Automatic Speech Recognition (ASR) System for Isolated Marathi Words: Using HTK
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Communalization and Disintegration of Urdu in Anita Desai’S in Custody 1
The Communalization and Disintegration of Urdu in Anita Desai’s In Custody 1 Introduction T of Urdu in India is an extremely layered one which needs to be examined historically, politically and ideologically in order to grasp the various forces which have shaped its current perception as a sectarian language adopted by Indian Muslims, marking their separation from the national collectivity. In this article I wish to explore these themes through the lens of literature, specifically an Indian English novel about Urdu entitled In Custody by Anita Desai. Writing in the early s, Aijaz Ahmad was of the opinion that the teaching of English literature has cre- ated a body of English-speaking Indians who represent “the only” over- arching national community with a common language, able to imagine themselves across the disparate nation as a “national literary intelligentsia” with “a shared body of knowledge, shared presumptions and a shared knowledge of mutual exchange” (, ).2 Arguably both Desai and Ahmad belong to this “intelligentsia” through the postcolonial secular English connection, but equally they are implicated in the discursive structures of cultural hegemony in civil society (Viswanathan , –; Rajan , –). However, it is not my intention to re-inscribe an authentic myth of origin about Indianness through linguistic associations, 1An earlier version of this essay was first presented as a paper at the Minori- ties, Education and Language in st Century Indian Democracy—The Case of Urdu with Special Reference to Dr. Zakir Husain, Late President of India Con- ference held in Delhi, February . 2See also chapter “‘Indian Literature’: Notes Toward the Definition of a Category,” in the same work, –. -

A Study on Divergence in Malayalam and Tamil Language in Machine Translation Perceptive
A Study on Divergence in Malayalam and Tamil Language in Machine Translation Perceptive Jisha P Jayan Elizabeth Sherly Virtual Resource Centre for Virtual Resource Centre for Language Computing Language Computing IIITM-K,Trivandrum IIITM-K,Trivandrum [email protected] [email protected] Abstract others are specific with respect to the language pair (Lavanya et al., 2005; Saboor and Khan, Machine Translation has made significant 2010). Hence, the divergence in the translation achievements for the past decades. How- need to be studied both perspectives that is across ever, in many languages, the complex- the languages and language specific pair (Sinha, ity with its rich inflection and agglutina- 2005).The most problematic area in translation is tion poses many challenges, that forced the lexicon and the role it plays in the act of creat- for manual translation to make the cor- ing deviations in sense and reference based on the pus available. The divergence in lexi- context of its occurrence in texts (Dash, 2013). cal, syntactic and semantic in any pair Indian languages come under Indo-Aryan or of languages makes machine translation Dravidian scripts. Though there are similarities more difficult. And many systems still de- in scripts, there are many issues and challenges pend on rules heavily, that deteriates sys- in translation between languages such as lexical tem performance. In this paper, a study divergences, ambiguities, lexical mismatches, re- on divergence in Malayalam-Tamil lan- ordering, syntactic and semantic issues, structural guages is attempted at source language changes etc. Human translators try to choose the analysis to make translation process easy. -

The Death of Sanskrit*
The Death of Sanskrit* SHELDON POLLOCK University of Chicago “Toutes les civilisations sont mortelles” (Paul Valéry) In the age of Hindu identity politics (Hindutva) inaugurated in the 1990s by the ascendancy of the Indian People’s Party (Bharatiya Janata Party) and its ideo- logical auxiliary, the World Hindu Council (Vishwa Hindu Parishad), Indian cultural and religious nationalism has been promulgating ever more distorted images of India’s past. Few things are as central to this revisionism as Sanskrit, the dominant culture language of precolonial southern Asia outside the Per- sianate order. Hindutva propagandists have sought to show, for example, that Sanskrit was indigenous to India, and they purport to decipher Indus Valley seals to prove its presence two millennia before it actually came into existence. In a farcical repetition of Romantic myths of primevality, Sanskrit is consid- ered—according to the characteristic hyperbole of the VHP—the source and sole preserver of world culture. The state’s anxiety both about Sanskrit’s role in shaping the historical identity of the Hindu nation and about its contempo- rary vitality has manifested itself in substantial new funding for Sanskrit edu- cation, and in the declaration of 1999–2000 as the “Year of Sanskrit,” with plans for conversation camps, debate and essay competitions, drama festivals, and the like.1 This anxiety has a longer and rather melancholy history in independent In- dia, far antedating the rise of the BJP. Sanskrit was introduced into the Eighth Schedule of the Constitution of India (1949) as a recognized language of the new State of India, ensuring it all the benefits accorded the other fourteen (now seventeen) spoken languages listed. -

Word Level Language Identification in English Telugu
PACLIC 32 Word Level Language Identification in English Telugu Code Mixed Data Sunil Gundapu Radhika Mamidi Language Technologies Research Centre Language Technologies Research Centre KCIS, IIIT Hyderabad KCIS, IIIT Hyderabad Telangana, India Telangana, India [email protected] [email protected] Abstract tion in a single discourse between two languages, where the switching occurs within a sentence). Code In a multilingual or sociolingual configura- mixing is inconsistently elucidated in disparate sub- tion Intra-sentential Code Switching (ICS) or Code Mixing (CM) is frequently observed fields of linguistics and frequent examination of nowadays. In the world most of the people phrases, words, inflectional, derivational morphol- know more than one language. The CM us- ogy and syntax use of a term as an equivalent to age is especially apparent in social media plat- Code Mixing. forms. Moreover, ICS is particularly signifi- Code mixing is defined as the embedding of lin- cant in the context of technology, health and guistic units of one language into utterance of an- law where conveying the upcoming develop- other language. CM is not only used in commonly ments are difficult in ones native language. used spoken form of multilingual setting, but also In applications like dialog systems, machine translation, semantic parsing, shallow pars- used in social media websites in the form of com- ing, etc. CM and Code Switching pose seri- ments and replies, posts and especially in chat con- ous challenges. To do any further advance- versations. Most of the chat conversations are in a ment in code-mixed data, the necessary step formal or semi-formal setting and CM is often used. -
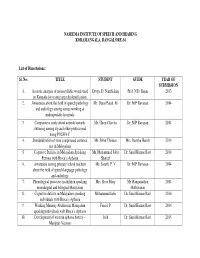
Research Done at Naseema Institute of Speech and Hearing, Bangalore
NASEEMA INSTITUTE OF SPEECH AND HEARING KORAMANGALA, BANGALORE-34 List of Dissertations: Sl. No: TITLE STUDENT GUIDE YEAR OF SUBMISSION 1. Acoustic analysis of monosyllabic words used Divya. D. Nambishan Prof. N.D. Rajan 2013 in Kannada for testing speech identification 2. Awareness about the field of speech pathology Mr. Durai Pandi. M Dr. M.P Ravanan 2014 and audiology among nurses working at multispecialty hospitals 3. Comparative study about attitude towards Mr. Hiren Chovtia Dr. M.P Ravanan 2014 stuttering among slp and other professional using POSHA-C 4. Standardization of time compressed sentence Mr. Jobin Thomas Mrs. Rasitha Harish 2014 test in Malayalam 5. Cognitive Deficits in Malayalam Speaking Mr. Mohammed Jabir Dr. Sunil Kumar Ravi 2014 Persons with Broca’s Aphasia Shareef 6. Awareness among primary school teachers Mr. Sarath. P. V Dr. M.P Ravanan 2014 about the field of speech language pathology and audiology 7. Phonological processes in children speaking Mrs. Rose Mary Mr. Ranganathan 2014 monolingual and bilingual Malayalam Mathivanan 8. Cognitive deficits in Malayalam speaking Mohammed Jabir Dr. Sunil Kumar Ravi 2014 individuals with Broca’s Aphasia 9. Working Memory Abilities in Malayalam Faisal. P Dr. Sunil Kumar Ravi 2014 speaking individuals with Broca’s Aphasia 10. Development of western aphasia battery – Irish Dr. Sunil Kumar Ravi 2015 Manipuri Version 11. Speech dysfluencies in Malayalam speaking Almas Medha .M.Hegde 2015 children with Intellectual Disability 12. Conversational analysis in Malayalam speaking Sitara Shamsuden Medha .M. Hegde 2015 individuals with Dementia 13. Comparison of speech dysfluencies in L1 and Arshida Dr. Sunil Kumar Ravi 2015 L2 of Malayalam –English speaking typical Bilingual children 14. -

South Asian Studies Council 1 South Asian Studies Council
South Asian Studies Council 1 South Asian Studies Council The MacMillan Center 210 Luce Hall, 203.436.3517 http://southasia.macmillan.yale.edu Chair Sunil Amrith (History; on leave) Acting Chair Rohit De (History) Professors Sunil Amrith (History), Tim Barringer (History of Art), Veneeta Dayal (Linguistics), Michael Dove (School of the Environment), Robert Jensen (School of Management), Alan Mikhail (History), A. Mushfiq Mobarak (School of Management), Kaivan Munshi (Economics), Rohini Pande (Economics), Kishwar Rizvi (History of Art), Kalyanakrishnan Sivaramakrishnan (Anthropology), Shyam Sunder (School of Management), Steven Wilkinson (Political Science) Associate Professors Rohit De (History), Nihal DeLanerolle (School of Medicine), Mayur Desai (Public Health), Zareena Grewal (American Studies; Religious Studies) Assistant Professors Subhashini Kaligotla (History of Art), Sarah Khan (Political Science), Priyasha Mukhopadhyay (English) Senior Lecturer Carol Carpenter (School of the Environment) Senior Lector Swapna Sharma (Hindi) Lector Aleksandar Uskokov (Sanskrit) Students with an interest in South Asian Studies should apply to one of the University’s degree-granting departments, such as Anthropology, History, Political Science, Economics, or Religious Studies. The South Asian Studies Council is part of the MacMillan Center for International and Area Studies. It has been organized to provide guidance to graduate students who desire to use the resources of the departments of the University that offer South Asia-related courses. The South Asian Studies Council aims to bring together faculty and students sharing an interest in South Asia, and it supplements the curriculum with seminars, conferences, and special lectures by scholars from Yale as well as visiting scholars. It provides information concerning grants, fellowships, research programs, and foreign study opportunities. -

Multichannel LSTM-CNN for Telugu Technical Domain Identification
Multichannel LSTM-CNN for Telugu Technical Domain Identification Sunil Gundapu Radhika Mamidi Language Technologies Research Centre Language Technologies Research Centre KCIS, IIIT Hyderabad KCIS, IIIT Hyderabad Telangana, India Telangana, India [email protected] [email protected] Abstract Languages. Telugu is one of India’s old traditional languages, and it is categorized as one of the Dra- With the instantaneous growth of text informa- vidian language family. According to the Ethno- tion, retrieving domain-oriented information logue1 list, there are about 93 million native Telugu from the text data has a broad range of applica- tions in Information Retrieval and Natural lan- speakers, and it ranks sixteenth most-spoken lan- guage Processing. Thematic keywords give a guages worldwide. compressed representation of the text. Usually, We tried to identify the domain of Telugu text Domain Identification plays a significant role data using various Supervised Machine Learning in Machine Translation, Text Summarization, and Deep Learning techniques in our work. Our Question Answering, Information Extraction, Multichannel LSTM-CNN method outperforms the and Sentiment Analysis. In this paper, we pro- other methods on the provided dataset. This ap- posed the Multichannel LSTM-CNN method- ology for Technical Domain Identification for proach incorporates the advantages of CNN and Telugu. This architecture was used and eval- Self-Attention based BiLSTM into one model. uated in the context of the ICON shared task The rest of the paper is structured as follows: “TechDOfication 2020” (task h), and our sys- Section 2 explains some related works of domain tem got 69.9% of the F1 score on the test identification, Section 3 describes the dataset pro- dataset and 90.01% on the validation set. -

Dr. SUNIL KUMAR. RAVI, M.Sc (SLP), Ph.D (Speech Language Pathology) Associate Professor & Principal, Naseema Institute of Speech & Hearing, Bangalore, India
Curriculum Vitae Dr. SUNIL KUMAR. RAVI, M.Sc (SLP), Ph.D (Speech Language Pathology) Associate Professor & Principal, Naseema Institute of Speech & Hearing, Bangalore, India. Tel: +91-9620542794 E-Mail: [email protected] PROFESSIONAL PROFILE 1. Working as Associate Professor & Principal at Naseema Institute of Speech and Hearing, Bangalore from August, 2013. 2. Faculty Consultant for developing curriculum for Bachelor of Health Science (Majors in Speech & Hearing) at Gulf Medical University, Ajman (as per ASHA standards) during April, May, & October, 2014. 3. Guest Faculty at Department of Psychology, University of Mysore, Mysore for M.Phil in Learning Disability Course. 4. Expert Committee member (Speech Language Pathology) in Indian Council of Medical Research (ICMR) National Task Force (NTF) project titled “Development and Validation of a Comprehensive Clinical and Neuropsychological Test Battery for use in the Indian context for patients with Vascular Cognitive Impairment (VCI)". 5. Ph.D Thesis title: An Event Related Brain Potential Study of Language Processing in Kannada – English Bilingual Aphasics (University of Mysore, Mysore). AWARDS/ FELLOWSHIPS Received Foreign Travel Grant from Council of Scientific and Industrial Research, Human Resource Development Group, Government of India, New Delhi for attending and presenting three research papers at International Conference on Bilingualism and Comparative Linguistics, held at Chinese University of Hong Kong, Hong Kong, during 15th and 16th of May, 2012. (Ref no: TG/6661/11-HRD dated 23.04.2012.) Received Junior Research Fellowship for pursuing Ph.D in Speech Language Pathology program from All India Institute of Speech and Hearing, Mysore for a period of three years. Received best paper award in National Conference on Neurogenic Communication Disorders in Adults held at Krishna Institute of Medical Sciences, Hyderabad in December, 2015. -

Tamil Studies, Or Essays on the History of the Tamil People, Language
'^J'iiiDNVSoi^^ v/yaaAiNrtiwv" ^(?Aavaaiiiv> ^omMW -^llIBRARYd?/r. ^MEUNIVERy/A. vvlOSANCE o o \^my\^ ^OJUVJ-JO"^ ^OFCAIIFO/?^ ^OF-CAilFO/?^ ^^WE UNIVERi/^ ^lOSANCE o ^AUvHsni^ "^^^AHvaan^- ^tji^dkysoi^^ AWEUNIVER5'//. vvlOSANCElfj> ^lllBRARY6k. <rii33Nvsoi^ '^/ya3AiNn3WV %ojnvojo^ .^WEUNIVER% v^lOSANCElfj> ^^;OFCAL1FO/?^ 4sS ^, <rii30Nvsoi^ %a3AiNiiawv* ^<?Aavaaii-i^ ^IIIBRARY<9^ A^^lllBRARYQ^^ ^\^EUNIVER% ^lOSANCEl U-o ^ ^«!/0JITV3JO^ ^<!/0JnV3J0^ ^OF-CAIIFO% >;,OFCAIIFOP^ ^WEUNIVER% vvlOSANCEl o '^^Aavaaii-^'^ ^bvaaii^- <rji30Nvsoi^'^ C^ V<y lONvsoi^ %a3AiNn-3UV* ^<?AJivaaii^'^ ^^AHvaaii] ^ILIBRARYQ^ -.v^lLIBRARY6k, A\\EUNIVERS/A .vWSANCEli o = ;^ \oi\mi^'^ ^<tfOdllV3-JO^ ^TiiJOKVSOl^'^ ^OF-CALfFOMi^ .-A;OFCA[IFO/?^ .^WEUNIVERS-/// O .avaaiH^ %avHani^ <rii30Nvsoi=<^ \WEUNIVER5//, ^lOSANGElfj> 5^llIBRARY6>/\ ^lUBRARY i^ o o -< ^/5a3AINn]WV^ ^(tfOdllVDJO^ %QmH ,>\^EUNIVERS//i vvlOSANCElfx^ ^OFCAIIFO/?^ o tjLJ> o "^AddAINfl-dUV ^^Aav«aii-i^ LiBRARYQc. ^^•IIBRARYQ^ A\^EUNIVER5/A ^lOSANCEli OOr o ^<!/OJI7V3JO^ ^OFCAIIFO^^ ^OFCAIIFO/?^ aWEUNIVERS//, '^^AWaaiH'^ ^^Aavaaii-^^^ <r?]3ow.soi^'^ TAMIL STUDIES k \\ • MAP OF Ind|/\ W *|/ a u<-7 '^'^Ti /"**"" .h^'t^^iitu^yh ( D) \ \ TAMIL STUDIES OR ESSAYS ON THE HISTORY OF THE TAMIL PEOPLE, LANGUAGE, RELIGION AND LITERATURE BY M. SRINIVASA AIYANGAR, M.A. FIRST SERIES WITH MAP AND PLATE MADRAS AT THE GQARDIAN PRESS ' 1914 J[All rights reserved"} G. C. LOGANADHAM BROS, THE GUARDIAN PRESS, MADRAS D3 T3S7 To Tbe VConourable SIR HAROLD STUART, k.cy.o., C.s.i., i.c.s, /Aerober of Qouncil, /AadraS Tb'S 9olun)e 3s by Hind pern))SSion roost reSpectfutty Pedicatecf By ^bs ^utbor (Cs a bu")bte tribute of gratitude 2n5ien5io PREFACE A popular hand-book to the history, from original sources, of the Tamil people has been a want. In these essays an attempt has been made for the first time to put together the results of past researches, so as to present before the reader a complete bird's-eye view of the early history of Tamil culture and civilisation. -
Sunil Kumar Pawar B
SUNIL KUMAR PAWAR B. Sc, MBA, NET (Management) E-mail: [email protected] Mobile: +917026847373, +919901714843 CAREER OBJECTIVE: Strategically exploit potential and ability to attain desired synergy in a creative, challenging and competitive environment. EDUCATIONAL QUALIFICATION: National Eligibility Test (NET) Qualified in UGC NET (Eligibility for Lectureship), held on 30th June 2013 in Management Subject. Post Graduation Completed MBA specialized in Marketing and Human Resource Management, from Vijaynagara Institute of Management Studies, Bellary (Gulbarga University). Graduation Completed B.Sc (Computer Science and Electronics) from S.B. College, Gulbarga (Gulbarga University). WORK EXPERIENCE: Total experience of 9+ years (academics experience of 8.5 years and industrial experience of 1.6 years). ACADEMICS Working with Central University of Karnataka at Kadaganchi as Assistant Professor on contract basis from August 18th 2014 to till date. Worked with Sai Vidya Institute of Technology, Bangalore affiliated to Visvesvaraiah Technological University, Belgaum, as Assistant Professor from 18th Feb to 19th June 2014. Worked with Sinhgad Institute of Business Management, Sangola, Maharashtra, affiliated to Sholapur University, as Assistant Professor from 5th Jan, 2010 to 15th Feb 2011. Worked with Sharnbasveshwar College of Commerce, Department of BBM at Gulbarga affiliated to Gulbarga University, Gulbarga, as Lecturer, from 4th December 2007 to 31st December 2009. INDUSTRY Worked with HDFC Bank Ltd’s DST, HBL Global from December 2005 to May 2007 as Senior Sales Executive for loans in Koramangala Branch, Bangalore. RESEARCH PAPERS: Written, presented and published research papers in national and international seminars and conferences and journal as mentioned below: Written and published a research paper in international journal of research in management and social science on the topic “Amplified Growth through Integration” in October – December, Issue 4 (I), Volume 2 in 2014. -

Student Stories
Student Stories Name: Shanti Lamani Age: 12 Currently Studying: 7th Standard Shanti’s background Shanti and her family belong to the Lamani community which is classified as a scheduled caste by the Indian Government. She’s from Hampi in Karnataka, the same state as KSV. Here she attended her local school from 1st to 6th Standard before joining KSV in 2017 in 7th Standard. Shanti has four older sisters and two younger. Three of her sisters Kaveri, Chinni and Pooja are also attending KSV in 9th, 8th and 3rd Standard. Her parents are no longer together, her father left the family home and now has a new wife. To be closer to her daughters, Shanti’s mother, Yankubai, has moved near to the school, where she hopes to open a shop. Previously in Hampi she used to sell fruit and rent bikes to tourists. Before joining KSV, Shanti used to help her mother with selling after school and help at her uncle’s hotel. Shanti’s achievements at KSV For her performing arts, Shanti is learning dance and vocals. Dance is her favourite. She speaks Lamani (her local language) but also English, Kannada and Hindi which she continues to learn at KSV. Compared to other students of her standard, Shanti’s level of English is very good having had experience of working with tourists in Hampi. Every day, except on Sundays, she attends vocal lessons in the morning and then academic classes until the end of the school day. She studies Kannada, English, Mathematics, Hindi, Sport and Science. Shanti loves learning English, especially as it wasn’t a subject she was taught at her previous school in Hampi. -

Of Doordarshan Bo
Arpan Srivastava gmail.com submitted on 14 January 2013 Hi, I want to add one more horror serial of 80's named " Bunder Ka punja" of Doordarshan bobbysing submitted on 23 January 2013 Thanks Arpan for your addition and Keep Visiting. HIS BLESSINGS Naveen K. Narela submitted on 14 January 2013 Sh. Bobby ji, I remember one serial on doordarshan in very early period say 1980,s "Pintoo Singh Taxi wala" with Paintal as in lead role. bobbysing submitted on 23 January 2013 Hi Naveen, Thanks a lot for reminding me but actually it was "Ladoo Singh Taxi Wala" as I can recall and would soon add it in the article too. Cheers! Bala submitted on 19 January 2013 Cartoons: Guchee, potlie Baba, tales spin, duck tales, gadget man, superhuman samurai Serials: Ajnabi, Hindustani, Khanoon, captain house, street hawk, turning point, different strokes, made in india. bobbysing submitted on 23 January 2013 Thanks Bala for writing in but here we are actually listing all the HINDI serials before 90 only. Yet it was good to read those names again. Cheers! raghuveer submitted on 21 January 2013 Will any body tell me one of doordarshan horror tv serial whose name i can not recall. It start music with ti, titi,titi, DAN (only music & no title song) With picturisation of Khandar situated in open space. if i am not wrong it telecast on saturday or sunday at appx 9pm. it comes after neev, chunoti, & nearby period of subah. bobbysing submitted on 23 January 2013 Hi Raghuveer, Our friend Rashmi has given the right answer to you as I can recall too! Cheers! raj submitted on 22 January 2013 Bobby ji, Badi kushi hui is blog dekke, Ekbar aap pura list ko taza karenge with what are all available in the market as CD/DVD's (all those loverly serials which left an impression on us before to 1991) I really thank you from bottom of my heart.