; Yazghulami; Wakhi; Ishkashimi. These languages have no script and written tradition and are used only as spoken languages in the region. The status of these languages and many other local linguemes is still discussed in Iranology. Nearly all Pamir languages to a certain extent can be called "endangered". Some of these languages, like Yazghulami, Roshorvi, Ishkashimi are included into "The Red Book " (UNESCO 1995) as "endangered". Some of them are extinct. Information on other idioms up to now is not available. These languages live in close cooperation and interaction with the state language of Tajikistan - Tajik. Almost all population of Badakhshan is multilingual or bilingual. The second language is official language of the state - Tajik. This language is used in Badakhshan as the language of education, press, media, and culture. This is the reason why this paper is focused on the status of Tajik language in Republic Tajikistan and particularly in Badakhshan. The Tajik literary language (its oral and written forms) has a long history and rich written traditions. -

Voice and Transitivity in Complex Predicates in Iranian Agnes Korn
Looking for the Middle Way: Voice and Transitivity in Complex Predicates in Iranian Agnes Korn To cite this version: Agnes Korn. Looking for the Middle Way: Voice and Transitivity in Complex Predicates in Iranian . Lingua, Elsevier, 2013, Special Issue: Complex Predicates, 135, pp. 30-55. 10.1016/j.lingua.2013.07.015. halshs-01340632 HAL Id: halshs-01340632 https://halshs.archives-ouvertes.fr/halshs-01340632 Submitted on 1 Jul 2016 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution - NonCommercial - NoDerivatives| 4.0 International License [NOTICE: this is the author's version of a work that was accepted for publication in Lingua. Changes resulting from the publishing process, such as editing, corrections, structural formatting, and other quality control mechanisms may not be reflected in this document. A definitive version was subsequently published in Lingua 135, pp. 30-55, http://dx.doi.org/10.1016/j.lingua.2013.07.015] Looking for the Middle Way: Voice and Transitivity in Complex Predicates in Iranian * Agnes Korn Abstract This article explores the emergence of complex predicates in Persian with a focus on voice and transitivity. -
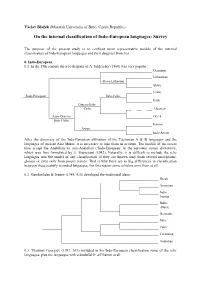
Internal Classification of Indo-European Languages: Survey
Václav Blažek (Masaryk University of Brno, Czech Republic) On the internal classification of Indo-European languages: Survey The purpose of the present study is to confront most representative models of the internal classification of Indo-European languages and their daughter branches. 0. Indo-European 0.1. In the 19th century the tree-diagram of A. Schleicher (1860) was very popular: Germanic Lithuanian Slavo-Lithuaian Slavic Celtic Indo-European Italo-Celtic Italic Graeco-Italo- -Celtic Albanian Aryo-Graeco- Greek Italo-Celtic Iranian Aryan Indo-Aryan After the discovery of the Indo-European affiliation of the Tocharian A & B languages and the languages of ancient Asia Minor, it is necessary to take them in account. The models of the recent time accept the Anatolian vs. non-Anatolian (‘Indo-European’ in the narrower sense) dichotomy, which was first formulated by E. Sturtevant (1942). Naturally, it is difficult to include the relic languages into the model of any classification, if they are known only from several inscriptions, glosses or even only from proper names. That is why there are so big differences in classification between these scantily recorded languages. For this reason some scholars omit them at all. 0.2. Gamkrelidze & Ivanov (1984, 415) developed the traditional ideas: Greek Armenian Indo- Iranian Balto- -Slavic Germanic Italic Celtic Tocharian Anatolian 0.3. Vladimir Georgiev (1981, 363) included in his Indo-European classification some of the relic languages, plus the languages with a doubtful IE affiliation at all: Tocharian Northern Balto-Slavic Germanic Celtic Ligurian Italic & Venetic Western Illyrian Messapic Siculian Greek & Macedonian Indo-European Central Phrygian Armenian Daco-Mysian & Albanian Eastern Indo-Iranian Thracian Southern = Aegean Pelasgian Palaic Southeast = Hittite; Lydian; Etruscan-Rhaetic; Elymian = Anatolian Luwian; Lycian; Carian; Eteocretan 0.4. -

A Linguistic Assessment of the Munji Language in Afghanistan
Vol. 6 (2011), pp. 38-103 http://nflrc.hawaii.edu/ldc/ http://hdl.handle.net/10125/4506 A Linguistic Assessment of the Munji Language in Afghanistan Daniela Beyer Simone Beck International Assistance Mission (IAM) This paper presents a sociolinguistic assessment of the Munji (ISO: mnj) speech variety based on data collected in the Munjan area of northern Afghanistan. The goal was to determine whether a national language is adequate for primary school education and literature, or whether the Munji people would benefit from language development, including literature development in the vernacular. The survey trip entailed administering questionnaires to village elders,sociolinguistic questionnaires as well as Dari proficiency questionnaires to men and women of various age groups, eliciting word lists, and observing intelligibility of Dari and language use. In this way we aimed to determine the vitality of Munji, the different varieties of Munji, the use of Munji and Dari in the different domains of life, attitudes toward the speaking community’s own speech variety and toward Dari, and to investigate their intelligibility of Dari. In this paper we aim to show that the Munji people would benefit from Munji language development as a basis for both primary school material and adult literacy material in the mother tongue. In the long term, this is likely to raise the education level as well as the Munji people’s ability to acquire Dari literacy. 1. INTRODUCTION.1 From April 20 to 25, 2008, we conducted sociolingistic research in the Munjan language area of northern Afghanistan.2 The research was carried out under the auspices of the International Assistance Mission (IAM), a non-governmental organization working in Afghanistan. -

THE PHONOLOGY of the VERBAL PHRASE in HINDKO Submitted By
THE PHONOLOGY OF THE VERBAL PHRASE IN HINDKO submitted by ELAHI BAKHSH AKHTAR AWAN FOR THE AWARD OF A DEGREE OF Ph.D. at the UNIVERSITY OF LONDON 1974 ProQuest Number: 10672820 All rights reserved INFORMATION TO ALL USERS The quality of this reproduction is dependent upon the quality of the copy submitted. In the unlikely event that the author did not send a com plete manuscript and there are missing pages, these will be noted. Also, if material had to be removed, a note will indicate the deletion. uest ProQuest 10672820 Published by ProQuest LLC(2017). Copyright of the Dissertation is held by the Author. All rights reserved. This work is protected against unauthorized copying under Title 17, United States C ode Microform Edition © ProQuest LLC. ProQuest LLC. 789 East Eisenhower Parkway P.O. Box 1346 Ann Arbor, Ml 48106- 1346 acknowledgment I wish to express my profound sense of gratitude and indebtedness to my supervisor Dr. R.K. Sprigg. But for his advice, suggestions, constructive criticism and above all unfailing kind ness at all times this thesis could not have been completed. In addition, I must thank my wife Riaz Begum for her help and encouragement during the many months of preparation. CONTENTS Introduction i Chapter I Value of symbols used in this thesis 1 1 .00 Introductory 1 1.10 I.P.A. Symbols 1 1.11 Other symbols 2 Chapter II The Verbal Phrase and the Verbal Word 6 2.00 Introductory 6 2.01 The Sentence 6 2.02 The Phrase 6 2.10 The Verbal Phra.se 7 2.11 Delimiting the Verbal Phrase 7 2.12 Place of the Verbal Phrase 7 2.121