Revised Proposal to Encode Old Uyghur in Unicode
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Critique of L2/18-276
A Critique of L2/18-276 Abe Meyers* November 30, 2018 Contents 1 Introduction 1 2 Multiple incompatible representations 2 2.1 <gimel-daleth-yodh> + <shin> vs <aleph-heth> + <aleph-heth> 3 2.2 <Fixed-aleph> + <gimel-daleth-yodh> vs <fixed-gimel-daleth-yodth> + <aleph> ............................. 3 2.3 <gimel-daleth-yodth> + <gimel-daleth> vs <samekh> . 3 2.4 <pe> vs <sadhe> ......................... 4 3 Miscellaneous issues 4 3.1 Joining of <aleph-heth> ..................... 5 3.2 Missing alternate form of <gimel-daleth-yodh> . 5 3.3 Inclusion of <HE> ......................... 5 3.4 Joining of <zayin> ........................ 5 3.5 Old lamedth . 5 4 The dogma of shape-shifting and the problem of good-enough 5 5 Bibliography 6 1 Introduction It has been a source of delight that after a dormant period of four years, since the submission of my proposal to encode Book Pahlavi in the Unicode *abraham.meyers AT orientology DOT ca 1 standard, there has been some renewed activity in the community. The recent preliminary proposal by Dr. Anshuman Pandey (L2/18-276) might therefore signal a resurgence of activities towards the noble goal of encoding of Book Pahlavi in the Unicode standard. I started reading the work of Dr. Pandey with enthusiasm and in antic- ipation of further improvement and suggestions and perhaps discovery of new characters. It was indeed pleasant to see a relatively thorough classica- tion of the visual joining of the stem of the characters of Book Pahlavi, while taking the base-line into consideration. Such studies will be very benecial for the future type designers of Book Pahlavialthough I have doubts about the applicability of this study to the level of abstraction pertaining to the Unicode standard. -

Arabic Alphabet - Wikipedia, the Free Encyclopedia Arabic Alphabet from Wikipedia, the Free Encyclopedia
2/14/13 Arabic alphabet - Wikipedia, the free encyclopedia Arabic alphabet From Wikipedia, the free encyclopedia َأﺑْ َﺠ ِﺪﯾﱠﺔ َﻋ َﺮﺑِﯿﱠﺔ :The Arabic alphabet (Arabic ’abjadiyyah ‘arabiyyah) or Arabic abjad is Arabic abjad the Arabic script as it is codified for writing the Arabic language. It is written from right to left, in a cursive style, and includes 28 letters. Because letters usually[1] stand for consonants, it is classified as an abjad. Type Abjad Languages Arabic Time 400 to the present period Parent Proto-Sinaitic systems Phoenician Aramaic Syriac Nabataean Arabic abjad Child N'Ko alphabet systems ISO 15924 Arab, 160 Direction Right-to-left Unicode Arabic alias Unicode U+0600 to U+06FF range (http://www.unicode.org/charts/PDF/U0600.pdf) U+0750 to U+077F (http://www.unicode.org/charts/PDF/U0750.pdf) U+08A0 to U+08FF (http://www.unicode.org/charts/PDF/U08A0.pdf) U+FB50 to U+FDFF (http://www.unicode.org/charts/PDF/UFB50.pdf) U+FE70 to U+FEFF (http://www.unicode.org/charts/PDF/UFE70.pdf) U+1EE00 to U+1EEFF (http://www.unicode.org/charts/PDF/U1EE00.pdf) Note: This page may contain IPA phonetic symbols. Arabic alphabet ا ب ت ث ج ح خ د ذ ر ز س ش ص ض ط ظ ع en.wikipedia.org/wiki/Arabic_alphabet 1/20 2/14/13 Arabic alphabet - Wikipedia, the free encyclopedia غ ف ق ك ل م ن ه و ي History · Transliteration ء Diacritics · Hamza Numerals · Numeration V · T · E (//en.wikipedia.org/w/index.php?title=Template:Arabic_alphabet&action=edit) Contents 1 Consonants 1.1 Alphabetical order 1.2 Letter forms 1.2.1 Table of basic letters 1.2.2 Further notes -

Page 1 CHAPTER EIGHTEEN on INFIĀL and IFTIĀL These Two Verb
CHAPTER EIGHTEEN ON INFIʿĀL AND IFTIʿĀL These two verb types are intransitive. Conjugational patterns of .הִבָנֵה ,הִשָׁחֵט ,הִמָלֵט ,.the type of inʿāl do not contain a taw, e.g A conjugational pattern of the type of iftiʿāl has a taw that nev- -The taw of iftiʿāl does not oc .הִתְאַמֵץ ,הִתְמַכֵר er disappears, as in cur between radicals, unless the #rst radical is a samekh, a ṣadi or a shin. Other letters do not come before the taw, as do samekh, ,(Micah 6:16) וישתמר חקות עמרי ,(Eccl. 12:5) ויסתבל החגב ,.ṣadi and shin, e.g and similar cases. An exception to this is one word beginning in a -Jer. 49:3), in which the taw occurs be) והתשוטטנה בגדרות ,shin, namely fore the shin. As for ṣadi, they said that the people of the lan- guage substituted a ṭet for the taw after the ṣadi in order to ease ומה ,(Josh. 9:4) וילכו ויצטירו ,(Josh. 9:12) חם הצטידנו אותו ,.pronunciation, e.g .(Gen. 44:16) נצטדק Take note that the taw of iftiʿāl cannot be confused with the fu- ture pre#x taw, because the taw of iftiʿāl is stable in the entire paradigm, but the future pre#x taw is not. Moreover, the vocali- sation of the taw of iftiʿāl is a shewa in all cases when it does not occur between the #rst and the second radical. But the pre#xes can be vocalised with a shewa or other vowels. Moreover, a א֗ ֗ י ֗ נ ת֗ word can never begin in the taw of iftiʿāl, but another letter must come before it, be it a heh, a mem, or a future pre#x. -
![Adaptations of Hebrew Script -Mala Enciklopedija Prosvetq I978 [Small Prosveta Encyclopedia]](https://docslib.b-cdn.net/cover/2327/adaptations-of-hebrew-script-mala-enciklopedija-prosvetq-i978-small-prosveta-encyclopedia-702327.webp)
Adaptations of Hebrew Script -Mala Enciklopedija Prosvetq I978 [Small Prosveta Encyclopedia]
726 PART X: USE AND ADAPTATION OF SCRIPTS Series Minor 8) The Hague: Mouton SECTION 6I Ly&in, V. I t952. Drevnepermskij jazyk [The Old Pemic language] Moscow: Izdalel'slvo Aka- demii Nauk SSSR ry6r. Komi-russkij sLovar' [Komi-Russian diclionary] Moscow: Gosudarstvennoe Izda- tel'slvo Inostrannyx i Nacional'nyx Slovuej. Adaptations of Hebrew Script -MaLa Enciklopedija Prosvetq I978 [Small Prosveta encycloPedia]. Belgrade. Moll, T. A,, & P. I InEnlikdj t951. Cukotsko-russkij sLovaf [Chukchee-Russian dicrionary] Len- BENJAMIN HARY ingrad: Gosudtrstvemoe udebno-pedagogideskoe izdatel'stvo Ministerstva Prosveldenija RSFSR Poppe, Nicholas. 1963 Tatqr Manual (Indima Universily Publications, Uralic atrd Altaic Series 25) Mouton Bloomington: Indiana University; The Hague: "lagguages" rgjo. Mongolian lnnguage Handbook.Washington, D C.: Center for Applied Linguistics Jewish or ethnolects HerbertH Papet(Intema- Rastorgueva,V.S. 1963.A ShortSketchofTajikGrammar, fans anded It is probably impossible to offer a purely linguistic definition of a Jewish "language," tional Joumal ofAmerican Linguisticr 29, no part 2) Bloominglon: Indiana University; The - 4, as it is difficult to find many cornmon linguistic criteria that can apply to Judeo- Hague: Moulon. (Russiu orig 'Kratkij oderk grammatiki lad;ikskogo jzyka," in M. V. Rax- Arabic, Judeo-Spanish, and Yiddish, for example. Consequently, a sociolinguistic imi & L V Uspenskaja, eds,Tadiikskurusstj slovar' lTajik-Russian dictionary], Moscow: Gosudustvennoe Izdatel'stvo Inostrmyx i Nacional'tryx SIovarej, r954 ) definition with a more suitable term, such as ethnolect, is in order. An ethnolect is an Sjoberg, Andr€e P. t963. Uzbek StructuraL Grammar (Indiana University Publications, Uralic and independent linguistic entity with its own history and development that refers to a lan- Altaic Series r8). -

Elites in Between Ethnic Mongolians and the Han in China 39
Elites in Between Ethnic Mongolians and the Han in China 39 Chelegeer Contents Introduction ...................................................................................... 696 MINZU in China at a Glance ................................................................ 696 Mongolian Elites Before 1949 .................................................................. 699 The Old Nobility ............................................................................. 700 From Old House to New Elite ............................................................... 702 Mongol MINZU from 1949 to 1979 ............................................................ 704 Economic and Cultural Reforming .......................................................... 705 MINZU as Social Transformation ........................................................... 707 Ongoing Generations from the 1980s ........................................................... 709 Conclusion ....................................................................................... 711 References ....................................................................................... 712 Abstract Whether an ethnicity or a nationality is a natural and historical entity with clear self-consciousness, or a constructed identity as one of the consequences of modernity, there are always academic debates in sociology. By concerning Mongolian elites, this chapter argues their essential role in interacting with Han, the dominant population of China, through history and informing their -

Learn-The-Aramaic-Alphabet-Ashuri
Learn The ARAMAIC Alphabet 'Hebrew' Ashuri Script By Ewan MacLeod, B.Sc. Hons, M.Sc. 2 LEARN THE ARAMAIC ALPHABET – 'HEBREW' ASHURI SCRIPT Ewan MacLeod is the creator of the following websites: JesusSpokeAramaic.com JesusSpokeAramaicBook.com BibleManuscriptSociety.com Copyright © Ewan MacLeod, JesusSpokeAramaic.com, 2015. All Rights Reserved. No part of this publication may be reproduced, stored in, or introduced into, a retrieval system, or transmitted, in any form, or by any means (electronic, mechanical, scanning, photocopying, recording or otherwise) without prior written permission from the copyright holder. The right of Ewan MacLeod to be identified as the author of this work has been asserted by him in accordance with the Copyright, Designs and Patents Act 1988. This book is sold subject to the condition that it shall not, by way of trade or otherwise, be lent, resold, hired out, or otherwise circulated without the copyright holder's prior consent, in any form, or binding, or cover, other than that in which it is published, and without a similar condition, including this condition, being imposed on the subsequent purchaser. Jesus Spoke AramaicTM is a Trademark. 3 Table of Contents Introduction To These Lessons.............................................................5 How Difficult Is Aramaic To Learn?........................................................7 Introduction To The Aramaic Alphabet And Scripts.............................11 How To Write The Aramaic Letters....................................................... 19 -

Encoding Diversity for All the World's Languages
Encoding Diversity for All the World’s Languages The Script Encoding Initiative (Universal Scripts Project) Michael Everson, Evertype Westport, Co. Mayo, Ireland Bamako, Mali • 6 May 2005 1. Current State of the Unicode Standard • Unicode 4.1 defines over 97,000 characters 1. Current State of the Unicode Standard: New Script Additions Unicode 4.1 (31 March 2005): For Unicode 5.0 (2006): Buginese N’Ko Coptic Balinese Glagolitic Phags-pa New Tai Lue Phoenician Nuskhuri (extends Georgian) Syloti Nagri Cuneiform Tifinagh Kharoshthi Old Persian Cuneiform 1. Current State of the Unicode Standard • Unicode 4.1 defines over 97,000 characters • Unicode covers over 50 scripts (many of which are used for languages with over 5 million speakers) 1. Current State of the Unicode Standard • Unicode 4.1 defines over 97,000 characters • Unicode covers over 50 scripts (often used for languages with over 5 million speakers) • Unicode enables millions of users worldwide to view web pages, send e-mails, converse in chat-rooms, and share text documents in their native script 1. Current State of the Unicode Standard • Unicode 4.1 defines over 97,000 characters • Unicode covers over 50 scripts (often used for languages with over 5 million speakers) • Unicode enables millions of users worldwide to view web pages, send e-mails, converse in chat- rooms, and share text documents in their native script • Unicode is widely supported by current fonts and operating systems, but… Over 80 scripts are missing! Missing Modern Minority Scripts India, Nepal, Southeast Asia China: -
Grammar Chapter 1.Pdf
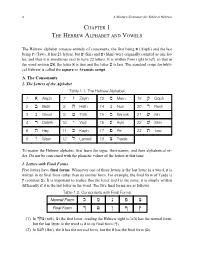
4 A Modern Grammar for Biblical Hebrew CHAPTER 1 THE HEBREW ALPHABET AND VOWELS Aleph) and the last) א The Hebrew alphabet consists entirely of consonants, the first being -Shin) were originally counted as one let) שׁ Sin) and) שׂ Taw). It has 23 letters, but) ת being ter, and thus it is sometimes said to have 22 letters. It is written from right to left, so that in -is last. The standard script for bibli שׁ is first and the letter א the letter ,אשׁ the word written cal Hebrew is called the square or Aramaic script. A. The Consonants 1. The Letters of the Alphabet Table 1.1. The Hebrew Alphabet Qoph ק Mem 19 מ Zayin 13 ז Aleph 7 א 1 Resh ר Nun 20 נ Heth 14 ח Beth 8 ב 2 Sin שׂ Samek 21 ס Teth 15 ט Gimel 9 ג 3 Shin שׁ Ayin 22 ע Yod 16 י Daleth 10 ד 4 Taw ת Pe 23 פ Kaph 17 כ Hey 11 ה 5 Tsade צ Lamed 18 ל Waw 12 ו 6 To master the Hebrew alphabet, first learn the signs, their names, and their alphabetical or- der. Do not be concerned with the phonetic values of the letters at this time. 2. Letters with Final Forms Five letters have final forms. Whenever one of these letters is the last letter in a word, it is written in its final form rather than its normal form. For example, the final form of Tsade is It is important to realize that the letter itself is the same; it is simply written .(צ contrast) ץ differently if it is the last letter in the word. -

1דwriting Hebrew
Writing Hebrew ד1 Reading Biblical Hebrew Chapter 1: Consonants John C. Beckman 2016-08-08 Goal: Learn to Write the Hebrew Alefbet 2 General comments • Stroke order and direction are suggested but optional. • Precise letter shapes are optional. • Only certain features are required (e.g., foot on nun) • All letters are full height, unless otherwise noted. Dot (Dagesh or Mappiq) is shown with all letters. • It is not part of the letters. • Don’t add it when writing the alefbet. • Chapter 3 discusses when the dot is added. • It is shown now so that you know where it goes. 3 א ל ָ֫ ָ֫ ף Alef 1 2 3 4 בֵּ ית Bet 1 2 כ from Kaf ב Bump on lower right distinguishes Bet 5 ג ימֵּ ל Gimel Optional hook 1 in top left 2 6 ד לת Dalet 1 2 ר from Resh ד Bump on upper right distinguishes Dalet 7 הֵּ א He 1 2 ח from ḥet ה Gap in upper left distinguishes he 8 וו Vav Optional hook in top left 1 .extends below . ן is half height. Final nun י is full height. Yod ו Vav 9 ז ין Zayin 1 2 ו from vav ז Bump on upper right distinguishes zayin 10 חֵּ ית Ḥet 1 2 ה from he ח Lack of gap in upper left distinguishes ḥet 11 טֵּ ית Tet 1 12 יֹוד Yod Optional hook in top left 1 .is full height ו is half height. Vav י Yod .extends below the baseline . ן Final nun 13 כף Kaf 1 ב from bet כ Round lower right distinguishes kaf 14 כ ףָ֫סֹופית Final Kaf 1 Alternately, final kaf can be a single curved line 2 ן from final nun . -

Old Phrygian Inscriptions from Gordion: Toward A
OLD PHRYGIAN INSCRIPTIONSFROM GORDION: TOWARD A HISTORY OF THE PHRYGIAN ALPHABET1 (PLATES 67-74) JR HRYYSCarpenter's discussion in 1933 of the date of the Greektakeover of the Phoenician alphabet 2 stimulated a good deal of comment at the time, most of it attacking his late dating of the event.3 Some of the attacks were ill-founded and have been refuted.4 But with the passage of time Carpenter's modification of his original thesis, putting back the date of the takeover from the last quarter to the middle of the eighth century, has quietly gained wide acceptance.5 The excavations of Sir Leonard Woolley in 1936-37 at Al Mina by the mouth of the Orontes River have turned up evidence for a permanent Greek trading settle- ment of the eighth century before Christ, situated in a Semitic-speaking and a Semitic- writing land-a bilingual environment which Carpenter considered essential for the transmission of alphabetic writing from a Semitic- to a Greek-speakingpeople. Thus to Carpenter's date of ca. 750 B.C. there has been added a place which would seem to fulfill the conditions necessary for such a takeover, perhaps only one of a series of Greek settlements on the Levantine coast.6 The time, around 750 B.C., the required 1The fifty-one inscriptions presented here include eight which have appeared in Gordion preliminary reports. It is perhaps well (though repetitive) that all the Phrygian texts appear together in one place so that they may be conveniently available to those interested. A few brief Phrygian inscriptions which add little or nothing to the corpus are omitted here. -

Old Turkic Script
Old Turkic script The Old Turkic script (also known as variously Göktürk script, Orkhon script, Orkhon-Yenisey script, Turkic runes) is the Old Turkic script alphabet used by the Göktürks and other early Turkic khanates Type Alphabet during the 8th to 10th centuries to record the Old Turkic language.[1] Languages Old Turkic The script is named after the Orkhon Valley in Mongolia where early Time 6th to 10th centuries 8th-century inscriptions were discovered in an 1889 expedition by period [2] Nikolai Yadrintsev. These Orkhon inscriptions were published by Parent Proto-Sinaitic(?) Vasily Radlov and deciphered by the Danish philologist Vilhelm systems Thomsen in 1893.[3] Phoenician This writing system was later used within the Uyghur Khaganate. Aramaic Additionally, a Yenisei variant is known from 9th-century Yenisei Syriac Kirghiz inscriptions, and it has likely cousins in the Talas Valley of Turkestan and the Old Hungarian alphabet of the 10th century. Sogdian or Words were usually written from right to left. Kharosthi (disputed) Contents Old Turkic script Origins Child Old Hungarian Corpus systems Table of characters Direction Right-to-left Vowels ISO 15924 Orkh, 175 Consonants Unicode Old Turkic Variants alias Unicode Unicode U+10C00–U+10C4F range See also (https://www.unicode. org/charts/PDF/U10C Notes 00.pdf) References External links Origins According to some sources, Orkhon script is derived from variants of the Aramaic alphabet,[4][5][6] in particular via the Pahlavi and Sogdian alphabets of Persia,[7][8] or possibly via Kharosthi used to write Sanskrit (cf. the inscription at Issyk kurgan). Vilhelm Thomsen (1893) connected the script to the reports of Chinese account (Records of the Grand Historian, vol. -

Uyghur Five Reasons Why You Should Uyghur Learn More About Uyghurs ياخشىمۇسىز، مېنىڭ ئىسمىم جون
SOME USEFUL PHRASES IN UYGHUR FIVE REASONS WHY YOU SHOULD UYGHUR LEARN MORE ABOUT UYGHURS ياخشىمۇسىز، مېنىڭ ئىسمىم جون. [jɑχˈʃɪmusɪz mɛˈnɪŋ ɪsˈmɪm ʤɑn] AND THEIR LANGUAGE /Yakh-shimusiz, mening ismim Jon./ 1. Uyghur is spoken natively by over 11 million Hi. My name is John. worldwide, mainly in the Xinjiang Uyghur Autonomous Region, but in other Central ئىسمىڭىز نېمە؟ [ˈɪsmɪŋɪz nɪˈmɛ] Asia countries as well, specifically Kazakhstan /Ismingiz nime?/ and Uzbekistan. What is your name? 2. As a member of the Altaic language family, Uyghur shares structural similarities to other قانداق ئەھۋالىڭىز؟ [qɑnˈdɑq ɛhˈwɑlɪŋɪz] Turkic languages such as vowel harmony and /Qandaq eh-walingiz?/ subject–object–verb word order, and it is a How are you doing? gateway to learning other Turkic languages, .such as Chaghatay قانداق ئەھۋالىڭىز؟ مەن ئىندىيانادىن. [sɪz qɛyɛrˈdɪn mɛn ɪndiˈɑnɑdɪn] 3. Uyghur is the only major Turkic language to /Siz qeyerdin? Men Indianadin./ still predominately use a Perso-Arabic writing Where are you from? I am from Indiana. system. The Xinjiang Uyghur Autonomous Region of .4 ئازراق چاي ئىچەمسىز؟ [ɑzˈrɑq ʧɑɪ ˈɪʧɛmsɪz] the People’s Republic of China is the largest /Azraq chay ichemsiz?/ Chinese administrative division and spans Would you like some tea? 642,800 sq mi. Uyghur cuisine is a perfect blend of Central .5 ئېتىڭىز بەك چىرايلىقكەن. [ˈɛtɪŋɪz bɛk ʧɪˈrɑɪlɪqkɛn] Asia and Chinese influeces. Using lots of /Etingiz bek chirayliqken./ seasonings, fresh vegetables an assortment of You have a beautiful horse. meats, including beef, chicken, fish, goose, !mutton, and camel ھاجەتخانا قەيەردە؟ [hɑˈʤɛt•χɑˌnɑ ˈqɛjɛrdɛ] /Hajet-khana qeyerde?/ Where is the bathroom? ABOUT US The Center for Languages of the Central Asian Region at Indiana University develops materials, online language كۆپ رەھمەت! [køp rɛχˈmɛt] courses, and mobile apps for learning and teaching a wide /Köp rekh-met!/ variety of Central Asian languages.