Content-Based Recommendations for Radio Stations with Deep Learned Audio Fingerprints
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

1 Decision of the Election Committee on a Due Impartiality Complaint Brought by the Respect Party in Relation to the London Deba
Decision of the Election Committee on a due impartiality complaint brought by the Respect Party in relation to The London Debate ITV London, 5 April 2016 LBC 97.3 , 5 April 2016 1. On Friday 29 April 2016, Ofcom’s Election Committee (“the Committee”)1 met to consider and adjudicate on a complaint made by the Respect Party in relation to its candidate for the London Mayoral election, George Galloway (“the Complaint”). The Complaint was about the programme The London Debate, broadcast in ITV’s London region on ITV, and on ITV HD and ITV+1 at 18:00 on Tuesday 5 April 2016 (“the Programme”). The Programme was broadcast simultaneously by LBC on the local analogue radio station LBC 97.3, as well as nationally on DAB radio and on digital television (as a radio channel). 2. The Committee consisted of the following members: Nick Pollard (Chair, Member of the Ofcom Content Board); Dame Lynne Brindley DBE (Member of the Ofcom Board and Content Board); Janey Walker (Member of the Ofcom Content Board); and Tony Close (Ofcom Director with responsibility for Content Standards, Licensing and Enforcement and Member of the Ofcom Content Board). 3. For the reasons set out in this decision, having considered all of the submissions and evidence before it under the relevant provisions of the Broadcasting Code (“the Code”), the Committee decided not to uphold the Respect Party’s complaint. The Committee found that in respect of ITV the broadcast of the Programme complied with the requirements of the Code. In the case of LBC, the Programme did not a contain list of candidates in the 2016 London Mayoral election (in audio form) and LBC therefore breached Rule 6.11. -

Appendix 1 – Press Monitoring (National Publications)
APPENDIX 1 – PRESS MONITORING (NATIONAL PUBLICATIONS) Sunday Daily Nationals Magazines Nationals Other Daily Express Anglers Mail Daily Star City AM London Sunday Daily Mail Angling Times Sunday Times Lloyds List London Daily Star CIWM Magazine The Mail on International Sunday Herald Tribune Daily Telegraph Economist News of the Wall Street World Journal Europe Evening Standard ENDS Report The Observer Financial Times Farmers Guardian Sunday Express Metro Farmers Weekly Sunday Mirror The Guardian The People Independent i Local Government Chronicle Independent Materials Recycling Week Daily Mirror Motorboats Monthly The Sun Municipal Journal The Times Regeneration & Renewal New Statesman New Scientist PR Week Planning Private Eye Recycling and Waste World Utility Week Resource Management and Recovery Reuters New Civil Engineer APPENDIX 2 – PRESS MONITORING (NATIONAL KEY WORDS) Keyword Keyword Description Agriculture - Environment Important mentions of farming or agriculture ICW the environment. Carbon Emissions All mentions of carbon emissions OICW climate change, global warming etc. Climate Change All mentions of climate change. Coastal Erosion All mentions of coastal erosion. DEFRA All mentions of Department for Environment, Food and Rural Affairs (DEFRA). Department of Energy & Climate All mentions of the Department of Energy & Climate Change Change (DECC) Drought Main focus mentions of droughts in the UK Environment All mentions of environmental issues Environment - Emissions Important mentions of emissions and their effect on the environment. Environment Agency All mentions of the Environment Agency. Fishing All mentions of fishing ICW the environment. Flooding - Environmental Impact Important Mentions of floods OICW effects on the environment and homes Fly Tipping All mentions of fly tipping Hosepipes All mentions of hosepipes Nuclear Power - Environmental Main focus mentions of environmental effects of nuclear power. -

Audio-Based Fingerprinting for Radio Station Recommendations
AUDIO-BASED FINGERPRINTING FOR RADIO STATION RECOMMENDATIONS Stefan Langer, Markus Friedrich, Liza Obermeier, Emma Munisamy Andre´ Ebert Claudia Linnhoff-Popien∗ inovex GmbH LMU Munich, Mobile and Distributed Data Management and Analytics Systems Group andre.ebert@ifi.lmu.de [first name].[last name]@ifi.lmu.de ABSTRACT and precise station recommendations. This paper focuses on the latter and thus on the question how The world of linear radio broadcasting is characterized by a to generate meaningful recommendations for radio stations. wide variety of stations and played content. That is why find- Two main types of approaches can be distinguished for that: ing stations playing the preferred content is a tough task for a Recommendations based on Collaborative Filtering (CF) and potential listener, especially due to the overwhelming number Content-based Filtering (CBF) approaches. CF focuses on of offered choices. Here, recommender systems usually step user opinions and behavior, which can lead to privacy issues in but existing content-based approaches rely on metadata and as well as the Cold Start Problem (see Section 2). Thus, a thus are constrained by the available data quality. Therefore, CBF based recommender system working with characteris- we propose a new pipeline for the generation of audio-based tics derived from available station data is preferred in context radio station fingerprints relying on audio stream crawling of this work. In [1], it could be shown that station recom- and a deep autoencoder. We show that the proposed finger- mendation based on available metadata is possible, but only prints are especially useful for characterizing radio stations if the metadata reaches a certain quality level. -

BMJ in the News 29 March
BMJ in the News is a weekly digest of journal stories, plus any other news about the company that has appeared in the national and a selection of English-speaking international media. A total of 27 journals were picked up in the media last week (29 March-4 April) - our highlights include: ● Research published in The BMJ finding that levels of adherence to the UK’s test, trace, and isolate system are low made national headlines, including BBC News, The Guardian, and The Daily Telegraph. ● A BJSM study suggesting that physical inactivity is responsible for up to 8% of non-communicable diseases and deaths worldwide was picked up by CNN, ITV News, and Gulf Today. ● A study in The BMJ revealing that people discharged from hospital after covid-19 appear to have increased rates of organ damage compared with similar individuals in the general population made headlines in the Times of India, Huffington Post, and Asian Image. BMJ PRESS RELEASES The BMJ | British Journal of Ophthalmology British Journal of Sports Medicine | Thorax EXTERNAL PRESS RELEASES BMJ Nutrition, Prevention & Health | BMJ Open Gut | Journal for Immunotherapy of Cancer Stroke & Vascular Neurology OTHER COVERAGE The BMJ | Annals of the Rheumatic Diseases BMJ Case Reports | BMJ Global Health BMJ Open Gastroenterology | BMJ Open Ophthalmology BMJ Open Science | BMJ Open Sport & Exercise Medicine BMJ Supportive & Palliative Care| Heart Journal of Epidemiology & Community Health | Journal of Medical Ethics Journal of Medical Genetics | Journal of NeuroInterventional Surgery Journal -

Culture, Media and Sport Committee
House of Commons Culture, Media and Sport Committee Future of the BBC Fourth Report of Session 2014–15 Report, together with formal minutes relating to the report Ordered by the House of Commons to be printed 10 February 2015 HC 315 INCORPORATING HC 949, SESSION 2013-14 Published on 26 February 2015 by authority of the House of Commons London: The Stationery Office Limited £0.00 The Culture, Media and Sport Committee The Culture, Media and Sport Committee is appointed by the House of Commons to examine the expenditure, administration and policy of the Department for Culture, Media and Sport and its associated public bodies. Current membership Mr John Whittingdale MP (Conservative, Maldon) (Chair) Mr Ben Bradshaw MP (Labour, Exeter) Angie Bray MP (Conservative, Ealing Central and Acton) Conor Burns MP (Conservative, Bournemouth West) Tracey Crouch MP (Conservative, Chatham and Aylesford) Philip Davies MP (Conservative, Shipley) Paul Farrelly MP (Labour, Newcastle-under-Lyme) Mr John Leech MP (Liberal Democrat, Manchester, Withington) Steve Rotheram MP (Labour, Liverpool, Walton) Jim Sheridan MP (Labour, Paisley and Renfrewshire North) Mr Gerry Sutcliffe MP (Labour, Bradford South) The following Members were also a member of the Committee during the Parliament: David Cairns MP (Labour, Inverclyde) Dr Thérèse Coffey MP (Conservative, Suffolk Coastal) Damian Collins MP (Conservative, Folkestone and Hythe) Alan Keen MP (Labour Co-operative, Feltham and Heston) Louise Mensch MP (Conservative, Corby) Mr Adrian Sanders MP (Liberal Democrat, Torbay) Mr Tom Watson MP (Labour, West Bromwich East) Powers The Committee is one of the Departmental Select Committees, the powers of which are set out in House of Commons Standing Orders, principally in SO No 152. -

Ofcom Audio Survey 2021: Questionnaire
Survey name: Ofcom Audio Survey 2021 Timings: 3-7 March 2021 Methodology: Online survey We are conducting research on behalf of the UK's communications regulator Ofcom, who are looking to understand use of and attitudes towards different types of radio and audio services. ASK ALL 1. How often, if at all, do you do any of the following? GRID ROWS – RANDOMISE ORDER 1. A. Listen to radio (at the time of broadcast: not catch-up/podcast) 2. B. Listen to catch-up radio 3. C. Listen to music online 4. D. Listen to music stored or downloaded on a device 5. E. Listen to personal music collection (e.g. CDs, vinyls) 6. F. Listen to podcasts 7. G. Listen to audiobooks (digital/online and physical) 8. H. Use music videos as background listening (i.e. music video channels or sites such as YouTube or MTV) 9. GRID COLUMNS – SINGLE CODE 1. Several times a day 2. About once a day 3. Several times a week 4. About once a week 5. Several times a month 6. About once a month 7. Less often 8. Never ASK ALL (BACK FILTER ANYONE WHO LISTS A STATION HERE BUT DID NOT CODE ‘A RADIO STATION’ IN Q1) 2. Which, if any, of these radio stations have you listened to in the last 7 days? MULTICODE BBC Radio 1 BBC Radio 2 BBC Radio 3 BBC Radio 4 BBC Radio 5 live BBC 6 Music BBC Asian Network BBC Radio 1Xtra BBC Radio 4 Extra BBC Radio 5 live sports extra BBC World Service BBC radio for your nation / region (e.g. -
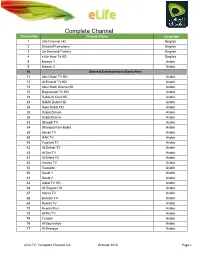
Complete Channel List October 2015 Page 1
Complete Channel Channel No. List Channel Name Language 1 Info Channel HD English 2 Etisalat Promotions English 3 On Demand Trailers English 4 eLife How-To HD English 8 Mosaic 1 Arabic 9 Mosaic 2 Arabic 10 General Entertainment Starts Here 11 Abu Dhabi TV HD Arabic 12 Al Emarat TV HD Arabic 13 Abu Dhabi Drama HD Arabic 15 Baynounah TV HD Arabic 22 Dubai Al Oula HD Arabic 23 SAMA Dubai HD Arabic 24 Noor Dubai HD Arabic 25 Dubai Zaman Arabic 26 Dubai Drama Arabic 33 Sharjah TV Arabic 34 Sharqiya from Kalba Arabic 38 Ajman TV Arabic 39 RAK TV Arabic 40 Fujairah TV Arabic 42 Al Dafrah TV Arabic 43 Al Dar TV Arabic 51 Al Waha TV Arabic 52 Hawas TV Arabic 53 Tawazon Arabic 60 Saudi 1 Arabic 61 Saudi 2 Arabic 63 Qatar TV HD Arabic 64 Al Rayyan HD Arabic 67 Oman TV Arabic 68 Bahrain TV Arabic 69 Kuwait TV Arabic 70 Kuwait Plus Arabic 73 Al Rai TV Arabic 74 Funoon Arabic 76 Al Soumariya Arabic 77 Al Sharqiya Arabic eLife TV : Complete Channel List October 2015 Page 1 Complete Channel 79 LBC Sat List Arabic 80 OTV Arabic 81 LDC Arabic 82 Future TV Arabic 83 Tele Liban Arabic 84 MTV Lebanon Arabic 85 NBN Arabic 86 Al Jadeed Arabic 89 Jordan TV Arabic 91 Palestine Arabic 92 Syria TV Arabic 94 Al Masriya Arabic 95 Al Kahera Wal Nass Arabic 96 Al Kahera Wal Nass +2 Arabic 97 ON TV Arabic 98 ON TV Live Arabic 101 CBC Arabic 102 CBC Extra Arabic 103 CBC Drama Arabic 104 Al Hayat Arabic 105 Al Hayat 2 Arabic 106 Al Hayat Musalsalat Arabic 108 Al Nahar TV Arabic 109 Al Nahar TV +2 Arabic 110 Al Nahar Drama Arabic 112 Sada Al Balad Arabic 113 Sada Al Balad -

Craft Focus Magazine
www.craftfocus.com April/May 2010 April/May CRAFTFOCUS Issue 18 www.craftfocus.com MAGAZINE Happy Birthday Craft Focus! REVIEWS • Craft Hobby + Stitch International • CHA Winter Show TRIED AND TESTED KNITTING YARN How card making is evolving Does e-commerce work for your business? PLUS WIN! Latest products £500 worth of Numberjacks craft Industry profiles kits from Creativity International News & views Position Yourself for the Economic Recovery! Just turn the page to discover how leading UK retailers and manufacturers plan to grow their business in 2010! Give Your Business a Competitive Join us on a Special Reader Trip to the 27-29 Stephens Con Rosemont, Illinois - j “It’s the ideal platform for UK manufacturers and retailers to learn more about the US craft business and the way it operates. Many UK companies that have ventured into the important US market have used the Show as a starting point before committing full-scale.” - Sara Davies, Sales Director at Crafter’s Companion Discover Trends Before Your Competitors X Superb access to craft industry design, manufacturing and retail trends from across the globe X Engage with hundreds of exhibitors and thousands of attendees representing a vast selection of product categories across: B Scrapbooking and Papercrafts B Fabric, Quilting and Needlecrafts B Art Materials and Framing B General Crafts Edge and Find Inspiration in Chicago CHA 2010 Summer Convention & Trade Show July 2010 nvention Center just outside of Chicago Build Your Business with World Class Education X Business building seminars that provide attendees with ideas and strategies they can immediately apply to their own businesses. -

Optical Studies of Massive X-Ray Binaries" Door E.J
C 7A OPTICAL STUDIES OF SIVE m EJ. ZUIDERWIJK optical studies of massive X- ray binaries ACADEMISCH PROEFSCHRIFT TER VERKRIJGING VAN DE GRAAD VAN DOCTOR IN DE WISKUNDE EN NATUURWETENSCHAPPEN AAN DE UNIVERSITEIT VAN AMSTERDAM, OP GEZAG VAN DE RECTOR MAGNIFICUS, DR. J. BRUYN, HOOGLERAAR IN DE FACULTEIT DER LETTEREN, IN HET OPENBAAR TE VERDEDIGEN IN DE AULA DER UNIVERSITEIT (TIJDELIJK IN DE LUTHERSE KERK, INGANG SINGEL 411, HOEK SPUI) OP WOENSDAG 20 JUN11979 DES NAMIDDAGS TE 15.00 UUR PRECIES DOOR EDUARDUSJOSEPHUSZUIDERWIJK GEBOREN TE HAARLEM PROMOTOR : Prof. Dr. E.P.J. van den Heave 1 COREFERENT : Dr. H.G L.M. Lamers The work described in this thesis was supported by the "Netherlands Organi- sation for the advancement of Pure Re- search" (ZWO) and by the University of of Amsterdam. -\ Voor mijn Iet en onze Ouders i Na het voltooien van mijn proefschrift wil ik graag allen bedanken die aan het tot stand komen ervan hebben bijgedragen. Allereerst dank ik mijn ouders, die mij de gelegenheid gaven een aca- demische opleiding te volgen. Bijzonder erkentelijk ben ik mijn Promotor Prof. Dr. E.P.J. van den Heuvel, die het voor mij mogelijk maakte het onderzoek uit te voeren. Hij is daarbij altijd een steun geweest door de interesse getoond in mijn werk, die onder andere tot uiting kwam in langdurige en diepgaande gedach- tenwisselingen. De coreferent Dr. H.J.G.L.M. Lamers dank ik voor het kritisch lezen van het proefschrift. Het grootste deel van de in mijn proefschrift verwerkte publicaties zijn tot stand gekomen in nauwe samenwerking met mijn collega's van het Sterrenkundig Instituut van de universiteit van Amsterdam en van het As- trophysisch Instituut van de Vrije Universiteit van Brussel. -

Issue 385 of Ofcom's Broadcast and on Demand Bulletin
Issue 385 of Ofcom’s Broadcast and On Demand Bulletin 27 August 2019 Issue number 385 27 August 2019 Issue 385 of Ofcom’s Broadcast and On Demand Bulletin 27 August 2019 Contents Introduction 3 Notice of Sanction Autonomous Non-profit Organisation TV-Novosti 5 Broadcast Standards cases In Breach The No Repeat 9 to 5 on Sam FM Sam FM Bristol, 20 May 2019, 12:34 7 Journey for Iqra Iqra Bangla, 28 March 2019, 20:00 9 Resolved The Music Marathon Gold, 27 May 2019, 12:45 15 Advertising Scheduling cases In Breach Advertising minutage ATN Bangla UK, various dates between 27 January 2019 and 10 March 2019 19 Advertising minutage Sony Entertainment Television, various dates between 24 February 2019 and 14 April 2019 20 Broadcast Licence Conditions cases In Breach Providing a service in accordance with ‘Key Commitments’ EAVA FM, St Mathews Community Solution Centre Ltd, 6 to 12 May 2019 22 Retention and production of recordings ATN Bangla UK, ATN Bangla UK Limited 25 Tables of cases Complaints assessed, not investigated 27 Complaints outside of remit 38 BBC First 40 Investigations List 42 Issue 385 of Ofcom’s Broadcast and On Demand Bulletin 27 August 2019 Introduction Under the Communications Act 2003 (“the Act”), Ofcom has a duty to set standards for broadcast content to secure the standards objectives1. Ofcom also has a duty to ensure that On Demand Programme Services (“ODPS”) comply with certain standards requirements set out in the Act2. Ofcom reflects these requirements in its codes and rules. The Broadcast and On Demand Bulletin reports on the outcome of Ofcom’s investigations into alleged breaches of its codes and rules, as well as conditions with which broadcasters licensed by Ofcom are required to comply. -
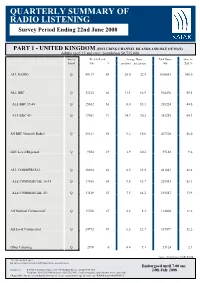
QUARTERLY SUMMARY of RADIO LISTENING Survey Period Ending 22Nd June 2008
QUARTERLY SUMMARY OF RADIO LISTENING Survey Period Ending 22nd June 2008 PART 1 - UNITED KINGDOM (INCLUDING CHANNEL ISLANDS AND ISLE OF MAN) Adults aged 15 and over: population 50,735,000 Survey Weekly Reach Average Hours Total Hours Share in Period '000 % per head per listener '000 TSA % ALL RADIO Q 45117 89 20.0 22.5 1016681 100.0 ALL BBC Q 33323 66 11.1 16.9 564476 55.5 ALL BBC 15-44 Q 15362 61 8.0 13.1 201224 44.6 ALL BBC 45+ Q 17961 71 14.3 20.2 363252 64.3 All BBC Network Radio¹ Q 29611 58 9.2 15.8 467328 46.0 BBC Local/Regional Q 9504 19 1.9 10.2 97148 9.6 ALL COMMERCIAL Q 30984 61 8.5 13.9 431081 42.4 ALL COMMERCIAL 15-44 Q 17465 69 9.5 13.7 239533 53.1 ALL COMMERCIAL 45+ Q 13519 53 7.5 14.2 191547 33.9 All National Commercial¹ Q 13760 27 2.2 8.3 114002 11.2 All Local Commercial Q 24992 49 6.2 12.7 317079 31.2 Other Listening Q 2978 6 0.4 7.1 21124 2.1 Source: RAJAR/Ipsos MORI/RSMB ¹ See note on back cover. For survey periods and other definitions please see back cover. Embargoed until 7.00 am Enquires to: RAJAR, Paramount House, 162-170 Wardour Street, London W1F 8ZX 24th July 2008 Telephone: 020 7292 9040 Facsimile: 020 7292 9041 e mail: [email protected] Internet: www.rajar.co.uk ©Rajar 2008. -

Global Is Still the UK's Number One Commercial Radio Company with a Weekly Reach of 23.1 Million Listeners
View this email online Global is still the UK's number one commercial radio company with a weekly reach of 23.1 million listeners. HEART Heart is still the largest commercial radio station in the UK with a weekly reach of 9.1 million listeners. More about Heart's results » CAPITAL Capital is the UK’s second largest commercial radio station, with 7.3m listeners. Capital London reaches 2m. This makes it London’s number one commercial station! More about Capital's results » CLASSIC FM Classic FM reaches 5.2 million listeners across the country each week with ABC1s making up 69% of its audience. More about Classic FM's results » SMOOTH Following Heart, Capital and Classic FM, Smooth remains one of the top five commercial stations in the country. Smooth reaches 4.7 million listeners, which is growth of 2% from last quarter. More about Smooth's results » LBC LBC’s high profile continues to attract new listeners. LBC’s weekly reach is 1.3 million nationwide. In London alone, LBC 97.3 reaches nearly 1 million each week. More about LBC's results » XFM XFM enjoys impressive growth this quarter. Reach is up 7% to 988,000 listeners. XFM’s Manchester station is the star performer, with reach up a staggering 29% from last quarter, taking its reach to 298,000 More about XFM's results » CAPITAL XTRA Capital XTRA reaches 809,000 listeners a week with 15-34 year olds making up 79% of its UK audience. Reach for 15-34s in London is up an impressive 16%.