Combining Static and Dynamic Approaches to Model Loop Performance in HPC Vincent Palomares
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Microcode Revision Guidance August 31, 2019 MCU Recommendations
microcode revision guidance August 31, 2019 MCU Recommendations Section 1 – Planned microcode updates • Provides details on Intel microcode updates currently planned or available and corresponding to Intel-SA-00233 published June 18, 2019. • Changes from prior revision(s) will be highlighted in yellow. Section 2 – No planned microcode updates • Products for which Intel does not plan to release microcode updates. This includes products previously identified as such. LEGEND: Production Status: • Planned – Intel is planning on releasing a MCU at a future date. • Beta – Intel has released this production signed MCU under NDA for all customers to validate. • Production – Intel has completed all validation and is authorizing customers to use this MCU in a production environment. -

A Superscalar Out-Of-Order X86 Soft Processor for FPGA
A Superscalar Out-of-Order x86 Soft Processor for FPGA Henry Wong University of Toronto, Intel [email protected] June 5, 2019 Stanford University EE380 1 Hi! ● CPU architect, Intel Hillsboro ● Ph.D., University of Toronto ● Today: x86 OoO processor for FPGA (Ph.D. work) – Motivation – High-level design and results – Microarchitecture details and some circuits 2 FPGA: Field-Programmable Gate Array ● Is a digital circuit (logic gates and wires) ● Is field-programmable (at power-on, not in the fab) ● Pre-fab everything you’ll ever need – 20x area, 20x delay cost – Circuit building blocks are somewhat bigger than logic gates 6-LUT6-LUT 6-LUT6-LUT 3 6-LUT 6-LUT FPGA: Field-Programmable Gate Array ● Is a digital circuit (logic gates and wires) ● Is field-programmable (at power-on, not in the fab) ● Pre-fab everything you’ll ever need – 20x area, 20x delay cost – Circuit building blocks are somewhat bigger than logic gates 6-LUT 6-LUT 6-LUT 6-LUT 4 6-LUT 6-LUT FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel code and hardware accelerators need effort – Less effort if soft processors got faster 5 FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel code and hardware accelerators need effort – Less effort if soft processors got faster 6 FPGA Soft Processors ● FPGA systems often have software components – Often running on a soft processor ● Need more performance? – Parallel -

The Microarchitecture of the Pentium 4 Processor
The Microarchitecture of the Pentium 4 Processor Glenn Hinton, Desktop Platforms Group, Intel Corp. Dave Sager, Desktop Platforms Group, Intel Corp. Mike Upton, Desktop Platforms Group, Intel Corp. Darrell Boggs, Desktop Platforms Group, Intel Corp. Doug Carmean, Desktop Platforms Group, Intel Corp. Alan Kyker, Desktop Platforms Group, Intel Corp. Patrice Roussel, Desktop Platforms Group, Intel Corp. Index words: Pentium® 4 processor, NetBurst™ microarchitecture, Trace Cache, double-pumped ALU, deep pipelining provides an in-depth examination of the features and ABSTRACT functions of the Intel NetBurst microarchitecture. This paper describes the Intel® NetBurst™ ® The Pentium 4 processor is designed to deliver microarchitecture of Intel’s new flagship Pentium 4 performance across applications where end users can truly processor. This microarchitecture is the basis of a new appreciate and experience its performance. For example, family of processors from Intel starting with the Pentium it allows a much better user experience in areas such as 4 processor. The Pentium 4 processor provides a Internet audio and streaming video, image processing, substantial performance gain for many key application video content creation, speech recognition, 3D areas where the end user can truly appreciate the applications and games, multi-media, and multi-tasking difference. user environments. The Pentium 4 processor enables real- In this paper we describe the main features and functions time MPEG2 video encoding and near real-time MPEG4 of the NetBurst microarchitecture. We present the front- encoding, allowing efficient video editing and video end of the machine, including its new form of instruction conferencing. It delivers world-class performance on 3D cache called the Execution Trace Cache. -

Multiprocessing Contents
Multiprocessing Contents 1 Multiprocessing 1 1.1 Pre-history .............................................. 1 1.2 Key topics ............................................... 1 1.2.1 Processor symmetry ...................................... 1 1.2.2 Instruction and data streams ................................. 1 1.2.3 Processor coupling ...................................... 2 1.2.4 Multiprocessor Communication Architecture ......................... 2 1.3 Flynn’s taxonomy ........................................... 2 1.3.1 SISD multiprocessing ..................................... 2 1.3.2 SIMD multiprocessing .................................... 2 1.3.3 MISD multiprocessing .................................... 3 1.3.4 MIMD multiprocessing .................................... 3 1.4 See also ................................................ 3 1.5 References ............................................... 3 2 Computer multitasking 5 2.1 Multiprogramming .......................................... 5 2.2 Cooperative multitasking ....................................... 6 2.3 Preemptive multitasking ....................................... 6 2.4 Real time ............................................... 7 2.5 Multithreading ............................................ 7 2.6 Memory protection .......................................... 7 2.7 Memory swapping .......................................... 7 2.8 Programming ............................................. 7 2.9 See also ................................................ 8 2.10 References ............................................. -

Evaluation of the Intel Sandy Bridge-EP Server Processor
Evaluation of the Intel Sandy Bridge-EP server processor Sverre Jarp, Alfio Lazzaro, Julien Leduc, Andrzej Nowak CERN openlab, March 2012 – version 2.2 Executive Summary In this paper we report on a set of benchmark results recently obtained by CERN openlab when comparing an 8-core “Sandy Bridge-EP” processor with Intel’s previous microarchitecture, the “Westmere-EP”. The Intel marketing names for these processors are “Xeon E5-2600 processor series” and “Xeon 5600 processor series”, respectively. Both processors are produced in a 32nm process, and both platforms are dual-socket servers. Multiple benchmarks were used to get a good understanding of the performance of the new processor. We used both industry-standard benchmarks, such as SPEC2006, and specific High Energy Physics benchmarks, representing both simulation of physics detectors and data analysis of physics events. Before summarizing the results we must stress the fact that benchmarking of modern processors is a very complex affair. One has to control (at least) the following features: processor frequency, overclocking via Turbo mode, the number of physical cores in use, the use of logical cores via Simultaneous Multi-Threading (SMT), the cache sizes available, the memory configuration installed, as well as the power configuration if throughput per watt is to be measured. Software must also be kept under control and we show that a change of operating system or compiler can lead to different results, as well. We have tried to do a good job of comparing like with like. In summary, we obtained a performance improvement of 9 – 20% per core and 46 – 60% improvement across all cores available. -

The Intel X86 Microarchitectures Map Version 2.0
The Intel x86 Microarchitectures Map Version 2.0 P6 (1995, 0.50 to 0.35 μm) 8086 (1978, 3 µm) 80386 (1985, 1.5 to 1 µm) P5 (1993, 0.80 to 0.35 μm) NetBurst (2000 , 180 to 130 nm) Skylake (2015, 14 nm) Alternative Names: i686 Series: Alternative Names: iAPX 386, 386, i386 Alternative Names: Pentium, 80586, 586, i586 Alternative Names: Pentium 4, Pentium IV, P4 Alternative Names: SKL (Desktop and Mobile), SKX (Server) Series: Pentium Pro (used in desktops and servers) • 16-bit data bus: 8086 (iAPX Series: Series: Series: Series: • Variant: Klamath (1997, 0.35 μm) 86) • Desktop/Server: i386DX Desktop/Server: P5, P54C • Desktop: Willamette (180 nm) • Desktop: Desktop 6th Generation Core i5 (Skylake-S and Skylake-H) • Alternative Names: Pentium II, PII • 8-bit data bus: 8088 (iAPX • Desktop lower-performance: i386SX Desktop/Server higher-performance: P54CQS, P54CS • Desktop higher-performance: Northwood Pentium 4 (130 nm), Northwood B Pentium 4 HT (130 nm), • Desktop higher-performance: Desktop 6th Generation Core i7 (Skylake-S and Skylake-H), Desktop 7th Generation Core i7 X (Skylake-X), • Series: Klamath (used in desktops) 88) • Mobile: i386SL, 80376, i386EX, Mobile: P54C, P54LM Northwood C Pentium 4 HT (130 nm), Gallatin (Pentium 4 Extreme Edition 130 nm) Desktop 7th Generation Core i9 X (Skylake-X), Desktop 9th Generation Core i7 X (Skylake-X), Desktop 9th Generation Core i9 X (Skylake-X) • Variant: Deschutes (1998, 0.25 to 0.18 μm) i386CXSA, i386SXSA, i386CXSB Compatibility: Pentium OverDrive • Desktop lower-performance: Willamette-128 -

A Performance Analysis Tool for Intel SGX Enclaves
sgx-perf: A Performance Analysis Tool for Intel SGX Enclaves Nico Weichbrodt Pierre-Louis Aublin Rüdiger Kapitza IBR, TU Braunschweig LSDS, Imperial College London IBR, TU Braunschweig Germany United Kingdom Germany [email protected] [email protected] [email protected] ABSTRACT the provider or need to refrain from offloading their workloads Novel trusted execution technologies such as Intel’s Software Guard to the cloud. With the advent of Intel’s Software Guard Exten- Extensions (SGX) are considered a cure to many security risks in sions (SGX)[14, 28], the situation is about to change as this novel clouds. This is achieved by offering trusted execution contexts, so trusted execution technology enables confidentiality and integrity called enclaves, that enable confidentiality and integrity protection protection of code and data – even from privileged software and of code and data even from privileged software and physical attacks. physical attacks. Accordingly, researchers from academia and in- To utilise this new abstraction, Intel offers a dedicated Software dustry alike recently published research works in rapid succession Development Kit (SDK). While it is already used to build numerous to secure applications in clouds [2, 5, 33], enable secure network- applications, understanding the performance implications of SGX ing [9, 11, 34, 39] and fortify local applications [22, 23, 35]. and the offered programming support is still in its infancy. This Core to all these works is the use of SGX provided enclaves, inevitably leads to time-consuming trial-and-error testing and poses which build small, isolated application compartments designed to the risk of poor performance. -

Intel PSU Cage Replacement Process Support Guide
Intel® PSU Cage Replacement Process Support Guide A Guide for Technically Qualified Assemblers of Intel® 2U ATX Products Document No.: PSU-01 Revision No.: 002 Disclaimer Information in this document is provided in connection with Intel® products. No license, express or implied, by estoppel or otherwise, to any intellectual property rights is granted by this document. Except as provided in Intel's Terms and Conditions of Sale for such products, Intel assumes no liability whatsoever, and Intel disclaims any express or implied warranty, relating to sale and/or use of Intel products including liability or warranties relating to fitness for a particular purpose, merchantability, or infringement of any patent, copyright or other intellectual property right. Intel products are not designed, intended or authorized for use in any medical, life saving, or life sustaining applications or for any other application in which the failure of the Intel product could create a situation where personal injury or death may occur. Intel may make changes to specifications and product descriptions at any time, without notice. Intel server boards contain a number of high-density VLSI and power delivery components that need adequate airflow for cooling. Intel's own chassis are designed and tested to meet the intended thermal requirements of these components when the fully integrated system is used together. It is the responsibility of the system integrator that chooses not to use Intel developed server building blocks to consult vendor datasheets and operating parameters to determine the amount of airflow required for their specific application and environmental conditions. Intel Corporation can not be held responsible if components fail or the server board does not operate correctly when used outside any of their published operating or non-operating limits. -

M39 Sandy Bridge-PDF
SANDY BRIDGE SPANS GENERATIONS Intel Focuses on Graphics, Multimedia in New Processor Design By Linley Gwennap {9/27/10-01} ................................................................................................................... Intel’s processor clock has tocked, delivering a next- periods. For notebook computers, these improvements can generation architecture for PCs and servers. At the recent significantly extend battery life by completing tasks more Intel Developer’s Forum (IDF), the company unveiled its quickly and allowing the system to revert to a sleep state. Sandy Bridge processor architecture, the next tock in its tick-tock roadmap. The new CPU is an evolutionary im- Integration Boosts Graphics Performance provement over its predecessor, Nehalem, tweaking the Intel had a false start with integrated graphics: the ill-fated branch predictor, register renaming, and instruction de- Timna project, which was canceled in 2000. More recently, coding. These changes will slightly improve performance Nehalem-class processors known as Arrandale and Clark- on traditional integer applications, but we may be reaching dale “integrated” graphics into the processor, but these the point where the CPU microarchitecture is so efficient, products actually used two chips in one package, as Figure few ways remain to improve performance. 1 shows. By contrast, Sandy Bridge includes the GPU on The big changes in Sandy Bridge target multimedia the processor chip, providing several benefits. The GPU is applications such as 3D graphics, image processing, and now built in the same leading-edge manufacturing process video processing. The chip is Intel’s first to integrate the as the CPU, rather than an older process, as in earlier graphics processing unit (GPU) on the processor itself. -

Intel® Itanium® Architecture Assembly Language Reference Guide
Intel® Itanium® Architecture Assembly Language Reference Guide Copyright © 2000 - 2003 Intel Corporation. All rights reserved. Order Number: 248801-004 World Wide Web: http://developer.intel.com Intel(R) Itanium(R) Architecture Assembly Lanuage Reference Guide Page 2 Disclaimer and Legal Information Information in this document is provided in connection with Intel products. No license, express or implied, by estoppel or otherwise, to any intellectual property rights is granted by this document. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. Intel products are not intended for use in medical, life saving, or life sustaining applications. This Intel® Itanium® Architecture Assembly Language Reference Guide as well as the software described in it is furnished under license and may only be used or copied in accordance with the terms of the license. The information in this manual is furnished for informational use only, is subject to change without notice, and should not be construed as a commitment by Intel Corporation. Intel Corporation assumes no responsibility or liability for any errors or inaccuracies that may appear in this document or any software that may be provided in association with this document. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or "undefined." Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. -
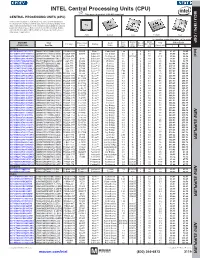
CPU) MCU / MPU / DSP This Page of Product Is Rohs Compliant
INTEL Central Processing Units (CPU) MPU /DSP MCU / This page of product is RoHS compliant. CENTRAL PROCESSING UNITS (CPU) Intel Processor families include the most powerful and flexible Central Processing Units (CPUs) available today. Utilizing industry leading 22nm device fabrication techniques, Intel continues to pack greater processing power into smaller spaces than ever before, providing desktop, mobile, and embedded products with maximum performance per watt across a wide range of applications. Atom Celeron Core Pentium Xeon For quantities greater than listed, call for quote. MOUSER Intel Core Cache Data Price Each Package Processor Family Code Freq. Size No. of Bus Width TDP STOCK NO. Part No. Series Name (GHz) (MB) Cores (bit) (Max) (W) 1 10 Desktop Intel 607-DF8064101211300Y DF8064101211300S R0VY FCBGA-559 D2550 Atom™ Cedarview 1.86 1 2 64 10 61.60 59.40 607-CM8063701444901S CM8063701444901S R10K FCLGA-1155 G1610 Celeron® Ivy Bridge 2.6 2 2 64 55 54.93 52.70 607-RK80532RC041128S RK80532RC041128S L6VR PPGA-478 - Celeron® Northwood 2.0 0.0156 1 32 52.8 42.00 40.50 607-CM8062301046804S CM8062301046804S R05J FCLGA-1155 G540 Celeron® Sandy Bridge 2.5 2 2 64 65 54.60 52.65 607-AT80571RG0641MLS AT80571RG0641MLS LGTZ LGA-775 E3400 Celeron® Wolfdale 2.6 1 2 64 65 54.93 52.70 607-HH80557PG0332MS HH80557PG0332MS LA99 LGA-775 E4300 Core™ 2 Conroe 1.8 2 2 64 65 139.44 133.78 607-AT80570PJ0806MS AT80570PJ0806MS LB9J LGA-775 E8400 Core™ 2 Wolfdale 3.0 6 2 64 65 207.04 196.00 607-AT80571PH0723MLS AT80571PH0723MLS LGW3 LGA-775 E7400 Core™ 2 Wolfdale -

Intel® Omni-Path Architecture Overview and Update
The architecture for Discovery June, 2016 Intel Confidential Caught in the Vortex…? Business Efficiency & Agility DATA: Trust, Privacy, sovereignty Innovation: New Economy Biz Models Macro Economic Effect Growth Enablers/Inhibitors Intel® Solutions Summit 2016 2 Intel® Solutions Summit 2016 3 Intel Confidential 4 Data Center Blocks Reduce Complexity Intel engineering, validation, support Data Center Blocks Speed time to market Begin with a higher level of integration HPC Cloud Enterprise Storage Increase Value VSAN Ready HPC Compute SMB Server Block Reduce TCO, value pricing Block Node Fuel innovation Server blocks for specific segments Focus R&D on value-add and differentiation Intel® Solutions Summit 2016 5 A Holistic Design Solution for All HPC Needs Intel® Scalable System Framework Small Clusters Through Supercomputers Compute Memory/Storage Compute and Data-Centric Computing Fabric Software Standards-Based Programmability On-Premise and Cloud-Based Intel Silicon Photonics Intel® Xeon® Processors Intel® Solutions for Lustre* Intel® Omni-Path Architecture HPC System Software Stack Intel® Xeon Phi™ Processors Intel® SSDs Intel® True Scale Fabric Intel® Software Tools Intel® Xeon Phi™ Coprocessors Intel® Optane™ Technology Intel® Ethernet Intel® Cluster Ready Program Intel® Server Boards and Platforms 3D XPoint™ Technology Intel® Silicon Photonics Intel® Visualization Toolkit Intel Confidential 14 Parallel is the Path Forward Intel® Xeon® and Intel® Xeon Phi™ Product Families are both going parallel How do we attain extremely high compute