Economics 250A Lecture 1: a Very Quick Overview of Consumer Choice
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Calculating a Giffen Good
WINPEC Working Paper Series No.E1908 June 2019 Calculating a Giffen Good Kazuyuki Sasakura Waseda INstitute of Political EConomy Waseda University Tokyo, Japan Calculating a Giffen Good Kazuyuki Sasakura¤ June 6, 2019 Abstract This paper provides a simple example of the utility function with two consumption goods which can be calculated by hand to produce a Giffen good. It is based on the theoretical result by Kubler, Selden, and Wei (2013). Using a model of portfolio selection with a risk-free asset and a risky asset, they showed that the risk-free asset becomes a Giffen good if the utility belongs to the HARA family. This paper investigates their result further in a usual microeconomic setting, and derives the conditions for one of the consumption goods to be a Giffen good from a broader perspective. Key words: HARA family, Decreasing relative risk aversion, Giffen good, Slutsky equation, Ratio effect JEL classification: D11, D01, G11 1 Introduction Since Marshall (1895) mentioned a possibility of a Giffen good, economists have been trying to find it theoretically and empirically. Although their sincere efforts must be respected, it is also recognized among them that such a good seldom, if ever, shows up as Marhsall already said.1 But the recent theoretical result by Kubler, Selden, and Wei (2013) seems to be a solid example for a Giffen good. Using a model of portfolio selection with a risk-free asset and a risky asset, they showed that there always exists a parameter set which assures that the risk-free asset becomes a Giffen good if the utility belongs to the HARA (hyperbolic absolute risk aversion) family with decreasing absolute risk aversion (DARA) and decreasing relative risk aversion (DRRA).2 As is well known, Arrow (1971) proposed both DARA and increasing relative risk aversion (IRRA) because the former means that a risky asset is a normal good, while the latter means that a risk-free asset is a normal good the wealth elasticity of the demand for which exceeds one as is observed in reality. -

3. Slutsky Equations Slutsky 方程式 Y
Part 2C. Individual Demand Functions 3. Slutsky Equations Slutsky 方程式 Own-Price Effects A Slutsky Decomposition Cross-Price Effects Duality and the Demand Concepts 2014.11.20 1 Own-Price Effects Q: Wha t h appens t o purch ases of good x chhhange when px changes? x/px Differentiation of the FOCsF.O.Cs from utility maximization could be used. HHthiowever, this approachhi is cumb ersome and provides little economic insight. 2 The Identity b/w Marshallian & Hicksian Demands: * Since x = x(px, py, I) = hx(px, py, U) Replacing I by the EF, e(px, py, U), and U by gives x(px, py, e(px, py, )) = hx(px, py, ) Differenti ati on ab ove equati on w.r.t. px, we have xxehx x pepp x x xx p x U = constant I = hx = x x xx x pp I xxU = constant 3 x xx x pp I xxU = constant S.E. I.E. ( – ) ( ?) The S. E. is always negative h x 0 as long as MRS is diminishing. px The Law of Deman d hldholds x x as long as x is a normal good. 00 Ipx xx If x is a Giffen good , 00 hen x must be an inferior good. pIx E/px = hx = x A$1iA $1 increase in px raiditises necessary expenditures by x dollars. 4 Compensated Demand Elasticities The compensated demand function: hx(px, py, U) Compensated OwnOwn--PricePrice Elasticity of Demand dhx hhp e x xx hpx , x dp x px hx px Compensated CrossCross--PricePrice Elasticity of Demand dhx hh p e xxy hpxy, dp y phyx p x 5 OwnOwn--PricePrice Elasticity form of the Slutsky Equation x h x x x ppxx I x php xI p xxx x x pxxx p x IxI ee se x,,pxxxhIh pxx ,I px where s x Expenditure share on x. -

More on Consumer Theory: Identities and Slutsky's Equation
Economics 101A Section Notes GSI: David Albouy More on Consumer Theory: Identities and Slutsky’s Equation 1 Identities Relating the UMP and the EMP The UMP and EMP discussed earlier are mathematically known as "dual" problems. What is a constraint in one is the objective in the other and vice-versa. Furthermore their solutions are very similar, and both are characterized by the same tangency condition, with the only major di¤erence coming from the di¤erence in the constraints: the budget constraint for the UMP and minimum utility constraint for the EMP. Some useful identities can be given on how their solutions are related. As shown earlier the maximum of utility attained in the UMP is given by the indirect utility function V (px, py, I). If we substitute the indirect utility function in for the minimum level utility in the EMP, i.e. we set the constraint U (x, y) ¸ V (px, py, I) = u, and minimize expenditure pxx+pyy. The solution of this particular EMP will be identical to the initial UMP. This can be seen since we will be along the same indi¤erence curve as we ended up in the UMP (characterized by U (x, y) = V (px, py, I) = u - remember since px, py, and I are given V (px, py, I) is just a number) and since we will be at a point where @U @x (x, y) px MRS (x, y) = @U = @y (x, y) py with an amount of expenditure equal to the amount of income I given in the UMP. -

G021 Microeconomics Lecture Notes Ian Preston
G021 Microeconomics Lecture notes Ian Preston 1 Consumption set and budget set The consumption set X is the set of all conceivable consumption bundles q, n usually identified with R+ The budget set B ⊂ X is the set of affordable bundles In standard model individuals can purchase unlimited quantities at constant prices p subject to total budget y. The budget set is the Walrasian, competitive or linear budget set: n 0 B = {q ∈ R+|p q ≤ y} Notice this is a convex, closed and bounded set with linear boundary p0q = y. Maximum affordable quantity of any commodity is y/pi and slope dqi/dqj|B = −pj/pi is constant and independent of total budget. In practical applications budget constraints are frequently kinked or discon- tinuous as a consequence for example of taxation or non-linear pricing. 2 Marshallian demands, elasticities and types of good The consumer chooses bundles f(y, p) ∈ B known as Marshallian, uncompen- sated, competitive or market demands. In general the consumer may be prepared to choose more than one bundle in which case f(y, p) is a demand correspon- dence but typically a single bundle is chosen and f(y, p) is a demand function. We wish to understand the effects of changes in y and p on demand for, say, the ith good: • total budget y – the path traced out by demands in q-space as y increases is called the income expansion path whereas the graph of fi(y, p) as a function of y is called the Engel curve – for differentiable demands we can summarise dependence in the total budget elasticity y ∂qi ∂ ln qi i = = qi ∂y ∂ ln y 1 3 PROPERTIES -

ECON2001 Microeconomics Lecture Notes Budget Constraint
ECON2001 Lecture Notes ECON2001 Microeconomics Lecture Notes Term 1 Ian Preston Budget constraint Consumers purchase goods q from within a budget set B of affordable bun- dles. In the standard model, prices p are constant and total spending has to remain within budget p0q ≤ y where y is total budget. Maximum affordable quantity of any commodity is y/pi and slope ∂qi/∂qj|B = −pj/pi is constant and independent of total budget. In practical applications budget constraints are frequently kinked or discon- tinuous as a consequence for example of taxation or non-linear pricing. If the price of a good rises with the quantity purchased (say because of taxation above a threshold) then the budget set is convex whereas if it falls (say because of a bulk buying discount) then the budget set is not convex. Marshallian demands The consumer’s chosen quantities written as a function of y and p are the Marshallian or uncompensated demands q = f(y, p) Consider the effects of changes in y and p on demand for, say, the ith good: • total budget y – the path traced out by demands as y increases is called the income expansion path whereas the graph of fi(y, p) as a function of y is called the Engel curve – we can summarise dependence in the total budget elasticity y ∂qi ∂ ln qi i = = qi ∂y ∂ ln y – if demand for a good rises with total budget, i > 0, then we say it is a normal good and if it falls, i < 0, we say it is an inferior good – if budget share of a good, wi = piqi/y, rises with total budget, i > 1, then we say it is a luxury or income elastic and if it -

Expenditure Minimisation Problem
Expenditure Minimisation Problem Simon Board This Version: September 20, 2009 First Version: October, 2008. The expenditure minimisation problem (EMP) looks at the reverse side of the utility maximisa- tion problem (UMP). The UMP considers an agent who wishes to attain the maximum utility from a limited income. The EMP considers an agent who wishes to ¯nd the cheapest way to attain a target utility. This approach complements the UMP and has several rewards: ² It enables us to analyse the e®ect of a price change, holding the utility of the agent constant. ² It enables us to decompose the e®ect of a price change on an agent's Marshallian demand into a substitution e®ect and an income e®ect. This decomposition is called the Slutsky equation. ² It enables us to calculate how much we need to compensate a consumer in response to a price change if we wish to keep her utility constant. 1 Model We make several assumptions: 1. There are N goods. For much of the analysis we assume N = 2 but nothing depends on this. 2. The agent takes prices as exogenous. We normally assume prices are linear and denote them by fp1; : : : ; pN g. 1 Eco11, Fall 2009 Simon Board 3. Preferences satisfy completeness, transitivity and continuity. As a result, a utility func- tion exists. We normally assume preferences also satisfy monotonicity (so indi®erence curves are well behaved) and convexity (so the optima can be characterised by tangency conditions). The expenditure minimisation problem is XN min pixi subject to u(x1; : : : ; xN ) ¸ u (1.1) x1;:::;xN i=1 xi ¸ 0 for all i The idea is that the agent is trying to ¯nd the cheapest way to attain her target utility, u. -

Demand Functions, Income Effects and Substitution
Demand Functions, Income E¤ects and Substitution E¤ects: Theory and Evidence David Autor 14.03 Fall 2004 1 The e¤ect of price changes on Marshallian demand A simple change in the consumer’s budget (i.e., an increase or decrease or I) involves a parallel shift of the feasible consumption set inward or outward from the origin. This economics of this are simple. Since this shift preserves the price ratio px ; it typically has no e¤ect on the consumer’s marginal rate of py substitution (MRS), Ux ; unless the chosen bundle is either initially or ultimately at a corner solution. Uy A rise in the price of one good holding constant both income and the price of other goods has economically more complex e¤ects: 1. It shifts the budget set inward toward the origin for the good whose price has risen. In other words, the consumer is now e¤ectively poorer. This component is the ‘incomee¤ect.’ 2. It changes the slope of the budget set so that the consumer faces a di¤erent set of market trade-o¤s. This component is the ‘price e¤ect.’ Although both shifts occur simultaneously, they are conceptually distinct and have potentially di¤erent implications for consumer behavior. 1.1 Income e¤ect First, consider the “income e¤ect.”What is the impact of an inward shift in the budget set in a 2-good economy (X1;X2): 1. Total consumption? [Falls] 2. Utility? [Falls] 3. Consumption of X1? [Answer depends on normal, inferior] 4. Consumption of X2? [Answer depends on normal, inferior] 1 1.2 Substitution e¤ect In the same two good economy, what happens to consumption of X1 if p1 p2 " but utility is held constant? In other words, we want the sign of @X1 Sign U=U . -

Hicksian & Marshallian Demand
INCOME AND SUBSTITUTION EFFECTS [See Chapter 5 and 6] 1 Two Demand Functions • Marshallian demand xi(p1,…,pn,m) describes how consumption varies with prices and income. – Obtained by maximizing utility subject to the budget constraint. • Hicksian demand hi(p1,…,pn,u) describes how consumption varies with prices and utility. – Obtained by minimizing expenditure subject to the utility constraint. 2 CHANGES IN INCOME 3 Changes in Income • An increase in income shifts the budget constraint out in a parallel fashion • Since p1/p2 does not change, the optimal MRS will stay constant as the worker moves to higher levels of utility. 4 Increase in Income • If both x1 and x2 increase as income rises, x1 and x2 are normal goods Quantity of x2 As income rises, the individual chooses to consume more x1 and x2 C B A U3 U2 U1 Quantity of x1 5 Increase in Income • If x1 decreases as income rises, x1 is an inferior good As income rises, the individual chooses to consume less x1 and more x2 Quantity of x2 Note that the indifference C curves do not have to be “oddly” shaped. The B U3 preferences are convex U2 A U1 Quantity of x1 6 Changes in Income • The change in consumption caused by a change in income from m to m’ can be computed using the Marshallian demands: x1 x1(p1, p2,m') x1(p1, p2 ,m) • If x1(p1,p2,m) is increasing in m, i.e. x1/m 0, then good 1 is normal. • If x1(p1,p2,m) is decreasing in m, i.e. -
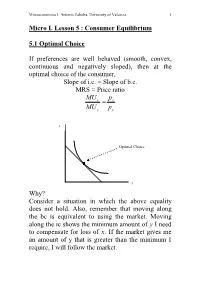
Micro I. Lesson 5 : Consumer Equilibrium
Microeconomics I. Antonio Zabalza. University of Valencia 1 Micro I. Lesson 5 : Consumer Equilibrium 5.1 Optimal Choice If preferences are well behaved (smooth, convex, continuous and negatively sloped), then at the optimal choice of the consumer, Slope of i.c. = Slope of b.c. MRS = Price ratio MUp xx= MUpyy y Optimal Choice x Why? Consider a situation in which the above equality does not hold. Also, remember that moving along the bc is equivalent to using the market. Moving along the ic shows the minimum amount of y I need to compensate for loss of x. If the market gives me an amount of y that is greater than the minimum I require, I will follow the market. Microeconomics I. Antonio Zabalza. University of Valencia 2 y C U(C) U(B) B B’ U(A) A x B’’ Microeconomics I. Antonio Zabalza. University of Valencia 3 At A, for instance, if I give up 1 unit of x (distance AB’’), the market gives me 1 unit of y (distance B’’B). But I would be satisfied with less; say, 0.25 units of y (distance B’B’’). Then, it is optimal for me to trade in the market, and go to point B where my utility U(B) is higher than that at point a, U(A). If I keep applying this reasoning I end up at point C. (Check that you understand this). Point C represents the best I can do, given my opportunities. Point C therefore represents the optimal choice, the equilibrium, of the consumer. -

Slutsky Revisited: a New Decomposition of the Price Effect
Ital Econ J (2016) 2:253–280 DOI 10.1007/s40797-016-0034-y RESEARCH PAPER Slutsky Revisited: A New Decomposition of the Price Effect Kazuyuki Sasakura1 Received: 26 February 2016 / Accepted: 26 April 2016 / Published online: 9 May 2016 © Società Italiana degli Economisti (Italian Economic Association) 2016 Abstract It is only the Slutsky equation that has been universally used to examine how the demand for a good responds to variations in its own price. This paper proposes an alternative to the Slutsky equation. It decomposes such a price effect into the “ratio effect” and the “unit-elasticity effect”. The “ratio effect” is positive (negative) if the expenditure spent on a good under consideration increases (decreases) when its own price rises, and it can be divided further into the familiar substitution effect and the “transfer effect” which reflects the income effect of other goods. The “unit-elasticity effect,” which is always negative, stands for unitary price elasticity of demand. It is also shown that the new method can be used for the analysis of the cross-price effect with and without initial endowments. The Slutsky equation and the new one are “complements”, but graphical representations as well as examples of the applications reveal that the latter is much easier to understand intuitively. Keywords The Slutsky equation · Price effect · Ratio effect · Unit-elasticity effect JEL Classification D11 I express my deepest gratitude to Professor Masamichi Kawano, Kwansei Gakuin University, and participants at the 2010 fall meeting of the Japanese Economic Association for their useful comments. This paper has also greatly improved due to detailed comments from an anonymous referee and the editor of this journal. -

Consumer Theory.Pdf
Consumer Theory Jonathan Levin and Paul Milgrom October 2004 1 The Consumer Problem Consumer theory is concerned with how a rational consumer would make consump- tion decisions. What makes this problem worthy of separate study, apart from the general problem of choice theory, is its particular structure that allows us to de- rive economically meaningful results. The structure arises because the consumer’s choice sets sets are assumed to be defined by certain prices and the consumer’s income or wealth. With this in mind, we define the consumer problem (CP) as: max u(x) x Rn ∈ + s.t. p x w · ≤ The idea is that the consumer chooses a vector of goods x =(x1, ..., xn)tomaximize herutilitysubjecttoabudget constraint that says she cannot spend more than her total wealth. What exactly is a “good”? The answer lies in the eye of the modeler. Depending on the problem to be analyzed, goods might be very specific, like tickets to different world series games, or very aggregated like food and shelter, or consumption and leisure. The components of x might refer to quantities of different goods, as if all consumption takes place at a moment in time, or they might refer to average rates of consumption of each good over time. If we want to emphasize the roles of quality, time and place, the description of a good could be something like “Number 1 2 grade Red Winter Wheat in Chicago.” Of course, the way we specify goods can affect the kinds of assumptions that make sense in a model. Some assumptions implicit in this formulation will be discussed below. -

Consumer Theory
Lectures 3—4: Consumer Theory Alexander Wolitzky MIT 14.121 1 Consumer Theory Consumer theory studies how rational consumer chooses what bundle of goods to consume. Special case of general theory of choice. Key new assumption: choice sets defined by prices of each of n goods, and income (or wealth). 2 Consumer Problem (CP) max u (x) x Rn ∈ + s.t. p x w · ≤ Interpretation: � Consumer chooses consumption vector x = (x1, ... , xn ) � xk is consumption of good k � Each unit of good k costs pk � Total available income is w Lectures 3—4 devoted to studying (CP). Lecture 5 covers some applications. 3 Now discuss some implicit assumptions underlying (CP). Prices are Linear Each unit of good k costs the same. No quantity discounts or supply constraints. Consumer’s choice set (or budget set) is B (p, w ) = x Rn : p x w { ∈ + · ≤ } Set is defined by single line (or hyperplane): the budget line p x = w · Assume p 0. ≥ 4 Goods are Divisible x Rn and consumer can consume any bundle in budget set ∈ + Can model indivisibilities by assuming utility only depends on integer part of x. 5 Set of Goods is Finite Debreu (1959): A commodity is characterized by its physical properties, the date at which it will be available, and the location at which it will be available. In practice, set of goods suggests itself naturally based on context. 6 Marshallian Demand The solution to the (CP) is called the Marshallian demand (or Walrasian demand). May be multiple solutions, so formal definition is: Definition The Marshallian demand correspondence x : Rn R Rn is + × � + defined by x (p, w ) = argmaxx B (p,w ) u (x) ∈ = z B (p, w ) : u (z) = max u (x) .