Introducing Sandy Bridge
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Microcode Revision Guidance August 31, 2019 MCU Recommendations
microcode revision guidance August 31, 2019 MCU Recommendations Section 1 – Planned microcode updates • Provides details on Intel microcode updates currently planned or available and corresponding to Intel-SA-00233 published June 18, 2019. • Changes from prior revision(s) will be highlighted in yellow. Section 2 – No planned microcode updates • Products for which Intel does not plan to release microcode updates. This includes products previously identified as such. LEGEND: Production Status: • Planned – Intel is planning on releasing a MCU at a future date. • Beta – Intel has released this production signed MCU under NDA for all customers to validate. • Production – Intel has completed all validation and is authorizing customers to use this MCU in a production environment. -

Multiprocessing Contents
Multiprocessing Contents 1 Multiprocessing 1 1.1 Pre-history .............................................. 1 1.2 Key topics ............................................... 1 1.2.1 Processor symmetry ...................................... 1 1.2.2 Instruction and data streams ................................. 1 1.2.3 Processor coupling ...................................... 2 1.2.4 Multiprocessor Communication Architecture ......................... 2 1.3 Flynn’s taxonomy ........................................... 2 1.3.1 SISD multiprocessing ..................................... 2 1.3.2 SIMD multiprocessing .................................... 2 1.3.3 MISD multiprocessing .................................... 3 1.3.4 MIMD multiprocessing .................................... 3 1.4 See also ................................................ 3 1.5 References ............................................... 3 2 Computer multitasking 5 2.1 Multiprogramming .......................................... 5 2.2 Cooperative multitasking ....................................... 6 2.3 Preemptive multitasking ....................................... 6 2.4 Real time ............................................... 7 2.5 Multithreading ............................................ 7 2.6 Memory protection .......................................... 7 2.7 Memory swapping .......................................... 7 2.8 Programming ............................................. 7 2.9 See also ................................................ 8 2.10 References ............................................. -

Evaluation of the Intel Sandy Bridge-EP Server Processor
Evaluation of the Intel Sandy Bridge-EP server processor Sverre Jarp, Alfio Lazzaro, Julien Leduc, Andrzej Nowak CERN openlab, March 2012 – version 2.2 Executive Summary In this paper we report on a set of benchmark results recently obtained by CERN openlab when comparing an 8-core “Sandy Bridge-EP” processor with Intel’s previous microarchitecture, the “Westmere-EP”. The Intel marketing names for these processors are “Xeon E5-2600 processor series” and “Xeon 5600 processor series”, respectively. Both processors are produced in a 32nm process, and both platforms are dual-socket servers. Multiple benchmarks were used to get a good understanding of the performance of the new processor. We used both industry-standard benchmarks, such as SPEC2006, and specific High Energy Physics benchmarks, representing both simulation of physics detectors and data analysis of physics events. Before summarizing the results we must stress the fact that benchmarking of modern processors is a very complex affair. One has to control (at least) the following features: processor frequency, overclocking via Turbo mode, the number of physical cores in use, the use of logical cores via Simultaneous Multi-Threading (SMT), the cache sizes available, the memory configuration installed, as well as the power configuration if throughput per watt is to be measured. Software must also be kept under control and we show that a change of operating system or compiler can lead to different results, as well. We have tried to do a good job of comparing like with like. In summary, we obtained a performance improvement of 9 – 20% per core and 46 – 60% improvement across all cores available. -

The Intel X86 Microarchitectures Map Version 2.0
The Intel x86 Microarchitectures Map Version 2.0 P6 (1995, 0.50 to 0.35 μm) 8086 (1978, 3 µm) 80386 (1985, 1.5 to 1 µm) P5 (1993, 0.80 to 0.35 μm) NetBurst (2000 , 180 to 130 nm) Skylake (2015, 14 nm) Alternative Names: i686 Series: Alternative Names: iAPX 386, 386, i386 Alternative Names: Pentium, 80586, 586, i586 Alternative Names: Pentium 4, Pentium IV, P4 Alternative Names: SKL (Desktop and Mobile), SKX (Server) Series: Pentium Pro (used in desktops and servers) • 16-bit data bus: 8086 (iAPX Series: Series: Series: Series: • Variant: Klamath (1997, 0.35 μm) 86) • Desktop/Server: i386DX Desktop/Server: P5, P54C • Desktop: Willamette (180 nm) • Desktop: Desktop 6th Generation Core i5 (Skylake-S and Skylake-H) • Alternative Names: Pentium II, PII • 8-bit data bus: 8088 (iAPX • Desktop lower-performance: i386SX Desktop/Server higher-performance: P54CQS, P54CS • Desktop higher-performance: Northwood Pentium 4 (130 nm), Northwood B Pentium 4 HT (130 nm), • Desktop higher-performance: Desktop 6th Generation Core i7 (Skylake-S and Skylake-H), Desktop 7th Generation Core i7 X (Skylake-X), • Series: Klamath (used in desktops) 88) • Mobile: i386SL, 80376, i386EX, Mobile: P54C, P54LM Northwood C Pentium 4 HT (130 nm), Gallatin (Pentium 4 Extreme Edition 130 nm) Desktop 7th Generation Core i9 X (Skylake-X), Desktop 9th Generation Core i7 X (Skylake-X), Desktop 9th Generation Core i9 X (Skylake-X) • Variant: Deschutes (1998, 0.25 to 0.18 μm) i386CXSA, i386SXSA, i386CXSB Compatibility: Pentium OverDrive • Desktop lower-performance: Willamette-128 -

M39 Sandy Bridge-PDF
SANDY BRIDGE SPANS GENERATIONS Intel Focuses on Graphics, Multimedia in New Processor Design By Linley Gwennap {9/27/10-01} ................................................................................................................... Intel’s processor clock has tocked, delivering a next- periods. For notebook computers, these improvements can generation architecture for PCs and servers. At the recent significantly extend battery life by completing tasks more Intel Developer’s Forum (IDF), the company unveiled its quickly and allowing the system to revert to a sleep state. Sandy Bridge processor architecture, the next tock in its tick-tock roadmap. The new CPU is an evolutionary im- Integration Boosts Graphics Performance provement over its predecessor, Nehalem, tweaking the Intel had a false start with integrated graphics: the ill-fated branch predictor, register renaming, and instruction de- Timna project, which was canceled in 2000. More recently, coding. These changes will slightly improve performance Nehalem-class processors known as Arrandale and Clark- on traditional integer applications, but we may be reaching dale “integrated” graphics into the processor, but these the point where the CPU microarchitecture is so efficient, products actually used two chips in one package, as Figure few ways remain to improve performance. 1 shows. By contrast, Sandy Bridge includes the GPU on The big changes in Sandy Bridge target multimedia the processor chip, providing several benefits. The GPU is applications such as 3D graphics, image processing, and now built in the same leading-edge manufacturing process video processing. The chip is Intel’s first to integrate the as the CPU, rather than an older process, as in earlier graphics processing unit (GPU) on the processor itself. -
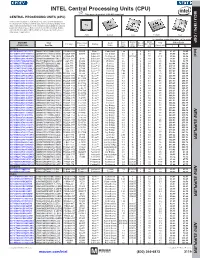
CPU) MCU / MPU / DSP This Page of Product Is Rohs Compliant
INTEL Central Processing Units (CPU) MPU /DSP MCU / This page of product is RoHS compliant. CENTRAL PROCESSING UNITS (CPU) Intel Processor families include the most powerful and flexible Central Processing Units (CPUs) available today. Utilizing industry leading 22nm device fabrication techniques, Intel continues to pack greater processing power into smaller spaces than ever before, providing desktop, mobile, and embedded products with maximum performance per watt across a wide range of applications. Atom Celeron Core Pentium Xeon For quantities greater than listed, call for quote. MOUSER Intel Core Cache Data Price Each Package Processor Family Code Freq. Size No. of Bus Width TDP STOCK NO. Part No. Series Name (GHz) (MB) Cores (bit) (Max) (W) 1 10 Desktop Intel 607-DF8064101211300Y DF8064101211300S R0VY FCBGA-559 D2550 Atom™ Cedarview 1.86 1 2 64 10 61.60 59.40 607-CM8063701444901S CM8063701444901S R10K FCLGA-1155 G1610 Celeron® Ivy Bridge 2.6 2 2 64 55 54.93 52.70 607-RK80532RC041128S RK80532RC041128S L6VR PPGA-478 - Celeron® Northwood 2.0 0.0156 1 32 52.8 42.00 40.50 607-CM8062301046804S CM8062301046804S R05J FCLGA-1155 G540 Celeron® Sandy Bridge 2.5 2 2 64 65 54.60 52.65 607-AT80571RG0641MLS AT80571RG0641MLS LGTZ LGA-775 E3400 Celeron® Wolfdale 2.6 1 2 64 65 54.93 52.70 607-HH80557PG0332MS HH80557PG0332MS LA99 LGA-775 E4300 Core™ 2 Conroe 1.8 2 2 64 65 139.44 133.78 607-AT80570PJ0806MS AT80570PJ0806MS LB9J LGA-775 E8400 Core™ 2 Wolfdale 3.0 6 2 64 65 207.04 196.00 607-AT80571PH0723MLS AT80571PH0723MLS LGW3 LGA-775 E7400 Core™ 2 Wolfdale -

Demystifying Intel® Ivy Bridge Microarchitecture
Presented at the Research Congress 2013 De La Salle University Manila March 7-9, 2013 DEMYSTIFYING INTEL® IVY BRIDGE MICROARCHITECTURE Roger Luis Uy College of Computer Studies, De La Salle University Abstract: Tick-Tock is a model introduced by Intel ® Corporation in 2006 to show the improvement of its chip development. Every “tick” is the die-shrink of the current microarchitecture, while every “tock” is the new microarchitecture. During the 2nd quarter of 2012, Ivy Bridge Microarchitecture was introduced as the 22-nm die shrink (the “tick”) of the Sandy Bridge microarchitecture (the “tock”). Ivy Bridge-based microprocessors are multi- core processor which place emphasis on minimizing thermal dissipation of processor and providing architecture innovation rather than raw processor speed. Ivy Based-processor comes in three variations – for desktop, for mobile and for server usage. Difference among them lies in the number of core in a processor, the clock frequency, the Thermal Design Power (TDP), the cache memory size and architectural innovations. This research paper will survey the Ivy Based-processor and classify them accordingly. Survey will be based from the Intel’s official website (ark.intel.com). At the same time, independent website (www.cpu-world.com) will be used to counter- check the specifications and to obtain additional information. A freeware software, called CPU-Z (www.cpuid.com) is used to gather information of the processor and provide information such as the name and number of the processor, internal and external clock rate, clock multiplier, supported instructions and cache information. Once the survey and classification is done, we can gain information on which type of applications can be used on which type of microprocessor. -

Intel's Haswell CPU Microarchitecture
Intel’s Haswell CPU Microarchitecture www.realworldtech.com/haswell-cpu/ David Kanter Over the last 5 years, high performance microprocessors have changed dramatically. One of the most significant influences is the increasing level of integration that is enabled by Moore’s Law. In the context of semiconductors, integration is an ever-present fact of life, reducing system power consumption and cost and increasing performance. The latest incarnation of this trend is the System-on-a-Chip (SoC) philosophy and design approach. SoCs have been the preferred solution for extremely low power systems, such as 1W mobile phone chips. However, high performance microprocessors span a much wider design space, from 15W notebook chips to 150W server sockets and the adoption of SoCs has been slower because of the more diverse market. Sandy Bridge was a dawn of a new era for Intel, and the first high-end x86 microprocessor that could truly be described as an SoC, integrating the CPU, GPU, Last Level Cache and system I/O. However, Sandy Bridge largely targets conventional PC markets, such as notebooks, desktops, workstations and servers, with a smattering of embedded applications. The competition for Sandy Bridge is largely AMD’s Bulldozer family, which has suffered from poor performance in the first few iterations. The 32nm Sandy Bridge CPU introduced AVX, a new instruction extension for floating point (FP) workloads and fundamentally changed almost every aspect of the pipeline, from instruction fetching to memory accesses. The system architecture was radically revamped, with a coherent ring interconnect for on-chip communication, a higher bandwidth Last Level Cache (LLC), integrated graphics and I/O, and comprehensive power management. -

Performance Evaluation of the Intel Sandy Bridge Based NASA
NAS Technical Report: NAS-2015-05 Performance Evaluation of the Intel Sandy Bridge Based NASA Pleiades Using Scientific and Engineering Applications Subhash Saini, Johnny Chang, Haoqiang Jin NASA Advanced Supercomputing Division NASA Ames Research Center Moffett Field, California 94035-1000, USA {subhash.saini, johnny.chang, haoqiang.jin}@nasa.gov Abstract — We present a performance evaluation of Pleiades based based on the Many Integrated Core (code-named Knight’s on the Intel Xeon E5-2670 processor, a fourth-generation eight-core Corner) architecture and Yellowstone [1, 5, 6]. New and Sandy Bridge architecture, and compare it with the previous third extended features of Sandy Bridge architecture are: generation Nehalem architecture. Several architectural features have been incorporated in Sandy Bridge: (a) four memory channels as a) A ring to connect on-chip L3 cache with cores, system opposed to three in Nehalem; (b) memory speed increased from 1333 agent, memory controller, and QPI agent and I/O MHz to 1600 MHz; (c) ring to connect on-chip L3 cache with cores, controller to increase the scalability. L3 cache per core system agent, memory controller, and QPI agent and I/O controller to has been increased from 2 MB to 2.5 MB. increase the scalability; (d) new AVX unit with wider vector registers of 256 bit; (e) integration of PCI-Express 3.0 controllers into the I/O b) New micro-ops (L0) cache that caches instructions as subsystem on chip; (f) new Turbo Boost version 2.0 where base they are decoded. The cache is direct mapped and can frequency of processor increased from 2.6 to 3.2 GHz; and (g) QPI link store 1.5 K micro-ops. -

Intel® Processor Architecture
Intel® Processor Architecture January 2013 Software & Services Group, Developer Products Division Copyright © 2013, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. Agenda •Overview Intel® processor architecture •Intel x86 ISA (instruction set architecture) •Micro-architecture of processor core •Uncore structure •Additional processor features – Hyper-threading – Turbo mode •Summary Software & Services Group, Developer Products Division Copyright © 2013, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. 2 Intel® Processor Segments Today Architecture Target ISA Specific Platforms Features Intel® phone, tablet, x86 up to optimized for ATOM™ netbook, low- SSSE-3, 32 low-power, in- Architecture power server and 64 bit order Intel® mainstream x86 up to flexible Core™ notebook, Intel® AVX, feature set Architecture desktop, server 32 and 64bit covering all needs Intel® high end server IA64, x86 by RAS, large Itanium® emulation address space Architecture Intel® MIC accelerator for x86 and +60 cores, Architecture HPC Intel® MIC optimized for Instruction Floating-Point Set performance Software & Services Group, Developer Products Division Copyright © 2013, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners. 3 Itanium® 9500 (Poulson) New Itanium Processor Poulson Processor • Compatible with Itanium® 9300 processors (Tukwila) Core Core 32MB Core Shared Core • New micro-architecture with 8 Last Core Level Core Cores Cache Core Core • 54 MB on-die cache Memory Link • Improved RAS and power Controllers Controllers management capabilities • Doubles execution width from 6 to 12 instructions/cycle 4 Intel 4 Full + 2 Half Scalable Width Intel • 32nm process technology Memory QuickPath Interface Interconnect • Launched in November 2012 (SMI) Compatibility provides protection for today’s Itanium® investment Software & Services Group, Developer Products Division Copyright © 2013, Intel Corporation. -

How to Write Fast Numerical Code Spring 2013 Lecture: Architecture/Microarchitecture and Intel Core
How to Write Fast Numerical Code Spring 2013 Lecture: Architecture/Microarchitecture and Intel Core Instructor: Markus Püschel TA: Georg Ofenbeck & Daniele Spampinato Technicalities Research project: . Let us know once you have a partner . Three in a team is fine, but not one . If you have a project idea, talk to me after class or this week Tues 10:30, Wed 15:00, Fr 10:00 (1 hour each) . Some clarifications from my side . Deadline: March 7th Finding partner: [email protected] . Recipients: TA Georg + all students that have no partner yet 2 © Markus Püschel How to write fast numerical code Computer Science Spring 2013 Today Architecture/Microarchitecture In detail: Core 2/Core i7 Crucial microarchitectural parameters Peak performance Operational intensity 3 Definitions Architecture (also instruction set architecture = ISA): The parts of a processor design that one needs to understand to write assembly code Examples: instruction set specification, registers Counterexamples: cache sizes and core frequency Example ISAs . x86 . ia . MIPS . POWER . SPARC . ARM 4 © Markus Püschel How to write fast numerical code Computer Science Spring 2013 MMX: Multimedia extension SSE: Intel x86 Processors Streaming SIMD extension x86-16 8086 AVX: Advanced vector extensions 286 x86-32 386 486 Pentium MMX Pentium MMX SSE Pentium III time SSE2 Pentium 4 SSE3 Pentium 4E x86-64 / em64t Pentium 4F Core 2 Duo SSE4 Penryn Core i7 (Nehalem) AVX Sandy Bridge 5 ISA SIMD (Single Instruction Multiple Data) Vector Extensions What is it? . Extension of the ISA. Data types and instructions for the parallel computation on short (length 2-8) vectors of integers or floats + x 4-way . -

Intel's Core 2 Family
Intel’s Core 2 family - TOCK lines References Dezső Sima Vers. 1.0 Januar 2019 Contents (1) • 1. Introduction • 2. The Core 2 line • 3. The Nehalem line • 4. The Sandy Bridge line • 5. The Haswell line • 6. The Skylake line • 7. The Kaby Lake line • 8. The Kaby Lake Refresh line • 9. The Coffee Lake line • 10. The Coffee Lake line Refresh Contents (2) • 11. The Cannon Lake line (outlook) • 12. Sunny Cove • 13. References 13. References 12. References (1) [1]: Singhal R., “Next Generation Intel Microarchitecture (Nehalem) Family: Architecture Insight and Power Management, IDF Taipeh, Oct. 2008, http://intel.wingateweb.com/taiwan08/ published/sessions/TPTS001/FA08%20IDFTaipei_TPTS001_100.pdf [2]: Bryant D., “Intel Hitting on All Cylinders,” UBS Conf., Nov. 2007, http://files.shareholder.com/downloads/INTC/0x0x191011/e2b3bcc5-0a37-4d06- aa5a-0c46e8a1a76d/UBSConfNov2007Bryant.pdf [3]: Fisher S., “Technical Overview of the 45 nm Next Generation Intel Core Microarchitecture (Penryn),” IDF 2007, ITPS001, http://isdlibrary.intel-dispatch.com/isd/89/45nm.pdf [4]:Pabst T., The New Athlon Processor: AMD Is Finally Overtaking Intel, Tom's Hardware, August 9, 1999, http://www.tomshardware.com/reviews/athlon-processor,121-2.html [5]: Carmean D., “Inside the Pentium 4 Processor Micro-architecture,” Aug. 2000, http://people.virginia.edu/~zl4j/CS854/pda_s01_cd.pdf [6]: Shimpi A. L. & Clark J., “AMD Opteron 248 vs. Intel Xeon 2.8: 2-way Web Servers go Head to Head,” AnandTech, Dec. 17 2003, http://www.anandtech.com/showdoc.aspx?i=1935&p=1 [7]: Völkel F., “Duel of the Titans: Opteron vs. Xeon : Hammer Time: AMD On The Attack,” Tom’s Hardware, Apr.