Train Shunting and Service Scheduling: an Integrated Local Search Approach
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Serviceability of Passenger Trains During Acquisition Projects
SERVICEABILITY OF PASSENGER TRAINS DURING ACQUISITION PROJECTS Jorge Eduardo Parada Puig SERVICEABILITY OF PASSENGER TRAINS DURING ACQUISITION PROJECTS DISSERTATION to obtain the degree of doctor at the University of Twente, on the authority of the rector magnificus, Prof. Dr. H. Brinksma, on account of the decision of the graduation committee, to be publicly defended on Wednesday the th of June at : by Jorge Eduardo Parada Puig born on the th of September in Mérida, Venezuela. This dissertation has been approved by the Supervisor: Prof.Dr.Ir. L.A.M. van Dongen and the Co-Supervisors: Dr.Ir. S. Hoekstra Dr.Ir. R.J.I. Basten SERVICEABILITY OF PASSENGER TRAINS DURING ACQUISITION PROJECTS Jorge Eduardo Parada Puig Dissertation Committee Chairman / Secretary Prof.dr. G.P.M.R. Dewulf Supervisor Prof.dr.ir. L.A.M. van Dongen Co-Supervisors Dr.ir. S. Hoekstra Dr.ir. R.J.I. Basten Members Prof.dr.ir. T. Tinga (UT, CTW) Prof.dr.ir. F.J.A.M. van Houten (UT, CTW) Prof.dr.ir. C. Witteveen (TU Delft, EWI) Prof.dr.ir. G.J.J.A.N. Jan van Houtum (TU/e, IEIS) Prof.dr.ir. D. Gerhard (TU Wien, MWB) This research is part of the “Rolling Stock Life Cycle Logistics” applied research and development program, funded by NS/NedTrain. Publisher: J.E. Parada Puig, Design Production and Management, University of Twente, P.O. Box , AE Enschede, The Netherlands Cover by J.E. Parada Puig The image of the front cover is a graphical representation of the indenture struc- ture of a train, and its optimal line replaceable unit definitions. -

Llght Rall Translt Statlon Deslgn Guldellnes
PORT AUTHORITY OF ALLEGHENY COUNTY LIGHT RAIL TRANSIT V.4.0 7/20/18 STATION DESIGN GUIDELINES ACKNOWLEDGEMENTS Port Authority of Allegheny County (PAAC) provides public transportation throughout Pittsburgh and Allegheny County. The Authority’s 2,600 employees operate, maintain, and support bus, light rail, incline, and paratransit services for approximately 200,000 daily riders. Port Authority is currently focused on enacting several improvements to make service more efficient and easier to use. Numerous projects are either underway or in the planning stages, including implementation of smart card technology, real-time vehicle tracking, and on-street bus rapid transit. Port Authority is governed by an 11-member Board of Directors – unpaid volunteers who are appointed by the Allegheny County Executive, leaders from both parties in the Pennsylvania House of Representatives and Senate, and the Governor of Pennsylvania. The Board holds monthly public meetings. Port Authority’s budget is funded by fare and advertising revenue, along with money from county, state, and federal sources. The Authority’s finances and operations are audited on a regular basis, both internally and by external agencies. Port Authority began serving the community in March 1964. The Authority was created in 1959 when the Pennsylvania Legislature authorized the consolidation of 33 private transit carriers, many of which were failing financially. The consolidation included the Pittsburgh Railways Company, along with 32 independent bus and inclined plane companies. By combining fare structures and centralizing operations, Port Authority established the first unified transit system in Allegheny County. Participants Port Authority of Allegheny County would like to thank agency partners for supporting the Light Rail Transportation Station Guidelines, as well as those who participated by dedicating their time and expertise. -

Solent Connectivity May 2020
Solent Connectivity May 2020 Continuous Modular Strategic Planning Page | 1 Page | 2 Table of Contents 1.0 Executive Summary .......................................................................................................................................... 6 2.0 The Solent CMSP Study ................................................................................................................................... 10 2.1 Scope and Geography....................................................................................................................... 10 2.2 Fit with wider rail industry strategy ................................................................................................. 11 2.3 Governance and process .................................................................................................................. 12 3.0 Context and Strategic Questions ............................................................................................................ 15 3.1 Strategic Questions .......................................................................................................................... 15 3.2 Economic context ............................................................................................................................. 16 3.3 Travel patterns and changes over time ............................................................................................ 18 3.4 Dual-city region aspirations and city to city connectivity ................................................................ -

NS Annual Report 2018
See www.nsannualreport.nl for the online version NS Annual Report 2018 Table of contents 2 In brief 4 2018 in a nutshell 8 Foreword by the CEO 12 The profile of NS 16 Our strategy Activities in the Netherlands 23 Results for 2018 27 The train journey experience 35 Operational performance 47 World-class stations Operations abroad 54 Abellio 56 Strategy 58 Abellio United Kingdom (UK) 68 Abellio Germany 74 Looking ahead NS Group 81 Report by the Supervisory Board 94 Corporate governance 100 Organisation of risk management 114 Finances in brief 126 Our impact on the environment and on society 134 NS as an employer in the Netherlands 139 Organisational improvements 145 Dialogue with our stakeholders 164 Scope and reporting criteria Financial statements 168 Financial statements 238 Company financial statements Other information 245 Combined independent auditor’s report on the financial statements and sustainability information 256 NS ten-year summary This annual report is published both Dutch and English. In the event of any discrepancies between the Dutch and English version, the Dutch version will prevail. 1 NS annual report 2018 In brief More satisfied 4.2 million trips by NS app gets seat passengers in the OV-fiets searcher Netherlands (2017: 3.1 million) On some routes, 86% gave travelling by passengers can see which train a score of 7 out of carriages have free seats 10 or higher Customer 95.1% chance of Clean trains: 68% of satisfaction with HSL getting a seat passengers gave a South score of 7 out of 10 (2017: 95.0%) or higher 83% of -
European Railways Combine
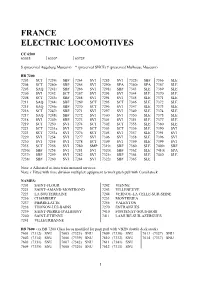
FRANCE ELECTRIC LOCOMOTIVES CC 6500 6503$ 6530* 6572# $ (preserved Augsburg Museum) * (preserved SNCF) # (preserved Mulhouse Museum) BB 7200 7203 SCT 7239r SBF 7264 SVI 7285 SVI 7323r SBF 7366 SLE 7204 SCT 7240r SBF 7265 SVI 7290r SPA 7340r SPA 7367 SLE 7205 SAQ 7241r SBF 7266 SVI 7291r SBF 7343 SLE 7369 SLE 7206 SVI 7242 SCT 7267 SVI 7293 SVI 7344 SLE 7370 SLE 7208 SCT 7243r SBF 7268 SVI 7294 SVI 7345 SLE 7371 SLE 7211 SAQ 7244r SBF 7269 SCT 7295 SCT 7346 SLE 7372 SLE 7215 SAQ 7246r SBF 7270 SCT 7296 SVI 7347 SLE 7373 SLE 7216 SCT 7247r SBF 7271 SVI 7297 SVI 7349 SLE 7374 SLE 7217 SAQ 7248r SBF 7272 SVI 7300 SVI 7350 SLE 7375 SLE 7218 SVI 7249r SBF 7273 SVI 7301 SVI 7351 SLE 7377 SLE 7219 SCT 7250 SVI 7274 SCT 7302 SCT 7355 SLE 7380 SLE 7221 SCT 7251a SVI 7275 SCT 7303 SCT 7356 SLE 7390 SVI 7223 SCT 7253a SVI 7276 SCT 7305 SVI 7357 SLE 7391 SVI 7229 SVI 7254 SVI 7277 SVI 7306 SVI 7358 SLE 7396 SVI 7230 SVI 7255 SVI 7278 SCT 7309 SVI 7359 SLE 7399 SVI 7235 SCT 7256 SVI 7280 SMP 7319r SBF 7360 SLE 7409r SBF 7236r SBF 7258 SVI 7281 SVI 7320r SBF 7362 SLE 7410r SPA 7237r SBF 7259 SVI 7282 SVI 7321r SBF 7364 SLE 7440 SLE 7238r SBF 7260 SVI 7284 SVI 7322r SBF 7365 SLE Note: a Allocated to Auto train motorail services Note: r Fitted with time division multiplex equipment to work push pull with Corail stock NAMES: 7203 SAINT-FLOUR 7242 VIENNE 7221 SAINT-AMAND-MONTROND 7243 VILLENEUVE 7223 LA SOUTERRAINE 7244 VERNOU-LA CELLE-SUR-SEINE 7236 CHAMBERY 7253 MONTREJEA 7237 PIERRELATTE 7256 VALENTON 7238 THONON-LES-BAINS 7270 ENTRAIGUES 7239 SAINT-PIERRE-D'ALBIGNY 7410 FONTENAY-SOUS-BOIS 7240 SAINT-ETIENNE 7411 LAMURE-SUR-AZERGUES 7241 VILLEURBANNE BB 7600 (ex BB 7200 Class locos modified for push pull with VB2N double deck stock) 7601 (7312) SNU 7605 (7325) SNU 7609 (7330) SNU 7613 (7327) SNU 7602 (7314) SNU 7606 (7339) SNU 7610 (7332) SNU 7614 (7337) SNU 7603 (7331) SNU 7607 (7342) SNU 7611 (7341) SNU 7604 (7335) SNU 7608 (7326) SNU 7612 (7311) SNU 5 BELGIUM DIESEL LOCOMOTIVES Class 50 Co-Co 5001 Saint-Gobain Works, Auvelais. -

STAMP Incident Investigation: Control Structures As a Tool to Intervene
STAMP Incident Investigation: Control Structures as a Tool to Intervene Rob Hoitsma Kirsten van Schaardenburgh Our goals today • To show you our use of STAMP during incident investigation • To share with you • the results so far • our recommendations Questions you migth have 1. Who is NEDTRAIN? 2. What is NEDTRAIN’s ‘traditional way’ of incident investigation? 3. Why did you introduce STAMP? 4. How did you apply STAMP? 5. Can you show us an example? 6. What are the results of using STAMP till now? 7. What would you recommend us? 1. NedTrain & NS NS: Operator & Owner rolling stock Amsterdam Daily inspection & cleaning Onnen 30 servicelocations Maastricht Amsterdam Leidschendam Groningen Line Maintenance Depot 30.000- 100.000 km Repairs Den Haag Maastricht Component R & O Overhaul Haarlem Overhaul and modernisations 15-20 years NedTrain: Subsidiary of Dutch Railways (NS) Damage repairs Maintenance, Repair & Overhaul of NS fleet 3100 emplyees 2. NEDTRAIN’s incident investigation Incidents & near misses: • Railtraffic (shunting), • Occupational health • Train safety Approx. 100 investigations/yr Proces: • Interviews • Data analysis • Multi Timeline & animation • Analysis & conclusions • Check & suggestions; by presenting to all involved • Measures & management learning; by presenting to management • New: STAMP analysis to improve last step 5 3. Reasons for introducing STAMP • Nancy’s lecture on STAMP in Amsterdam 2014 • Desire to include systems thinking in incident investigation • Desire to include mental models in incident investigation • Desire to change thinking of management • they did it wrong why did it make sense? • It’s up to the workfloor I have a stake! 6 4. Application of STAMP: context • Little experience in applying STAMP during incident investigation • at NEDTRAIN: none • in the Netherlands: limited, mainly Dutch Safety Board • No handbook • No training courses • Solution: hands-on coaching by experienced user, just start! 7 4. -

The Urban Rail Development Handbook
DEVELOPMENT THE “ The Urban Rail Development Handbook offers both planners and political decision makers a comprehensive view of one of the largest, if not the largest, investment a city can undertake: an urban rail system. The handbook properly recognizes that urban rail is only one part of a hierarchically integrated transport system, and it provides practical guidance on how urban rail projects can be implemented and operated RAIL URBAN THE URBAN RAIL in a multimodal way that maximizes benefits far beyond mobility. The handbook is a must-read for any person involved in the planning and decision making for an urban rail line.” —Arturo Ardila-Gómez, Global Lead, Urban Mobility and Lead Transport Economist, World Bank DEVELOPMENT “ The Urban Rail Development Handbook tackles the social and technical challenges of planning, designing, financing, procuring, constructing, and operating rail projects in urban areas. It is a great complement HANDBOOK to more technical publications on rail technology, infrastructure, and project delivery. This handbook provides practical advice for delivering urban megaprojects, taking account of their social, institutional, and economic context.” —Martha Lawrence, Lead, Railway Community of Practice and Senior Railway Specialist, World Bank HANDBOOK “ Among the many options a city can consider to improve access to opportunities and mobility, urban rail stands out by its potential impact, as well as its high cost. Getting it right is a complex and multifaceted challenge that this handbook addresses beautifully through an in-depth and practical sharing of hard lessons learned in planning, implementing, and operating such urban rail lines, while ensuring their transformational role for urban development.” —Gerald Ollivier, Lead, Transit-Oriented Development Community of Practice, World Bank “ Public transport, as the backbone of mobility in cities, supports more inclusive communities, economic development, higher standards of living and health, and active lifestyles of inhabitants, while improving air quality and liveability. -

Study on Medium Capacity Transit System Project in Metro Manila, the Republic of the Philippines
Study on Economic Partnership Projects in Developing Countries in FY2014 Study on Medium Capacity Transit System Project in Metro Manila, The Republic of The Philippines Final Report February 2015 Prepared for: Ministry of Economy, Trade and Industry Ernst & Young ShinNihon LLC Japan External Trade Organization Prepared by: TOSTEMS, Inc. Oriental Consultants Global Co., Ltd. Mitsubishi Heavy Industries, Ltd. Japan Transportation Planning Association Reproduction Prohibited Preface This report shows the result of “Study on Economic Partnership Projects in Developing Countries in FY2014” prepared by the study group of TOSTEMS, Inc., Oriental Consultants Global Co., Ltd., Mitsubishi Heavy Industries, Ltd. and Japan Transportation Planning Association for Ministry of Economy, Trade and Industry. This study “Study on Medium Capacity Transit System Project in Metro Manila, The Republic of The Philippines” was conducted to examine the feasibility of the project which construct the medium capacity transit system to approximately 18km route from Sta. Mesa area through Mandaluyong City, Ortigas CBD and reach to Taytay City with project cost of 150 billion Yen. The project aim to reduce traffic congestion, strengthen the east-west axis by installing track-guided transport system and form the railway network with connecting existing and planning lines. We hope this study will contribute to the project implementation, and will become helpful for the relevant parties. February 2015 TOSTEMS, Inc. Oriental Consultants Global Co., Ltd. Mitsubishi Heavy -

Eindhoven University of Technology MASTER an Aggregate Planning For
Eindhoven University of Technology MASTER An aggregate planning for preventive maintenance of bogies by NedTrain Vernooij, K. Award date: 2011 Link to publication Disclaimer This document contains a student thesis (bachelor's or master's), as authored by a student at Eindhoven University of Technology. Student theses are made available in the TU/e repository upon obtaining the required degree. The grade received is not published on the document as presented in the repository. The required complexity or quality of research of student theses may vary by program, and the required minimum study period may vary in duration. General rights Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. • Users may download and print one copy of any publication from the public portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain Eindhoven, July 2011 An Aggregate Planning for Preventive Maintenance of Bogies by NedTrain by Karin Vernooij BSc Industrial Engineering & Management Science (2009) Student Identity Number 0572650 in partial fulfilment of the requirements for the degree of Master of Science in Operations Management and Logistics Supervisors: Ir. B. Huisman, NedTrain Ir. dr. S.D.P. Flapper, TU/e, OPAC Prof. dr. ir. G.J. van Houtum, TU/e, OPAC Ir. J.J. Arts, TU/e, OPAC II TUE. -

Nedtrain.Pdf
Get Practiced: Op Snijvlak van Techniek en Proces! AMC Seminar 2013 Amersfoort, 10 oktober 2013 Prof.dr.ir. Leo A.M. van Dongen NedTrain Fleet Services Universiteit Twente Bedrijfsbrede Aanpak van Instandhouding Inhoud • Innovatieketen • Operational Excellence (zie AMC Seminar 2009) • Techniek terug op de agenda • Performance verbetering van materieel • Registreren, analyseren en bijsturen • Vergroting van voorspelbaarheid • Dynamisering van onderhoudsaanpak • Lerende organisatie Bijlagen: karakteristiek van NedTrain 2 Innovatieketen Vervoerders Leveranciers Energiebedrijven Architecten Consumenten Organisaties Aannemers Productie- proces Wetgeving Techniek Product Onderhouds- Kennisinstellingen proces Overheid Adviseurs Reizigers System Integrators Toezichthouders Service Providers Scheepswerven 3 Installateurs 2005-2010 Operationeel Proces op Orde! Reveil (1) Meer doen met minder maar betere middelen (55+ regeling) Aandacht voor primair proces: • Afleverkwaliteit (PQI), Kaizen, Lean Working, First Time Right • Veiligheid als voorwaarde • Opleidingen en sociale innovatie Vernieuwing van bedrijfsmiddelen (ca. 200 mio geïnvesteerd): • In/uitproces in Haarlem • Hispeed werkplaats in Watergraafsmeer • Wasmachines en servicelocaties Nijmegen, Utrecht, Eindhoven, Maastricht en Den Haag • Verhuizing in Rotterdam en Tilburg Boter bij de Vis Roadshow op locaties Medewerkers presenteren voor jury ideeën! 5 Onttrekking in Kort Cyclisch Onderhoud 6 Veiligheids DO Bespreking diverse veiligheidsonderwerpen Inspectierondes met terugkoppeling 7 Ontwikkeling -

Exposition Corridor Transit Project Phase 2 Final Environmental Impact Report Technical Background Report
Exposition Metro Line Construction Authority Exposition Corridor Transit Project Phase 2 Final Environmental Impact Report Technical Background Report FINAL Hazards and Hazardous Materials December 2009 Prepared for: Exposition Metro Line Construction Authority By: ERRATA The Exposition Metro Line Construction Authority (Expo Authority) has determined that the bike path and Second Street Santa Monica Terminus are no longer under consideration as part of the Expo Phase 2 Light-Rail Transit project. This Technical Background Report was drafted prior to the final definition of the LRT Alternatives that was presented in the Draft Environmental Impact Report (DEIR). Accordingly, discussion of the bike path and Second Street Santa Monica Terminus still remain in this report but no longer apply and should be disregarded. Exposition Corridor Transit Project Phase 2 FINAL Hazards and Hazardous Materials Contents 1. INTRODUCTION ....................................................................................................................... 1 1.1 Overview ............................................................................................................. 1 1.2 Project Summary ................................................................................................ 1 1.2.1 No-Build Alternative ................................................................................. 1 1.2.2 Transportation Systems Management (TSM) Alternative ......................... 2 1.2.3 Light-Rail Transit (LRT) Alternatives ....................................................... -

Part 2 Feasibility Study on the Yangon Circular Railway Line
Part 2 Feasibility Study on The Yangon Circular Railway Line Upgrading Project Feasibility Study Report onThe the Yangon CircularCircular RailwRailwayay Line Upgrading Project Final Report Chapter 1 Introduction 1.1 Background of the Project The city of Yangon, with a population of about 5.21 million as of 2014 according to the year 2014 Census Survey, is the largest economic center of the country, and has been experiencing rapid urbanization in these days. With the recent economic reform and corresponding deregulation, the number of imported cars has increased sharply. According to the Comprehensive Urban Transport Master Plan of the Greater Yangon (YUTRA), the number of registered vehicles in the Yangon region dramatically increased from 260,000 cars in 2011/2012 to some 370,000 cars in 2012/2013 (Figure 1.1.1). Imported used cars are used mainly for personal and business purposes such as taxi services and commodity delivery, and the Yangon residents are now suffered from serious traffic congestion. While the number of cars has increased, service level of the existing public buses has remains almost the same as before. The public buses in the city have continued to be crowded, but majority of the people have no alternative modes of public transport. Source: YUTRA, JICA (2013) Figure 1.1.1 The number of registered vehicles in the Yangon Region The Yangon Circular Railway Line (herein after referred as “the YCR Line”) is expected to perform as a spine urban transit system in Yangon. However, the modal share of the YCR remains low at present. Less attractive level of service of the YCR Line is resulted in a small share of rail based trips.