Impact of Physical Low Power Techniques in a RISC-V Processor
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Prostep Ivip CPO Statement Template
CPO Statement of Mentor Graphics For Questa SIM Date: 17 June, 2015 CPO Statement of Mentor Graphics Following the prerequisites of ProSTEP iViP’s Code of PLM Openness (CPO) IT vendors shall determine and provide a list of their relevant products and the degree of fulfillment as a “CPO Statement” (cf. CPO Chapter 2.8). This CPO Statement refers to: Product Name Questa SIM Product Version Version 10 Contact Ellie Burns [email protected] This CPO Statement was created and published by Mentor Graphics in form of a self-assessment with regard to the CPO. Publication Date of this CPO Statement: 17 June 2015 Content 1 Executive Summary ______________________________________________________________________________ 2 2 Details of Self-Assessment ________________________________________________________________________ 3 2.1 CPO Chapter 2.1: Interoperability ________________________________________________________________ 3 2.2 CPO Chapter 2.2: Infrastructure _________________________________________________________________ 4 2.3 CPO Chapter 2.5: Standards ____________________________________________________________________ 4 2.4 CPO Chapter 2.6: Architecture __________________________________________________________________ 5 2.5 CPO Chapter 2.7: Partnership ___________________________________________________________________ 6 2.5.1 Data Generated by Users ___________________________________________________________________ 6 2.5.2 Partnership Models _______________________________________________________________________ 6 2.5.3 Support of -

Power Reduction of a CMOS High-Speed Interface Using Power Gating
FACULDADE DE ENGENHARIA DA UNIVERSIDADE DO PORTO Power reduction of a CMOS high-speed interface using power gating Luís Miguel Granja Gomes FOR JURY EVALUATION Mestrado Integrado em Engenharia Eletrotécnica e de Computadores FEUP Supervisor: Prof. João Canas Ferreira Synopsys Supervisor: Engineer Hélder Araújo June 25, 2013 c Luís Gomes, 2013 Resumo A indústria de circuitos VLSI sofreu uma série de revoluções na forma como os chips eletrónicos são projetados. Começou com o uso de linguagens de descrição de hardware e de avançadas ferramentas de trabalho, com o objetivo de diminuir os tempos de projeto e de produção, ao mesmo tempo que circuitos mais rápidos e pequenos eram construídos. A produção de dispos- itivos eletrónicos aumentou significativamente, de tal modo que, hoje, são usados biliões todos os dias. Atualmente, o maior desafio não é só projetar circuitos integrados mais pequenos e rápidos, mas manter esses acréscimos de velocidade e diminuição de tamanho, reduzindo simultaneamente o consumo de potência. Com a diminuição do tamanho da tecnologia e o uso de transístores com tensões de threshold cada vez mais reduzidas, o consumo de potência dinâmica e estática atingiu níveis insuportáveis. Chegou-se a um ponto em que, tanto económica como ambientalmente fa- lando, é obrigatório projetar para reduzir a potência. Synopsys, uma das maiores empresas desta indústria, apresentou um projeto com o objetivo de implementar Power Gating numa das suas interfaces de alta velocidade, como técnica mais eficaz na redução da potência estática. Esta dissertação apresenta as adaptações necessárias para a implementação de Power Gating us- ando ferramentas Synopsys, aplicando-as a um caso de estudo complexo. -

Powerpoint Template
Accellera Overview February 27, 2017 Lu Dai | Accellera Chairman Welcome Agenda . About Accellera . Current news . Technical activities . IEEE collaboration 2 © 2017 Accellera Systems Initiative, Inc. February 2017 Accellera Systems Initiative Our Mission To provide a platform in which the electronics industry can collaborate to innovate and deliver global standards that improve design and verification productivity for electronics products. 3 © 2017 Accellera Systems Initiative, Inc. February 2017 Broad Industry Support Corporate Members 4 © 2017 Accellera Systems Initiative, Inc. February 2017 Broad Industry Support Associate Members 5 © 2017 Accellera Systems Initiative, Inc. February 2017 Global Presence SystemC Evolution Day DVCon Europe DVCon U.S. SystemC Japan Design Automation Conference DVCon China Verification & ESL Forum DVCon India 6 © 2017 Accellera Systems Initiative, Inc. February 2017 Agenda . About Accellera . Current news . Technical activities . IEEE collaboration 7 © 2017 Accellera Systems Initiative, Inc. February 2017 Accellera News . Standards - IEEE Approves UVM 1.2 as IEEE 1800.2-2017 - Accellera relicenses SystemC reference implementation under Apache 2.0 . Outreach - First DVCon China to be held April 19, 2017 - Get IEEE free standards program extended 10 years/10 standards . Awards - Thomas Alsop receives 2017 Technical Excellence Award for his leadership of the UVM Working Group - Shrenik Mehta receives 2016 Accellera Leadership Award for his role as Accellera chair from 2005-2010 8 © 2017 Accellera Systems Initiative, Inc. February 2017 DVCon – Global Presence 29th Annual DVCon U.S. 4th Annual DVCon Europe www.dvcon-us.org 4th Annual DVCon India www.dvcon-europe.org 1st DVCon China www.dvcon-india.org www.dvcon-china.org 9 © 2017 Accellera Systems Initiative, Inc. -

IEEE-SA and How Standardization Can Enhance Your Business and Career Case Study in Electronic Design Automation
IEEE-SA and How Standardization Can Enhance Your Business and Career Case Study in Electronic Design Automation Yatin Trivedi Member, Board of Governors, IEEE-SA Member, Standards Board, IEEE-SA Member, Education Activities Board, IEEE Director of Standards and Interoperability, Synopsys Vienna, March 2015 Contents Standards and EDA Impact of EDA standards Case Study: Successful Standards Standards as Innovation Platform Standards, Business and Career © 2015 IEEE Standards Association Vienna, March 2015 2 1 IEEE Technical Societies/Councils Top-class technical expert base . Aerospace & Electronic Systems . Instrumentation & Measurement . Antennas & Propagation . Lasers & Electro-Optics . Broadcast Technology . Magnetics . Circuits & Systems . Microwave Theory & Techniques . Communications . Nanotechnology Council . Components, Packaging, & Manufacturing . Nuclear & Plasma Sciences Technology . Oceanic Engineering Computer . Power Electronics Computational Intelligence . Power & Energy Consumer Electronics . Product Safety Engineering Control Systems . Professional Communication Council on Electronic Design Automation . Reliability Council on Superconductivity . Robotics & Automation Dielectrics & Electrical Insulation . Sensors Council Education . Signal Processing Electromagnetic Compatibility . Social Implications of Technology Electron Devices . Solid-State Circuits . Engineering in Medicine & Biology . Systems Council . Geosciences & Remote Sensing . Systems, Man, & Cybernetics . Industrial Electronics . Technology Management Council -

Volume 10, Issue 1 — March 2014
A PUBLICATION OF MENTOR GRAPHICS — VOLUME 10, ISSUE 1 — MARCH 2014 WHAT’S ON Whether It’s Fixing a Boiler, or Getting THE HORIZON? to Tapeout, It’s Productivity that Matters. By Tom Fitzpatrick, Editor and Verification Technologist The Little Things that Can Make Verification Easier Make verification more As I write this, we’re experiencing yet another winter storm here in New England. It started this productive by keeping your focus on verifying your design’s functionality...page 4 morning, and the timing was fortuitous since my wife had scheduled a maintenance visit by the oil company to fix a minor problem with the pipes before it really started snowing heavily. While the kids were sleeping in due to school being cancelled, the plumber worked in our basement to make The advantages of using the Unified Power Format (UPF) sure everything was working well. It turned out that he had to replace the water feeder valve on the standard with Questa See how Questa was able to model the behaviors boiler, which was preventing enough water from circulating in the heating pipes. Aside from being from their UPF specification...page 8 inefficient, this also caused the pipes to make a gurgling sound, which was the key symptom that led to the service call in the first place. As I see the snow piling Pre-silicon validation of IEEE 1149.1-2013 based Silicon up outside my window (6-8 inches and counting), it’s easy to Instruments Verify the functionality picture the disaster that this could have become had we not of the actual chip through what Intellitech calls “silicon instruments.”...page 13 identified the problem early and gotten it fixed. -

Validation of Low Power Format Using Standard Cell Library Santosh K
Validation of Low Power Format using Standard Cell Library Santosh K. Anchatgeri1, Padmanaban K.2, Sachin Bapat3 1- M.Sc. [Engg.] Student, 2-Assistant Professor, Department of Electronics and Electrical Engineering, M. S. Ramaiah School of Advanced Studies, Bangalore- 560 058 3- Staff Manager, VLSI System Design Centre, QUALCOMM, Bangalore. Abstract Increased system complexity has led to the substitution of the traditional bottom-up design flow by systematic hierarchical design flow. With decreasing channel lengths, few key problems such as timing closure, design sign-off, routing complexity, and power dissipation arise in the design flows. Specifically, minimizing power dissipation is critical in several high-end processors. This research aims at optimizing the design flow for power using the unified power format (UPF). The low power reduction techniques enforced in this research are multivoltage, multi-threshold voltage (Vth), and power gating with state retention. A top-down digital design flow for a flash based mixed signal microcontroller has been implemented with and without UPF synthesis flow for 45nm technology. The UPF synthesis is implemented with two voltages, 1.2V and 0.9V (Multi- VDD). Area, power and timing metrics are analyzed for the flows developed. Power savings of about 20 % are achieved in the design flow with 'multi-threshold' power technique compared to that of the design flow with no low power techniques employed. Similarly, 31 % power savings are achieved in the design flow with the UPF implemented when compared to that of the design flow with 'multi-threshold' power technique employed. Thus, a cumulative power savings of 51% has been achieved in a complete power efficient design flow (UPF) compared to that of the generic top-down standard flow with no power saving techniques employed. -

An Effective and Efficient Methodology for Soc Power Management Through UPF
An effective and efficient methodology for SoC power management through UPF By Renduchinthala Anusha Under the Supervision of Dr. Sujay Deb Mr. Akhilesh Chandra Mishra Mr. Rangarajan Ramanujam Indraprastha Institute of Information Technology Delhi June, 2016 ©Indraprastha Institute of Information Technology (IIITD), New Delhi 2016 An effective and efficient methodology for SoC power management through UPF By Renduchinthala Anusha Submitted in partial fulfilment of the requirements for the degree of Master of Technology in Electronics & Communication Engineering with specialization in VLSI & Embedded Systems To Indraprastha Institute of Information Technology Delhi June, 2016 Abstract With technology scaling and increase of chip complexity, power consumption of chip has been rising and its power architecture is getting complicated. Many power management techniques like power gating, multi-voltage, multi-threshold are applied to reduce power dissipation of devices. UPF is an IEEE 1801 standard format to describe the power architecture, also called as power intent, including power network connectivity and power reduction methods. It enables verification of power intent at early phases of the design cycle. The UPF developed should be consistent with the design at all stages of the design cycle and it should be updated according to the modifications made in the design. In conventional UPF flow through design cycle, few practical challenges are faced. Many bugs are not detected at earlier phases which might lead to the wrong implementation of power intent. In addition, parallel development of power intent for complex designs, limitations of UPF standard to describe few power intent components effectively and time- consuming conventional UPF flow hinder efficient UPF development and management. -
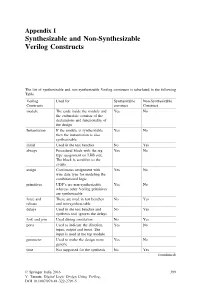
Non-Synthesizable Verilog Constructs
Appendix I Synthesizable and Non-Synthesizable Verilog Constructs The list of synthesizable and non-synthesizable Verilog constructs is tabu-lated in the following Table Verilog Used for Synthesizable Non-Synthesizable Constructs construct Construct module The code inside the module and Yes No the endmodule consists of the declarations and functionality of the design Instantiation If the module is synthesizable Yes No then the instantiation is also synthesizable initial Used in the test benches No Yes always Procedural block with the reg Yes No type assignment on LHS side. The block is sensitive to the events assign Continuous assignment with Yes No wire data type for modeling the combinational logic primitives UDP’s are non-synthesizable Yes No whereas other Verilog primitives are synthesizable force and These are used in test benches No Yes release and non-synthesizable delays Used in the test benches and No Yes synthesis tool ignores the delays fork and join Used during simulation No Yes ports Used to indicate the direction, Yes No input, output and inout. The input is used at the top module parameter Used to make the design more Yes No generic time Not supported for the synthesis No Yes (continued) © Springer India 2016 399 V. Taraate, Digital Logic Design Using Verilog, DOI 10.1007/978-81-322-2791-5 400 Appendix I: Synthesizable and Non-Synthesizable Verilog Constructs (continued) real Not supported for synthesis No Yes functions and Both are synthesizable. Provided Yes No task that the task does not have the timing constructs loop The for loop is synthesizable and Yes No used for the multiple iterations. -

VLSI Design of Configurable Low-Power Coarse-Grained Array
CORE Metadata, citation and similar papers at core.ac.uk Provided by Repositório Aberto da Universidade do Porto FACULDADE DE ENGENHARIA DA UNIVERSIDADE DO PORTO VLSI design of configurable low-power Coarse-Grained Array Architectures Diogo Alexandre Ribeiro de Sousa Mestrado Integrado em Engenharia Eletrotécnica e de Computadores Advisor: Professor Doutor João Paulo de Castro Canas Ferreira July 13, 2017 c Diogo Sousa, 2017 Abstract Coarse Grained Reconfigurable Arrays have gained importance in the field of accelerators. Several types of architectures have been proposed in the literature mainly targeting applications in the multimedia field. This document aims to contribute to the application of CGRAs in different areas by targeting low-power architectures for biomedical signal processing. The objective is to design a low power architecture which may be placed in a small battery-operated portable device. To do so, a look is taken into the different types of power consumption in a chip giving special attention to static power consumption. To produce a chip EDA (Electronic Design Automation) tools are used. These tools impose a considerable time overhead which delays the project. The purpose of the design flow is to ease the process of taking a CGRA architecture to tape-out in addition to save a considerable amount of time spent dealing with the aforementioned tools. The proposed design flow is capable of transforming a HDL description of a CGRA in a physical design while applying low-power methodologies such as the insertion of power domains along with power-gating capabilities which will deal with the static power consumption previously mentioned. -

An Electronic System Level Modeling Approach for the Design and Verification of Low-Power Systems-On Chip Ons Mbarek
An electronic system level modeling approach for the design and verification of low-power systems-on chip Ons Mbarek To cite this version: Ons Mbarek. An electronic system level modeling approach for the design and verification of low- power systems-on chip. Other [cs.OH]. Université Nice Sophia Antipolis, 2013. English. NNT : 2013NICE4023. tel-00837662v2 HAL Id: tel-00837662 https://tel.archives-ouvertes.fr/tel-00837662v2 Submitted on 18 Nov 2013 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. UNIVERSITE DE NICE-SOPHIA ANTIPOLIS ECOLE DOCTORALE STIC SCIENCES ET TECHNOLOGIES DE L’INFORMATION ET DE LA COMMUNICATION T H E S E pour l’obtention du grade de Docteur en Sciences de l’Université de Nice-Sophia Antipolis Mention Informatique présentée et soutenue publiquement par Ons MBAREK Une Approche de Modélisation au Niveau Système pour la Conception et la Vérification de Systèmes sur Puce à Faible Consommation An Electronic System Level Modeling Approach for the Design and Verification of Low-Power Systems-on-Chip Thèse dirigée par Michel AUGUIN Laboratoire LEAT, Université de Nice-Sophia Antipolis –CNRS, Sophia Antipolis soutenue le 29/05/2013 Jury : M. -

Digital Design of a Forward Error Correction System for IEEE 802.15.7
Mateus Gonçalves Silva Digital Design of a Forward Error Correction System for IEEE 802.15.7 Belo Horizonte 2020 Mateus Gonçalves Silva Digital Design of a Forward Error Correction System for IEEE 802.15.7 Dissertation submitted to the Graduate Pro- gram in Electrical Engineering at Universi- dade Federal de Minas Gerais, in partial ful- fillment of the requirements for the degree of Master in Electrical Engineering. Supervisor: Prof. Dr. Ricardo de Oliveira Duarte Belo Horizonte 2020 Silva, Mateus Gonçalves. S586d Digital design of a forward error correction system for IEEE 802.15.7 [recurso eletrônico] / Mateus Gonçalves Silva. – 2020. 1 recurso online (149 f. : il., color.) : pdf. Orientador: Ricardo de Oliveira Duarte. Dissertação (mestrado) Universidade Federal de Minas Gerais, Escola de Engenharia. Anexos: f. 127-149. Bibliografia: f. 121-126. Exigências do sistema: Adobe Acrobat Reader. 1. Engenharia elétrica - Teses. 2. Sistemas digitais - Teses. 3. Propriedade intelectual - Teses. I. Duarte, Ricardo de Oliveira. II. Universidade Federal de Minas Gerais. Escola de Engenharia. III. Título. CDU: 621.3(043) Ficha catalográfica: Biblioteca Profº Mário Werneck, Escola de Engenharia da UFMG. Agradecimentos Esta dissertação de mestrado é um resultado de um processo de formação acadêmica e cidadã fornecido pela Universidade Federal de Minas Gerais (UFMG), iniciado nos tempos de graduação. Por isso sou grato à UFMG pelo suporte dado durante esses anos e aos seus membros que acreditam em um ensino público, de qualidade e inclusivo. Em especial, agradeço ao Prof. Dr. Ricardo de Oliveira Duarte, que me acompanhou durante a maior parte deste processo como professor, orientador e amigo. Também agradeço aos alunos de iniciação científica Elisa Santos Bacelar e Gabriel Ricardo Thomaz de Araújo pelo esforço e dedicação empenhados na pesquisa e pela contribuição fundamental para este trabalho. -
PESL: System-Level Estimation of Power-Management Effect on Dynamic Energy Consumption
electronics Article PESL: System-Level Estimation of Power-Management Effect on Dynamic Energy Consumption Jaroslav Erdelyi, Dominik Macko * and Katarina Jelemenska Faculty of Informatics and Information Technologies, Slovak University of Technology in Bratislava, Ilkoviˇcova2, 84216 Bratislava, Slovakia; [email protected] (J.E.); [email protected] (K.J.) * Correspondence: [email protected] Received: 28 July 2020; Accepted: 13 August 2020; Published: 15 August 2020 Abstract: Power estimation is one of the key aspects that can help designers create digital circuits more effectively. If a designer is able to estimate circuit parameters during the early stages of development, correct decisions can be made that can significantly shorten the design time. The early design stages are represented by modeling at the system level of abstraction. However, existing system-level power/energy estimation methods are either too complicated, or they do not consider power management when estimating power consumption, meaning they are inaccurate. Therefore, in this paper we propose a method for a more accurate system-level estimation of the dynamic energy consumption by considering the impact of power management. The SystemC description of a power-managed system and the simulation results (in the form of the value change dump (VCD)) are inputs to the estimation method. The proposed method is based on an activity profile using the modified Hamming distance computation. The method is especially useful for the exploration of alternative power-management strategies, and it helps the designer to select the most efficient strategy. Keywords: digital system; energy estimation; low power; power management; system level 1. Introduction When designing a new Internet of Things (IoT) system, we need to consider power consumption from the beginning of the design process, especially when designing IoT end nodes with a limited amount of available energy, such as in battery-powered or energy harvesting applications (e.g., [1,2]).