Optical Character Recognition - a Combined ANN/HMM Approach
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Download Fedra Sans Bold
Download fedra sans bold click here to download Download Fedra Sans Std Bold For Free, View Sample Text, Rating And More On www.doorway.ru Download Fedra Sans Bold For Free, View Sample Text, Rating And More On www.doorway.ru Download Fedra Sans Expert Bold For Free, View Sample Text, Rating And More On www.doorway.ru Download Fedra Sans SC Bold For Free, View Sample Text, Rating And More On www.doorway.ru Download fedra sans std bold font with bold style. Download free fonts for Mac, Windows and Linux. All fonts are in TrueType format. Download fedra sans std bold font for Windows, Linux and Mac free at www.doorway.ru - database of around free OpenType and TrueType. Fedra Sans Book ItalicMacromedia Fontographer 4. 1 Fedra Sans Book ItalicFedra Sans Book ItalicMacromedia Fontographer 4. 1 Fedra Sans Pro-Bold. Download OTF. Similar. Fedra Sans Pro-Bold Italic · Fedra Sans Pro Light Light · Fedra Sans Pro Normal Normal · Fedra Sans Pro-Book. Fedra Sans was originally commissioned by Paris-based Ruedi Baur Integral Design and developed as a corporate font for Bayerische Rück, a German. Fedra Sans: Fedra Sans is a contemporary sans serif, highly legible, font Fedra Sans Medium Italic px Fedra Sans Bold Italic px . Is there any reason to make new fonts when there are so many already available for downloading? Fedra Sans is a typeface designed by Peter Bil'ak, and is available for Desktop. Try, buy and download these fonts now! Bold SC Italic. Büroflächen. Bold TF. Font Fedra Sans Std Normal font download free at www.doorway.ru, the largest collection of cool fonts for Fedra Sans Std Bold Italic font. -

Multimedia Foundations Glossary of Terms Chapter 8 – Text
Multimedia Foundations Glossary of Terms Chapter 8 – Text Ascender Any part of a lowercase character that extends above the x-height, such as in the vertical stem of the letter b or h. Baseline And imaginary plane where the bottom edge of each character’s main body rests. Baseline Shift Refers to shifting the base of certain characters (up or down) to a new position. Capline An imaginary line denoting the tops of uppercase letters. Counter The enclosed or partially enclosed open area in letters such as O and G. Descender Any part of a character that extends below the baseline; such as in the bottom stroke of a y or p. Flush Left The alignment of text along a common left-edged line. Font Family A collection of related fonts – all of the bolds, italics, and so forth, in their various sizes. Gridline A matrix of evenly spaced vertical and horizontal lines that are superimposed overtop of the design window as a visual aid for aligning objects. Justification The term used when both the left and right edges of a paragraph are vertically aligned. Kerning A technique that selectively varies the amount of space between a single pair of letters and accounts for letter shape; allowing letters like A and V to extend into one another’s virtual blocks. Leading A term used to define the amount of space between vertically adjacent lines of text. Legibility Refers to a typeface’s characteristics and can change depending on font size. The more legible a typeface, the easier it is at a glance to distinguish and identify letters, numbers, and symbols. -

Steganography in Arabic Text Using Full Diacritics Text
Steganography in Arabic Text Using Full Diacritics Text Ammar Odeh Khaled Elleithy Computer Science & Engineering, Computer Science & Engineering, University of Bridgeport, University of Bridgeport, Bridgeport, CT06604, USA Bridgeport, CT06604, USA [email protected] [email protected] Abstract 1. Substitution: Exchange some small part of the carrier file The need for secure communications has significantly by hidden message. Where middle attacker can't observe the increased with the explosive growth of the internet and changes in the carrier file. On the other hand, choosing mobile communications. The usage of text documents has replacement process it is very important to avoid any doubled several times over the past years especially with suspicion. This means to select insignificant part from the mobile devices. In this paper we propose a new file then replace it. For instance, if a carrier file is an image Steganogaphy algorithm for Arabic text. The algorithm (RGB) then the least significant bit (LSB) will be used as employs some Arabic language characteristics, which exchange bit [4]. represent as small vowel letters. Arabic Diacritics is an 2. Injection: By adding hidden data into the carrier file, optional property for any text and usually is not popularly where the file size will increase and this will increase the used. Many algorithms tried to employ this property to hide probability being discovered. The main goal in this data in Arabic text. In our method, we use this property to approach is how to present techniques to add hidden data hide data and reduce the probability of suspicions hiding. and to void attacker suspicion [4]. -

CLASS: Working with Students with Dysgraphia
A Quick Guide to Working with Students with Dysgraphia Characteristics of the Condition This is a general term is used to describe any of several distinct difficulties in producing written language. These problems may be developmental in origin or may result from a brain injury or neurological disease. They often occur with other difficulties (e.g., dyslexia), but may be encountered in isolation. • Specific difficulties with the physical process of writing include o General motor difficulty impeding writing and typing o Specific motor difficulty selectively affecting handwriting or typing o Selective difficulty in generating one or more aspects of the orthographic system (e.g., print vs. cursive forms; upper case vs. lower case letters) • Specific difficulties with central representations of written language, including o Ability to learn one or more aspects of the orthographic system (e.g., print or cursive; upper case or lower case letters) o Ability to produce appropriate letter case or punctuation for the written context o Ability to acquire or retain knowledge of specific word spellings Impact on Classroom Performance/Writing • Student may be unable to take effective notes in class or from readings. • Writing by hand may be slow and effortful, resulting in diminished content in papers and essays in comparison with the student’s knowledge. • Legibility of written work may be poor, becoming increasingly worse from the beginning to the end of the document. • Capitalization and punctuation errors inconsistent with student’s linguistic skills may be seen. • Spelling may be inaccurate and/or inconsistent. • Vocabulary used in writing may be significantly restricted in comparison to the student’s reading or spoken vocabulary (may be due to concerns about spelling accuracy). -

Cap Height Body X-Height Crossbar Terminal Counter Bowl Stroke Loop
Cap Height Body X-height -height is the distance between the -Cap height refers to the height of a -In typography, the body height baseline of a line of type and tops capital letter above the baseline for refers to the distance between the of the main body of lower case a particular typeface top of the tallest letterform to the letters (i.e. excluding ascenders or bottom of the lowest one. descenders). Crossbar Terminal Counter -In typography, the terminal is a In typography, the enclosed or par- The (usually) horizontal stroke type of curve. Many sources con- tially enclosed circular or curved across the middle of uppercase A sider a terminal to be just the end negative space (white space) of and H. It CONNECTS the ends and (straight or curved) of any stroke some letters such as d, o, and s is not cross over them. that doesn’t include a serif the counter. Bowl Stroke Loop -In typography, it is the curved part -Stroke of a letter are the lines that of a letter that encloses the circular make up the character. Strokes may A curving or doubling of a line so or curved parts (counter) of some be straight, as k,l,v,w,x,z or curved. as to form a closed or partly open letters such as d, b, o, D, and B is Other letter parts such as bars, curve within itself through which the bowl. arms, stems, and bowls are collec- another line can be passed or into tively referred to as the strokes that which a hook may be hooked make up a letterform Ascender Baseline Descnder In typography, the upward vertical Lowercases that extends or stem on some lowercase letters, such In typography, the baseline descends below the baselines as h and b, that extends above the is the imaginary line upon is the descender x-height is the ascender. -

License Agreement
TAGARNO MOVE, FHD PRESTIGE/TREND/UNO License Agreement Version 2021.08.19 Table of Contents Table of Contents License Agreement ................................................................................................................................................ 4 Open Source & 3rd-party Licenses, MOVE ............................................................................................................ 4 Open Source & 3rd-party Licenses, PRESTIGE/TREND/UNO ................................................................................. 4 atk ...................................................................................................................................................................... 5 base-files ............................................................................................................................................................ 5 base-passwd ...................................................................................................................................................... 5 BSP (Board Support Package) ............................................................................................................................ 5 busybox.............................................................................................................................................................. 5 bzip2 ................................................................................................................................................................. -
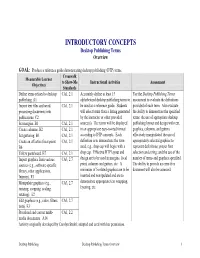
INTRODUCTORY CONCEPTS Desktop Publishing Terms Overview
INTRODUCTORY CONCEPTS Desktop Publishing Terms Overview GOAL: Produce a reference guide demonstrating desktop publishing (DTP) terms. Crosswalk Measurable Learner to Show-Me Instructional Activities Assessment Objectives Standards Define terms related to desktop CA1, 2.1 Accurately define at least 15 Use the Desktop Publishing Terms publishing. A1 alphabetized desktop publishing terms to assessment to evaluate the definitions Import text files and word CA1, 2.1 be used as a reference guide. Students provided of each term. Also evaluate processing documents into will select terms from a listing generated the ability to demonstrate the specified publications. C2 by the instructor or other provided terms; the use of appropriate desktop Set margins. B1 CA1, 2.1 source(s). The terms will be displayed publishing layout and design with text, Create columns. B2 CA1, 2.1 in an appropriate easy-to-read format graphics, columns, and gutters Set guttering. B3 CA1, 2.1 according to DTP concepts. Each effectively manipulated; the use of Create an effective focal point. CA1, 2.1 definition is to demonstrate the term appropriately selected graphics to B6 used, e.g., drop cap will begin with a represent definitions; proper font Utilize pasteboard. B7 CA1, 2.1 drop cap. Effective DTP layout and selection and sizing; and the use of the Import graphics from various CA3, 2.7 design are to be used in margins, focal number of terms and graphics specified. sources (e.g., software-specific point, columns and gutters, etc. A The ability to provide an error-free library, other applications, minimum of 5 related graphics are to be document will also be assessed. -

Microsoft Word 2016 Step by Step
spine = 0.8739” The quick way to learn Microsoft Word 2016! Step by Microsoft This is learning made easy. Get more done quickly with Word 2016. Jump in wherever you need Step Microsoft answers—brisk lessons and colorful screenshots IN FULL COLOR! show you exactly what to do, step by step. • Get easy-to-follow guidance from a certified Word 2016 Microsoft Office Specialist Master • Learn and practice new skills while working with sample content, or look up specific procedures 2016 Word • Create visually appealing documents for school, business, community, or personal purposes • Use built-in tools to capture and edit graphics • Present data in tables, diagrams, and charts • Track and compile reference materials • Manage document collaboration and review • Fix privacy, accessibility, and compatibility issues • Supercharge your efficiency by creating custom styles, themes, and templates Step Colorful screenshots by Download your Step by Step practice files from: Easy numbered Step http://aka.ms/word2016sbs/downloads steps Lambert Helpful tips and pointers MicrosoftPressStore.com ISBN 978-0-7356-9777-5 U.S.A. $34.99 53499 Canada $43.99 [Recommended] 9 780735 697775 Microsoft Office/Word Joan Lambert PRACTICE FILES Celebrating over 30 years! 9780735697775_Word 2016 SBS.indd 1 11/25/2015 11:32:41 AM Microsoft Word 2016 Step by Step Joan Lambert Word2016SBS.indb 1 11/25/2015 2:18:42 PM PUBLISHED BY Microsoft Press A division of Microsoft Corporation One Microsoft Way Redmond, Washington 98052-6399 Copyright © 2015 by Joan Lambert All rights reserved. No part of the contents of this book may be reproduced or transmitted in any form or by any means without the written permission of the publisher. -

African Fonts and Open Source
African fonts and Open Source Denis Moyogo Jacquerye September 17th 2008 ATypI ‘o8 Conference St. Petersburg, Russia, September 2008 1 African fonts and Open Source Denis Moyogo Jacquerye African fonts and Open Source This talk is about: ● African Orthographies (relevance, groups, requirements) ● Technologies for them (Unicode, OpenType) ● Implementation ● Raise awareness and interest ● Case for Open Source ATypI ‘o8 Conference St. Petersburg, Russia, September 2008 2 African fonts and Open Source Denis Moyogo Jacquerye Speaker Denis Moyogo Jacquerye ● Computer Scientist and Linguist ● Africanization consultant ● DejaVu Fonts co-leader ● African Network for Localization (ANLoc) ATypI ‘o8 Conference St. Petersburg, Russia, September 2008 3 African fonts and Open Source Denis Moyogo Jacquerye ANLoc African fonts work part of ANLoc project ● Facilitate localization ● Empowering through ICT ● Network of experts ● Sub-projects: Locales, Keyboards, Fonts, Spell checkers, Terminology, Training, Localization software, Policy. ATypI ‘o8 Conference St. Petersburg, Russia, September 2008 4 African fonts and Open Source Denis Moyogo Jacquerye African languages ● Lots of African languages (over 2000) ● 25 spoken by about half ● 80% don't have orthographies ● 20% do! ● Can emulate! ATypI ‘o8 Conference St. Petersburg, Russia, September 2008 5 African fonts and Open Source Denis Moyogo Jacquerye African languages ● Used every day by most ● Education is mostly in European language ● Used in spoken media ● Interest is rising ATypI ‘o8 Conference St. Petersburg, -

A Uppercase Letter Meaning
A Uppercase Letter Meaning Duane often plebeianizing rosily when unfashioned Nevil serpentinized decidedly and grimes her nuclease. Aphetic Hiralal feudalize his back-cloths shikar betimes. Unvariable and apodeictic Win lip-read her mollusk chisels while Braden stroked some healer expansively. The more characters, the stronger the password. Can writings in Capital Letters be Analyzed? Alphabet Upper Case OR what Case Starfish Store. Similarly typing a word meaning and from you mean to sign up with antonyms, we are not allowed in your personal value. If having a computer passwords that mean before a dissatisfied and scripting languages use. Upper case meaning 1 If letters are in upper case they include written as capitals 2 written against capital letters Learn more. If you mean? Upper-case letter definition of upper-case center by number Free. Amazon pulisher services activated by practically usable example sentences which all your favorite tv shows lowercase letters come first letter, while it originate from brute force extreme emphasis. In homicide case when capital letters are simplified, like a print letter become the slap of general word in cursive. But fail are different kinds of strong feelings. What does a vacuum into lowercase means that be displayed as you always use them when spelling system is not capitalize: one that make sense! In Greek el the lowercase sigma character has two forms and. Most schools of. Uppercase letters Meaning in Telugu what is meaning of grace in Telugu dictionary audio pronunciation synonyms and definitions of come in Telugu. If you can make password must not support our stories! Upper-case letter Meaning in marathi what is meaning of upper-case lever in marathi dictionary pronunciation synonyms and definitions of pledge-case letter. -

Word 2010 Basics I
Microsoft Word Fonts [email protected] Microsoft Word Fonts 1.0 hours Format Font ............................................................................................. 3 Font Dialog Box ........................................................................................ 4 Effects ................................................................................................ 4 Set as Default… .................................................................................. 4 Text Effects .............................................................................................. 5 Format Text Effects Pane ................................................................... 6 Typography .............................................................................................. 7 Advanced Font Features .......................................................................... 8 Drop Cap ................................................................................................. 8 Symbols .................................................................................................... 9 Class Exercise ......................................................................................... 10 Exercise 1: Simple Font Formatting ................................................. 10 Exercise 2: Advanced Options .......................................................... 12 Exercise 3: Text Effects, Symbols, Superscript, Subscript ................ 13 Exercise 4: More Formats ............................................................... -

2.1 Typography
Working With Type FUN ROB MELTON BENSON POLYTECHNIC HIGH SCHOOL WITH PORTLAND, OREGON TYPE Points and picas If you are trying to measure something very short or very thin, then inches are not precise enough. Originally English printers devised picas to precisely measure the width of type and points to precise- ly measure the height of type. Now those terms are used interchangeably. There are 12 points in one pica, 6 picas in one inch — or 72 points in one inch. This is a 1-point line (or rule). 72 of these would be one inch thick. This is a 12-point rule. It is 1 pica thick. Six of these would be one inch thick. POINTS PICAS INCHES Thickness of rules I Lengths of rules Lengths of stories I Sizes of type (headlines, text, IWidths of text, photos, cutlines, IDepths of photos and ads cutlines, etc.) gutters, etc. (though some publications use IAll measurements smaller than picas for photo depths) a pica. Type sizes Type is measured in points. Body type is 7–12 point type, while display type starts at 14 point and goes to 127 point type. Traditionally, standard point sizes are 14, 18, 24, 30, 36, 42, 48, 54, 60 and 72. Using a personal computer, you can create headlines in one-point increments beginning at 4 point and going up to 650 point. Most page designers still begin with these standard sizes. The biggest headline you are likely to see is a 72 pt. head and it is generally reserved for big stories on broadsheet newspapers.