On the Universality of Intonational Phrases: a Cross- Linguistic Interrater Study
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Developments of Affectedness Marking
Language & Linguistics in Melanesia Vol. 31 No. 1, 2013 ISSN: 0023-1959 Journal of the Linguistic Society of Papua New Guinea ISSN: 0023-1959 Vol. 31 No. 1, 2013 0 Language & Linguistics in Melanesia Vol. 31 No. 1, 2013 ISSN: 0023-1959 Towards a Papuan history of languages MARK DONOHUE Department of Linguistics, College of Asia and the Pacific, Australian National University [email protected] 1. Introduction and overview In this paper, I raise one simple point that must be taken into account when considering the history of the ‘Papuan’ languages – namely, the scope of the term ‘Papuan’. I shall argue that ‘Papuan’ is a term that logically should include many languages that have generally been discussed as being ‘Austronesian’. While much detailed work has been carried out on a number of ‘Papuan’ language families, the fact that they are separate families, and are not believed to be related to each other (in the sense of the comparative method) any more than they are to the Austronesian languages which largely surround their region, means that they cannot be considered without reference to those Austronesian languages. I will argue that many of the Austronesian languages which surround the Papuan region (see the appendix) can only be considered to be ‘Austronesian’ in a lexical sense. Since historical linguistics puts little value on simple lexical correspondences in the absence of regular sound correspondences, and regularity of sound correspondence is lacking in the Austronesian languages close to New Guinea, we cannot consider these languages to be ‘fully’ Austronesian. We must therefore consider a Papuan history that is much more widespread than usually conceived. -

Some Principles of the Use of Macro-Areas Language Dynamics &A
Online Appendix for Harald Hammarstr¨om& Mark Donohue (2014) Some Principles of the Use of Macro-Areas Language Dynamics & Change Harald Hammarstr¨om& Mark Donohue The following document lists the languages of the world and their as- signment to the macro-areas described in the main body of the paper as well as the WALS macro-area for languages featured in the WALS 2005 edi- tion. 7160 languages are included, which represent all languages for which we had coordinates available1. Every language is given with its ISO-639-3 code (if it has one) for proper identification. The mapping between WALS languages and ISO-codes was done by using the mapping downloadable from the 2011 online WALS edition2 (because a number of errors in the mapping were corrected for the 2011 edition). 38 WALS languages are not given an ISO-code in the 2011 mapping, 36 of these have been assigned their appropri- ate iso-code based on the sources the WALS lists for the respective language. This was not possible for Tasmanian (WALS-code: tsm) because the WALS mixes data from very different Tasmanian languages and for Kualan (WALS- code: kua) because no source is given. 17 WALS-languages were assigned ISO-codes which have subsequently been retired { these have been assigned their appropriate updated ISO-code. In many cases, a WALS-language is mapped to several ISO-codes. As this has no bearing for the assignment to macro-areas, multiple mappings have been retained. 1There are another couple of hundred languages which are attested but for which our database currently lacks coordinates. -

Four Undocumented Languages of Raja Ampat, West Papua, Indonesia
Language Documentation and Description ISSN 1740-6234 ___________________________________________ This article appears in: Language Documentation and Description, vol 17. Editor: Peter K. Austin Four undocumented languages of Raja Ampat, West Papua, Indonesia LAURA ARNOLD Cite this article: Arnold, Laura. 2020. Four undocumented languages of Raja Ampat, West Papua, Indonesia. In Peter K. Austin (ed.) Language Documentation and Description 17, 25-43. London: EL Publishing. Link to this article: http://www.elpublishing.org/PID/180 This electronic version first published: July 2020 __________________________________________________ This article is published under a Creative Commons License CC-BY-NC (Attribution-NonCommercial). The licence permits users to use, reproduce, disseminate or display the article provided that the author is attributed as the original creator and that the reuse is restricted to non-commercial purposes i.e. research or educational use. See http://creativecommons.org/licenses/by-nc/4.0/ ______________________________________________________ EL Publishing For more EL Publishing articles and services: Website: http://www.elpublishing.org Submissions: http://www.elpublishing.org/submissions Four undocumented languages of Raja Ampat, West Papua, Indonesia Laura Arnold University of Edinburgh Summary Salawati, Batta, Biga, and As are four undocumented Austronesian languages belonging to the Raja Ampat-South Halmahera branch of South Halmahera- West New Guinea, spoken in West Papua province, Indonesia. Salawati, Batta, and Biga are spoken in the Raja Ampat archipelago, just off the western tip of the Bird’s Head peninsula of New Guinea, and As is spoken nearby on the New Guinea mainland. All four languages are to some degree endangered, as speakers shift to Papuan Malay, the local lingua franca: Biga is the most vital of the four languages, in that children are still acquiring it, whereas As is moribund, with only a handful of speakers remaining. -
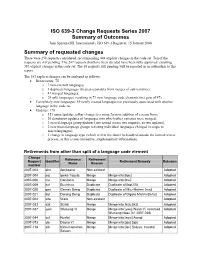
2007 Series Change Requests Report
ISO 639-3 Change Requests Series 2007 Summary of Outcomes Joan Spanne (SIL International), ISO 639-3 Registrar, 15 January 2008 Summary of requested changes There were 258 requests considered, recommending 404 explicit changes in the code set. Ten of the requests are still pending. The 247 requests that have been decided have been fully approved, entailing 383 explicit changes in the code set. The 10 requests still pending will be reported in an addendum to this report. The 383 explicit changes can be analyzed as follows: • Retirements: 75 o 7 non-existent languages; o 3 duplicate languages (treated separately from merges of sub-varieties); o 41 merged languages; o 24 split languages, resulting in 71 new language code elements (net gain of 47). • Completely new languages: 59 newly created languages not previously associated with another language in the code set. • Updates: 178 o 151 name updates, either change to a name form or addition of a name form; o 20 denotation updates of languages into which other varieties were merged; o 3 macrolanguage group updates (one spread across two requests, as two updates); o 2 new macrolanguage groups (existing individual languages changed in scope to macrolanguages); o 1 change in language type (which will in the future be handled outside the formal review process, as this is non-normative, supplementary information). Retirements from other than split of a language code element Change Reference Retirement Request Identifier Retirement Remedy Outcome Name Reason number 2007-003 akn Amikoana Non-existent Adopted 2007-004 paj Ipeka-Tapuia Merge Merge into [kpc] Adopted 2007-006 cru Carútana Merge Merge into [bwi] Adopted 2007-009 bxt Buxinhua Duplicate Duplicate of [bgk] Bit Adopted 2007-020 gen Geman Deng Duplicate Duplicate of Miju-Mishmi [mxj] Adopted 2007-021 dat Darang Deng Duplicate Duplicate of Digaro Mishmi [mhu] Adopted 2007-024 wre Ware Non-existent Adopted 2007-033 szk Sizaki Merge Merge into Ikizu [ikz] Adopted 2007-037 ywm Wumeng Yi Merge Merge into [ywu] Wusa Yi, renamed Adopted Wumeng Nasu (cf. -

Papuan Malay – a Language of the Austronesian- Papuan Contact Zone
Journal of the Southeast Asian Linguistics Society JSEALS 14.1 (2021): 39-72 ISSN: 1836-6821, DOI: http://hdl.handle.net/10524/52479 University of Hawaiʼi Press PAPUAN MALAY – A LANGUAGE OF THE AUSTRONESIAN- PAPUAN CONTACT ZONE Angela Kluge SIL International [email protected] Abstract This paper describes the contact features that Papuan Malay, an eastern Malay variety, situated in East Nusantara, the Austronesian-Papuan contact zone, displays under the influence of Papuan languages. This selection of features builds on previous studies that describe the different contact phenomena between Austronesian and non-Austronesian languages in East Nusantara. Four typical western Austronesian features that Papuan Malay is lacking or making only limited use of are examined in more detail: (1) the lack of a morphologically marked passive voice, (2) the lack of the clusivity distinction in personal pronouns, (3) the limited use of affixation, and (4) the limited use of the numeral-noun order. Also described in more detail are six typical Papuan features that have diffused to Papuan Malay: (1) the genitive-noun order rather than the noun-genitive order to express adnominal possession, (2) serial verb constructions, (3) clause chaining, and (4) tail-head linkage, as well as (5) the limited use of clause-final conjunctions, and (6) the optional use of the alienability distinction in nouns. This paper also briefly discusses whether the investigated features are also present in other eastern Malay varieties such as Ambon Malay, Maluku Malay and Manado Malay, and whether they are inherited from Proto-Austronesian, and more specifically from Proto-Malayic. By highlighting the unique features of Papuan Malay vis-à-vis the other East Nusantara Austronesian languages and placing the regional “adaptations” of Papuan Malay in a broader diachronic perspective, this paper also informs future research on Papuan Malay. -

Abbi, Anvita. 2013. a Grammar of the Great Andamanese Language: an Ethnolinguistic Study
Abbi, Anvita. 2013. A grammar of the Great Andamanese language: An ethnolinguistic study. Leiden/Boston: Brill. Adelaar, Alexander. 2011. Siraya: Retrieving the phonology, grammar and lexicon of a dormant Formosan language. Berlin: Mouton de Gruyter. Aguilera, Oscar E. 2001. Gramática de la lengua kawésqar. Temuco: Corporación de Desarrollo Indígena. Ahland, Michael B. 2012. A grammar of Northern Mao (Màwés Aas’è). Eugene: University of Oregon PhD dissertation. Aikhenvald, Alexandra Y. 2003. A grammar of Tariana, from northwest Amazonia. Cambridge: Cambridge Univerity Press. Aikhenvald, Alexandra Y. 2008. The Manambu language of East Sepik, Papua New Guinea. Oxford: Oxford University Press. Alfira, David A., Timothy K. Kafi, Hassan K. kaki, Ali A. Hasan, Anjo K. Anjo, Dayan K. Jas & Sadik K. Sarukh. 2016. Caning grammar book. Khartoum: Trial Edition, Sudan Workshop Program. Alnet, Aimee J. 2009. The clause structure of the Shimaore dialect of Comorian (Bantu). Urbana: University of Illinois PhD dissertation. Anderson, Judi L. 1989. Comaltepec Chinantec syntax. Dallas: Summer Institute of Linguistics, University of Texas at Arlington. Andronov, Mikhail S. 2001. A grammar of the Brahui language in comparative treatment. Munich: Lincom Europa. Årsjö, Britten. 2016. Konai reference grammar. Ukarumpa: Summer Institute of Linguistics. Austin, Peter K. 1981. A grammar of Diyari, South Australia. Cambridge: Cambridge University Press. Austing, John F. & Randolph Upia. 1975. Highlights of Ömie morphology. In Tom E. Dutton (ed.), Studies in languages of central and south-east Papua, 513-598. Canberra: Australian National University. Bader, Christian. 2008. Parlons karimojong: Une langue de l’Afrique orientale. Paris: L’Harmattan. Banks, Jonathan. 2007. The verbal morphology of Santiam Kalapuya. -

29#Suprasegmental#Phonology
29#Suprasegmental#phonology Daniel Kaufman (Queens College, CUNY & ELA) & Nikolaus P. Himmelmann (Universität zu Köln) This%chapter%examines%what%is%an%under2researched%field%encompassing%stress,%tone,% and% intonation.% Apart% from% summarizing% the% relatively% little% that% is% known% about% intonation%in%the%area%under%scrutiny,%the%chapter%is%primarily%concerned%with%stress% systems.%Of%particular%interest%is%that%recent%research%has%suggested%that%for%several% western%Austronesian%languages,%including%most%notably%Indonesian,%stress%is%entirely% absent.% The% sporadic% appearance% of% tone% in% western% Austronesian% languages% (including%Chamic%and%West%New%Guinea)%is%notable%for%the%variety%of%tonal%systems% found%and%the%role%of%contact%with%non2Austronesian%tonal%languages.% 1.0 Introduction In this chapter, we investigate stress, tone and intonation as it relates to western Austronesian languages and offer a typological overview of the region’s prosodic systems. A major focus of the chapter is on the difficulties posed by Austronesian languages for canonical analyses of stress systems. Although the stress systems of many Austronesian languages have been described and most grammars contain a short note on stress, these descriptions have been almost entirely impressionistic. It is now clear that perception biases have colored these impressions and, as a result, wide swaths of the descriptive literature. A small body of work examines this problem with regard to Malay varieties and concludes that several of these varieties, contrary to traditional descriptions, show no word stress at all. On this analysis, typical correlates of stress, i.e. prominence in pitch, duration and intensity, originate on the phrase level rather than the word level. -

Stress Predictors in a Papuan Malay Random Forest
STRESS PREDICTORS IN A PAPUAN MALAY RANDOM FOREST Constantijn Kaland1, Nikolaus P. Himmelmann1, Angela Kluge2 1Institute of Linguistics, University of Cologne, Germany 2SIL International {ckaland, sprachwissenschaft}@uni-koeln.de, [email protected] ABSTRACT penultimate syllable. This distribution makes Papuan Malay similar to other Trade Malay varieties [16] The current study investigates the phonological where stress has been reported to be mostly factors that determine the location of word stress in penultimate; e.g. Manado [25], Kupang [23], Papuan Malay, an under-researched language Larantuka [12] and the North Moluccan varieties spoken in East-Indonesia. The prosody of this Tidore [30] and Ternate [14]. Similarly, varieties of language is poorly understood, in particular the use Indonesian have been analysed as having of word stress. The approach taken here is novel in penultimate stress. Work on Indonesian has shown that random forest analysis was used to assess which the importance of distinguishing language varieties. factors are most predictive for the location of stress Where Toba Batak listeners rated manipulated stress in a Papuan Malay word. The random forest analysis cues as less acceptable when these did not occur on was carried out with a set of 17 potential word stress the penultimate syllable, Javanese listeners had no predictors on a corpus of 1040 phonetically preference whatsoever [4]. transcribed words. A complementary analysis of As for the Trade Malay varieties, Ambonese word stress distributions was done in order to derive appeared to not make use of word stress [15], a set of phonological criteria. Results show that with counter to earlier claims [29]. -

On the Perception of Prosodic Prominences and Boundaries in Papuan Malay
Chapter 13 On the perception of prosodic prominences and boundaries in Papuan Malay Sonja Riesberg Universität zu Köln & Centre of Excellence for the Dynamics of Language, The Australian National University Janina Kalbertodt Universität zu Köln Stefan Baumann Universität zu Köln Nikolaus P. Himmelmann Universität zu Köln This paper reports the results of two perception experiments on the prosody ofPapuan Malay. We investigated how native Papuan Malay listeners perceive prosodic prominences on the one hand, and boundaries on the other, following the Rapid Prosody Transcription method as sketched in Cole & Shattuck-Hufnagel (2016). Inter-rater agreement between the participants was shown to be much lower for prosodic prominences than for boundaries. Importantly, however, the acoustic cues for prominences and boundaries largely overlap. Hence, one could claim that inasmuch as prominence is perceived at all in Papuan Malay, it is perceived at boundaries, making it doubtful whether prosodic prominence can be usefully distinguished from boundary marking in this language. Our results thus essentially confirm the results found for Standard Indonesian by Goedemans & van Zanten (2007) and vari- ous claims regarding the production of other local varieties of Malay; namely, that Malayic varieties appear to lack stress (i.e. lexical stress as well as post-lexical pitch accents). Sonja Riesberg, Janina Kalbertodt, Stefan Baumann & Nikolaus P. Himmelmann. 2018. On the perception of prosodic prominences and boundaries in Papuan Malay. In Sonja Riesberg, Asako Shiohara & Atsuko Utsumi (eds.), Perspectives on informa- tion structure in Austronesian languages, 389–414. Berlin: Language Science Press. DOI:10.5281/zenodo.1402559 S. Riesberg, J. Kalbertodt, S. Baumann & N. -

Prosodic Systems: Austronesian Nikolaus P
1 Prosodic systems: Austronesian Nikolaus P. Himmelmann (Universität zu Köln) & Daniel Kaufman (Queens College, CUNY & ELA) 30.1 Introduction Figure 1. The Austronesian family tree (Blust 1999, Ross 2008) Austronesian languages cover a vast area, reaching from Madagascar in the west to Hawai'i and Easter Island in the east. With close to 1300 languages, over 550 of which belong to the large Oceanic subgroup spanning the Pacific Ocean, they constitute one of the largest well- established phylogenetic units of languages. While a few Austronesian languages, in particular Malay in its many varieties and the major Philippine languages, have been documented for some centuries, most of them remain underdocumented and understudied. The major monographic reference work on Austronesian languages is Blust (2013). Adelaar & Himmelmann (2005) and Lynch, Crowley & Ross (2005) provide language sketches as well as typological and historical overviews for the non-Oceanic and Oceanic Austronesian languages, respectively. Major nodes in the phylogenetic structure of the Austronesian family are shown in Figure 1 (see Blust 2013: chapter 10 for a summary). Following Ross (2008), the italicized groupings in Figure 1 are not valid phylogenetic subgroups, but rather collections of subgroups whose relations have not yet been fully worked out. The groupings in boxes, on the other hand, are thought to represent single proto-languages and have been partially reconstructed using the comparative method. Most of languages mentioned in the chapter belong to the Western Malayo-Polynesian linkage, which includes all the languages of the Philippines and, with a few exceptions, Indonesia. When dealing with languages from other branches, this is explicity noted. -

The Uniqueness Formation of Papuan Malay in Morphologically
The Uniqueness formation of Papuan Malay in Morphologically JELTL (Journal of English Language Teaching and Linguistics) e-ISSN: 2502-6062, p-ISSN: 2503-1848 2018, Vol. 3 (2) www.jeltl.org The Uniqueness Formation of Papuan Malay in Morphologically Herlandri Eka Jayaputri Magister Program of Applied Linguistics, Yogyakarta State University Colombo Street No.1, Caturtunggal, Depok, Yogyakarta 55281, Indonesia [email protected] Dwiyanto Djoko Pranowo Magister Program of Applied Linguistics, Yogyakarta State University Colombo Street No.1, Caturtunggal, Depok, Yogyakarta 55281, Indonesia [email protected] Abstract Indonesia has many Malay speakers and it spreads to Papua with the influence of Ambon and Indonesian becomes one of the variations in the Papuan Malay dialect. Papuan itself is the home of 275 languages that are 218 non-Austronesian or Papuan (79%) and 57 languages are Austronesian (21%) (Lewis et al. 2013 cited in Kludge, 2014). Moreover the influence of Ambon and the North Moluccan Malay, and Indonesia played an important role especially in the formation of Papuan Malay (Paauw, 2009). Papuan Malay language is spoken by the inhabitants of the West Papua and uses as the daily language (Kludge, 2014). The formation of Papuan Malay has the uniqueness because it deletes some syllables but does not have the impact of the meaning. This study aims to know and explain the process of clipping word of Papuan Malay as well as their word classes. The Data come from the video of MOB Papua. Besides that, the method used in this study is a Padan method with comparing of other langue. Therefore, this study appears the history and the role of Papuan Malay as well as compare the Indonesian with Papua Malay to find the clipping word process in Papuan Malay. -

Language Distinctiveness*
RAI – data on language distinctiveness RAI data Language distinctiveness* Country profiles *This document provides data production information for the RAI-Rokkan dataset. Last edited on October 7, 2020 Compiled by Gary Marks with research assistance by Noah Dasanaike Citation: Liesbet Hooghe and Gary Marks (2016). Community, Scale and Regional Governance: A Postfunctionalist Theory of Governance, Vol. II. Oxford: OUP. Sarah Shair-Rosenfield, Arjan H. Schakel, Sara Niedzwiecki, Gary Marks, Liesbet Hooghe, Sandra Chapman-Osterkatz (2021). “Language difference and Regional Authority.” Regional and Federal Studies, Vol. 31. DOI: 10.1080/13597566.2020.1831476 Introduction ....................................................................................................................6 Albania ............................................................................................................................7 Argentina ...................................................................................................................... 10 Australia ....................................................................................................................... 12 Austria .......................................................................................................................... 14 Bahamas ....................................................................................................................... 16 Bangladesh ..................................................................................................................