CMPUT 396: Alphago
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Discovery of Chinese Logic Modern Chinese Philosophy
The Discovery of Chinese Logic Modern Chinese Philosophy Edited by John Makeham, Australian National University VOLUME 1 The titles published in this series are listed at brill.nl/mcp. The Discovery of Chinese Logic By Joachim Kurtz LEIDEN • BOSTON 2011 This book is printed on acid-free paper. Library of Congress Cataloging-in-Publication Data Kurtz, Joachim. The discovery of Chinese logic / by Joachim Kurtz. p. cm. — (Modern Chinese philosophy, ISSN 1875-9386 ; v. 1) Includes bibliographical references and index. ISBN 978-90-04-17338-5 (hardback : alk. paper) 1. Logic—China—History. I. Title. II. Series. BC39.5.C47K87 2011 160.951—dc23 2011018902 ISSN 1875-9386 ISBN 978 90 04 17338 5 Copyright 2011 by Koninklijke Brill NV, Leiden, The Netherlands. Koninklijke Brill NV incorporates the imprints Brill, Global Oriental, Hotei Publishing, IDC Publishers, Martinus Nijhoff Publishers and VSP. All rights reserved. No part of this publication may be reproduced, translated, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without prior written permission from the publisher. Authorization to photocopy items for internal or personal use is granted by Koninklijke Brill NV provided that the appropriate fees are paid directly to The Copyright Clearance Center, 222 Rosewood Drive, Suite 910, Danvers, MA 01923, USA. Fees are subject to change. CONTENTS List of Illustrations ...................................................................... vii List of Tables ............................................................................. -
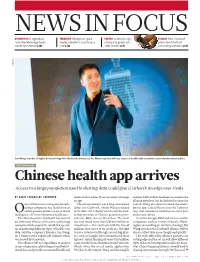
Chinese Health App Arrives Access to a Large Population Used to Sharing Data Could Give Icarbonx an Edge Over Rivals
NEWS IN FOCUS ASTROPHYSICS Legendary CHEMISTRY Deceptive spice POLITICS Scientists spy ECOLOGY New Zealand Arecibo telescope faces molecule offers cautionary chance to green UK plans to kill off all uncertain future p.143 tale p.144 after Brexit p.145 invasive predators p.148 ICARBONX Jun Wang, founder of digital biotechnology firm iCarbonX, showcases the Meum app that will use reams of health data to provide customized medical advice. BIOTECHNOLOGY Chinese health app arrives Access to a large population used to sharing data could give iCarbonX an edge over rivals. BY DAVID CYRANOSKI, SHENZHEN medical advice directly to consumers through another $400 million had been invested in the an app. alliance members, but he declined to name the ne of China’s most intriguing biotech- The announcement was a long-anticipated source. Wang also demonstrated the smart- nology companies has fleshed out an debut for iCarbonX, which Wang founded phone app, called Meum after the Latin for earlier quixotic promise to use artificial in October 2015 shortly after he left his lead- ‘my’, that customers would use to enter data Ointelligence (AI) to revolutionize health care. ership position at China’s genomics pow- and receive advice. The Shenzhen firm iCarbonX has formed erhouse, BGI, also in Shenzhen. The firm As well as Google, IBM and various smaller an ambitious alliance with seven technology has now raised more than US$600 million in companies, such as Arivale of Seattle, Wash- companies from around the world that special- investment — this contrasts with the tens of ington, are working on similar technology. But ize in gathering different types of health-care millions that most of its rivals are thought Wang says that the iCarbonX alliance will be data, said the company’s founder, Jun Wang, to have invested (although several big play- able to collect data more cheaply and quickly. -

Computer Go: from the Beginnings to Alphago Martin Müller, University of Alberta
Computer Go: from the Beginnings to AlphaGo Martin Müller, University of Alberta 2017 Outline of the Talk ✤ Game of Go ✤ Short history - Computer Go from the beginnings to AlphaGo ✤ The science behind AlphaGo ✤ The legacy of AlphaGo The Game of Go Go ✤ Classic two-player board game ✤ Invented in China thousands of years ago ✤ Simple rules, complex strategy ✤ Played by millions ✤ Hundreds of top experts - professional players ✤ Until 2016, computers weaker than humans Go Rules ✤ Start with empty board ✤ Place stone of your own color ✤ Goal: surround empty points or opponent - capture ✤ Win: control more than half the board Final score, 9x9 board ✤ Komi: first player advantage Measuring Go Strength ✤ People in Europe and America use the traditional Japanese ranking system ✤ Kyu (student) and Dan (master) levels ✤ Separate Dan ranks for professional players ✤ Kyu grades go down from 30 (absolute beginner) to 1 (best) ✤ Dan grades go up from 1 (weakest) to about 6 ✤ There is also a numerical (Elo) system, e.g. 2500 = 5 Dan Short History of Computer Go Computer Go History - Beginnings ✤ 1960’s: initial ideas, designs on paper ✤ 1970’s: first serious program - Reitman & Wilcox ✤ Interviews with strong human players ✤ Try to build a model of human decision-making ✤ Level: “advanced beginner”, 15-20 kyu ✤ One game costs thousands of dollars in computer time 1980-89 The Arrival of PC ✤ From 1980: PC (personal computers) arrive ✤ Many people get cheap access to computers ✤ Many start writing Go programs ✤ First competitions, Computer Olympiad, Ing Cup ✤ Level 10-15 kyu 1990-2005: Slow Progress ✤ Slow progress, commercial successes ✤ 1990 Ing Cup in Beijing ✤ 1993 Ing Cup in Chengdu ✤ Top programs Handtalk (Prof. -

GO WINDS Play Over 1000 Professional Games to Reach Recent Sets Have Focused on "How the Pros 1-Dan, It Is Said
NEW FROM YUTOPIAN ENTERPRISES GO GAMES ON DISK (GOGoD) SOFTWARE GO WINDS Play over 1000 professional games to reach Recent sets have focused on "How the pros 1-dan, it is said. How about 6-dan? Games of play the ...". So far there are sets covering the Go on Disk now offers over 6000 professional "Chinese Fuseki" Volume I (a second volume Volume 2 Number 4 Winter 1999 $3.00 games on disk, games that span the gamut of is in preparation), and "Nirensei", Volumes I go history - featuring players that helped and II. A "Sanrensei" volume is also in define the history. preparation. All these disks typically contain All game collections come with DOS or 300 games. Windows 95 viewing software, and most The latest addition to this series is a collections include the celebrated Go Scorer in "specialty" item - so special GoGoD invented which you can guess the pros' moves as you a new term for it. It is the "Sideways Chinese" play (with hints if necessary) and check your fuseki, which incorporates the Mini-Chinese score. pattern. Very rarely seen in western The star of the collection may well be "Go publications yet played by most of the top Seigen" - the lifetime games (over 800) of pros, this opening is illustrated by over 130 perhaps the century's greatest player, with games from Japan, China and Korea. Over more than 10% commented. "Kitani" 1000 half have brief comments. The next specialty makes an ideal matching set - most of the item in preparation is a set of games featuring lifetime games of his legendary rival, Kitani unusual fusekis - this will include rare New Minoru. -

Curriculum Guide for Go in Schools
Curriculum Guide 1 Curriculum Guide for Go In Schools by Gordon E. Castanza, Ed. D. October 19, 2011 Published By: Rittenberg Consulting Group 7806 108th St. NW Gig Harbor, WA 98332 253-853-4831 © 2005 by Gordon E. Castanza, Ed. D. Curriculum Guide 2 Table of Contents Acknowledgements ......................................................................................................................... 4 Purpose and Rationale..................................................................................................................... 5 About this curriculum guide ................................................................................................... 7 Introduction ..................................................................................................................................... 8 Overview ................................................................................................................................. 9 Building Go Instructor Capacity ........................................................................................... 10 Developing Relationships and Communicating with the Community ................................. 10 Using Resources Effectively ................................................................................................. 11 Conclusion ............................................................................................................................ 11 Major Trends and Issues .......................................................................................................... -

ELF Opengo: an Analysis and Open Reimplementation of Alphazero
ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero Yuandong Tian 1 Jerry Ma * 1 Qucheng Gong * 1 Shubho Sengupta * 1 Zhuoyuan Chen 1 James Pinkerton 1 C. Lawrence Zitnick 1 Abstract However, these advances in playing ability come at signifi- The AlphaGo, AlphaGo Zero, and AlphaZero cant computational expense. A single training run requires series of algorithms are remarkable demonstra- millions of selfplay games and days of training on thousands tions of deep reinforcement learning’s capabili- of TPUs, which is an unattainable level of compute for the ties, achieving superhuman performance in the majority of the research community. When combined with complex game of Go with progressively increas- the unavailability of code and models, the result is that the ing autonomy. However, many obstacles remain approach is very difficult, if not impossible, to reproduce, in the understanding of and usability of these study, improve upon, and extend. promising approaches by the research commu- In this paper, we propose ELF OpenGo, an open-source nity. Toward elucidating unresolved mysteries reimplementation of the AlphaZero (Silver et al., 2018) and facilitating future research, we propose ELF algorithm for the game of Go. We then apply ELF OpenGo OpenGo, an open-source reimplementation of the toward the following three additional contributions. AlphaZero algorithm. ELF OpenGo is the first open-source Go AI to convincingly demonstrate First, we train a superhuman model for ELF OpenGo. Af- superhuman performance with a perfect (20:0) ter running our AlphaZero-style training software on 2,000 record against global top professionals. We ap- GPUs for 9 days, our 20-block model has achieved super- ply ELF OpenGo to conduct extensive ablation human performance that is arguably comparable to the 20- studies, and to identify and analyze numerous in- block models described in Silver et al.(2017) and Silver teresting phenomena in both the model training et al.(2018). -

(CMPUT) 455 Search, Knowledge, and Simulations
Computing Science (CMPUT) 455 Search, Knowledge, and Simulations James Wright Department of Computing Science University of Alberta [email protected] Winter 2021 1 455 Today - Lecture 22 • AlphaGo - overview and early versions • Coursework • Work on Assignment 4 • Reading: AlphaGo Zero paper 2 AlphaGo Introduction • High-level overview • History of DeepMind and AlphaGo • AlphaGo components and versions • Performance measurements • Games against humans • Impact, limitations, other applications, future 3 About DeepMind • Founded 2010 as a startup company • Bought by Google in 2014 • Based in London, UK, Edmonton (from 2017), Montreal, Paris • Expertise in Reinforcement Learning, deep learning and search 4 DeepMind and AlphaGo • A DeepMind team developed AlphaGo 2014-17 • Result: Massive advance in playing strength of Go programs • Before AlphaGo: programs about 3 levels below best humans • AlphaGo/Alpha Zero: far surpassed human skill in Go • Now: AlphaGo is retired • Now: Many other super-strong programs, including open source Image source: • https://www.nature.com All are based on AlphaGo, Alpha Zero ideas 5 DeepMind and UAlberta • UAlberta has deep connections • Faculty who work part-time or on leave at DeepMind • Rich Sutton, Michael Bowling, Patrick Pilarski, Csaba Szepesvari (all part time) • Many of our former students and postdocs work at DeepMind • David Silver - UofA PhD, designer of AlphaGo, lead of the DeepMind RL and AlphaGo teams • Aja Huang - UofA postdoc, main AlphaGo programmer • Many from the computer Poker group -

Computer Wins Second GAME Against Chinese GO Champion
TECHNOLOGY SATURDAY, MAY 27, 2017 Samsung investigating Galaxy S8 ‘iris hack’ SEOUL: Samsung Electronics is investigating claims by a German hacking group that it fooled the iris recognition system of the new flagship Galaxy S8 device, the firm said yesterday. The launch of the Galaxy S8 was a key step for the world’s largest smartphone maker as it sought to move on from last year’s humiliating withdrawal of the fire-prone Galaxy Note 7s, which hammered the firm’s once-stellar reputation. But a video posted by the Chaos Computer Club (CCC), a German hacking group founded in 1981, shows the Galaxy S8 being unlocked using a printed photo of the owner’s eye covered with a contact lens to replicate the curvature of a real eyeball. “A high- resolution picture from the internet is sufficient to cap- ture an iris,” CCC spokesman Dirk Engling said, adding: “Ironically, we got the best results with laser printers made by Samsung.” A Samsung spokeswoman said it was aware of the report and was investigating. The iris scanning technolo- gy was “developed through rigorous testing”, the firm said in a statement as it sought to reassure customers. “If there is a potential vulnerability or the advent of a new method that challenges our efforts to ensure security at WUZHEN: Chinese Go player Ke Jie, left, looks at the board as a person makes a move on behalf of Google’s artificial any time, we will respond as quickly as possible to resolve intelligence program, AlphaGo, during a game of Go at the Future of Go Summit in Wuzhen in eastern China’s Zhejiang the issue.” Samsung’s hopes of competing against archri- Province. -

Encyclopedia of Life & Death
Cho Chikun’s Encyclopedia of Life & Death Part 3 — Advanced Motto “It is a matter of life and death, a road either to safety or to ruin. Hence it is a subject of inquiry which can on no account be neglected.” — Sun Tzu: The Art of War Preface This is a collection of almost three thousand problems from Encyclo- pedia of Life and Death by Cho Chikun. The problems come without solutions for two reasons: first, one can learn more by reading out all the paths and solving the problems oneself; second, the solutions are copyrighted. All the problems are black to move. In the third part, you can find about eight hundred problems aimed at advanced players. A dan player should find the solution in a few minutes and will need about 100 hours to solve the whole book. I wish you enjoyment and improvement in the wonderful game of go, weiqi, baduk, or whatever you like to call it. Vít ‘tasuki’ Brunner November 2004 Anniversary edition It’s been 13 and a half years. This booklet has been downloaded over twenty thousand times. I never imagined the reach it would have. The anniversary edition comes with a better layout and wording. -

Modern Master Games Volume One the Dawn of Tournament Go
Modern Master Games Volume One The games presented in Modern Master Games, Volume One were played in turbulent The Dawn of times. When the first Honinbo tournament was Tournament Go established, the war had not yet seriously affected the Japanese go world or the daily life of the average Japanese. But by the time of the third Honinbo tournament, Japanese society Rob van Zeijst was in chaos; the atomic bomb was dropped and just 10 kilometers from where the second game Richard Bozulich of the title match was being played. After the war, life was slowly returning to With historical notes by normal. By the 1950s, the go world was again John Power abuzz. Rivalries were flourishing, and newspapers were establishing new tournaments with abundant prize money. As the post-war go world was reorganizing itself, the matches played were of much consequence — it became more than just winning a title. The results were to determine the organizations that governed the game in Japan until today. The pressures on the players were intense, and it exposed their psychological strengths as well as fragilities. Takagawa’s games in this book show how dangerous it is to underestimate an opponent. It was almost unbelievable to some that the mild-mannered Takagawa, whose quiet and laid-back style, never attacking too strongly, and lacking the brilliance of a player like Sakata, could hold the Honinbo title against all comers for nearly 10 years. Sakata’s games are good illustrations of the slashing style which earned him the moniker Razor-Sharp Sakata. We also see examples of the depth of his analysis in which he makes an unorthodox peep (dubbed the tesuji of the century) against Fujisawa Shuko that entails another tesuji 15 moves later whose consequences also have to be analyzed. -

Human Vs. Computer Go: Review and Prospect
This article is accepted and will be published in IEEE Computational Intelligence Magazine in August 2016 Human vs. Computer Go: Review and Prospect Chang-Shing Lee*, Mei-Hui Wang Department of Computer Science and Information Engineering, National University of Tainan, TAIWAN Shi-Jim Yen Department of Computer Science and Information Engineering, National Dong Hwa University, TAIWAN Ting-Han Wei, I-Chen Wu Department of Computer Science, National Chiao Tung University, TAIWAN Ping-Chiang Chou, Chun-Hsun Chou Taiwan Go Association, TAIWAN Ming-Wan Wang Nihon Ki-in Go Institute, JAPAN Tai-Hsiung Yang Haifong Weiqi Academy, TAIWAN Abstract The Google DeepMind challenge match in March 2016 was a historic achievement for computer Go development. This article discusses the development of computational intelligence (CI) and its relative strength in comparison with human intelligence for the game of Go. We first summarize the milestones achieved for computer Go from 1998 to 2016. Then, the computer Go programs that have participated in previous IEEE CIS competitions as well as methods and techniques used in AlphaGo are briefly introduced. Commentaries from three high-level professional Go players on the five AlphaGo versus Lee Sedol games are also included. We conclude that AlphaGo beating Lee Sedol is a huge achievement in artificial intelligence (AI) based largely on CI methods. In the future, powerful computer Go programs such as AlphaGo are expected to be instrumental in promoting Go education and AI real-world applications. I. Computer Go Competitions The IEEE Computational Intelligence Society (CIS) has funded human vs. computer Go competitions in IEEE CIS flagship conferences since 2009. -

Go Books Detail
Evanston Go Club Ian Feldman Lending Library A Compendium of Trick Plays Nihon Ki-in In this unique anthology, the reader will find the subject of trick plays in the game of go dealt with in a thorough manner. Practically anything one could wish to know about the subject is examined from multiple perpectives in this remarkable volume. Vital points in common patterns, skillful finesse (tesuji) and ordinary matters of good technique are discussed, as well as the pitfalls that are concealed in seemingly innocuous positions. This is a gem of a handbook that belongs on the bookshelf of every go player. Chapter 1 was written by Ishida Yoshio, former Meijin-Honinbo, who intimates that if "joseki can be said to be the highway, trick plays may be called a back alley. When one masters the alleyways, one is on course to master joseki." Thirty-five model trick plays are presented in this chapter, #204 and exhaustively analyzed in the style of a dictionary. Kageyama Toshiro 7 dan, one of the most popular go writers, examines the subject in Chapter 2 from the standpoint of full board strategy. Chapter 3 is written by Mihori Sho, who collaborated with Sakata Eio to produce Killer of Go. Anecdotes from the history of go, famous sayings by Sun Tzu on the Art of Warfare and contemporary examples of trickery are woven together to produce an entertaining dialogue. The final chapter presents twenty-five problems for the reader to solve, using the knowledge gained in the preceding sections. Do not be surprised to find unexpected booby traps lurking here also.