Legacy Image
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
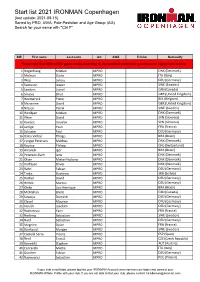
Start List 2021 IRONMAN Copenhagen (Last Update: 2021-08-15) Sorted by PRO, AWA, Pole Posistion and Age Group (AG) Search for Your Name with "Ctrl F"
Start list 2021 IRONMAN Copenhagen (last update: 2021-08-15) Sorted by PRO, AWA, Pole Posistion and Age Group (AG) Search for your name with "Ctrl F" BIB First name Last name AG AWA TriClub Nationallty Please note that BIBs will be given onsite according to the selected swim time you choose in registration oniste. 1 Hogenhaug Kristian MPRO DNK (Denmark) 2 Molinari Giulio MPRO ITA (Italy) 3 Wojt Lukasz MPRO DEU (Germany) 4 Svensson Jesper MPRO SWE (Sweden) 5 Sanders Lionel MPRO CAN (Canada) 6 Smales Elliot MPRO GBR (United Kingdom) 7 Heemeryck Pieter MPRO BEL (Belgium) 8 Mcnamee David MPRO GBR (United Kingdom) 9 Nilsson Patrik MPRO SWE (Sweden) 10 Hindkjær Kristian MPRO DNK (Denmark) 11 Plese David MPRO SVN (Slovenia) 12 Kovacic Jaroslav MPRO SVN (Slovenia) 14 Jarrige Yvan MPRO FRA (France) 15 Schuster Paul MPRO DEU (Germany) 16 Dário Vinhal Thiago MPRO BRA (Brazil) 17 Lyngsø Petersen Mathias MPRO DNK (Denmark) 18 Koutny Philipp MPRO CHE (Switzerland) 19 Amorelli Igor MPRO BRA (Brazil) 20 Petersen-Bach Jens MPRO DNK (Denmark) 21 Olsen Mikkel Hojborg MPRO DNK (Denmark) 22 Korfitsen Oliver MPRO DNK (Denmark) 23 Rahn Fabian MPRO DEU (Germany) 24 Trakic Strahinja MPRO SRB (Serbia) 25 Rother David MPRO DEU (Germany) 26 Herbst Marcus MPRO DEU (Germany) 27 Ohde Luis Henrique MPRO BRA (Brazil) 28 McMahon Brent MPRO CAN (Canada) 29 Sowieja Dominik MPRO DEU (Germany) 30 Clavel Maurice MPRO DEU (Germany) 31 Krauth Joachim MPRO DEU (Germany) 32 Rocheteau Yann MPRO FRA (France) 33 Norberg Sebastian MPRO SWE (Sweden) 34 Neef Sebastian MPRO DEU (Germany) 35 Magnien Dylan MPRO FRA (France) 36 Björkqvist Morgan MPRO SWE (Sweden) 37 Castellà Serra Vicenç MPRO ESP (Spain) 38 Řenč Tomáš MPRO CZE (Czech Republic) 39 Benedikt Stephen MPRO AUT (Austria) 40 Ceccarelli Mattia MPRO ITA (Italy) 41 Günther Fabian MPRO DEU (Germany) 42 Najmowicz Sebastian MPRO POL (Poland) If your club is not listed, please log into your IRONMAN Account (www.ironman.com/login) and connect your IRONMAN Athlete Profile with your club. -

Carnegie Hall Rental
Friday Evening, October 26, 2012, at 8:00 Isaac Stern Auditorium/Ronald O. Perelman Stage Conductor’s Notes Q&A with Leon Botstein at 7:00 presents 50th Birthday Celebration LEON BOTSTEIN, Conductor JOHN STAFFORD SMITH The Star-Spangled Banner Arr. by LEOPOLD STOKOWSKI CHARLES IVES Symphony No. 4 Prelude: Maestoso Allegretto Fugue: Andante moderato Largo maestoso BLAIR MCMILLEN, Piano THE COLLEGIATE CHORALE Intermission GUSTAV MAHLER Symphony No. 8 in E-flat Major (“Symphony of a Thousand”) Part 1: Hymnus: Veni, Creator Spiritus Part 2: Final scene from Goethe’s Faust Part 2 Magna Peccatrix: REBECCA DAVIS, Soprano Una Poenitentium: ABBIE FURMANSKY, Soprano Mater Gloriosa: KATHERINE WHYTE, Soprano Mulier Samaritana: SUSAN PLATTS, Mezzo-soprano Maria Aegyptiaca: FREDRIKA BRILLEMBOURG, Mezzo-soprano (continued) This evening’s concerT will run approximaTely Two and a half hours, inlcuding one 20-minuTe inTermission. The Empire State Building is liT red and white this evening in honor of American Symphony Orchestra’s 50th Birthday. We would like to Thank the Empire State Building for This special honor. American Symphony Orchestra welcomes students and teachers from ASO’s arts education program, Music Notes. For information on how you can support Music Notes, visit AmericanSymphony.org. PLEASE SWITCH OFF YOUR CELL PHONES AND OTHER ELECTRONIC DEVICES. Dr. Marianus: CLAY HILLEY, Tenor Pater EcsTaticus: TYLER DUNCAN, Baritone Pater Profundus: DENIS SEDOV, Bass THE COLLEGIATE CHORALE JAMES BAGWELL, Director THE BROOKLYN YOUTH CHORUS DIANNE BERKUN, Director THE Program JOHN STAFFORD SMITH (Arr. by LEOPOLD STOKOWSKI) The Star-Spangled Banner Smith: Born March 30, 1750 in Gloucester, England Died September 21, 1836 in London Stokowski: Born April 18, 1882 in London Died September 13, 1977 in Nether Wallop, Hampshire, England Composed by Smith as “The Anacreontic Song” in 1775 in London Stokowski first arranged the song in 1940. -

The Berkeley Rep Magazine 2017–18 · Issues 5–6
aids in the United States today 25 · 4 questions for the cast 27 · The program for Angels in America: A Gay Fantasia on National Themes 33 THE BERKELEY REP MAGAZINE 2017–18 · ISSUES 5–6 AG_program.indd 1 4/4/18 3:54 PM Encore spread.indd 1 2/28/18 3:55 PM Encore spread.indd 1 2/28/18 3:55 PM AG_program.indd 4 4/4/18 3:54 PM IN THIS ISSUE 16 23 29 BERKELEY REP PRESENTS MEET THE CAST & CREW · 34 ANGELS IN AMERICA: A GAY FANTASIA ON NATIONAL THEMES · 33 PROLOGUE A letter from the artistic director · 7 Connect with us online! A letter from the managing director · 8 Visit our website berkeleyrep.org facebook.com/ @berkeleyrep You can buy tickets and plan your visit, berkeleyrep watch videos, sign up for classes, donate to vimeo.com/ @berkeleyrep REPORTS the Theatre, and explore Berkeley Rep. berkeleyrep The Messenger has arrived: berkeleyrep. berkeleyrep The art of theatrical flying ·13 We’re mobile! tumblr.com Crossing paths: Download our free iPhone or Google Play app —or visit our mobile site —to buy tickets, read An intergenerational conversation · 16 the buzz, watch videos, and plan your visit. June 2018, when 21 Ground Floor projects roam · 19 Considerations FEATURES Only beverages in cans, cartons, or cups with You are welcome to take a closer look, but The Origin Story · 20 lids are allowed in the house. Food is prohibited please don’t step onto the stage or touch in the house. the props. Tinkering and tinkering: An interview with Tony Kushner and Tony Taccone · 21 Smoking and the use of e-cigarettes is prohibited Any child who can quietly sit in their own by law on Berkeley Rep’s property. -
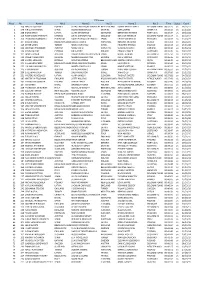
Place No Name 1 Nat 1 Name 2 Nat 2 Name 3 Nat 3
FTE-Junior Place No Name 1 Nat 1 Name 2 Nat 2 Name 3 Nat 3 Time Status Count 1 158 MACIEJ LUCERSKI POLAND SEBASTIAN AYSON MACARLANENEW ZEALAND ESMEE VAN DE MAELE BELGIUM FLANDERS00:31:23 ok 24/21/17 2 240 KIRILL PIVOVAROV SPAIN OLEKSII KONOVALOV UKRAINE MAN ZHANG CHINA P.R. 00:33:10 ok 21/19/22 3 238 SIGNE SIRMA LATVIA CLARE STANSFIELD SCOTLAND BERNARDO PEREIRA PORTUGAL 00:33:47 ok 19/22/24 4 260 TOMI-ANDRE PIIRMETS ESTONIA ANIKA CHINTAPATLA ENGLAND BEN VAN HEMELEN BELGIUM FLANDERS00:34:19 ok 24/22/17 5 200 LEONARDO RAMALHO PORTUGAL DAVID POBLACIÓN CRIADO SPAIN CECILIE ANDERSON ENGLAND 00:34:59 ok 21/20/21 6 197 SIEL DE SMUL BELGIUM FLANDERSVASCO DUARTE PORTUGAL RIHARDS KRUMINS LATVIA 00:35:01 ok 18/21/23 7 119 SEHER ŞAHİN TURKEY REGEV AVRAHAM ISRAEL FRYDERYK PRYJMA POLAND 00:35:18 ok 15/19/28 8 232 JOHANNA TRUMMER AUSTRIA MINGHAO LI CHINA P.R. VLADYSLAV LIAKH UKRAINE 00:35:30 ok 24/19/19 9 234 KEVIN HALLOP ESTONIA JULIA SEIDEL POLAND EWAN SHEARER SCOTLAND 00:35:35 ok 20/22/20 10 121 JANNIS BONEK AUSTRIA INMACULADA CRESPO GONZÁLEZSPAIN BORILE ADRIAN BELGIUM FC 00:35:50 ok 19/21/23 11 213 VALERIY SHELUDKO UKRAINE MARKUS-HARALD PAIS ESTONIA KATIE SKINNER SCOTLAND 00:36:36 ok 23/21/19 12 209 KAAREL VESILIND ESTONIA WOUT KEUPPENS BELGIUM FLANDERSANDREA GRÁCIA JÁTIVA SPAIN 00:36:40 ok 22/22/19 13 271 KLAAS MELLEBEEK BELGIUM FLANDERSIRENE GARCÍA BERNABEU SPAIN LAURI PÄHN ESTONIA 00:36:46 ok 20/20/22 14 222 LUCIANO MASSACCESI ITALY MARTA LÓPEZ GUILL SPAIN MARIE VUITTON FRANCE 00:36:51 ok 17/20/25 15 115 FLORIAN KURZ AUSTRIA AYLİN ŞENGÜNLÜ TURKEY DRIES VAN LOMMEL BELGIUM FLANDERS00:36:53 ok 22/18/22 16 206 SÜLEYMAN EREN TURKEY DALIT MANSOOR ISRAEL XINHAO LU CHINA P.R. -

2013 2013 5Th International Conference on Cyber Conflict
2013 2013 5th International Conference on Cyber Conflict PROCEEDINGS K. Podins, J. Stinissen, M. Maybaum (Eds.) 4-7 JUNE 2013, TALLINN, ESTONIA 2013 5TH INTERNATIONAL CONFERENCE ON CYBER CONFLICT (CYCON 2013) Copyright © 2013 by NATO CCD COE Publications. All rights reserved. IEEE Catalog Number: CFP1326N-PRT ISBN 13 (print): 978-9949-9211-4-0 ISBN 13 (pdf): 978-9949-9211-5-7 ISBN 13 (epub): 978-9949-9211-6-4 Copyright and Reprint Permissions No part of this publication may be reprinted, reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without the prior written permission of the NATO Cooperative Cyber Defence Centre of Excellence ([email protected]). This restriction does not apply to making digital or hard copies of this publication for internal use within NATO, and for personal or educational use when for non-profit or non- commercial purposes, providing that copies bear this notice and a full citation on the first page as follows: [Article author(s)], [full article title] 2013 5th International Conference on Cyber Conflict K. Podins, J. Stinissen, M. Maybaum (Eds.) 2013 © NATO CCD COE Publications Printed copies of this publication are available from: NATO CCD COE Publications Filtri tee 12, 10132 Tallinn, Estonia Phone: +372 717 6800 Fax: +372 717 6308 E-mail: [email protected] Web: www.ccdcoe.org Layout: Marko Söönurm Legal Notice: This publication contains opinions of the respective authors only. They do not necessarily reflect the policy or the opinion of NATO CCD COE, NATO, or any agency or any government. -

Globe. Athletic Gear for Firefighters.Tm
PERFORMANCE AND PROTECTION IN PERFECT BALANCE. GLOBE. ATHLETIC GEAR FOR FIREFIGHTERS.TM Globe gear is designed to meet the new challenges you face every day to help keep you safe and healthy throughout your career and beyond. Get the full story at MSAfire.com/Globe GLOBE, ATHLETIX, and designs are trademarks or registered trademarks of Globe Holding Company, LLC. DUPONT, KEVLAR, NOMEX, and designs are trademarks or registered trademarks of E.I. DuPont de Nemours and Company or its affiliates. Spring 2019 Fire Fighter Quarterly vol. 102 no.2 33 Mount Pleasant Local 4693 Fights for Increased Staffing Truro Local 1627 Member Skyler Blackie 18 2019 Legislative Conference 34 Mourned Cover Features Departments 12 The Power of 16 IAFF Endorses Joe Biden for President n 5 From the General President Political Action Based on his unequaled record of Affiliates across the support on fire fighter issues, the IAFF n 7 From the General International are winning Executive Board voted unanimously to Secretary-Treasurer state and local support Biden in the Democratic primary. n 9 Letters legislative victories following the IAFF 18 Building On Our Legislative Success n 10 Noteworthy News political action playbook. IAFF legislative conferences provide opportunities to advocate on priority n 22 Across the IAFF On the cover: Montana Governor Steve legislation and solidify support for fire Bullock signs legislation giving fire fighter issues. n 33 Local Scene fighters presumptive protections. n 35 On the Road n 36 Retirees n 44 Never Forget n 46 Last Alarm Download the IAFF App The IAFF app is available for Apple and Android devices. -

Partners Help Fulfill Bju's Mission
PARTNERS HELP FULFILL BJU’S MISSION Rev. and Mrs. Stacey B. Peek Rev. and Mrs. Rex K. Clemens Mrs. Susan L. Jacox Mr. and Mrs. Edward E. Sedivy Dr. and Mrs. Stephen D. Pettit Miss Martha L. Cochran Mr. and Mrs. Bobby J. Johnson Mr. and Mrs. John E. Sedivy Bob Jones University recognizes and thanks the following alumni and friends whose generous gifts since June 1, 2015, Dr. and Mrs. Warren L. Popwell Mr. and Mrs. Michael G. Collins Mr. and Mrs. Jeffrey A. Johnson Dr. Lesa M. Seibert Mr. and Mrs. Marvin P. Reem Mr. Clarence E. Cook Mr. and Mrs. Kenneth E. Johnson Mr. and Mrs. Stephen R. Sejda demonstrate their partnership in helping BJU fulfill its mission. Mr. and Mrs. Donald R. Rochester Mr. and Mrs. Russell I. Cooper Mr. and Mrs. Michael D. Johnson Mr. and Mrs. David W. Simonaire Mr. and Mrs. Timothy J. Rogne Mrs. Virginia C. Copiaco Mr. and Mrs. Stephen E. Johnston Miss Jonna M. Smith Mr. and Mrs. Brian P. Romig Mr. and Mrs. Wesley F. Curtis Mr. and Mrs. Timothy J. Joiner Mr. Ralph V. Starr $25,000+ $5,000 to $9,999 $2,500 to $4,999 Mr. and Mrs. Timothy L. Stees Mr. and Mrs. Michael B. Cushman Mr. and Mrs. William W. Kayser Ms. Vickie B. Stone Dr. and Mrs. T. W. Brashier Sr. LtCol. and Mrs. J A. Abels Mrs. Jane Allen Dr. and Mrs. Robert R. Taylor Jr. Mr. Parke M. Dague Dr. and Mrs. Leonard C. Keifer Rev. and Mrs. Melvin L. Stonewall Dr. -

2014 Drake Relays
Complete Results 2014 DRAKE RELAYS | APRIL 23-27 | DRAKE STADIUM Drake Stadium - Site License Hy-Tek's MEET MANAGER Page 1 2014 Drake Relays presented by Hy-Vee America's Athletic Classic Drake University, Des Moines, Iowa - 4/23/2014 to 4/26/2014 Results 5 Daniel Bonthius JR Wartburg 1:53.03 Event 5 Men 100 Meter Dash Univ/Col 6 Jake Mazanke SO Loyola IL 1:53.70 Stadium: 9.89 S 6/10/2011 Ngonidzashe Makusha 7 Moses Heppner SR North Dakota 1:53.89 Relays: 10.11 D 1983 Calvin Smith 8 Ryan Van Portfliet JR Loyola IL 1:54.02 Name Yr School Prelims 9 Kisean Smith SO Georgia 1:54.13 Preliminaries 10 Chris Miedema SR DePaul 1:54.49 1 Trayvon Bromell FR Baylor 10.16Q2.0 11 Justin Chambers SR Texas Christ 1:55.21 2 Ronnie Baker SO Texas Christ 10.29Q1.0 12 Goaner Deng SO Minnesota 1:56.10 3 Johnathan Smith SR Georgia 10.38Q-0.6 4 O'Shea Wilson FR Iowa 10.48Q0.6 Event 12 Men 800 Meter Run Unseeded Univ/Col 5 Wayne Gordon SO Kent St 10.36q 1.0 Stadium: 1:44.71 S 6/10/2011 Robby Andrews 6 Johnathan Farquarshon JR Abilene Chr 10.44q 2.0 Relays: 1:50.37 D 4/26/2012 Lucas Manring 7 Thurgood Dennis JR UW-Eau Clair 10.48q -0.6 Name Yr School Finals 8 Everett Walker SR Baylor 10.51q -0.6 Finals 9 Jerrell Hancock SR Minn St Mankato 10.51 2.0 1 McKena Ramos FR UW-Oshkosh 1:51.33 10 Kolby Listenbee FR Texas Christ 10.52 0.6 2 Bradley Johnson FR Minnesota 1:52.13 11 Tevin-Cee Mincy SR Iowa 10.55 1.0 3 Jermaine Blake SR Lincoln (MO) 1:53.12 12 Corneil Lionel SO Iowa Western 10.55 1.0 4 Jeffrey Cottrell JR Minnesota 1:53.24 13 Tim Thompson SR Nebraska 10.56 -

Estonian: Typological Studies V
TARTU ÜLIKOOLI EESTI KEELE ÕPPETOOLI TOIMETISED 18 PUBLICATIONS OF THE DEPARTMENT OF ESTONIAN OF THE UNIVERSITY OF TARTU 18 ESTONIAN: TYPOLOGICAL STUDIES V edited by Mati Erelt TARTU 2001 ESTONIAN: TYPOLOGICAL STUDIES V TARTU ÜLIKOOLI EESTI KEELE ÕPPETOOLI TOIMETISED 18 PUBLICATIONS OF THE DEPARTMENT OF ESTONIAN OF THE UNIVERSITY OF TARTU 18 ESTONIAN: TYPOLOGICAL STUDIES V edited by Mati Erelt TARTU 2001 ESTONIAN: TYPOLOGICAL STUDIES V This work was supported by the Estonian Science Foundation, Grant No. 3259. Raamatukogu © University of Tartu, 2001 ISSN 1406-0183 Tartu Ülikooli Kirjastuse trükikoda Tiigi 78, Tartu 50410 Tellimus nr 651 CONTENTS Mati Erelt Some notes on the grammaticalization of the verb pidama in Estonian ......................................................7 Külli Habicht Lexicalization and grammaticalization - opposite phenomena? About some lexicalized verb forms of Old Written Estonian ....26 Reet Kasik Analytic causatives in Estonian..................... ................................77 Ago Kiinnap On some peculiarities of the Estonian language ....................... 123 Liina Lindström Verb-initial clauses in the narrative ............................................ 138 Merilin Mil] an Adjectival modification in Estonian and Estonian sign language ................................... 169 Enn Veldi Estonian and English: a lexicographer’s view. II 189 SOME NOTES ON THE GRAMMATICALIZATION OF THE VERB pidama IN ESTONIAN Mati Erelt University of Tartu 1. Two pidama-\erbs The Explanatory Dictionary of Estonian (EKS) tells us that there are two pidama-verbs in contemporary Estonian. One of them occurs mostly in the meanings ‘keep, hold, regard, etc.’, e.g. (1) Ta suudab veel mõõka käes pidada. ‘He can still hold the sword in his hand’. Kurjategijat peeti üksikkambris. ‘The criminal was kept in solitary confinement’. Ta ei suutnud naeru tagasi pidada. -

Annual Meeting 2016
TITLE ANNUAL MEETING 2016 11–14 DECEMBER ACC, LIVERPOOL, UK british ecologicalsociety.org 1 © Google Maps 2016 11–14 DECEMBER ANNUAL ACC, LIVERPOOL, UK MEETING 2016 CONTENTS ORAL PRESENTATIONS 30 MONDAY 12 DECEMBER 30 TUESDAY 13 DECEMBER 38 LOCAL AREA MAP 2 WEDNESDAY 14 DECEMBER 45 CONTENTS 3 POSTER PRESENTATIONS 52 BES WELCOME 4 MONDAY 12 DECEMBER 52 WELCOME TO LIVERPOOL 5 TUESDAY 13 DECEMBER 57 FIRST TIME AT OUR ANNUAL MEETING 6 INDEX OF PRESENTERS 62 ACC LAYOUT 8 ATTENDEE INFORMATION 72 FLOORPLAN 9 MEET OUR TEAM 75 MEETING OVERVIEW 10 BES FUN RUN 76 ORAL SESSION OVERVIEW 12 SOCIAL EVENTS 78 PLENARY LECTURES 14 PHOTOGRAPHIC COMPETITION WINNERS 83 THEMATIC TOPIC SESSIONS 18 INFORMATION FOR FAMILIES 84 WORKSHOPS OVERVIEW 22 FUTURE MEETINGS 86 CAREERS DEVELOPMENT PROGRAMME 26 AGM 88 POLICY AT BES 27 AWARD WINNERS 92 PRESENTER INFORMATION 28 SPECIAL INTEREST GROUPS 94 WELCOME It is with great pleasure that I welcome you to the 2016 BES Annual Meeting here in Liverpool. Banish any lingering post-Brexit blues with our fantastic and truly international programme of talks, posters, workshops, events and plenaries! If the exciting science and great networking opportunities The Annual Meeting is certainly one of the most important somehow fail to cheer, then there is always our legendary events for the Society – last year’s meeting in Edinburgh Christmas jersey competition on Wednesday. was one of our biggest ever and this year’s meeting will be just as successful I’m sure. But the BES is far more than just Festive fun aside, the heart of our meeting is top quality this meeting, so do come along to the BES stand to meet the ecological science and this week you will have an opportunity staff and hear about all the vital work that has been going on to hear from researchers at the forefront of the field. -

Stanford Health Care Financial Assistance Participating Providers
Stanford Health Care Financial Assistance Participating Providers Last Name First Name Degree Specialty Provider's NPI Aalami Oliver MD Vascular Surgery 1225229024 Aasi Sumaira MD Dermatology 1780675181 Abad Vivien MD Neurology 1861588030 Abbasi Fahim MD Endocrinology, Diabetes &Metabolism 1841484037 Abdelwahab Mohamed Visiting Otolaryngology 1528679768 Abdollah Shamshirsaz Alireza MD Obstetrics & Gynecology 1881804235 Abe Brian MD Rheumatology 1104262708 Abir Gillian MBChB Anesthesiology 1538300595 Abou‐Arraj Nadeem MD Internal Medicine 1437684909 Aboujaoude Elias MD Psychiatry 1649209768 Abovwe Nkeiru NP Nurse Practitioner 1467878447 Abra Graham MD Nephrology 1760644678 Abragan Roy Patrick NP Nurse Practitioner 1629588512 Abrams Leslie NP Nurse Practitioner 1326078692 Abrams Geoffrey MD Orthopaedic Surgery 1285821223 Acker Peter MD Emergency Medicine 1639480718 Ackerman Jack DO Internal Medicine 1780794107 Adey Jennifer MD Obstetrics & Gynecology 1417202508 Adler Sarah PsyD Psychology 1194011619 Admani Shehla MD Dermatology 1073805248 Adriano Aileen MD Anesthesiology 1558311886 Advani Ranjana MD Medical Oncology 1639225121 Agarwal Rita MD Anesthesiology 1437264793 Agarwala Vineeta MD Internal Medicine 1619408903 Agely Ali MD Diagnostic Radiology 1073991360 Aggarwal Anuj MD Anesthesiology 1659703288 Aghajanova Lusine MD Obstetrics & Gynecology 1427315522 Ahearn Patrick MD Nephrology 1972878072 Ahmad Shahzad MD Pulmonary Disease 1730110123 Ahmad Maleeha Visiting Neurological Surgery 1538535612 Ahmad Iram MD Otolaryngology 1316174014 Ahmed -

Estonia “Has No Time”: Existential Politics at the End of Empire
Estonia “has no time”: Existential Politics at the End of Empire Kaarel PIIRIMÄE Associate Professor in History University of Helsinki (FI) University of Tartu (EE) [email protected] Abstract This article is about the Estonian transition from the era of perestroika to the 1990s. It suggests that the Estonian national movement considered the existence of the nation to be threatened. Therefore, it used the window of opportunity presented by perestroika to take control of time and break free of the empire. This essay has the following theoretical premises. First, Estonia was not engaged in “normal politics” but in something that I will conceptualise, following the Copenhagen School, as “existential politics.” Second, the key feature of existential politics is time. I will draw on the distinction, made in the ancient Greek thought, between the gods Chronos and Kairos. By applying these concepts to Estonia, I suggest Kairos presented the opportunity to break the normal flow of time and the decay of Socialism (Chronos) in order to fight for the survival of the Estonian nation. The third starting point is Max Weber’s historical sociology, particularly his notion of “charisma,” developed in Stephen Hanson’s interpretation of the notions of time in Marxism-Leninism-Stalinism. Based on this, I will argue that Estonian elites thought they were living in extraordinary times that required the breaking of the normal flow of time, which was thought to be corroding the basis of the nation’s existence. Keywords: Notions of Time, Existential Politics, Perestroika, Estonia, Soviet Union, Social Transitions. Résumé Cet article porte sur la transition estonienne de la perestroïka aux années 1990.