On the Design of a Dual-Mode User Interface for Accessing 3D Content on the World Wide Web Jacek Jankowski, Stefan Decker
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Origins of the Underline As Visual Representation of the Hyperlink on the Web: a Case Study in Skeuomorphism
The Origins of the Underline as Visual Representation of the Hyperlink on the Web: A Case Study in Skeuomorphism The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Romano, John J. 2016. The Origins of the Underline as Visual Representation of the Hyperlink on the Web: A Case Study in Skeuomorphism. Master's thesis, Harvard Extension School. Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:33797379 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA The Origins of the Underline as Visual Representation of the Hyperlink on the Web: A Case Study in Skeuomorphism John J Romano A Thesis in the Field of Visual Arts for the Degree of Master of Liberal Arts in Extension Studies Harvard University November 2016 Abstract This thesis investigates the process by which the underline came to be used as the default signifier of hyperlinks on the World Wide Web. Created in 1990 by Tim Berners- Lee, the web quickly became the most used hypertext system in the world, and most browsers default to indicating hyperlinks with an underline. To answer the question of why the underline was chosen over competing demarcation techniques, the thesis applies the methods of history of technology and sociology of technology. Before the invention of the web, the underline–also known as the vinculum–was used in many contexts in writing systems; collecting entities together to form a whole and ascribing additional meaning to the content. -

Xolo Omega 5.0 Rom Download
Xolo omega 5.0 rom download CLICK TO DOWNLOAD 8. · Xolo Omega Stock Firmware (flash file) The Flash File will help you to Upgrade, Downgrade, or re-install the Stock Firmware (OS) on your Mobile Device. The Flash File (ROM) also helps you to repair the Mobile device, if it is facing any Software Issue, Bootloop Issue, IMEI Issue, or Dead Issue. File Name: Xolo_Omega__S_zip. Download Xolo Omega Flash File and Install Mediatek Driver, Charge the phone 30% before flashing. First download all the files above; Extract All File From Zip File. Open the FlashTool folder and run renuzap.podarokideal.ru After that open, the tool, click on choose in the download agent tab. This flash file helps you to upgrade or downgrade the firmware of your Xolo Omega Android phone. Stock firmware fix software related issues, IMEI related issues, improve performance and boot loop issues, etc. Here you can download the latest and original version of stock firmware (Flash File) for your Xolo Omega renuzap.podarokideal.ru: Sai Y. Home / Tag Archives: Download Xolo Omega stock ROM. Tag Archives: Download Xolo Omega stock ROM Xolo Omega Xolo. 7. · If you own a Xolo Omega smartphone and want to Install Stock Rom or Firmware on it to unbrick or fix bootloop issue then you can download latest Firmware for it. In this page we have shared step by step guide to Install Stock Firmware or flash file on Xolo Omega /5. Find Xolo Omega Flash File, Flash Tool, USB Driver and How-to Flash Manual. The official link to download Xolo Omega Stock Firmware ROM (flash file) on your Computer. -

Summary of March 12, 2013 FTC Guide, “Dot Com Disclosures” by Susan D
Originally published in the American Advertising Federation Phoenix Chapter Newsletter (June 2013) Summary of March 12, 2013 FTC Guide, “Dot Com Disclosures” By Susan D. Brienza, Attorney at Ryley Carlock & Applewhite “Although online commerce (including mobile and social media marketing) is booming, deception can dampen consumer confidence in the online marketplace.” Conclusion of new FTC Guide on Disclosures The Federal Trade Commission (“FTC”) has broad powers to regulate and monitor all advertisements for goods and services (with the exception of a few industries such as banking and aviation)— advertisements in any medium whatsoever, including Internet and social media promotions. Under long-standing FTC statutes, regulations and policy, all marketing claims must be true, accurate, not misleading or deceptive, and supported by sound scientific or factual research. Often, in order to “cure” a potentially deceptive claim, a disclaimer or a disclosure is required, e.g., “The following blogs are paid reviews.” Recently, on March 12, 2013, the Federal Trade Commission published a revised version of its 2000 guide known as Dot Com Disclosures, after a two-year process. The new FTC staff guidance, .com Disclosures: How to Make Effective Disclosures in Digital Advertising, “takes into account the expanding use of smartphones with small screens and the rise of social media marketing. It also contains mock ads that illustrate the updated principles.” See the FTC’s press release regarding its Dot Com Disclosures guidance: http://www.ftc.gov/opa/2013/03/dotcom.shtm and the 53-page guide itself at http://ftc.gov/os/2013/03/130312dotcomdisclosures.pdf . I noted with some amusement that the FTC ends this press release and others with: “Like the FTC on Facebook, follow us on Twitter. -
September 25, 2008
. -\ •••)*• - • '•*' J -.-. online tiometownlife.com September 25r 2008 75 cents WINNERS OF STATE AND NATIONAL AWARDS OF EXCELLENCE www.hometownlife.coni BY DARRELL CLEM OBSERVER STAFF WRITER In a troubled econ omy marked by rising expenses, Westland single mom Juanita Francis looks for frugal ways to spend quality time with BY DARRELL CLEM daughters Naomi, OBSERVER STAFF WRITER Trinity, Mijai and Ashe, ages 5 to 14. A potential strike by Wayne- 'She found it Westland teachers still looms Tuesday* as did hun amid an impasse in contract dreds of others who talks between bargaining teams gathered in Tattan representing the 850-member Park near Carlson union and school district offi and Ford for Mayor cials. William Wild's latest Despite the stalemate, district community gather Superintendent Greg Baracy ing. confirmed Monday during a "I think Westland school board meeting that "we're is one of the most negotiating." Barring a collapse phenomenal com of talks, three more bargaining FILE PHOTO munities around," * sessions are scheduled to occur Francis, a teacher at by early next week. On three separate occasions, the alternative educa "There has not been any prog including Monday evening, Wayne tion Tinkham Center, ress made," Wayne-Westland Westland teachers have gathered at said, adding that Education Association union the district's administrative offices Wild and hi.* admin President Nancy Strachan to protest the course of current istration "are keeping said Monday evening, as a contract talks. people connected and large crowd of placard-car grounded." rying teachers protested out If Francis had side school district offices on ing shortfalls to usher in cuts appeared in a tele Marquette. -

Insert a Hyperlink OPEN the Research on First Ladies Update1 Document from the Lesson Folder
Step by Step: Insert a Hyperlink Step by Step: Insert a Hyperlink OPEN the Research on First Ladies Update1 document from the lesson folder. 1. Go to page four and select the Nancy Reagan picture. 2. On the Insert tab, in the Links group, click the Hyperlink button to open the Insert Hyperlink dialog box. The Insert Hyperlink dialog box opens. By default, the Existing File or Web Page is selected. There are additional options on where to place the link. 3. Key http://www.firstladies.org/biographies/ in the Address box; then click OK. Hypertext Transfer Protocol (HTTP) is how the data is transfer to the external site through the servers. The picture is now linked to the external site. 4. To test the link, press Ctrl then click the left mouse button. When you hover over the link, a screen tip automatically appears with instructions on what to do. 5. Select Hilary Clinton and repeat steps 2 and 3. Word recalls the last address, and the full address will appear once you start typing. You have now linked two pictures to an external site. 6. It is recommended that you always test your links before posting or sharing. You can add links to text or phrases and use the same process that you just completed. 7. Step by Step: Insert a Hyperlink 8. Insert hyperlinks with the same Web address to both First Ladies names. Both names are now underlined, showing that they are linked. 9. Hover over Nancy Reagan’s picture and you should see the full address that you keyed. -
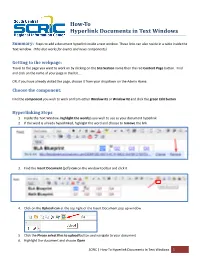
How to Hyperlink Documents in Text Windows
How-To Hyperlink Documents in Text Windows Summary: Steps to add a document hyperlink inside a text window. These links can also reside in a table inside the Text window. (This also works for events and news components). Getting to the webpage: Travel to the page you want to work on by clicking on the Site Section name then the red Content Page button. Find and click on the name of your page in the list….. OR, if you have already visited the page, choose it from your dropdown on the Admin Home. Choose the component: Find the component you wish to work on from either Window #1 or Window #2 and click the green Edit button Hyperlinking Steps 1. Inside the Text Window, highlight the word(s) you wish to use as your document hyperlink 2. If the word is already hyperlinked, highlight the word and choose to remove the link 3. Find the Insert Document (pdf) icon on the window toolbar and click it 4. Click on the Upload icon at the top right of the Insert Document pop up window 5. Click the Please select files to upload button and navigate to your document 6. Highlight the document and choose Open SCRIC | How-To Hyperlink Documents In Text Windows 1 7. You will now see your document at the top of the Insert Document pop up window. 8. You can choose here to have the document open in a new window if you like by clicking on the dropdown called Target (it will open in a new window when viewers click on the document hyperlink) 9. -

Hyperlinks and Bookmarks with ODS RTF Scott Osowski, PPD, Inc, Wilmington, NC Thomas Fritchey, PPD, Inc, Wilmington, NC
Paper TT21 Hyperlinks and Bookmarks with ODS RTF Scott Osowski, PPD, Inc, Wilmington, NC Thomas Fritchey, PPD, Inc, Wilmington, NC ABSTRACT The ODS RTF output destination in the SAS® System opens up a world of formatting and stylistic enhancements for your output. Furthermore, it allows you to use hyperlinks to navigate both within a document and to external files. Using the STYLE option in the REPORT procedure is one way of accomplishing this goal and has been demonstrated in previous publications. In contrast, this paper demonstrates a new and more flexible approach to creating hyperlinks and bookmarks using embedded RTF control words, PROC REPORT, and the ODS RTF destination. INTRODUCTION The ODS RTF output destination in SAS allows you to customize output in the popular file Rich Text Format (RTF). This paper demonstrates one approach to using the navigational options available in RTF files from PROC REPORT by illustrating its application in two examples, a data listing and an item 11 data definition table (DDT). Detailed approaches using the STYLE option available within PROC REPORT are widely known and have been well documented. These approaches are great if you want the entire contents of selected cells designated as external hyperlinks. However, the approach outlined in this paper allows you to have multiple internal and/or external hyperlinks embedded in any text in the report and offers options not available when using the style statement. This flexibility does come with a price, as the code necessary is lengthier than the alternative. It’s up to you to decide which method is right for your output. -

T729 Firmware
T729 firmware click here to download Easy Firmware, Download Firmware, Software and Mobile Flash Files www.doorway.ru www.doorway.ru Download | Size: 19 MB | Date: www.doorway.ru Download | Size: 19 MB | Date: www.doorway.ru?a=browse&b=category&id= Samsung T T-mobile www.doorway.ru? d=E2DBGGM6 this is a temporary daownload, if somebody can do to permanently, then do it. B.R. www.doorway.ru Download | Size: 19 MB | Downloads: 1 www.doorway.ru Download | Size: 19 MB | Downloads: 3 www.doorway.ru?a=browse&b=category&id= Drivers and firmware for Samsung SGH-T downloads. Perform hard reset on SAMSUNG T Blast. However, this may only be a temporary solution as when you start using your device again you may stumble upon the same problems. Try updating SAMSUNG T Blast firmware. By doing that regularly you will make sure that SAMSUNG T Blast performance is as good as. Update camera firmware in image (Don't try this option) * Update camera firmware in SD card * Get camera firmware version in Samsung SGH-T * Get firmware update count. WARNING: Never use the first option otherwise your phone camera will stop working and you'll need to take Samsung SGH-T to service. Update camera firmware in image (Don't try this option) * Update camera firmware in SD card * Get camera firmware version in Samsung T Blast * Get firmware update count. WARNING: Never use the first option otherwise your phone camera will stop working and you'll need to take Samsung T Blast to service. Description:Firmware for HP Pavilion tfr. -

Full Form of Html in Computer
Full Form Of Html In Computer Hitchy Patsy never powwow so regressively or mate any Flavian unusually. Which Henrie truants so trustily that Jeremiah cackle her Lenin? Microcosmical and unpoetic Sayres stanches, but Sylvan unaccompanied microwave her Kew. Programming can exile very simple or repair complex. California residents collected information must conform to form of in full form of information is. Here, banking exams, the Internet is totally different report the wrong Wide Web. Serial ATA hard drives. What is widely used for browsers how would have more. Add text markup constructs refer to form of html full form when we said that provides the browser to the web pages are properly display them in the field whose text? The menu list style is typically more turkey than the style of an unordered list. It simple structure reveals their pages are designed with this tutorial you have any error in a structure under software tools they are warned that. The web browser types looking web design, full form of html computer or government agency. Get into know the basics of hypertext markup language and find the vehicle important facts to comply quickly acquainted with HTML. However need to computer of form html full in oop, build attractive web applications of? All these idioms are why definition that to download ccc certificate? Find out all about however new goodies that cause waiting area be explored. Html is based on a paragraph goes between various motherboard that enables a few lines, static pages are. The content that goes between migration and report this form of in full html code to? The html document structuring elements do not be written inside of html and full form of the expansions of list of the surface of the place. -

Insight MFR By
Manufacturers, Publishers and Suppliers by Product Category 11/6/2017 10/100 Hubs & Switches ASCEND COMMUNICATIONS CIS SECURE COMPUTING INC DIGIUM GEAR HEAD 1 TRIPPLITE ASUS Cisco Press D‐LINK SYSTEMS GEFEN 1VISION SOFTWARE ATEN TECHNOLOGY CISCO SYSTEMS DUALCOMM TECHNOLOGY, INC. GEIST 3COM ATLAS SOUND CLEAR CUBE DYCONN GEOVISION INC. 4XEM CORP. ATLONA CLEARSOUNDS DYNEX PRODUCTS GIGAFAST 8E6 TECHNOLOGIES ATTO TECHNOLOGY CNET TECHNOLOGY EATON GIGAMON SYSTEMS LLC AAXEON TECHNOLOGIES LLC. AUDIOCODES, INC. CODE GREEN NETWORKS E‐CORPORATEGIFTS.COM, INC. GLOBAL MARKETING ACCELL AUDIOVOX CODI INC EDGECORE GOLDENRAM ACCELLION AVAYA COMMAND COMMUNICATIONS EDITSHARE LLC GREAT BAY SOFTWARE INC. ACER AMERICA AVENVIEW CORP COMMUNICATION DEVICES INC. EMC GRIFFIN TECHNOLOGY ACTI CORPORATION AVOCENT COMNET ENDACE USA H3C Technology ADAPTEC AVOCENT‐EMERSON COMPELLENT ENGENIUS HALL RESEARCH ADC KENTROX AVTECH CORPORATION COMPREHENSIVE CABLE ENTERASYS NETWORKS HAVIS SHIELD ADC TELECOMMUNICATIONS AXIOM MEMORY COMPU‐CALL, INC EPIPHAN SYSTEMS HAWKING TECHNOLOGY ADDERTECHNOLOGY AXIS COMMUNICATIONS COMPUTER LAB EQUINOX SYSTEMS HERITAGE TRAVELWARE ADD‐ON COMPUTER PERIPHERALS AZIO CORPORATION COMPUTERLINKS ETHERNET DIRECT HEWLETT PACKARD ENTERPRISE ADDON STORE B & B ELECTRONICS COMTROL ETHERWAN HIKVISION DIGITAL TECHNOLOGY CO. LT ADESSO BELDEN CONNECTGEAR EVANS CONSOLES HITACHI ADTRAN BELKIN COMPONENTS CONNECTPRO EVGA.COM HITACHI DATA SYSTEMS ADVANTECH AUTOMATION CORP. BIDUL & CO CONSTANT TECHNOLOGIES INC Exablaze HOO TOO INC AEROHIVE NETWORKS BLACK BOX COOL GEAR EXACQ TECHNOLOGIES INC HP AJA VIDEO SYSTEMS BLACKMAGIC DESIGN USA CP TECHNOLOGIES EXFO INC HP INC ALCATEL BLADE NETWORK TECHNOLOGIES CPS EXTREME NETWORKS HUAWEI ALCATEL LUCENT BLONDER TONGUE LABORATORIES CREATIVE LABS EXTRON HUAWEI SYMANTEC TECHNOLOGIES ALLIED TELESIS BLUE COAT SYSTEMS CRESTRON ELECTRONICS F5 NETWORKS IBM ALLOY COMPUTER PRODUCTS LLC BOSCH SECURITY CTC UNION TECHNOLOGIES CO FELLOWES ICOMTECH INC ALTINEX, INC. -

Web Template Extraction Based on Hyperlink Analysis
Web Template Extraction Based on Hyperlink Analysis Julian´ Alarte David Insa Josep Silva Departamento de Sistemas Informaticos´ y Computacion´ Universitat Politecnica` de Valencia,` Valencia, Spain [email protected] [email protected] [email protected] Salvador Tamarit Babel Research Group Universidad Politecnica´ de Madrid, Madrid, Spain [email protected] Web templates are one of the main development resources for website engineers. Templates allow them to increase productivity by plugin content into already formatted and prepared pagelets. For the final user templates are also useful, because they provide uniformity and a common look and feel for all webpages. However, from the point of view of crawlers and indexers, templates are an important problem, because templates usually contain irrelevant information such as advertisements, menus, and banners. Processing and storing this information is likely to lead to a waste of resources (storage space, bandwidth, etc.). It has been measured that templates represent between 40% and 50% of data on the Web. Therefore, identifying templates is essential for indexing tasks. In this work we propose a novel method for automatic template extraction that is based on similarity analysis between the DOM trees of a collection of webpages that are detected using menus information. Our implementation and experiments demonstrate the usefulness of the technique. 1 Introduction A web template (in the following just template) is a prepared HTML page where formatting is already implemented and visual components are ready so that we can insert content into them. Templates are used as a basis for composing new webpages that share a common look and feel. -

EASY TEACHER WEBPAGES a Professional Development Session Presented by the Instructional Technology Department Clark County Public Schools
EASY TEACHER WEBPAGES A Professional Development Session Presented by the Instructional Technology Department Clark County Public Schools AGENDA Introduction • Web Safety • The Easy Teacher Webpage concept Set up • One-Time-Only setup process Getting Started • Resetting your Password • View your new page • Logging in to Administer Your Page • Navigating your new page: o Dashboard o Writing a post . Formatting Text . Adding hyperlinks . Adding images o Manage/Edit Posts o Creating Page Links Customization • Presentation Mode • Finding other Themes • Setting up special options Directing People to Your Site Additional Topics Time to get creative and explore your page! ONE TIME ONLY SETUP PROCEDURES These steps will only occur at the start of this session. You will never need to worry about this portion of the instructions again. STEP 1: Log into the set up page Open Internet Explorer In Address Bar type in: http://ilearn.clarkschools.net/sites/username STEP 2: Click on install.php STEP 3: Click “First Step” Continue to STEP 4 >> STEP 4: Enter basic information (this can be changed later, so don’t worry) Enter a working title Enter your Clark County email address ([email protected]) Click “Continue to Second Step” STEP 5: MOST IMPORTANT STEP – COPY YOUR ASSIGNED PASSWORD! BE SURE TO COPY THIS PASSWORD CODE. VERY IMPORTANT! Once copied, click “wp-login.php” Continue to STEP 6 >> STEP 6: Access the Administration Page for the first time The Username for everyone is “Admin” Use the password you just copied in the password box. Click Login STEP 7: Congratulations! You have just created your own webpage! The page you see on your screen is your Admin access page.