Audio-Based Fingerprinting for Radio Station Recommendations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Content-Based Recommendations for Radio Stations with Deep Learned Audio Fingerprints
Herausgeber et al. (Hrsg.): Informatik 2020, Lecture Notes in Informatics (LNI), Gesellschaft für Informatik, Bonn 2020 1 Content-based Recommendations for Radio Stations with Deep Learned Audio Fingerprints Stefan Langer ,1 Liza Obermeier ,2 André Ebert ,3 Markus Friedrich ,4 Emma Munisamy ,5 Claudia Linnhoff-Popien 6 Abstract: The world of linear radio broadcasting is characterized by a wide variety of stations and played content. That is why finding stations playing the preferred content is a tough task for a potential listener, especially due to the overwhelming number of offered choices. Here, recommender systems usually step in but existing content-based approaches rely on metadata and thus are constrained by the available data quality. Other approaches leverage user behavior data and thus do not exploit any domain-specific knowledge and are furthermore disadvantageous regarding privacy concerns. Therefore, we propose a new pipeline for the generation of audio-based radio station fingerprints relying on audio stream crawling and a Deep Autoencoder. We show that the proposed fingerprints are especially useful for characterizing radio stations by their audio content and thus are an excellent representation for meaningful and reliable radio station recommendations. Furthermore, the proposed modules are part of the HRADIO Communication Platform, which enables hybrid radio features to radio stations. It is released with a flexible open source license and enables especially small- and medium-sized businesses, to provide customized and high quality radio services to potential listeners. Keywords: Hybrid Radio, Multimedia Services, Recommender Systems, Unsupervised Learning, Deep Audio Fingerprints, Deep Learning 1 Introduction Despite emerging competition from on-demand content services, linear radio broadcasting still remains one of the most popular entertainment and information media in Europe. -

Craft Focus Magazine
www.craftfocus.com April/May 2010 April/May CRAFTFOCUS Issue 18 www.craftfocus.com MAGAZINE Happy Birthday Craft Focus! REVIEWS • Craft Hobby + Stitch International • CHA Winter Show TRIED AND TESTED KNITTING YARN How card making is evolving Does e-commerce work for your business? PLUS WIN! Latest products £500 worth of Numberjacks craft Industry profiles kits from Creativity International News & views Position Yourself for the Economic Recovery! Just turn the page to discover how leading UK retailers and manufacturers plan to grow their business in 2010! Give Your Business a Competitive Join us on a Special Reader Trip to the 27-29 Stephens Con Rosemont, Illinois - j “It’s the ideal platform for UK manufacturers and retailers to learn more about the US craft business and the way it operates. Many UK companies that have ventured into the important US market have used the Show as a starting point before committing full-scale.” - Sara Davies, Sales Director at Crafter’s Companion Discover Trends Before Your Competitors X Superb access to craft industry design, manufacturing and retail trends from across the globe X Engage with hundreds of exhibitors and thousands of attendees representing a vast selection of product categories across: B Scrapbooking and Papercrafts B Fabric, Quilting and Needlecrafts B Art Materials and Framing B General Crafts Edge and Find Inspiration in Chicago CHA 2010 Summer Convention & Trade Show July 2010 nvention Center just outside of Chicago Build Your Business with World Class Education X Business building seminars that provide attendees with ideas and strategies they can immediately apply to their own businesses. -
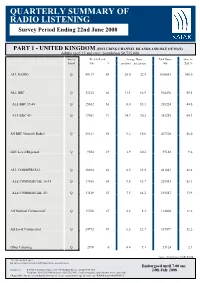
QUARTERLY SUMMARY of RADIO LISTENING Survey Period Ending 22Nd June 2008
QUARTERLY SUMMARY OF RADIO LISTENING Survey Period Ending 22nd June 2008 PART 1 - UNITED KINGDOM (INCLUDING CHANNEL ISLANDS AND ISLE OF MAN) Adults aged 15 and over: population 50,735,000 Survey Weekly Reach Average Hours Total Hours Share in Period '000 % per head per listener '000 TSA % ALL RADIO Q 45117 89 20.0 22.5 1016681 100.0 ALL BBC Q 33323 66 11.1 16.9 564476 55.5 ALL BBC 15-44 Q 15362 61 8.0 13.1 201224 44.6 ALL BBC 45+ Q 17961 71 14.3 20.2 363252 64.3 All BBC Network Radio¹ Q 29611 58 9.2 15.8 467328 46.0 BBC Local/Regional Q 9504 19 1.9 10.2 97148 9.6 ALL COMMERCIAL Q 30984 61 8.5 13.9 431081 42.4 ALL COMMERCIAL 15-44 Q 17465 69 9.5 13.7 239533 53.1 ALL COMMERCIAL 45+ Q 13519 53 7.5 14.2 191547 33.9 All National Commercial¹ Q 13760 27 2.2 8.3 114002 11.2 All Local Commercial Q 24992 49 6.2 12.7 317079 31.2 Other Listening Q 2978 6 0.4 7.1 21124 2.1 Source: RAJAR/Ipsos MORI/RSMB ¹ See note on back cover. For survey periods and other definitions please see back cover. Embargoed until 7.00 am Enquires to: RAJAR, Paramount House, 162-170 Wardour Street, London W1F 8ZX 24th July 2008 Telephone: 020 7292 9040 Facsimile: 020 7292 9041 e mail: [email protected] Internet: www.rajar.co.uk ©Rajar 2008. -

Hallett Arendt Rajar Topline Results - Wave 3 2005/Last Published Data
HALLETT ARENDT RAJAR TOPLINE RESULTS - WAVE 3 2005/LAST PUBLISHED DATA Population 15+ Change Weekly Reach 000's Change Weekly Reach % Total Hours 000's Change Average Hours Market Share LOCAL COMMERCIAL Last Pub W3 2005 000's % Last Pub W3 2005 000's % Last Pub W3 2005 Last Pub W3 2005 000's % Last Pub W3 2005 Last Pub W3 2005 Brighton's Juice 107.2 287 287 0 0% 30 28 -2 -7% 10% 10% 293 211 -82 -28% 9.8 7.5 3.8% 2.7% Total Chrysalis Radio (UK) 49377 49377 0 0% 6160 6191 31 1% 12% 13% 51908 53566 1658 3% 8.4 8.7 4.9% 5.0% Chrysalis Radio (ILR) 24893 24897 4 0% 5510 5501 -9 0% 22% 22% 47559 49079 1520 3% 8.6 8.9 9.0% 9.3% The Arrow (UK) 49377 49377 0 0% 79 79 0 0% *% *% 784 306 -478 -61% 10.0 3.9 0.1% *% Galaxy Network (UK) 49377 49377 0 0% 2539 2560 21 1% 5% 5% 17592 20398 2806 16% 6.9 8.0 1.6% 1.9% Galaxy Network (ILR) 11083 11087 4 0% 2160 2186 26 1% 19% 20% 15968 17006 1038 7% 7.4 7.8 7.0% 7.4% Galaxy Manchester 2722 2722 0 0% 419 453 34 8% 15% 17% 3029 3202 173 6% 7.2 7.1 5.4% 5.6% Galaxy Birmingham 2016 2016 0 0% 337 353 16 5% 17% 18% 2091 2683 592 28% 6.2 7.6 4.8% 5.9% Galaxy Yorkshire 4226 4226 0 0% 882 915 33 4% 21% 22% 6525 7035 510 8% 7.4 7.7 7.4% 7.8% Galaxy North East 2120 2124 4 0% 521 465 -56 -11% 25% 22% 4323 4086 -237 -5% 8.3 8.8 10.6% 10.3% Total Heart (UK) 49377 49377 0 0% 3079 3255 176 6% 6% 7% 22991 25780 2789 12% 7.5 7.9 2.2% 2.4% Heart FM (ILR) 15826 15826 0 0% 2926 2868 -58 -2% 18% 18% 23332 22620 -712 -3% 8.0 7.9 6.8% 6.7% 100.7 Heart FM 3461 3461 0 0% 866 778 -88 -10% 25% 22% 6782 6923 141 2% 7.8 8.9 9.0% 9.0% Heart -

Independent Radio (Alphabetical Order) Frequency Finder
Independent Radio (Alphabetical order) Frequency Finder Commercial and community radio stations are listed together in alphabetical order. National, local and multi-city stations A ABSOLUTE RADIO CLASSIC ROCK are listed together as there is no longer a clear distinction Format: Classic Rock Hits Broadcaster: Bauer between them. ABBEY 104 London area, Surrey, W Kent, Herts, Luton (Mx 3) DABm 11B For maps and transmitter details see: Mixed Format Community Swansea, Neath Port Talbot and Carmarthenshire DABm 12A • Digital Multiplexes Sherborne, Dorset FM 104.7 Shropshire, Wolverhampton, Black Country b DABm 11B • FM Transmitters by Region Birmingham area, West Midlands, SE Staffs a DABm 11C • AM Transmitters by Region ABC Coventry and Warwickshire DABm 12D FM and AM transmitter details are also included in the Mixed Format Community Stoke-on-Trent, West Staffordshire, South Cheshire DABm 12D frequency-order lists. Portadown, County Down FM 100.2 South Yorkshire, North Notts, Chesterfield DABm 11C Leeds and Wakefield Districts DABm 12D Most stations broadcast 24 hours. Bradford, Calderdale and Kirklees Districts DABm 11B Stations will often put separate adverts, and sometimes news ABSOLUTE RADIO East Yorkshire and North Lincolnshire DABm 10D and information, on different DAB multiplexes or FM/AM Format: Rock Music Tees Valley and County Durham DABm 11B transmitters carrying the same programmes. These are not Broadcaster: Bauer Tyne and Wear, North Durham, Northumberland DABm 11C listed separately. England, Wales and Northern Ireland (D1 Mux) DABm 11D Greater Manchester and North East Cheshire DABm 12C Local stations owned by the same broadcaster often share Scotland (D1 Mux) DABm 12A Central and East Lancashire DABm 12A overnight, evening and weekend, programming. -

New Titles 2020
Aster Australian Women’s Weekly Cassell Conran Endeavour Gaia OCTOPUS PUBLISHING GROUP Gods eld Hamlyn Ilex New Titles Kyle Miller’s 2020 Mitchell Beazley January - June Monoray Philip’s New Titles Pyramid Spruce | 2020 NEW TITLES NEW January - June The very best in non-ction JANUARY JUNE publishing Octopus Publishing Group Carmelite House 50 Victoria Embankment London EC4Y 0DZ T +44 (0)20 3122 6400 F +44 (0)20 8283 9704 www.octopusbooks.co.uk ISBN: 9780600636700 Contacts ead ce South idland orthern reland Foreign ight gent itriutor Ian Williamson Carmelite House epulic reland Veronique de Sutter T +44 (0)7768 764 397 merica 50 Victoria Embankment Hachette Book Group Ireland France, erman and ueec [email protected] nited State London T +353 1 824 6288 T +44 (0)20 3122 6767 Octopus Books USA EC4Y 0DZ veronique.desutter@octopusbooks. Scotland he orth c/o Hachette Book Group USA T 020 3122 6400 Jim Binchy – Managing Director, co.uk Jack Dennison Attn: Order department F 020 8283 9704 Sales & Marketing T +44 (0)7771 814 916 185 N. Mt Zion Rd www.octopusbooks.co.uk [email protected] Lana de Lucia [email protected] Lebanon, IN 46052 olland, entral Eatern Europe USA UK Trade Sales Enquiries Siobhan Tierney – Sales Manager and reece or call Customer Service: [email protected] [email protected] T +44 (0)20 3122 7160 T +1 800 759 0190 Special Sale Enuirie T +44 (0)7849 607 136 T +1 800 286 9471 UK Regional Sales Team [email protected] Bernard Hoban – Commercial [email protected] Manager Canada roup Field Sale irector [email protected] Marco Rodino Dominic Smith ulicit areting Canadian Manda Group ia inc apan 664 Annette St. -
RDE 2017 Programme 10
Radiodays Europe 2017 A Sound Future Amsterdam 19-21 March 2017 Conference Programme (More sessions and speakers will be added) V10 20170207 Radiodays Europe 2017 – Official Opening: A Sound Future In this opening session we’ll welcome everyone to Radiodays Europe 2017 in Amsterdam and set the agenda for the coming 2 days. What are the big themes for radio this year? How is our industry changing? And what great ideas and innovation can we celebrate and share? We’ll hear from some of the major organisations representing the radio industry in Europe and from our hosts in the Netherlands, plus we’ll get a perspective from both public service broadcasters and private radio companies alike. Welcoming addresses: Menno Koningsberger (CEO, Talpa Radio, the Netherlands), Graham Dixon (Head of radio, EBU, Switzerland), Stefan Möller (President, AER, Finland) >>Keynotes and content in the opening session will be announced later. Hosts: Paul Robinson (UK) and Annemieke Schollart (NL) The new BBC radio director in conversation Bob Shennan (Head of radio, BBC, UK) BBC Radio is by many seen as the ‘gold standard’ of radio broadcasting, with a wide range of services reaching over 34 Million listeners across the UK each week. In the face of increasing digital competition and changing audience habits, the BBC aims to maintain its reach and share by focusing on high-quality, distinctive programming, creative partnerships and digital innovation. The newly appointed Director of Radio - Bob Shennan, appearing for the first time at Radiodays Europe, will set out his vision for the future of BBC Radio and discuss the challenges for the industry that lie ahead in conversation with John Myers, UK. -

BBC Television
Independent Radio (Alphabetical order) Frequency Finder Commercial and community radio stations are listed together in alphabetical order. National, local and multi-city A ABSOLUTE RADIO 90S stations are listed together as there is no longer a clear Format: 90s Rock and Pop Music distinction between them. ABBEY 104 Broadcaster: Bauer For maps and transmitter details see: Mixed Format Community England, Wales and Northern Ireland (D1 Mux) DABm 11D Digital Multiplexes Sherborne, Dorset FM 104.7 Scotland (D1 Mux) DABm 12A London area, Surrey, W Kent, Herts, Luton (Mx 1) DABm 12C FM Transmitters by Region ABC AM Transmitters by Region Birmingham area, West Midlands, SE Staffs DABm 11C FM and AM transmitter details are also included in the Mixed Format Community South Yorkshire, North Notts, Chesterfield DABm 11C frequency-order lists. Portadown, County Down FM 100.2 Leeds and Wakefield Districts DABm 12D East Yorkshire and North Lincolnshire DABm 11B Most stations broadcast 24 hours. ABN RADIO Tees Valley and County Durham DABm 11B Stations will often put separate adverts, and sometimes news African Independent Tyne and Wear, North Durham, Northumberland DABm 11C and information, on different DAB multiplexes or FM/AM London area, Surrey, W Kent, Herts, Luton (Mx 3) DABm 11B Greater Manchester and North East Cheshire DABm 12C transmitters carrying the same programmes. These are not Central and East Lancashire DABm 12A listed separately. ABSOLUTE RADIO Merseyside and West Cheshire DABm 10C Local stations owned by the same broadcaster often share Glasgow, Clydeside, Lanarkshire, Stirling, Falkirk DABm 11C Format: Rock Music overnight, evening and weekend, programming. Edinburgh, Lothian and South Fife DABm 12D Broadcaster: Bauer Dundee, Angus, Perth & Kinross, North Fife DABm 11B Many stations broadcast different formats from that listed for England, Wales and Northern Ireland (D1 Mux) DABm 11D Inverness area DABm 12D a few hours a week in the evenings and weekend Scotland (D1 Mux) DABm 12A Northern Ireland DABm 12D afternoons. -

Broadcast Bulletin Issue Number 164 23/08/10
Ofcom Broadcast Bulletin Issue number 164 23 August 2010 1 Ofcom Broadcast Bulletin, Issue 164 23 August 2010 Contents Introduction 5 Standards cases In Breach Special Live With Jassi Khangura The Sikh Channel, 2 May 2010, 18:45 6 The Circle Wedding TV, 23 to 30 April 2010, 00:00 to 01:00 and 10:00 to 11:00 daily 9 The Raj Show Raaj FM, 27 April 2010, 11:00 12 Bang Babes Tease Me TV 2, 22 May 2010, 03:35 to 04:00 15 Early Bird Tease Me TV (Freeview) 3 June 2010, 05:45 to 06.30 and 08:00 to 09:00 19 18 Keen Tease Me, 10 June 2010, 21:30 to 22:30 22 Live XXX Babes Live XXX Babes, 31 March 2010, 22:00 to 23.00 Live XXX Babes Live XXX Babes, 1 April 2010, 22:00 to 22:24 Sport XXX Babes Sport XXX Babes, 3 April 2010, 22:00 to 02:00 Northern Birds Northern Birds, 11 April 2010, 22:30 to 23:00 Sport XXX Babes Sport XXX Babes, 16 May 2010, 21:00 to 21:30 Sport XXX Babes Sport XXX Babes, 19 May 2010, 00:00 to 01:00 25 The Naked Office Virgin 1, 5 June 2010, 20:00 30 Provision of recordings MATV, 5 June 2010, 21:30 and 6 June 2010, 22:00 32 2 Ofcom Broadcast Bulletin, Issue 164 23 August 2010 Advertising scheduling cases In Breach Advertising scheduling The Africa Channel, 20 April 2010, various 34 Resolved Advertising scheduling ITV1 HD, 12 June 2010, 19:34 35 Advertising scheduling Lava, various 37 Advertising scheduling Channel Starz, various Channel AKA, various 38 Advertising minutage STV, 24 May 2010, 19:00 39 Advertising minutage Attheraces, 3 June 2010, 22:00 40 Advertising scheduling Quest, 3 May 2010, 14:00 41 Fairness & Privacy cases -

RDE 2017 Programme 24
Radiodays Europe 2017 “A Sound Future” Amsterdam 19-21 March 2017 Conference Programme (Sunday sessions/masterclasses at the end) V24 20170317 Monday 20 March 9.00-9.55 Track 1 Auditorium Radiodays Europe 2017 – Official Opening: A Sound Future Welcome to Radiodays Europe 2017 in Amsterdam! What are the big themes for radio this year? How is our industry changing? And what great ideas and innovations can we celebrate and share? We’ll hear from some of the major organisations representing the radio industry in Europe and from our partner hosts in the Netherlands. Be prepared for a fast paced session with engaging topics and some challenge to your senses as well. Don´t miss this exciting opening session, which will be a bit different from what you might expect. Welcoming addresses: Graham Dixon (Head of Radio, EBU, Switzerland), Stefan Möller (President, AER, Finland), Anders Held (Manager and Co-founder, Radiodays Europe, Sweden) Radio industry keynote: Menno Koningsberger (CEO, Talpa Radio, the Netherlands) Thematic keynotes: Safe and sound Hannah Storm (Director, International News Safety Institute, UK ) Combatting fake news Joel Sucherman (Senior Director Digital Products, NPR, USA) Challenge your senses: MINDF*CK Victor Mids (Illusionist and doctor, the Netherlands) The power of sound David Lloyd (Radio moments, UK) Hosts: Paul Robinson (UK) and Annemieke Schollaardt (NL) 10.10-10.50 Track 1 Auditorium The new BBC radio director in conversation Bob Shennan (Director Radio and Music, BBC, UK) BBC Radio is seen by many as the ‘gold standard’ for radio broadcasting, with a wide range of services reaching over 34 million listeners across the UK each week. -
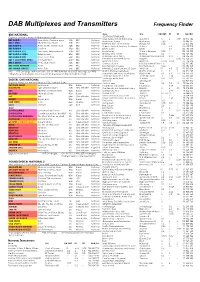
DAB Multiplexes and Transmitters Frequency Finder
DAB Multiplexes and Transmitters Frequency Finder BBC NATIONAL Area Site kW: BBC D1 SD Grid Ref SOUTH EAST ENGLAND England, Scotland, Wales, Northern Ireland (12B) West Surrey and NE Hampshire Guildford 5 5 4.89 SU 975 486 BBC RADIO 1 New Music, Contemporary 128s BBC National Haslemere, Surrey Haslemere 0.63 - - SU 886 331 BBC 1 XTRA Rhythmic New Music 128s BBC National NE Hampshire and Farnham Hungry Hill 0.08 1 - SU 824 490 BBC RADIO 2 Adult, Oldies, Mixed Music 128s BBC National Staines, Ashford, Sunbury, Heathrow Staines - 0.3 - TQ 038 718 BBC RADIO 3 Classical 192s* BBC National Esher, Surrey Esher - 0.3 - TQ 150 638 BBC RADIO 4 (FM) Talk, News, Entertainment 128s* BBC National North Surrey Stoke d’Abernon 0.05 1 - TQ 135 590 BBC RADIO 4 EXTRA Entertainment 80m BBC National Dorking area, Surrey Dorking 0.2 - - TQ 169 482 BBC RADIO 5 LIVE News, Sport, Talk 64m BBC National Caterham area, Surrey Caterham Old Pk Wd 2.4 0.14 - TQ 336 534 East Surrey and North Sussex Reigate 1 1 0.96 TQ 256 521 BBC 5 LIVE SPORTS EXTRA Sport part time 64m* BBC National Horsham, Sussex Horsham 0.024 0.024 - TQ 176 308 BBC 6 MUSIC Rock, Mixed Music 128s BBC National Crawley, Sussex Little Prestwood Farm 1.2 - - TQ 235 385 BBC ASIAN NETWORK Asian 64m BBC National East Grinstead, Sussex East Grinstead 0.64 - - TQ 386 360 BBC WORLD SERVICE News, Talk 64m BBC National NW Kent, Eastern London, SE Essex Wrotham 10 4.5 25 TQ 595 604 BBC 97% Coverage with new trans On-air 1995 (London area, 65% coverage by 1998) Dartford Tunnel, Kent-Essex Dartford Tunnel ? ? ? TQ -
![Neutral Citation Number: [2008] EWHC 2927 (QB) Case No: HQ08X02765 in the HIGH COURT of JUSTICE QUEEN's BENCH DIVISION](https://docslib.b-cdn.net/cover/8509/neutral-citation-number-2008-ewhc-2927-qb-case-no-hq08x02765-in-the-high-court-of-justice-queens-bench-division-12078509.webp)
Neutral Citation Number: [2008] EWHC 2927 (QB) Case No: HQ08X02765 in the HIGH COURT of JUSTICE QUEEN's BENCH DIVISION
Neutral Citation Number: [2008] EWHC 2927 (QB) Case No: HQ08X02765 IN THE HIGH COURT OF JUSTICE QUEEN'S BENCH DIVISION Royal Courts of Justice Strand, London, WC2A 2LL Date: 1 December 2008 Before : THE HONOURABLE MR JUSTICE EADY - - - - - - - - - - - - - - - - - - - - - Between : TISCALI UK LIMITED Claimant - and - BRITISH TELECOMMUNICATIONS PLC Defendant - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Richard Spearman QC and Matthew Nicklin (instructed by Schillings ) for the Claimant Ronald Thwaites QC and John Samson (instructed by BT Legal & Business Services ) for the Defendant Hearing date: 14 November 2008 - - - - - - - - - - - - - - - - - - - - - Judgment Mr Justice Eady : 1. The Claimant in these proceedings is Tiscali UK Limited, part of a large group of telecommunications companies based in Italy. The Defendant is British Telecommunications Plc, which is a rival of the Claimant in the provision of broadband internet within the United Kingdom. It is accepted that the Defendant is dominant in the market. 2. Reports were published in January of this year suggesting that the Claimant’s business was a potential takeover target. My attention was drawn, for example, to an article in the Financial Times on 23 January 2008 which was headed “Tiscali boss expects to be targeted by rivals” and began with the following two paragraphs: “Tiscali, the Milan-listed company that supplies broadband in the UK and Italy, expects its businesses to be bought up by rivals in the next two years, according to Tommaso Pompei, its chief executive. Mr Pompei said he did not see many opportunities for Tiscali to buy rivals, and therefore it was more likely that the company’s UK and Italian broadband operations would be sold.” 3.