Proposed Middleware Solution for Resource- Constrained Distributed Embedded Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

AMNESIA 33: How TCP/IP Stacks Breed Critical Vulnerabilities in Iot
AMNESIA:33 | RESEARCH REPORT How TCP/IP Stacks Breed Critical Vulnerabilities in IoT, OT and IT Devices Published by Forescout Research Labs Written by Daniel dos Santos, Stanislav Dashevskyi, Jos Wetzels and Amine Amri RESEARCH REPORT | AMNESIA:33 Contents 1. Executive summary 4 2. About Project Memoria 5 3. AMNESIA:33 – a security analysis of open source TCP/IP stacks 7 3.1. Why focus on open source TCP/IP stacks? 7 3.2. Which open source stacks, exactly? 7 3.3. 33 new findings 9 4. A comparison with similar studies 14 4.1. Which components are typically flawed? 16 4.2. What are the most common vulnerability types? 17 4.3. Common anti-patterns 22 4.4. What about exploitability? 29 4.5. What is the actual danger? 32 5. Estimating the reach of AMNESIA:33 34 5.1. Where you can see AMNESIA:33 – the modern supply chain 34 5.2. The challenge – identifying and patching affected devices 36 5.3. Facing the challenge – estimating numbers 37 5.3.1. How many vendors 39 5.3.2. What device types 39 5.3.3. How many device units 40 6. An attack scenario 41 6.1. Other possible attack scenarios 44 7. Effective IoT risk mitigation 45 8. Conclusion 46 FORESCOUT RESEARCH LABS RESEARCH REPORT | AMNESIA:33 A note on vulnerability disclosure We would like to thank the CERT Coordination Center, the ICS-CERT, the German Federal Office for Information Security (BSI) and the JPCERT Coordination Center for their help in coordinating the disclosure of the AMNESIA:33 vulnerabilities. -

China's Space Program
China’s Space Program An Introduction China’s Space Program ● Motivations ● Organization ● Programs ○ Satellites ○ Manned Space flight ○ Lunar Exploration Program ○ International Relations ● Summary China’s Space Program Motivations Stated Purpose ● Explore outer space and to enhance understanding of the Earth and the cosmos ● Utilize outer space for peaceful purposes, promote human civilization and social progress, and to benefit the whole of mankind ● Meet the demands of economic development, scientific and technological development, national security and social progress ● Improve the scientific and cultural knowledge of the Chinese people ● Protect China's national rights and interests ● Build up China’s national comprehensive strength National Space Motivations • Preservation of its political system is overriding goal • The CCP prioritizes investments into space technology ○ Establish PRC as an equal among world powers ○ Space for international competition and cooperation ○ Manned spaceflight ● Foster national pride ● Enhance the domestic and international legitimacy of the CCP. ○ Space technology is metric of political legitimacy, national power, and status globally China’s Space Program Organization The China National Space Administration (CNSA) ● The China National Space Administration (CNSA, GuóJiā HángTiān Jú,) ○ National space agency of the People's Republic of China ○ Responsible for the national space program. ■ Planning and development of space activities. The China National Space Administration ● CNSA and China Aerospace -

Talend Open Studio for Big Data Release Notes
Talend Open Studio for Big Data Release Notes 6.0.0 Talend Open Studio for Big Data Adapted for v6.0.0. Supersedes previous releases. Publication date July 2, 2015 Copyleft This documentation is provided under the terms of the Creative Commons Public License (CCPL). For more information about what you can and cannot do with this documentation in accordance with the CCPL, please read: http://creativecommons.org/licenses/by-nc-sa/2.0/ Notices Talend is a trademark of Talend, Inc. All brands, product names, company names, trademarks and service marks are the properties of their respective owners. License Agreement The software described in this documentation is licensed under the Apache License, Version 2.0 (the "License"); you may not use this software except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0.html. Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. This product includes software developed at AOP Alliance (Java/J2EE AOP standards), ASM, Amazon, AntlR, Apache ActiveMQ, Apache Ant, Apache Avro, Apache Axiom, Apache Axis, Apache Axis 2, Apache Batik, Apache CXF, Apache Cassandra, Apache Chemistry, Apache Common Http Client, Apache Common Http Core, Apache Commons, Apache Commons Bcel, Apache Commons JxPath, Apache -
Attachment A
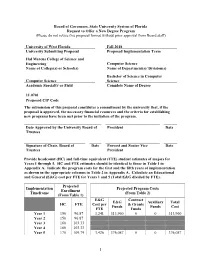
Board of Governors, State University System of Florida Request to Offer a New Degree Program (Please do not revise this proposal format without prior approval from Board staff) University of West Florida Fall 2018 University Submitting Proposal Proposed Implementation Term Hal Marcus College of Science and Engineering Computer Science Name of College(s) or School(s) Name of Department(s)/ Division(s) Bachelor of Science in Computer Computer Science Science Academic Specialty or Field Complete Name of Degree 11.0701 Proposed CIP Code The submission of this proposal constitutes a commitment by the university that, if the proposal is approved, the necessary financial resources and the criteria for establishing new programs have been met prior to the initiation of the program. Date Approved by the University Board of President Date Trustees Signature of Chair, Board of Date Provost and Senior Vice Date Trustees President Provide headcount (HC) and full-time equivalent (FTE) student estimates of majors for Years 1 through 5. HC and FTE estimates should be identical to those in Table 1 in Appendix A. Indicate the program costs for the first and the fifth years of implementation as shown in the appropriate columns in Table 2 in Appendix A. Calculate an Educational and General (E&G) cost per FTE for Years 1 and 5 (Total E&G divided by FTE). Projected Implementation Projected Program Costs Enrollment Timeframe (From Table 2) (From Table 1) E&G Contract E&G Auxiliary Total HC FTE Cost per & Grants Funds Funds Cost FTE Funds Year 1 150 96.87 3,241 313,960 0 0 313,960 Year 2 150 96.87 Year 3 160 103.33 Year 4 160 103.33 Year 5 170 109.79 3,426 376,087 0 0 376,087 1 Note: This outline and the questions pertaining to each section must be reproduced within the body of the proposal to ensure that all sections have been satisfactorily addressed. -

7. Operations
7. Operations 7.1 Ground Operations The Exploration Systems Architecture Study (ESAS) team addressed the launch site integra- tion of the exploration systems. The team was fortunate to draw on expertise from members with historical and contemporary human space flight program experience including the Mercury, Gemini, Apollo, Skylab, Apollo Soyuz Test Project, Shuttle, and International Space Station (ISS) programs, as well as from members with ground operations experience reaching back to the Redstone, Jupiter, Pershing, and Titan launch vehicle programs. The team had a wealth of experience in both management and technical responsibilities and was able to draw on recent ground system concepts and other engineering products from the Orbital Space Plane (OSP) and Space Launch Initiative (SLI) programs, diverse X-vehicle projects, and leadership in NASA/Industry/Academia groups such as the Space Propulsion Synergy Team (SPST) and the Advanced Spaceport Technology Working Group (ASTWG). 7.1.1 Ground Operations Summary The physical and functional integration of the proposed exploration architecture elements will occur at the primary launch site at the NASA Kennedy Space Center (KSC). In order to support the ESAS recommendation of the use of a Shuttle-derived Cargo Launch Vehicle (CaLV) and a separate Crew Launch Vehicle (CLV) for lunar missions and the use of a CLV for ISS missions, KSC’s Launch Complex 39 facilities and ground equipment were selected for conversion. Ground-up replacement of the pads, assembly, refurbishment, and/or process- ing facilities was determined to be too costly and time-consuming to design, build, outfit, activate, and certify in a timely manner to support initial test flights leading to an operational CEV/CLV system by 2011. -

B.Tech. CSE CBCS W.E.F. July, 2019
The Curriculum Book BACHELOR OF TECHNOLOGY I tn COMPUTER SCIENCE AND ENGINEERING FOUR YEAR PROGRAMME Choice Based Credit System vy. e. f. JuIy ZAlg (70:30) . ,_i 1 .I DEPARTMENT OF COMPUTER SCIENCE AI\D BNGINEERING GURU JAMBHESHWAR UNIVERSITY OF SCIENCE & TECHNOLOGY tr j HISAR.125OO1, HARYANA scheme & syllabi2019 GURU JAMBHESHWAR UNIVERSITY OF SCIENCE & TECHNOLOGY, HISAR (Established by state Legistature 'A',Grade,. Act 17 of lggs) NA.AC Accreditid state Govt. university Acad /AC-ilt,tFqc_1 Vot. 3DAlgJf 7 7 Dated: Ulfr:f To The Controller of Examinations GJUS&T, Hisar. sub: Approval of scheme of examination & syllabi of various B.Tech. progralle(sJ being run in university Teachiig Departments as welt as affil iated En g i neeri ng c oilege(s)/r nstitutelsy. AND Recommendations of Faculty Engineering open & Technology regarding Elective, Format of Minor Quu.ti;;-of papei Mooc strength for programme courses, minimum Erective, semester Registration etc. Sir, I am directed to inform you that the vice-chancellor, on the recommendations of the Faculty of Engineering & Technology, vide resolutions no. 2to 13 in its meeting held on 1B 07'2a19, is pleased to approve . the following scheme & syllabi of B.Tech. programme(s) w'e'f' the academic session batch / mentioned against each being run in University Teaching Departments as well as affiliated colleges/institutions and recommendations of Faculty of Engineering & Technolcgy, regarding open Elective, format of Minor Question Paper, Mooc courses, minimum strength for programme Elective' semester Registration etc under sectio n 11(5) in anticipation of approvat of the Acadenric councir of the University Act, 1995.- 1' B'Tech (Printing Technology), B Tec.h (Packaging Technology) (Printing & Packaging i""r'norogD-ath ""un',i""o,,,& B.Tech. -

Chang'e 5 Samples (Mexag) (Head-Final)
Chang’E 5 Lunar Sample Return Mission Update James w. Head Department of Earth, Environmental and Planetary Sciences Brown University Providence, RI 02912 USA Extraterrestrial Materials Analysis Group (ExMAG) Spring Meeting: April 7 - 8, 2021. Extraterrestrial Materials Analysis Group (ExMAG) Spring Meeting Barbara Cohen, ExMAG Chair. 2/10/21 • 1. Please provide an update on the Chang'e 5 Sample Return Mission. • 2. What is known of the collection so far? • 3. Please provide an overview of allocation procedures. • 4. Since US federally-funded researchers cannot work directly with China - Who outside of China is working with the mission team? • 5. We'd also appreciate your thoughts on: What NASA might be able to do to enable the US analysis community to collaborate on this sample collection? Extraterrestrial Materials Analysis Group (ExMAG) Spring Meeting Barbara Cohen, ExMAG Chair. 2/10/21 • 1. Some Myths and Realities. • 2. Organization of the Chinese Space Program. • 3. Chinese Lunar Exploration Program (CLEP) context for Chang’e 5. • 4. Chang’e 5 Landing Site Selection, Global Context, Key Questions, Mission Operations and Sample Return. • 5. Returned Sample Location, Storage, Preliminary Analysis and Distribution. • 6. Opportunities for International Cooperation. Extraterrestrial Materials Analysis Group (ExMAG) Spring Meeting Barbara Cohen, ExMAG Chair. 2/10/21 • 1. Some Myths and Realities. • 2. Organization of the Chinese Space Program. • 3. Chinese Lunar Exploration Program (CLEP) context for Chang’e 5. • 4. Chang’e 5 Landing Site Selection, Global Context, Key Questions, Mission Operations and Sample Return. • 5. Returned Sample Location, Storage, Preliminary Analysis and Distribution. • 6. Opportunities for International Cooperation. -

Kosten Senken Dank Open Source?
View metadata, citation and similar papers at core.ac.uk brought to you by CORE Kosten senken dank Open Source? provided by Bern Open Repository andStrategien Information System (BORIS) | downloaded: 13.3.2017 https://doi.org/10.7892/boris.47380 source: 36 Nr. 01/02 | Februar 2014 Swiss IT Magazine Strategien Kosten senken dank Open Source? Mehr Geld im Portemonnaie und weniger Sorgen im Gepäck Der Einsatz von Open Source Software kann das IT-Budget schonen, wenn man richtig vorgeht. Viel wichtiger sind aber strategische Vorteile wie die digitale Nachhaltigkeit oder die Unabhängigkeit von Herstellern, die sich durch den konsequenten Einsatz von Open Source ergeben. V ON D R . M ATTHIAS S TÜR M ER ines vorweg: Open Source ist nicht gra- tis. Oder korrekt ausgedrückt: Der Download von Open Source Software (OSS) von den vielen Internet-Portalen wieE Github, Google Code, Sourceforge oder Freecode ist selbstverständlich kostenlos. Aber wenn Open-Source-Lösungen professionell eingeführt und betrieben werden, verursacht dies interne und/oder externe Kosten. Geschäftskritische Lösungen benötigen stets zuverlässige Wartung und Support, ansonsten steigt das Risiko erheblich, dass zentrale Infor- matiksysteme ausfallen oder wichtige Daten verloren gehen oder gestohlen werden. Für den sicheren Einsatz von Open Source Soft- ware braucht es deshalb entweder interne INHALT Ressourcen und Know-how, wie die entspre- chenden Systeme betrieben werden. Oder es MEHR GELD im PORTemoNNaie UND weNIGER SorgeN im GEPÄck 36 wird ein Service Level Agreement (SLA) bei- MarkTÜbersicHT: 152 SCHweiZer OPEN-SOUrce-SPEZialisTEN 40 spielsweise in Form einer Subscription mit einem kommerziellen Anbieter von Open- SpareN ODER NICHT spareN 48 Source-Lösungen abgeschlossen. -

ADSS SES Admin Guide
Secure Email Server (SES) Admin Guide A S C E RT I A L TD J ANUARY 202 1 Document Version - 6.8 . 0 . 1 © Ascertia Limited. All rights reserved. This document contains commercial-in-confidence material. It must not be disclosed to any third party without the written authority of Ascertia Limited. Commercial-in-Confidence Secure Email Server (SES) – Admin Guide CONTENTS 1 INTRODUCTION .................................................................................................................................................... 4 1.1 SCOPE ............................................................................................................................................................. 4 1.2 INTENDED READERSHIP....................................................................................................................................... 4 1.3 CONVENTIONS .................................................................................................................................................. 4 1.4 TECHNICAL SUPPORT ......................................................................................................................................... 4 2 CONCEPTS & ARCHITECTURE ............................................................................................................................... 5 2.1 INTRODUCTION ................................................................................................................................................. 5 2.2 FEATURE & BENEFITS ........................................................................................................................................ -

Advantages and Limitations of Current Microgravity Platforms for Space Biology Research
applied sciences Review Advantages and Limitations of Current Microgravity Platforms for Space Biology Research Francesca Ferranti, Marta Del Bianco * and Claudia Pacelli Italian Space Agency, Via del Politecnico snc, 00133 Rome, Italy; [email protected] (F.F.); [email protected] (C.P.) * Correspondence: [email protected] Abstract: Human Space exploration has created new challenges and new opportunities for science. Reaching beyond the Earth’s surface has raised the issue of the importance of gravity for the de- velopment and the physiology of biological systems, while giving scientists the tools to study the mechanisms of response and adaptation to the microgravity environment. As life has evolved under the constant influence of gravity, gravity affects biological systems at a very fundamental level. Owing to limited access to spaceflight platforms, scientists rely heavily on on-ground facilities that reproduce, to a different extent, microgravity or its effects. However, the technical constraints of counterbalancing the gravitational force on Earth add complexity to data interpretation. In-flight experiments are also not without their challenges, including additional stressors, such as cosmic radi- ation and lack of convection. It is thus extremely important in Space biology to design experiments in a way that maximizes the scientific return and takes into consideration all the variables of the chosen setup, both on-ground or on orbit. This review provides a critical analysis of current ground-based and spaceflight facilities. In particular, the focus was given to experimental design to offer the reader the tools to select the appropriate setup and to appropriately interpret the results. Keywords: microgravity; ground-based facility; international Space station; clinostat; RPM; bed rest; CubeSat Citation: Ferranti, F.; Del Bianco, M.; Pacelli, C. -

Open Source and Third Party Documentation
Open Source and Third Party Documentation Verint.com Twitter.com/verint Facebook.com/verint Blog.verint.com Content Introduction.....................2 Licenses..........................3 Page 1 Open Source Attribution Certain components of this Software or software contained in this Product (collectively, "Software") may be covered by so-called "free or open source" software licenses ("Open Source Components"), which includes any software licenses approved as open source licenses by the Open Source Initiative or any similar licenses, including without limitation any license that, as a condition of distribution of the Open Source Components licensed, requires that the distributor make the Open Source Components available in source code format. A license in each Open Source Component is provided to you in accordance with the specific license terms specified in their respective license terms. EXCEPT WITH REGARD TO ANY WARRANTIES OR OTHER RIGHTS AND OBLIGATIONS EXPRESSLY PROVIDED DIRECTLY TO YOU FROM VERINT, ALL OPEN SOURCE COMPONENTS ARE PROVIDED "AS IS" AND ANY EXPRESSED OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. Any third party technology that may be appropriate or necessary for use with the Verint Product is licensed to you only for use with the Verint Product under the terms of the third party license agreement specified in the Documentation, the Software or as provided online at http://verint.com/thirdpartylicense. You may not take any action that would separate the third party technology from the Verint Product. Unless otherwise permitted under the terms of the third party license agreement, you agree to only use the third party technology in conjunction with the Verint Product. -

Licensing Information User Manual Mysql Enterprise Monitor 3.4
Licensing Information User Manual MySQL Enterprise Monitor 3.4 Table of Contents Licensing Information .......................................................................................................................... 4 Licenses for Third-Party Components .................................................................................................. 5 Ant-Contrib ............................................................................................................................... 10 ANTLR 2 .................................................................................................................................. 11 ANTLR 3 .................................................................................................................................. 11 Apache Commons BeanUtils v1.6 ............................................................................................. 12 Apache Commons BeanUtils v1.7.0 and Later ........................................................................... 13 Apache Commons Chain .......................................................................................................... 13 Apache Commons Codec ......................................................................................................... 13 Apache Commons Collections .................................................................................................. 14 Apache Commons Daemon ...................................................................................................... 14 Apache