Diacritics Restoration Using Neural Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Optical Character Recognition - a Combined ANN/HMM Approach
Optical Character Recognition - A Combined ANN/HMM Approach Dissertation submitted to the Department of Computer Science Technical University of Kaiserslautern for the fulfillment of the requirements for the doctoral degree Doctor of Engineering (Dr.-Ing.) by Sheikh Faisal Rashid Dean: Prof. Dr. Klaus Schneider Thesis supervisors: Prof. Dr. Thomas Breuel, TU Kaiserslautern Prof. Dr. Andreas Dengel, TU Kaiserslautern Chair of supervisory committee: Prof. Dr. Karsten Berns, TU Kaiserslautern Kaiserslautern, 11 July, 2014 D 386 Abstract Optical character recognition (OCR) of machine printed text is ubiquitously considered as a solved problem. However, error free OCR of degraded (broken and merged) and noisy text is still challenging for modern OCR systems. OCR of degraded text with high accuracy is very important due to many applications in business, industry and large scale document digitization projects. This thesis presents a new OCR method for degraded text recognition by introducing a combined ANN/HMM OCR approach. The approach provides significantly better performance in comparison with state-of-the-art HMM based OCR methods and existing open source OCR systems. In addition, the thesis introduces novel applications of ANNs and HMMs for document image preprocessing and recognition of low resolution text. Furthermore, the thesis provides psychophysical experiments to determine the effect of letter permutation in visual word recognition of Latin and Cursive script languages. HMMs and ANNs are widely employed pattern recognition paradigms and have been used in numerous pattern classification problems. This work presents a simple and novel method for combining the HMMs and ANNs in application to segmentation free OCR of degraded text. HMMs and ANNs are powerful pattern recognition strategies and their combination is interesting to improve current state-of-the-art research in OCR. -

Cap Height Body X-Height Crossbar Terminal Counter Bowl Stroke Loop
Cap Height Body X-height -height is the distance between the -Cap height refers to the height of a -In typography, the body height baseline of a line of type and tops capital letter above the baseline for refers to the distance between the of the main body of lower case a particular typeface top of the tallest letterform to the letters (i.e. excluding ascenders or bottom of the lowest one. descenders). Crossbar Terminal Counter -In typography, the terminal is a In typography, the enclosed or par- The (usually) horizontal stroke type of curve. Many sources con- tially enclosed circular or curved across the middle of uppercase A sider a terminal to be just the end negative space (white space) of and H. It CONNECTS the ends and (straight or curved) of any stroke some letters such as d, o, and s is not cross over them. that doesn’t include a serif the counter. Bowl Stroke Loop -In typography, it is the curved part -Stroke of a letter are the lines that of a letter that encloses the circular make up the character. Strokes may A curving or doubling of a line so or curved parts (counter) of some be straight, as k,l,v,w,x,z or curved. as to form a closed or partly open letters such as d, b, o, D, and B is Other letter parts such as bars, curve within itself through which the bowl. arms, stems, and bowls are collec- another line can be passed or into tively referred to as the strokes that which a hook may be hooked make up a letterform Ascender Baseline Descnder In typography, the upward vertical Lowercases that extends or stem on some lowercase letters, such In typography, the baseline descends below the baselines as h and b, that extends above the is the imaginary line upon is the descender x-height is the ascender. -
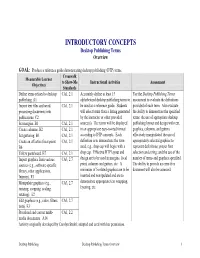
INTRODUCTORY CONCEPTS Desktop Publishing Terms Overview
INTRODUCTORY CONCEPTS Desktop Publishing Terms Overview GOAL: Produce a reference guide demonstrating desktop publishing (DTP) terms. Crosswalk Measurable Learner to Show-Me Instructional Activities Assessment Objectives Standards Define terms related to desktop CA1, 2.1 Accurately define at least 15 Use the Desktop Publishing Terms publishing. A1 alphabetized desktop publishing terms to assessment to evaluate the definitions Import text files and word CA1, 2.1 be used as a reference guide. Students provided of each term. Also evaluate processing documents into will select terms from a listing generated the ability to demonstrate the specified publications. C2 by the instructor or other provided terms; the use of appropriate desktop Set margins. B1 CA1, 2.1 source(s). The terms will be displayed publishing layout and design with text, Create columns. B2 CA1, 2.1 in an appropriate easy-to-read format graphics, columns, and gutters Set guttering. B3 CA1, 2.1 according to DTP concepts. Each effectively manipulated; the use of Create an effective focal point. CA1, 2.1 definition is to demonstrate the term appropriately selected graphics to B6 used, e.g., drop cap will begin with a represent definitions; proper font Utilize pasteboard. B7 CA1, 2.1 drop cap. Effective DTP layout and selection and sizing; and the use of the Import graphics from various CA3, 2.7 design are to be used in margins, focal number of terms and graphics specified. sources (e.g., software-specific point, columns and gutters, etc. A The ability to provide an error-free library, other applications, minimum of 5 related graphics are to be document will also be assessed. -

Alphabets, Letters and Diacritics in European Languages (As They Appear in Geography)
1 Vigleik Leira (Norway): [email protected] Alphabets, Letters and Diacritics in European Languages (as they appear in Geography) To the best of my knowledge English seems to be the only language which makes use of a "clean" Latin alphabet, i.d. there is no use of diacritics or special letters of any kind. All the other languages based on Latin letters employ, to a larger or lesser degree, some diacritics and/or some special letters. The survey below is purely literal. It has nothing to say on the pronunciation of the different letters. Information on the phonetic/phonemic values of the graphic entities must be sought elsewhere, in language specific descriptions. The 26 letters a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z may be considered the standard European alphabet. In this article the word diacritic is used with this meaning: any sign placed above, through or below a standard letter (among the 26 given above); disregarding the cases where the resulting letter (e.g. å in Norwegian) is considered an ordinary letter in the alphabet of the language where it is used. Albanian The alphabet (36 letters): a, b, c, ç, d, dh, e, ë, f, g, gj, h, i, j, k, l, ll, m, n, nj, o, p, q, r, rr, s, sh, t, th, u, v, x, xh, y, z, zh. Missing standard letter: w. Letters with diacritics: ç, ë. Sequences treated as one letter: dh, gj, ll, rr, sh, th, xh, zh. -

Unicode Alphabets for L ATEX
Unicode Alphabets for LATEX Specimen Mikkel Eide Eriksen March 11, 2020 2 Contents MUFI 5 SIL 21 TITUS 29 UNZ 117 3 4 CONTENTS MUFI Using the font PalemonasMUFI(0) from http://mufi.info/. Code MUFI Point Glyph Entity Name Unicode Name E262 � OEligogon LATIN CAPITAL LIGATURE OE WITH OGONEK E268 � Pdblac LATIN CAPITAL LETTER P WITH DOUBLE ACUTE E34E � Vvertline LATIN CAPITAL LETTER V WITH VERTICAL LINE ABOVE E662 � oeligogon LATIN SMALL LIGATURE OE WITH OGONEK E668 � pdblac LATIN SMALL LETTER P WITH DOUBLE ACUTE E74F � vvertline LATIN SMALL LETTER V WITH VERTICAL LINE ABOVE E8A1 � idblstrok LATIN SMALL LETTER I WITH TWO STROKES E8A2 � jdblstrok LATIN SMALL LETTER J WITH TWO STROKES E8A3 � autem LATIN ABBREVIATION SIGN AUTEM E8BB � vslashura LATIN SMALL LETTER V WITH SHORT SLASH ABOVE RIGHT E8BC � vslashuradbl LATIN SMALL LETTER V WITH TWO SHORT SLASHES ABOVE RIGHT E8C1 � thornrarmlig LATIN SMALL LETTER THORN LIGATED WITH ARM OF LATIN SMALL LETTER R E8C2 � Hrarmlig LATIN CAPITAL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C3 � hrarmlig LATIN SMALL LETTER H LIGATED WITH ARM OF LATIN SMALL LETTER R E8C5 � krarmlig LATIN SMALL LETTER K LIGATED WITH ARM OF LATIN SMALL LETTER R E8C6 UU UUlig LATIN CAPITAL LIGATURE UU E8C7 uu uulig LATIN SMALL LIGATURE UU E8C8 UE UElig LATIN CAPITAL LIGATURE UE E8C9 ue uelig LATIN SMALL LIGATURE UE E8CE � xslashlradbl LATIN SMALL LETTER X WITH TWO SHORT SLASHES BELOW RIGHT E8D1 æ̊ aeligring LATIN SMALL LETTER AE WITH RING ABOVE E8D3 ǽ̨ aeligogonacute LATIN SMALL LETTER AE WITH OGONEK AND ACUTE 5 6 CONTENTS -

Word 2010 Basics I
Microsoft Word Fonts [email protected] Microsoft Word Fonts 1.0 hours Format Font ............................................................................................. 3 Font Dialog Box ........................................................................................ 4 Effects ................................................................................................ 4 Set as Default… .................................................................................. 4 Text Effects .............................................................................................. 5 Format Text Effects Pane ................................................................... 6 Typography .............................................................................................. 7 Advanced Font Features .......................................................................... 8 Drop Cap ................................................................................................. 8 Symbols .................................................................................................... 9 Class Exercise ......................................................................................... 10 Exercise 1: Simple Font Formatting ................................................. 10 Exercise 2: Advanced Options .......................................................... 12 Exercise 3: Text Effects, Symbols, Superscript, Subscript ................ 13 Exercise 4: More Formats ............................................................... -

MUFI Character Recommendation V. 3.0: Alphabetical Order
MUFI character recommendation Characters in the official Unicode Standard and in the Private Use Area for Medieval texts written in the Latin alphabet ⁋ ※ ð ƿ ᵹ ᴆ ※ ¶ ※ Part 1: Alphabetical order ※ Version 3.0 (5 July 2009) ※ Compliant with the Unicode Standard version 5.1 ____________________________________________________________________________________________________________________ ※ Medieval Unicode Font Initiative (MUFI) ※ www.mufi.info ISBN 978-82-8088-402-2 ※ Characters on shaded background belong to the Private Use Area. Please read the introduction p. 11 carefully before using any of these characters. MUFI character recommendation ※ Part 1: alphabetical order version 3.0 p. 2 / 165 Editor Odd Einar Haugen, University of Bergen, Norway. Background Version 1.0 of the MUFI recommendation was published electronically and in hard copy on 8 December 2003. It was the result of an almost two-year-long electronic discussion within the Medieval Unicode Font Initiative (http://www.mufi.info), which was established in July 2001 at the International Medi- eval Congress in Leeds. Version 1.0 contained a total of 828 characters, of which 473 characters were selected from various charts in the official part of the Unicode Standard and 355 were located in the Private Use Area. Version 1.0 of the recommendation is compliant with the Unicode Standard version 4.0. Version 2.0 is a major update, published electronically on 22 December 2006. It contains a few corrections of misprints in version 1.0 and 516 additional char- acters (of which 123 are from charts in the official part of the Unicode Standard and 393 are additions to the Private Use Area). -

Path to a Baseline Proposal for Copper and Backplane PMD Clauses
November 2014 IEEE 802.3 25 Gb/s Ethernet Study Group 1 Path to a baseline proposal for copper and backplane PMD clauses Adee Ran Intel October 2014 November 2014 IEEE 802.3 25 Gb/s Ethernet Study Group 2 Introduction • This presentation aims at laying out the required components of a cable/backplane PMDs baseline proposal: • Suggested editorial structure • Technical components that require some work • Choices that do not seem obvious • The three objectives accepted by the study group in the September interim serve as the foundation: November 2014 IEEE 802.3 25 Gb/s Ethernet Study Group 3 General ideas • Assume a new clause will be created for a single-lane copper cable PMD • Refer back to clause 92 wherever appropriate • Assume a new clause will be created for a single-lane backplane PMD • Refer back to clause 93 wherever appropriate • Share structure and content between the backplane and cable PMD clauses where possible • Possible new concepts for the cable PMD: • More than one PMD “class” (exact definition has to be decided), so multiple electrical specifications • More than one loss budget, so multiple channel constructions • Choice of using FEC, possibly two FEC types, possibly different PCS encodings • Choice of MDIs Note: “class” used here temporarily until we decide on nomenclature (type, subtype, optional feature, or combinations ) November 2014 IEEE 802.3 25 Gb/s Ethernet Study Group 4 General structure – copper cable clause Subclauses of clause 92 (Boldface text means a possibly non-obvious change; strikethrough text means subclause can be omitted) 1. Overview 2. PMD service interface 3. -

Digital Desktop Publishing Course Code: 5176
DIGITAL DESKTOP PUBLISHING COURSE CODE: 5176 COURSE DESCRIPTION: This course brings together graphics and text to create professional level documents and publications. Students create, format, illustrate, design, edit/revise, and print publications. Improved productivity of digitally produced newsletters, flyers, brochures, reports, advertising materials, catalogs, and other publications is emphasized. OBJECTIVE: Given the necessary equipment, supplies, and facilities, the student will be able to successfully complete all of the following core competencies for a course granting one unit of credit. RECOMMENDED GRADE LEVELS: 10–12 COURSE CREDIT: 1 Carnegie unit PREREQUISITE: Computer Applications or Integrated Business Applications 1 RECOMMENDED SOFTWARE: Adobe InDesign COMPUTER REQUIREMENT: One computer per student OTHER APPLICABLE SOFTWARE: Adobe Illustrator, Adobe Photoshop, Microsoft Publisher, and Microsoft Word RESOURCES: www.mysctextbooks.com A. SAFETY 1. Review school safety policies and procedures. 2. Review classroom safety rules and procedures. 3. Review safety procedures for using equipment in the classroom. 4. Identify major causes of work-related accidents in office environments. 5. Demonstrate safety skills in an office/work environment. B. STUDENT ORGANIZATIONS 1. Identify the purpose and goals of a Career and Technology Student Organization (CTSO). 2. Explain how CTSOs are integral parts of specific clusters, majors, and/or courses. 3. Explain the benefits and responsibilities of being a member of a CTSO. 4. List leadership opportunities that are available to students through participation in CTSO conferences, competitions, community service, philanthropy, and other activities. October 2014 5. Explain how participation in CTSOs can promote lifelong benefits in other professional and civic organizations. C. TECHNOLOGY KNOWLEDGE 1. Demonstrate proficiency and skills associated with the use of technologies that are common to a specific occupation. -

A New Wave of Evidence: the Impact of School, Family, and Community
SEDL – Advancing Research, Improving Education A New Wave of Evidence The Impact of School, Family, and Community Connections on Student Achievement Annual Synthesis 2002 Anne T. Henderson Karen L. Mapp SEDL – Advancing Research, Improving Education A New Wave of Evidence The Impact of School, Family, and Community Connections on Student Achievement Annual Synthesis 2002 Anne T. Henderson Karen L. Mapp Contributors Amy Averett Deborah Donnelly Catherine Jordan Evangelina Orozco Joan Buttram Marilyn Fowler Margaret Myers Lacy Wood National Center for Family and Community Connections with Schools SEDL 4700 Mueller Blvd. Austin, Texas 78723 Voice: 512-476-6861 or 800-476-6861 Fax: 512-476-2286 Web site: www.sedl.org E-mail: [email protected] Copyright © 2002 by Southwest Educational Development Laboratory (SEDL). All rights reserved. No part of this publication may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying, recording, or any information storage and retrieval system, without permission in writing from SEDL or by submitting a copyright request form accessible at http://www.sedl.org/about/copyright_request.html on the SEDL Web site. This publication was produced in whole or in part with funds from the Institute of Education Sciences, U.S. Department of Education, under contract number ED-01-CO-0009. The content herein does not necessarily reflect the views of the U.S. Department of Education, or any other agency of the U.S. government, or any other source. To the late Susan McAllister Swap For more than 20 years, Sue worked tirelessly with both parents and edu- cators, exploring how to develop closer, richer, deeper partnerships. -

1 Symbols (2286)
1 Symbols (2286) USV Symbol Macro(s) Description 0009 \textHT <control> 000A \textLF <control> 000D \textCR <control> 0022 ” \textquotedbl QUOTATION MARK 0023 # \texthash NUMBER SIGN \textnumbersign 0024 $ \textdollar DOLLAR SIGN 0025 % \textpercent PERCENT SIGN 0026 & \textampersand AMPERSAND 0027 ’ \textquotesingle APOSTROPHE 0028 ( \textparenleft LEFT PARENTHESIS 0029 ) \textparenright RIGHT PARENTHESIS 002A * \textasteriskcentered ASTERISK 002B + \textMVPlus PLUS SIGN 002C , \textMVComma COMMA 002D - \textMVMinus HYPHEN-MINUS 002E . \textMVPeriod FULL STOP 002F / \textMVDivision SOLIDUS 0030 0 \textMVZero DIGIT ZERO 0031 1 \textMVOne DIGIT ONE 0032 2 \textMVTwo DIGIT TWO 0033 3 \textMVThree DIGIT THREE 0034 4 \textMVFour DIGIT FOUR 0035 5 \textMVFive DIGIT FIVE 0036 6 \textMVSix DIGIT SIX 0037 7 \textMVSeven DIGIT SEVEN 0038 8 \textMVEight DIGIT EIGHT 0039 9 \textMVNine DIGIT NINE 003C < \textless LESS-THAN SIGN 003D = \textequals EQUALS SIGN 003E > \textgreater GREATER-THAN SIGN 0040 @ \textMVAt COMMERCIAL AT 005C \ \textbackslash REVERSE SOLIDUS 005E ^ \textasciicircum CIRCUMFLEX ACCENT 005F _ \textunderscore LOW LINE 0060 ‘ \textasciigrave GRAVE ACCENT 0067 g \textg LATIN SMALL LETTER G 007B { \textbraceleft LEFT CURLY BRACKET 007C | \textbar VERTICAL LINE 007D } \textbraceright RIGHT CURLY BRACKET 007E ~ \textasciitilde TILDE 00A0 \nobreakspace NO-BREAK SPACE 00A1 ¡ \textexclamdown INVERTED EXCLAMATION MARK 00A2 ¢ \textcent CENT SIGN 00A3 £ \textsterling POUND SIGN 00A4 ¤ \textcurrency CURRENCY SIGN 00A5 ¥ \textyen YEN SIGN 00A6 -

FUPA) in the UCS Source: Michael Everson and Klaas Ruppel Version: 2.0 Date: 1998-11-02
Title: Encoding Finno-Ugric Phonetic Alphabet (FUPA) in the UCS Source: Michael Everson and Klaas Ruppel Version: 2.0 Date: 1998-11-02 The Finno-Ugric Phonetic Alphabet (FUPA) 0. Introduction This paper presents a collection of characters, diacritics, and notation marks used in the FUPA scheme. This transcription is and has been used creatively by different scientists in different countries at different times (Lagercrantz probably made the most baroque use of the system); therefore the phonetic or phonematic values of the elements of the FUPA are intentionally left aside here. However, all the users of this scheme have one thing in common: they use the FUPA in a technical way, as described below. We prefer the term ÒFUPAÓ to ÒFUTÓ (Finno- Ugric Transcription) because of its analogy to the IPA (International Phonetic Alphabet). It is not the intention of this paper to encourage exact (or over-exact) phonetic transcription or the extensive use of diacritics. The intention is rather to facilitate the use of the FUPA by the Uralicist community in the context of the Universal Character Set (UCS), by ensuring that a comprehensive analysis of the system leads to the possibility of encoding FUPA texts, past and present, with the UCS. In the exploratory versions of this document, firm advice on how to use FUPA will not be given; when the study is complete, however, advice on which characters in the UCS refer to whch letters used in the FUPA system will be given. An example of this, we believe, will be the advice for the LATIN SMALL LETTER ENG to be used in coded representations of FUPA texts, past and present, for the velar nasal, in preference to the GREEK SMALL LETTER ETA, although a great many printed texts use an eta glyph (Ç) and not an eng glyph (Ë).