Synchronous DRAM Architectures, Organizations, and Alternative Technologies
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Modeling System Signal Integrity Uncertainty Considerations
WHITE PAPER Intel® FPGA Modeling System Signal Integrity Uncertainty Considerations Authors Abstract Ravindra Gali This white paper describes signal integrity (SI) mechanisms that cause system-level High-Speed I/O Applications timing uncertainty and how these mechanisms are modeled in the Intel® Quartus® Engineering, Intel® Corporation Prime software Timing Analyzer to achieve timing closure for external memory interface designs. Zhi Wong By using the Intel Quartus Prime software to achieve timing closure for external High-Speed I/O Applications memory interfaces, a designer does not need to allocate a separate SI timing Engineering, Intel Corporation budget to account for simultaneous switching output (SSO), simultaneous Navid Azizi switching input (SSI), intersymbol interference (ISI), and board-level crosstalk for Software Engineeringr flip-chip device families such as Stratix® IV and Arria® II FPGAs for typical user Intel Corporation implementation of external memory interfaces following good board design practices. John Oh High-Speed I/O Applications Introduction Engineering, Intel Corporation The widening performance gap between FPGAs, microprocessors, and memory Arun VR devices, along with the growth of memory-intensive applications, are driving the Memory I/O Applications Engineering, need for faster memory technologies. This push to higher bandwidths has been Intel Corporation accompanied by an increase in the signal count and the signaling rates of FPGAs and memory devices. In order to attain faster bandwidths, device makers continue to reduce the supply voltage. Initially, industry-standard DIMMs operated at 5 V. However, due to improvements in DRAM storage density, the operating voltage was decreased to 3.3 V (SDR), then to 2.5V (DDR), 1.8 V (DDR2), 1.5 V (DDR3), and 1.35 V (DDR3) to allow the memory to run faster and consume less power. -
2GB DDR3 SDRAM 72Bit SO-DIMM
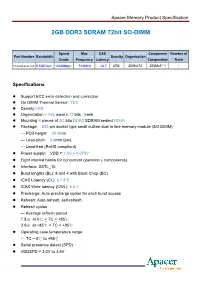
Apacer Memory Product Specification 2GB DDR3 SDRAM 72bit SO-DIMM Speed Max CAS Component Number of Part Number Bandwidth Density Organization Grade Frequency Latency Composition Rank 0C 78.A2GCB.AF10C 8.5GB/sec 1066Mbps 533MHz CL7 2GB 256Mx72 256Mx8 * 9 1 Specifications z Support ECC error detection and correction z On DIMM Thermal Sensor: YES z Density:2GB z Organization – 256 word x 72 bits, 1rank z Mounting 9 pieces of 2G bits DDR3 SDRAM sealed FBGA z Package: 204-pin socket type small outline dual in line memory module (SO-DIMM) --- PCB height: 30.0mm --- Lead pitch: 0.6mm (pin) --- Lead-free (RoHS compliant) z Power supply: VDD = 1.5V + 0.075V z Eight internal banks for concurrent operation ( components) z Interface: SSTL_15 z Burst lengths (BL): 8 and 4 with Burst Chop (BC) z /CAS Latency (CL): 6,7,8,9 z /CAS Write latency (CWL): 5,6,7 z Precharge: Auto precharge option for each burst access z Refresh: Auto-refresh, self-refresh z Refresh cycles --- Average refresh period 7.8㎲ at 0℃ < TC < +85℃ 3.9㎲ at +85℃ < TC < +95℃ z Operating case temperature range --- TC = 0℃ to +95℃ z Serial presence detect (SPD) z VDDSPD = 3.0V to 3.6V Apacer Memory Product Specification Features z Double-data-rate architecture; two data transfers per clock cycle. z The high-speed data transfer is realized by the 8 bits prefetch pipelined architecture. z Bi-directional differential data strobe (DQS and /DQS) is transmitted/received with data for capturing data at the receiver. z DQS is edge-aligned with data for READs; center aligned with data for WRITEs. -

Memory & Devices
Memory & Devices Memory • Random Access Memory (vs. Serial Access Memory) • Different flavors at different levels – Physical Makeup (CMOS, DRAM) – Low Level Architectures (FPM,EDO,BEDO,SDRAM, DDR) • Cache uses SRAM: Static Random Access Memory – No refresh (6 transistors/bit vs. 1 transistor • Main Memory is DRAM: Dynamic Random Access Memory – Dynamic since needs to be refreshed periodically (1% time) – Addresses divided into 2 halves (Memory as a 2D matrix): • RAS or Row Access Strobe • CAS or Column Access Strobe Random-Access Memory (RAM) Key features – RAM is packaged as a chip. – Basic storage unit is a cell (one bit per cell). – Multiple RAM chips form a memory. Static RAM (SRAM) – Each cell stores bit with a six-transistor circuit. – Retains value indefinitely, as long as it is kept powered. – Relatively insensitive to disturbances such as electrical noise. – Faster and more expensive than DRAM. Dynamic RAM (DRAM) – Each cell stores bit with a capacitor and transistor. – Value must be refreshed every 10-100 ms. – Sensitive to disturbances. – Slower and cheaper than SRAM. Semiconductor Memory Types Static RAM • Bits stored in transistor “latches” à no capacitors! – no charge leak, no refresh needed • Pro: no refresh circuits, faster • Con: more complex construction, larger per bit more expensive transistors “switch” faster than capacitors charge ! • Cache Static RAM Structure 1 “NOT ” 1 0 six transistors per bit 1 0 (“flip flop”) 0 1 0/1 = example 0 Static RAM Operation • Transistor arrangement (flip flop) has 2 stable logic states • Write 1. signal bit line: High à 1 Low à 0 2. address line active à “switch” flip flop to stable state matching bit line • Read no need 1. -

Different Types of RAM RAM RAM Stands for Random Access Memory. It Is Place Where Computer Stores Its Operating System. Applicat
Different types of RAM RAM RAM stands for Random Access Memory. It is place where computer stores its Operating System. Application Program and current data. when you refer to computer memory they mostly it mean RAM. The two main forms of modern RAM are Static RAM (SRAM) and Dynamic RAM (DRAM). DRAM memories (Dynamic Random Access Module), which are inexpensive . They are used essentially for the computer's main memory SRAM memories(Static Random Access Module), which are fast and costly. SRAM memories are used in particular for the processer's cache memory. Early memories existed in the form of chips called DIP (Dual Inline Package). Nowaday's memories generally exist in the form of modules, which are cards that can be plugged into connectors for this purpose. They are generally three types of RAM module they are 1. DIP 2. SIMM 3. DIMM 4. SDRAM 1. DIP(Dual In Line Package) Older computer systems used DIP memory directely, either soldering it to the motherboard or placing it in sockets that had been soldered to the motherboard. Most memory chips are packaged into small plastic or ceramic packages called dual inline packages or DIPs . A DIP is a rectangular package with rows of pins running along its two longer edges. These are the small black boxes you see on SIMMs, DIMMs or other larger packaging styles. However , this arrangment caused many problems. Chips inserted into sockets suffered reliability problems as the chips would (over time) tend to work their way out of the sockets. 2. SIMM A SIMM, or single in-line memory module, is a type of memory module containing random access memory used in computers from the early 1980s to the late 1990s . -

Product Guide SAMSUNG ELECTRONICS RESERVES the RIGHT to CHANGE PRODUCTS, INFORMATION and SPECIFICATIONS WITHOUT NOTICE
May. 2018 DDR4 SDRAM Memory Product Guide SAMSUNG ELECTRONICS RESERVES THE RIGHT TO CHANGE PRODUCTS, INFORMATION AND SPECIFICATIONS WITHOUT NOTICE. Products and specifications discussed herein are for reference purposes only. All information discussed herein is provided on an "AS IS" basis, without warranties of any kind. This document and all information discussed herein remain the sole and exclusive property of Samsung Electronics. No license of any patent, copyright, mask work, trademark or any other intellectual property right is granted by one party to the other party under this document, by implication, estoppel or other- wise. Samsung products are not intended for use in life support, critical care, medical, safety equipment, or similar applications where product failure could result in loss of life or personal or physical harm, or any military or defense application, or any governmental procurement to which special terms or provisions may apply. For updates or additional information about Samsung products, contact your nearest Samsung office. All brand names, trademarks and registered trademarks belong to their respective owners. © 2018 Samsung Electronics Co., Ltd. All rights reserved. - 1 - May. 2018 Product Guide DDR4 SDRAM Memory 1. DDR4 SDRAM MEMORY ORDERING INFORMATION 1 2 3 4 5 6 7 8 9 10 11 K 4 A X X X X X X X - X X X X SAMSUNG Memory Speed DRAM Temp & Power DRAM Type Package Type Density Revision Bit Organization Interface (VDD, VDDQ) # of Internal Banks 1. SAMSUNG Memory : K 8. Revision M: 1st Gen. A: 2nd Gen. 2. DRAM : 4 B: 3rd Gen. C: 4th Gen. D: 5th Gen. -

DDR and DDR2 SDRAM Controller Compiler User Guide
DDR and DDR2 SDRAM Controller Compiler User Guide 101 Innovation Drive Software Version: 9.0 San Jose, CA 95134 Document Date: March 2009 www.altera.com Copyright © 2009 Altera Corporation. All rights reserved. Altera, The Programmable Solutions Company, the stylized Altera logo, specific device designations, and all other words and logos that are identified as trademarks and/or service marks are, unless noted otherwise, the trademarks and service marks of Altera Corporation in the U.S. and other countries. All other product or service names are the property of their respective holders. Altera products are protected under numerous U.S. and foreign patents and pending ap- plications, maskwork rights, and copyrights. Altera warrants performance of its semiconductor products to current specifications in accordance with Altera's standard warranty, but reserves the right to make changes to any products and services at any time without notice. Altera assumes no responsibility or liability arising out of the application or use of any information, product, or service described herein except as expressly agreed to in writing by Altera Corporation. Altera customers are advised to obtain the latest version of device specifications before relying on any published information and before placing orders for products or services. UG-DDRSDRAM-10.0 Contents Chapter 1. About This Compiler Release Information . 1–1 Device Family Support . 1–1 Features . 1–2 General Description . 1–2 Performance and Resource Utilization . 1–4 Installation and Licensing . 1–5 OpenCore Plus Evaluation . 1–6 Chapter 2. Getting Started Design Flow . 2–1 SOPC Builder Design Flow . 2–1 DDR & DDR2 SDRAM Controller Walkthrough . -

AXP Internal 2-Apr-20 1
2-Apr-20 AXP Internal 1 2-Apr-20 AXP Internal 2 2-Apr-20 AXP Internal 3 2-Apr-20 AXP Internal 4 2-Apr-20 AXP Internal 5 2-Apr-20 AXP Internal 6 Class 6 Subject: Computer Science Title of the Book: IT Planet Petabyte Chapter 2: Computer Memory GENERAL INSTRUCTIONS: • Exercises to be written in the book. • Assignment questions to be done in ruled sheets. • You Tube link is for the explanation of Primary and Secondary Memory. YouTube Link: ➢ https://youtu.be/aOgvgHiazQA INTRODUCTION: ➢ Computer can store a large amount of data safely in their memory for future use. ➢ A computer’s memory is measured either in Bits or Bytes. ➢ The memory of a computer is divided into two categories: Primary Memory, Secondary Memory. ➢ There are two types of Primary Memory: ROM and RAM. ➢ Cache Memory is used to store program and instructions that are frequently used. EXPLANATION: Computer Memory: Memory plays a very important role in a computer. It is the basic unit where data and instructions are stored temporarily. Memory usually consists of one or more chips on the mother board, or you can say it consists of electronic components that store instructions waiting to be executed by the processor, data needed by those instructions, and the results of processing the data. Memory Units: Computer memory is measured in bits and bytes. A bit is the smallest unit of information that a computer can process and store. A group of 4 bits is known as nibble, and a group of 8 bits is called byte. -

Dual-DIMM DDR2 and DDR3 SDRAM Board Design Guidelines, External
5. Dual-DIMM DDR2 and DDR3 SDRAM Board Design Guidelines June 2012 EMI_DG_005-4.1 EMI_DG_005-4.1 This chapter describes guidelines for implementing dual unbuffered DIMM (UDIMM) DDR2 and DDR3 SDRAM interfaces. This chapter discusses the impact on signal integrity of the data signal with the following conditions in a dual-DIMM configuration: ■ Populating just one slot versus populating both slots ■ Populating slot 1 versus slot 2 when only one DIMM is used ■ On-die termination (ODT) setting of 75 Ω versus an ODT setting of 150 Ω f For detailed information about a single-DIMM DDR2 SDRAM interface, refer to the DDR2 and DDR3 SDRAM Board Design Guidelines chapter. DDR2 SDRAM This section describes guidelines for implementing a dual slot unbuffered DDR2 SDRAM interface, operating at up to 400-MHz and 800-Mbps data rates. Figure 5–1 shows a typical DQS, DQ, and DM signal topology for a dual-DIMM interface configuration using the ODT feature of the DDR2 SDRAM components. Figure 5–1. Dual-DIMM DDR2 SDRAM Interface Configuration (1) VTT Ω RT = 54 DDR2 SDRAM DIMMs (Receiver) Board Trace FPGA Slot 1 Slot 2 (Driver) Board Trace Board Trace Note to Figure 5–1: (1) The parallel termination resistor RT = 54 Ω to VTT at the FPGA end of the line is optional for devices that support dynamic on-chip termination (OCT). © 2012 Altera Corporation. All rights reserved. ALTERA, ARRIA, CYCLONE, HARDCOPY, MAX, MEGACORE, NIOS, QUARTUS and STRATIX words and logos are trademarks of Altera Corporation and registered in the U.S. Patent and Trademark Office and in other countries. -

Solving High-Speed Memory Interface Challenges with Low-Cost Fpgas
SOLVING HIGH-SPEED MEMORY INTERFACE CHALLENGES WITH LOW-COST FPGAS A Lattice Semiconductor White Paper May 2005 Lattice Semiconductor 5555 Northeast Moore Ct. Hillsboro, Oregon 97124 USA Telephone: (503) 268-8000 www.latticesemi.com Introduction Memory devices are ubiquitous in today’s communications systems. As system bandwidths continue to increase into the multi-gigabit range, memory technologies have been optimized for higher density and performance. In turn, memory interfaces for these new technologies pose stiff challenges for designers. Traditionally, memory controllers were embedded in processors or as ASIC macrocells in SoCs. With shorter time-to-market requirements, designers are turning to programmable logic devices such as FPGAs to manage memory interfaces. Until recently, only a few FPGAs supported the building blocks to interface reliably to high-speed, next generation devices, and typically these FPGAs were high-end, expensive devices. However, a new generation of low-cost FPGAs has emerged, providing the building blocks, high-speed FPGA fabric, clock management resources and the I/O structures needed to implement next generation DDR2, QDR2 and RLDRAM memory controllers. Memory Applications Memory devices are an integral part of a variety of systems. However, different applications have different memory requirements. For networking infrastructure applications, the memory devices required are typically high-density, high-performance, high-bandwidth memory devices with a high degree of reliability. In wireless applications, low-power memory is important, especially for handset and mobile devices, while high-performance is important for base-station applications. Broadband access applications typically require memory devices in which there is a fine balance between cost and performance. -

Semiconductor Memories
Semiconductor Memories Prof. MacDonald Types of Memories! l" Volatile Memories –" require power supply to retain information –" dynamic memories l" use charge to store information and require refreshing –" static memories l" use feedback (latch) to store information – no refresh required l" Non-Volatile Memories –" ROM (Mask) –" EEPROM –" FLASH – NAND or NOR –" MRAM Memory Hierarchy! 100pS RF 100’s of bytes L1 1nS SRAM 10’s of Kbytes 10nS L2 100’s of Kbytes SRAM L3 100’s of 100nS DRAM Mbytes 1us Disks / Flash Gbytes Memory Hierarchy! l" Large memories are slow l" Fast memories are small l" Memory hierarchy gives us illusion of large memory space with speed of small memory. –" temporal locality –" spatial locality Register Files ! l" Fastest and most robust memory array l" Largest bit cell size l" Basically an array of large latches l" No sense amps – bits provide full rail data out l" Often multi-ported (i.e. 8 read ports, 2 write ports) l" Often used with ALUs in the CPU as source/destination l" Typically less than 10,000 bits –" 32 32-bit fixed point registers –" 32 60-bit floating point registers SRAM! l" Same process as logic so often combined on one die l" Smaller bit cell than register file – more dense but slower l" Uses sense amp to detect small bit cell output l" Fastest for reads and writes after register file l" Large per bit area costs –" six transistors (single port), eight transistors (dual port) l" L1 and L2 Cache on CPU is always SRAM l" On-chip Buffers – (Ethernet buffer, LCD buffer) l" Typical sizes 16k by 32 Static Memory -

Access Order and Effective Bandwidth for Streams on a Direct Rambus Memory Sung I
Access Order and Effective Bandwidth for Streams on a Direct Rambus Memory Sung I. Hong, Sally A. McKee†, Maximo H. Salinas, Robert H. Klenke, James H. Aylor, Wm. A. Wulf Dept. of Electrical and Computer Engineering †Dept. of Computer Science University of Virginia University of Utah Charlottesville, VA 22903 Salt Lake City, Utah 84112 Abstract current DRAM page forces a new page to be accessed. The Processor speeds are increasing rapidly, and memory speeds are overhead time required to do this makes servicing such a request not keeping up. Streaming computations (such as multi-media or significantly slower than one that hits the current page. The order of scientific applications) are among those whose performance is requests affects the performance of all such components. Access most limited by the memory bottleneck. Rambus hopes to bridge the order also affects bus utilization and how well the available processor/memory performance gap with a recently introduced parallelism can be exploited in memories with multiple banks. DRAM that can deliver up to 1.6Gbytes/sec. We analyze the These three observations — the inefficiency of traditional, performance of these interesting new memory devices on the inner dynamic caching for streaming computations; the high advertised loops of streaming computations, both for traditional memory bandwidth of Direct Rambus DRAMs; and the order-sensitive controllers that treat all DRAM transactions as random cacheline performance of modern DRAMs — motivated our investigation of accesses, and for controllers augmented with streaming hardware. a hardware streaming mechanism that dynamically reorders For our benchmarks, we find that accessing unit-stride streams in memory accesses in a Rambus-based memory system. -

AN-371, Interfacing RC32438 with DDR SDRAM Memory
Interfacing the RC32438 with Application Note DDR SDRAM Memory AN-371 By Kasi Chopperla and Harold Gomard Notes Revision History July 3, 2003: Initial publication. October 23, 2003: Added DDR Loading section. October 29, 2003: Added Passive DDR Termination Scheme for Lightly Loaded Systems section. Introduction The RC32438 is a high performance, general-purpose, integrated processor that incorporates a 32-bit CPU core with a number of peripherals including: – A memory controller supporting DDR SDRAM – A separate memory/peripheral controller interfacing to EPROM, flash and I/O peripherals – Two Ethernet MACs – 32-bit v.2.2 compatible PCI interface – Other generic modules, such as two serial ports, I2C, SPI, interrupt controller, GPIO, and DMA. Internally, the RC32438 features a dual bus system. The CPU bus interfaces directly to the memory controller over a 32-bit bus running at CPU pipeline speed. Since it is not possible to run an external bus at the speed of the CPU, the only way to provide data fast enough to keep the CPU from starving is to use either a wider DRAM or a double data rate DRAM. As the memory technology used on PC motherboards transitions from SDRAM to DDR, the steep ramp- up in the volume of DDR memory being shipped is driving pricing to the point where DDR-based memory subsystems are primed to drop below those of traditional SDRAM modules. Anticipating this, IDT opted to incorporate a double data rate DRAM interface on its RC32438 integrated processor. DDR memory requires a VDD/2 reference voltage and combination series and parallel terminations that SDRAM does not have.