Using Black-Box Performance Models to Detect Performance Regressions Under Varying Workloads: an Empirical Study
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Talend Open Studio for Big Data Release Notes
Talend Open Studio for Big Data Release Notes 6.0.0 Talend Open Studio for Big Data Adapted for v6.0.0. Supersedes previous releases. Publication date July 2, 2015 Copyleft This documentation is provided under the terms of the Creative Commons Public License (CCPL). For more information about what you can and cannot do with this documentation in accordance with the CCPL, please read: http://creativecommons.org/licenses/by-nc-sa/2.0/ Notices Talend is a trademark of Talend, Inc. All brands, product names, company names, trademarks and service marks are the properties of their respective owners. License Agreement The software described in this documentation is licensed under the Apache License, Version 2.0 (the "License"); you may not use this software except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0.html. Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. This product includes software developed at AOP Alliance (Java/J2EE AOP standards), ASM, Amazon, AntlR, Apache ActiveMQ, Apache Ant, Apache Avro, Apache Axiom, Apache Axis, Apache Axis 2, Apache Batik, Apache CXF, Apache Cassandra, Apache Chemistry, Apache Common Http Client, Apache Common Http Core, Apache Commons, Apache Commons Bcel, Apache Commons JxPath, Apache -

Kosten Senken Dank Open Source?
View metadata, citation and similar papers at core.ac.uk brought to you by CORE Kosten senken dank Open Source? provided by Bern Open Repository andStrategien Information System (BORIS) | downloaded: 13.3.2017 https://doi.org/10.7892/boris.47380 source: 36 Nr. 01/02 | Februar 2014 Swiss IT Magazine Strategien Kosten senken dank Open Source? Mehr Geld im Portemonnaie und weniger Sorgen im Gepäck Der Einsatz von Open Source Software kann das IT-Budget schonen, wenn man richtig vorgeht. Viel wichtiger sind aber strategische Vorteile wie die digitale Nachhaltigkeit oder die Unabhängigkeit von Herstellern, die sich durch den konsequenten Einsatz von Open Source ergeben. V ON D R . M ATTHIAS S TÜR M ER ines vorweg: Open Source ist nicht gra- tis. Oder korrekt ausgedrückt: Der Download von Open Source Software (OSS) von den vielen Internet-Portalen wieE Github, Google Code, Sourceforge oder Freecode ist selbstverständlich kostenlos. Aber wenn Open-Source-Lösungen professionell eingeführt und betrieben werden, verursacht dies interne und/oder externe Kosten. Geschäftskritische Lösungen benötigen stets zuverlässige Wartung und Support, ansonsten steigt das Risiko erheblich, dass zentrale Infor- matiksysteme ausfallen oder wichtige Daten verloren gehen oder gestohlen werden. Für den sicheren Einsatz von Open Source Soft- ware braucht es deshalb entweder interne INHALT Ressourcen und Know-how, wie die entspre- chenden Systeme betrieben werden. Oder es MEHR GELD im PORTemoNNaie UND weNIGER SorgeN im GEPÄck 36 wird ein Service Level Agreement (SLA) bei- MarkTÜbersicHT: 152 SCHweiZer OPEN-SOUrce-SPEZialisTEN 40 spielsweise in Form einer Subscription mit einem kommerziellen Anbieter von Open- SpareN ODER NICHT spareN 48 Source-Lösungen abgeschlossen. -

ADSS SES Admin Guide
Secure Email Server (SES) Admin Guide A S C E RT I A L TD J ANUARY 202 1 Document Version - 6.8 . 0 . 1 © Ascertia Limited. All rights reserved. This document contains commercial-in-confidence material. It must not be disclosed to any third party without the written authority of Ascertia Limited. Commercial-in-Confidence Secure Email Server (SES) – Admin Guide CONTENTS 1 INTRODUCTION .................................................................................................................................................... 4 1.1 SCOPE ............................................................................................................................................................. 4 1.2 INTENDED READERSHIP....................................................................................................................................... 4 1.3 CONVENTIONS .................................................................................................................................................. 4 1.4 TECHNICAL SUPPORT ......................................................................................................................................... 4 2 CONCEPTS & ARCHITECTURE ............................................................................................................................... 5 2.1 INTRODUCTION ................................................................................................................................................. 5 2.2 FEATURE & BENEFITS ........................................................................................................................................ -

Open Source and Third Party Documentation
Open Source and Third Party Documentation Verint.com Twitter.com/verint Facebook.com/verint Blog.verint.com Content Introduction.....................2 Licenses..........................3 Page 1 Open Source Attribution Certain components of this Software or software contained in this Product (collectively, "Software") may be covered by so-called "free or open source" software licenses ("Open Source Components"), which includes any software licenses approved as open source licenses by the Open Source Initiative or any similar licenses, including without limitation any license that, as a condition of distribution of the Open Source Components licensed, requires that the distributor make the Open Source Components available in source code format. A license in each Open Source Component is provided to you in accordance with the specific license terms specified in their respective license terms. EXCEPT WITH REGARD TO ANY WARRANTIES OR OTHER RIGHTS AND OBLIGATIONS EXPRESSLY PROVIDED DIRECTLY TO YOU FROM VERINT, ALL OPEN SOURCE COMPONENTS ARE PROVIDED "AS IS" AND ANY EXPRESSED OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. Any third party technology that may be appropriate or necessary for use with the Verint Product is licensed to you only for use with the Verint Product under the terms of the third party license agreement specified in the Documentation, the Software or as provided online at http://verint.com/thirdpartylicense. You may not take any action that would separate the third party technology from the Verint Product. Unless otherwise permitted under the terms of the third party license agreement, you agree to only use the third party technology in conjunction with the Verint Product. -

Licensing Information User Manual Mysql Enterprise Monitor 3.4
Licensing Information User Manual MySQL Enterprise Monitor 3.4 Table of Contents Licensing Information .......................................................................................................................... 4 Licenses for Third-Party Components .................................................................................................. 5 Ant-Contrib ............................................................................................................................... 10 ANTLR 2 .................................................................................................................................. 11 ANTLR 3 .................................................................................................................................. 11 Apache Commons BeanUtils v1.6 ............................................................................................. 12 Apache Commons BeanUtils v1.7.0 and Later ........................................................................... 13 Apache Commons Chain .......................................................................................................... 13 Apache Commons Codec ......................................................................................................... 13 Apache Commons Collections .................................................................................................. 14 Apache Commons Daemon ...................................................................................................... 14 Apache -
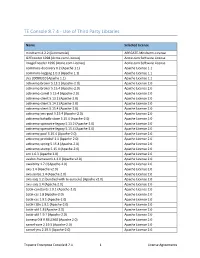
TE Console 8.7.4 - Use of Third Party Libraries
TE Console 8.7.4 - Use of Third Party Libraries Name Selected License mindterm 4.2.2 (Commercial) APPGATE-Mindterm-License GifEncoder 1998 (Acme.com License) Acme.com Software License ImageEncoder 1996 (Acme.com License) Acme.com Software License commons-discovery 0.2 (Apache 1.1) Apache License 1.1 commons-logging 1.0.3 (Apache 1.1) Apache License 1.1 jrcs 20080310 (Apache 1.1) Apache License 1.1 activemq-broker 5.13.2 (Apache-2.0) Apache License 2.0 activemq-broker 5.15.4 (Apache-2.0) Apache License 2.0 activemq-camel 5.15.4 (Apache-2.0) Apache License 2.0 activemq-client 5.13.2 (Apache-2.0) Apache License 2.0 activemq-client 5.14.2 (Apache-2.0) Apache License 2.0 activemq-client 5.15.4 (Apache-2.0) Apache License 2.0 activemq-jms-pool 5.15.4 (Apache-2.0) Apache License 2.0 activemq-kahadb-store 5.15.4 (Apache-2.0) Apache License 2.0 activemq-openwire-legacy 5.13.2 (Apache-2.0) Apache License 2.0 activemq-openwire-legacy 5.15.4 (Apache-2.0) Apache License 2.0 activemq-pool 5.15.4 (Apache-2.0) Apache License 2.0 activemq-protobuf 1.1 (Apache-2.0) Apache License 2.0 activemq-spring 5.15.4 (Apache-2.0) Apache License 2.0 activemq-stomp 5.15.4 (Apache-2.0) Apache License 2.0 ant 1.6.3 (Apache 2.0) Apache License 2.0 avalon-framework 4.2.0 (Apache v2.0) Apache License 2.0 awaitility 1.7.0 (Apache-2.0) Apache License 2.0 axis 1.4 (Apache v2.0) Apache License 2.0 axis-jaxrpc 1.4 (Apache 2.0) Apache License 2.0 axis-saaj 1.2 [bundled with te-console] (Apache v2.0) Apache License 2.0 axis-saaj 1.4 (Apache 2.0) Apache License 2.0 batik-constants -

Understanding Reuse in the Android Market
Understanding Reuse in the Android Market Israel J. Mojica Ruiz∗, Meiyappan Nagappan∗, Bram Adamsy, Ahmed E. Hassan∗ ∗Software Analysis and Intelligence Lab (SAIL) yMaintenance, Construction and Intelligence Lab (MCIS) Queen’s University, Kingston, Canada École Polytechnique de Montréal, Canada Email: mojica, mei, [email protected] Email: [email protected] Abstract—Mobile apps are software products developed to run This paper analyzes the adoption of code reuse for mobile on mobile devices, and are typically distributed via app stores. app development. Frakes and Kang define software reuse as The mobile app market is estimated to be worth billions of “the use of existing software or software knowledge to con- dollars, with more than hundred of thousands of apps, and still increasing in number. This explosion of mobile apps is struct new software” [9]. Research has shown that the judicious astonishing, given the short time span that they have been around. usage of code reuse tends to build more reliable systems One possible explanation for this explosion could be the practice and reduce the budget of the total development [7] [8] [9]. of software reuse. Yet, no research has studied such practice in Various types of software reuse exists, like inheritance, code, mobile app development. In this paper, we intend to analyze and framework reuse [10], each having its own advantages and software reuse in the Android mobile app market along two dimensions: (a) reuse by inheritance, and (b) class reuse. Since disadvantages. app stores only distribute the byte code of the mobile apps, and In this paper we focus on exploring the extent of reuse not the source code, we used the concept of Software Bertillonage among mobile apps. -

Sun Java, J2EE - News and Articles
Sun Java, J2EE - News and Articles http://www.javarss.com/ Special Thanks to: Elastic Path - Java eCommerce Software Tell-A-Friend | Menu... 6 | Session Timeout: 28:41 minutes JavaRSS.comWeb 2.0 top stories news ( 6) blogs tags forums groups tech world comments settings suggest feedback sitemap JavaRSS.com sitegraph Show only channels with new items since nmlkj my LastVisit nmlkj Past 24 hours nmlkj Past 2 days -- or -- nmlkji All channels Welcome! - Java News and Java Articles (6) JavaServer Faces course Developing on the iSeries Java Courses in London Java Developer Kito Mann in London 17/10. The most productive and efficient Java Bean, JSP, EJB, JDBC, XML IT Recruitment in Banking & The Register now and your colleague way to develop iSeries Oracle, ASP .net, Programming, Financial Markets comes free! Applications SQL www.eFinancialCareers.co.uk www.skillsmatter.com www.lansa.com www.bcoc.co.uk java.net News (6) Oct 12 Editor's Daily Blog Oct 11 « ‹ › | More.. « ‹ › | More.. ObjectLab Kit Radio (Part 1) Apache JAMES Server 2.30rc5 Frame By Frame H2 Database Engine 1.0/2006-10-10 Happy With What You Have To Be Happy With AgileWiki 3.5.0.6 Lawyers, Guns, and Money IBM Web Service Streaming Engine My Ride's Here Java Technology Headlines Sep 29 JavaWorld Oct 06 « ‹ › | More.. « ‹ › | More.. Java 2D Trickery Revisiting the logout problem Meet Shannon Hickey, Technical Lead for the Swing Toolkit Sun to shine on AJAX Team at Sun Microsystems SAP achieves Java EE 5 certification Getting Started With the NetBeans IDE 5.0 BlueJ Edition Try on Derby for size Writing Performant EJB Beans in the Java EE 5 Platform BEA focuses on flexible, collaborative SOA (EJB 3.0) Using Annotations U.S. -

Notice Report
NetApp Notice Report Copyright 2020 About this document The following copyright statements and licenses apply to the software components that are distributed with the Active IQ Platform product released on 2020-08-14 06:55:16. This product does not necessarily use all the software components referred to below. Where required, source code is published at the following location. ftp://ftp.netapp.com/frm-ntap/opensource 1 Components: Component License Achilles Core 5.3.0 Apache License 2.0 An open source Java toolkit for Amazon S3 0.9.0 Apache License 2.0 Aopalliance Version 1.0 Repackaged As A Module 2.5.0-b32 Common Development and Distribution License 1.1 Apache Avro 1.7.6-cdh5.4.2.1.1 Apache License 2.0 Apache Avro 1.7.6-cdh5.4.4 Apache License 2.0 Apache Avro Tools 1.7.6-cdh5.4.4 Apache License 2.0 Apache Commons BeanUtils 1.7.0 Apache License 2.0 Apache Commons BeanUtils 1.8.0 Apache License 2.0 Apache Commons CLI 1.2 Apache License 2.0 Apache Commons Codec 1.9 Apache License 2.0 Apache Commons Collections 3.2.1 Apache License 2.0 Apache Commons Compress 1.4.1 Apache License 2.0 Apache Commons Configuration 1.6 Apache License 2.0 Apache Commons Digester 1.8 Apache License 1.1 Apache Commons Lang 2.6 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 Apache Commons Math 3.1.1 Apache License 2.0 Apache Commons Net 3.1 Apache License 2.0 Apache Directory API ASN.1 API 1.0.0-M20 Apache License 2.0 Apache Directory LDAP API Utilities 1.0.0-M19 Apache License 2.0 Apache Directory LDAP API Utilities 1.0.0-M20 Apache License 2.0 -

Eyeglass Search OSS Licenses and Packages V9
ECA 15.1 opensuse https://en.opensuse.org/openSUSE:License Package Licence Name Version Type Key Licence Name opensuse 15.1 OS annogen:annogen 0.1.0 JAR Not Found antlr:antlr 2.7.7 JAR BSD Berkeley Software Distribution (BSD) aopalliance:aopalliance 1 JAR Public DomainPublic Domain asm:asm 3.1 JAR Not Found axis:axis 1.4 JAR Apache-2.0 The Apache Software License, Version 2.0 axis:axis-wsdl4j 1.5.1 JAR Not Found backport-util-concurrent:backport-util-concurrent3.1 JAR Public DomainPublic Domain com.amazonaws:aws-java-sdk 1.1.7.1 JAR Apache-2.0 The Apache Software License, Version 2.0 com.beust:jcommander 1.72 JAR Apache-2.0 The Apache Software License, Version 2.0 com.carrotsearch:hppc 0.6.0 JAR Apache-2.0 The Apache Software License, Version 2.0 com.clearspring.analytics:stream 2.7.0 JAR Apache-2.0 The Apache Software License, Version 2.0 com.drewnoakes:metadata-extractor 2.4.0-beta-1JAR Public DomainPublic Domain com.esotericsoftware:kryo-shaded 3.0.3 JAR BSD Berkeley Software Distribution (BSD) com.esotericsoftware:minlog 1.3.0 JAR BSD Berkeley Software Distribution (BSD) com.fasterxml.jackson.core:jackson-annotations2.6.1 JAR Apache-2.0 The Apache Software License, Version 2.0 com.fasterxml.jackson.core:jackson-annotations2.5.0 JAR Apache-2.0 The Apache Software License, Version 2.0 com.fasterxml.jackson.core:jackson-annotations2.2.0 JAR Apache-2.0 The Apache Software License, Version 2.0 com.fasterxml.jackson.core:jackson-annotations2.9.0 JAR Apache-2.0 The Apache Software License, Version 2.0 com.fasterxml.jackson.core:jackson-annotations2.6.0 -

Testsmelldescriber Enabling Developers’ Awareness on Test Quality with Test Smell Summaries
Bachelor Thesis January 31, 2018 TestSmellDescriber Enabling Developers’ Awareness on Test Quality with Test Smell Summaries Ivan Taraca of Pfullendorf, Germany (13-751-896) supervised by Prof. Dr. Harald C. Gall Dr. Sebastiano Panichella software evolution & architecture lab Bachelor Thesis TestSmellDescriber Enabling Developers’ Awareness on Test Quality with Test Smell Summaries Ivan Taraca software evolution & architecture lab Bachelor Thesis Author: Ivan Taraca, [email protected] URL: http://bit.ly/2DUiZrC Project period: 20.10.2018 - 31.01.2018 Software Evolution & Architecture Lab Department of Informatics, University of Zurich Acknowledgements First of all, I like to thank Dr. Harald Gall for giving me the opportunity to write this thesis at the Software Evolution & Architecture Lab. Special thanks goes out to Dr. Sebastiano Panichella for his instructions, guidance and help during the making of this thesis, without whom this would not have been possible. I would also like to express my gratitude to Dr. Fabio Polomba, Dr. Yann-Gaël Guéhéneuc and Dr. Nikolaos Tsantalis for providing me access to their research and always being available for questions. Last, but not least, do I want to thank my parents, sisters and nephews for the support and love they’ve given all those years. Abstract With the importance of software in today’s society, malfunctioning software can not only lead to disrupting our day-to-day lives, but also large monetary damages. A lot of time and effort goes into the development of test suites to ensure the quality and accuracy of software. But how do we elevate the quality of test code? This thesis presents TestSmellDescriber, a tool with the ability to generate descriptions detailing potential problems in test cases, which are collected by conducting a Test Smell analysis. -

Talend Open Studio for Big Data Getting Started Guide
Talend Open Studio for Big Data Getting Started Guide 6.0.0 Talend Open Studio for Big Data Adapted for v6.0.0. Supersedes previous releases. Publication date: July 2, 2015 Copyleft This documentation is provided under the terms of the Creative Commons Public License (CCPL). For more information about what you can and cannot do with this documentation in accordance with the CCPL, please read: http://creativecommons.org/licenses/by-nc-sa/2.0/ Notices Talend is a trademark of Talend, Inc. All brands, product names, company names, trademarks and service marks are the properties of their respective owners. License Agreement The software described in this documentation is licensed under the Apache License, Version 2.0 (the "License"); you may not use this software except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0.html. Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. This product includes software developed at AOP Alliance (Java/J2EE AOP standards), ASM, Amazon, AntlR, Apache ActiveMQ, Apache Ant, Apache Avro, Apache Axiom, Apache Axis, Apache Axis 2, Apache Batik, Apache CXF, Apache Cassandra, Apache Chemistry, Apache Common Http Client, Apache Common Http Core, Apache Commons, Apache Commons Bcel, Apache Commons JxPath,