How to Write Fast Numerical Code Spring 2013 Lecture: Architecture/Microarchitecture and Intel Core
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Intel® IA-64 Architecture Software Developer's Manual
Intel® IA-64 Architecture Software Developer’s Manual Volume 1: IA-64 Application Architecture Revision 1.1 July 2000 Document Number: 245317-002 THIS DOCUMENT IS PROVIDED “AS IS” WITH NO WARRANTIES WHATSOEVER, INCLUDING ANY WARRANTY OF MERCHANTABILITY, NONINFRINGEMENT, FITNESS FOR ANY PARTICULAR PURPOSE, OR ANY WARRANTY OTHERWISE ARISING OUT OF ANY PROPOSAL, SPECIFICATION OR SAMPLE. Information in this document is provided in connection with Intel products. No license, express or implied, by estoppel or otherwise, to any intellectual property rights is granted by this document. Except as provided in Intel's Terms and Conditions of Sale for such products, Intel assumes no liability whatsoever, and Intel disclaims any express or implied warranty, relating to sale and/or use of Intel products including liability or warranties relating to fitness for a particular purpose, merchantability, or infringement of any patent, copyright or other intellectual property right. Intel products are not intended for use in medical, life saving, or life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or "undefined." Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. Intel® IA-64 processors may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Copies of documents which have an order number and are referenced in this document, or other Intel literature, may be obtained by calling 1-800- 548-4725, or by visiting Intel’s website at http://developer.intel.com/design/litcentr. -

Microcode Revision Guidance August 31, 2019 MCU Recommendations
microcode revision guidance August 31, 2019 MCU Recommendations Section 1 – Planned microcode updates • Provides details on Intel microcode updates currently planned or available and corresponding to Intel-SA-00233 published June 18, 2019. • Changes from prior revision(s) will be highlighted in yellow. Section 2 – No planned microcode updates • Products for which Intel does not plan to release microcode updates. This includes products previously identified as such. LEGEND: Production Status: • Planned – Intel is planning on releasing a MCU at a future date. • Beta – Intel has released this production signed MCU under NDA for all customers to validate. • Production – Intel has completed all validation and is authorizing customers to use this MCU in a production environment. -

Asrock G41C-VS Motherboard, a Reliable Motherboard Produced Under Asrock’S Consistently Stringent Quality Control
G41C-VS User Manual Version 1.0 Published October 2009 Copyright©2009 ASRock INC. All rights reserved. 1 Copyright Notice: No part of this manual may be reproduced, transcribed, transmitted, or translated in any language, in any form or by any means, except duplication of documentation by the purchaser for backup purpose, without written consent of ASRock Inc. Products and corporate names appearing in this manual may or may not be regis- tered trademarks or copyrights of their respective companies, and are used only for identification or explanation and to the owners’ benefit, without intent to infringe. Disclaimer: Specifications and information contained in this manual are furnished for informa- tional use only and subject to change without notice, and should not be constructed as a commitment by ASRock. ASRock assumes no responsibility for any errors or omissions that may appear in this manual. With respect to the contents of this manual, ASRock does not provide warranty of any kind, either expressed or implied, including but not limited to the implied warran- ties or conditions of merchantability or fitness for a particular purpose. In no event shall ASRock, its directors, officers, employees, or agents be liable for any indirect, special, incidental, or consequential damages (including damages for loss of profits, loss of business, loss of data, interruption of business and the like), even if ASRock has been advised of the possibility of such damages arising from any defect or error in the manual or product. This device complies with Part 15 of the FCC Rules. Operation is subject to the following two conditions: (1) this device may not cause harmful interference, and (2) this device must accept any interference received, including interference that may cause undesired operation. -

MBP4ASG41M-VS3.Pdf
ASRock > G41M-VS3 Página 1 de 2 Home | Global / English [Change] About ASRock Products News Support Forum Download Awards Dealer Zone Where to Buy Products G41M-VS3 Motherboard Series »G41M-VS3 Translate »Overview & Specifications ■ Supports FSB1333/1066/800/533 MHz CPUs »Download ■ Supports Dual Channel DDR3 1333(OC) ■ Intel® Graphics Media Accelerator X4500, Pixel Shader 4.0, DirectX 10, Max. shared »Manual memory 1759MB »FAQ ■ EuP Ready »CPU Support List ■ Supports ASRock XFast RAM, XFast LAN, XFast USB Technologies ■ Supports Instant Boot, Instant Flash, OC DNA, ASRock OC Tuner (Up to 158% CPU »Memory QVL frequency increase) »Beta Zone ■ Supports Intelligent Energy Saver (Up to 20% CPU Power Saving) ■ Free Bundle : CyberLink DVD Suite - OEM and Trial; Creative Sound Blaster X-Fi MB - Trial This model may not be sold worldwide. Please contact your local dealer for the availability of this model in your region. Product Specifications General - LGA 775 for Intel® Core™ 2 Extreme / Core™ 2 Quad / Core™ 2 Duo / Pentium® Dual Core / Celeron® Dual Core / Celeron, supporting Penryn Quad Core Yorkfield and Dual Core Wolfdale processors - Supports FSB1333/1066/800/533 MHz CPU - Supports Hyper-Threading Technology - Supports Untied Overclocking Technology - Supports EM64T CPU - Northbridge: Intel® G41 Chipset - Southbridge: Intel® ICH7 - Dual Channel DDR3 memory technology - 2 x DDR3 DIMM slots - Supports DDR3 1333(OC)/1066/800 non-ECC, un-buffered memory Memory - Max. capacity of system memory: 8GB* *Due to the operating system limitation, the actual memory size may be less than 4GB for the reservation for system usage under Windows® 32-bit OS. For Windows® 64-bit OS with 64-bit CPU, there is no such limitation. -

SIMD Extensions
SIMD Extensions PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 12 May 2012 17:14:46 UTC Contents Articles SIMD 1 MMX (instruction set) 6 3DNow! 8 Streaming SIMD Extensions 12 SSE2 16 SSE3 18 SSSE3 20 SSE4 22 SSE5 26 Advanced Vector Extensions 28 CVT16 instruction set 31 XOP instruction set 31 References Article Sources and Contributors 33 Image Sources, Licenses and Contributors 34 Article Licenses License 35 SIMD 1 SIMD Single instruction Multiple instruction Single data SISD MISD Multiple data SIMD MIMD Single instruction, multiple data (SIMD), is a class of parallel computers in Flynn's taxonomy. It describes computers with multiple processing elements that perform the same operation on multiple data simultaneously. Thus, such machines exploit data level parallelism. History The first use of SIMD instructions was in vector supercomputers of the early 1970s such as the CDC Star-100 and the Texas Instruments ASC, which could operate on a vector of data with a single instruction. Vector processing was especially popularized by Cray in the 1970s and 1980s. Vector-processing architectures are now considered separate from SIMD machines, based on the fact that vector machines processed the vectors one word at a time through pipelined processors (though still based on a single instruction), whereas modern SIMD machines process all elements of the vector simultaneously.[1] The first era of modern SIMD machines was characterized by massively parallel processing-style supercomputers such as the Thinking Machines CM-1 and CM-2. These machines had many limited-functionality processors that would work in parallel. -

Validating the Intel® Pentium® 4 Microprocessor
16.1 9DOLGDWLQJ WKH ,QWHO 3HQWLXP 0LFURSURFHVVRU %RE%HQWOH\ ,QWHO&RUSRUDWLRQ 1(WK$YHQXH +LOOVERUR2UHJRQ86$ EREEHQWOH\#LQWHOFRP ABSTRACT 2. OVERVIEW Developing a new leading edge IA-32 microprocessor is an The Pentium® 4 processor is Intel’s most advanced IA-32 immensely complicated undertaking. In the case of the Pentium® microprocessor, incorporating a host of new microarchitectural 4 processor, the microarchitecture is significantly more complex features including a 400-MHz system bus, hyper-pipelined than any previous IA-32 microprocessor and the implementation technology, advanced dynamic execution, rapid execution engine, borrows almost nothing from any previous implementation. This advanced transfer cache, execution trace cache, and Streaming paper describes how we went about the task of finding bugs in the SIMD (Single Instruction, Multiple Data) Extensions 2 (SSE2). Pentium® 4 processor design prior to initial silicon, and what we For the most part, we applied similar tools and methodologies to found along the way. validating the Pentium® 4 processor that we had used previously General Terms on the Pentium® Pro processor. However, we developed new Management, Verification. methodologies and tools in response to lessons learnt from previous projects, and to address some of the new challenges that the Pentium® 4 processor design presented from a validation 1. INTRODUCTION perspective. In particular, the use of Formal Verification, Cluster Validation case studies are relatively rare in the literature of Test Environments and focused Power Reduction Validation were computer architecture and design ([1] and [2] contain lists of either new or greatly extended from previous projects; each of some recent papers) and case studies of commercial these is discussed in more detail in a section of this paper microprocessors are even rarer. -

Toshiba Hardware Portfolio – Microsoft Support by Family
Date created: 6/17/2020 Toshiba Hardware Portfolio – Microsoft Support by Family Windows 10 Windows 10 Windows 10 Toshiba Windows 10 Toshiba IoT IoT Enterprise Intel Platform Machine Intel Processor Model IoT Enterprise Family Enterprise LTSC 2019 Type LTSB 2015 LTSB 2016 Core i3 9100TE 777 TCx™ 700 4900 Core i5 9500T 787 9th Gen Core Core i7 9700T 797 (Coffee Lake Not Supported Refresh) Core i3 9100TE 371 TCx™ 300 4810 Core i5 9500T 381 Core i7 9700T 391 8th Gen Core TCx™ 300 4810 361 Celeron 4900T (Coffee Lake) TCx™ 700 4900 767 107 Available now and Core i7 7600U 117 supported until 137 Not Supported Jan 9, 2029 105 Core i5 7300U 115 7th Gen Core 135 TCx™ 800 6200 Available (Kaby Lake) 103 now and Core i3 7100U 113 supported until 133 Oct 13, 2026 10C Celeron 3965U 11C 13C N/A 4750 AMD GX-218GL D10 SoC Family Basics Celeron J1900 4818 T10 (Bay Trail) Quad Not Supported 6th Gen Core 145 TCxWave™ 6140 Core i5 6300U (Skylake/Q170) 155 Date created: 6/17/2020 14C Celeron 3955U 15C SoC Family Celeron J1900 A3R (Bay Trail) Quad Core i5 4950S 786 Available Core i3 4330 C86 now and TCx™ 700 4900 Celeron G1820 supported until 746 Oct 14, 2025 4th Gen Core Celeron G1820TE (Haswell/Q87) C46 Core i5 4570TE 380 TCx™ 300 4810 Core i3 4330TE 370 Celeron G1820TE 360 3rd Gen Core + TCxWave ™ 6140 Core i3 3217UE 120 2nd Gen PCH SurePOS (IvyBridge CPU + 4852 Core i5 3550S 580 CougarPoint PCH) 500 Toshiba Toshiba Limited TCxWave ™ 6140 Celeron 847E 100 Limited Support SurePOS Celeron G540 785 Support 2nd Gen Core 4900 700 Core i3 2120 C85 (SandyBridge/Q67) -

Class-Action Lawsuit
Case 3:20-cv-00863-SI Document 1 Filed 05/29/20 Page 1 of 279 Steve D. Larson, OSB No. 863540 Email: [email protected] Jennifer S. Wagner, OSB No. 024470 Email: [email protected] STOLL STOLL BERNE LOKTING & SHLACHTER P.C. 209 SW Oak Street, Suite 500 Portland, Oregon 97204 Telephone: (503) 227-1600 Attorneys for Plaintiffs [Additional Counsel Listed on Signature Page.] UNITED STATES DISTRICT COURT DISTRICT OF OREGON PORTLAND DIVISION BLUE PEAK HOSTING, LLC, PAMELA Case No. GREEN, TITI RICAFORT, MARGARITE SIMPSON, and MICHAEL NELSON, on behalf of CLASS ACTION ALLEGATION themselves and all others similarly situated, COMPLAINT Plaintiffs, DEMAND FOR JURY TRIAL v. INTEL CORPORATION, a Delaware corporation, Defendant. CLASS ACTION ALLEGATION COMPLAINT Case 3:20-cv-00863-SI Document 1 Filed 05/29/20 Page 2 of 279 Plaintiffs Blue Peak Hosting, LLC, Pamela Green, Titi Ricafort, Margarite Sampson, and Michael Nelson, individually and on behalf of the members of the Class defined below, allege the following against Defendant Intel Corporation (“Intel” or “the Company”), based upon personal knowledge with respect to themselves and on information and belief derived from, among other things, the investigation of counsel and review of public documents as to all other matters. INTRODUCTION 1. Despite Intel’s intentional concealment of specific design choices that it long knew rendered its central processing units (“CPUs” or “processors”) unsecure, it was only in January 2018 that it was first revealed to the public that Intel’s CPUs have significant security vulnerabilities that gave unauthorized program instructions access to protected data. 2. A CPU is the “brain” in every computer and mobile device and processes all of the essential applications, including the handling of confidential information such as passwords and encryption keys. -

The Microarchitecture of the Pentium 4 Processor
The Microarchitecture of the Pentium 4 Processor Glenn Hinton, Desktop Platforms Group, Intel Corp. Dave Sager, Desktop Platforms Group, Intel Corp. Mike Upton, Desktop Platforms Group, Intel Corp. Darrell Boggs, Desktop Platforms Group, Intel Corp. Doug Carmean, Desktop Platforms Group, Intel Corp. Alan Kyker, Desktop Platforms Group, Intel Corp. Patrice Roussel, Desktop Platforms Group, Intel Corp. Index words: Pentium® 4 processor, NetBurst™ microarchitecture, Trace Cache, double-pumped ALU, deep pipelining provides an in-depth examination of the features and ABSTRACT functions of the Intel NetBurst microarchitecture. This paper describes the Intel® NetBurst™ ® The Pentium 4 processor is designed to deliver microarchitecture of Intel’s new flagship Pentium 4 performance across applications where end users can truly processor. This microarchitecture is the basis of a new appreciate and experience its performance. For example, family of processors from Intel starting with the Pentium it allows a much better user experience in areas such as 4 processor. The Pentium 4 processor provides a Internet audio and streaming video, image processing, substantial performance gain for many key application video content creation, speech recognition, 3D areas where the end user can truly appreciate the applications and games, multi-media, and multi-tasking difference. user environments. The Pentium 4 processor enables real- In this paper we describe the main features and functions time MPEG2 video encoding and near real-time MPEG4 of the NetBurst microarchitecture. We present the front- encoding, allowing efficient video editing and video end of the machine, including its new form of instruction conferencing. It delivers world-class performance on 3D cache called the Execution Trace Cache. -
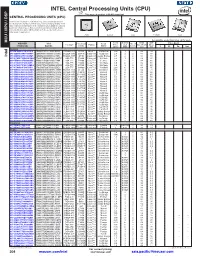
INTEL Central Processing Units (CPU) This Page of Product Is Rohs Compliant
INTEL Central Processing Units (CPU) This page of product is RoHS compliant. CENTRAL PROCESSING UNITS (CPU) Intel Processor families include the most powerful and flexible Central Processing Units (CPUs) available today. Utilizing industry leading 22nm device fabrication techniques, Intel continues to pack greater processing power into smaller spaces than ever before, providing desktop, mobile, and embedded products with maximum performance per watt across a wide range of applications. Atom Celeron Core Pentium Xeon For quantities greater than listed, call for quote. MCU \ MPU / DSP MPU / MCU \ MOUSER Intel Core Cache Data TDP Price Each Package Processor Family Code Freq. Size No. of Bus Width (Max) STOCK NO. Part No. Series Name (GHz) (MB) Cores (bit) (W) 1 25 50 100 Desktop 607-DF8064101211300Y DF8064101211300S R0VY FCBGA-559 D2550 Atom™ Cedarview 1.86 1 2 64 10 607-CM8063701444901S CM8063701444901S R10K FCLGA-1155 G1610 Celeron® Ivy Bridge 2.6 2 2 64 55 Intel 607-CM8062301046804S CM8062301046804S R05J FCLGA-1155 G540 Celeron® Sandy Bridge 2.5 2 2 64 65 607-AT80571RG0641MLS AT80571RG0641MLS LGTZ LGA-775 E3400 Celeron® Wolfdale 2.6 1 2 64 65 607-HH80557PG0332MS HH80557PG0332MS LA99 LGA-775 E4300 Core™ 2 Conroe 1.8 2 2 64 65 607-AT80570PJ0806MS AT80570PJ0806MS LB9J LGA-775 E8400 Core™ 2 Wolfdale 3.0 6 2 64 65 607-AT80571PH0723MLS AT80571PH0723MLS LGW3 LGA-775 E7400 Core™ 2 Wolfdale 2.8 3 2 64 65 607-AT80580PJ0676MS AT80580PJ0676MS LB6B LGA-775 Q9400 Core™ 2 Yorkfield 2.66 6 4 64 95 607-CM80616003060AES CM80616003060AES LBTD FCLGA-1156 -

Evolution of Microprocessor Performance
EvolutionEvolution ofof MicroprocessorMicroprocessor PerformancePerformance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static & dynamic branch predication. Even with these improvements, the restriction of issuing a single instruction per cycle still limits the ideal CPI = 1 Multiple Issue (CPI <1) Multi-cycle Pipelined T = I x CPI x C (single issue) Superscalar/VLIW/SMT Original (2002) Intel Predictions 1 GHz ? 15 GHz to ???? GHz IPC CPI > 10 1.1-10 0.5 - 1.1 .35 - .5 (?) Source: John P. Chen, Intel Labs We next examine the two approaches to achieve a CPI < 1 by issuing multiple instructions per cycle: 4th Edition: Chapter 2.6-2.8 (3rd Edition: Chapter 3.6, 3.7, 4.3 • Superscalar CPUs • Very Long Instruction Word (VLIW) CPUs. Single-issue Processor = Scalar Processor EECC551 - Shaaban Instructions Per Cycle (IPC) = 1/CPI EECC551 - Shaaban #1 lec # 6 Fall 2007 10-2-2007 ParallelismParallelism inin MicroprocessorMicroprocessor VLSIVLSI GenerationsGenerations Bit-level parallelism Instruction-level Thread-level (?) (TLP) 100,000,000 (ILP) Multiple micro-operations Superscalar /VLIW per cycle Simultaneous Single-issue CPI <1 u Multithreading SMT: (multi-cycle non-pipelined) Pipelined e.g. Intel’s Hyper-threading 10,000,000 CPI =1 u uuu u u Chip-Multiprocessors (CMPs) u Not Pipelined R10000 e.g IBM Power 4, 5 CPI >> 1 uuuuuuu u AMD Athlon64 X2 u uuuuu Intel Pentium D u uuuuuuuu u u 1,000,000 u uu uPentium u u uu i80386 u i80286 -

Intel(R) Pentium(R) 4 Processor on 90 Nm Process Datasheet
Intel® Pentium® 4 Processor on 90 nm Process Datasheet 2.80 GHz – 3.40 GHz Frequencies Supporting Hyper-Threading Technology1 for All Frequencies with 800 MHz Front Side Bus February 2005 Document Number: 300561-003 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. Intel products are not intended for use in medical, life saving, or life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked “reserved” or “undefined.” Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The Intel® Pentium® 4 processor on 90 nm process may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Contact your local Intel sales office or your distributor to obtain the latest specifications and before placing your product order. 1Hyper-Threading Technology requires a computer system with an Intel® Pentium® 4 processor supporting HT Technology and a Hyper-Threading Technology enabled chipset, BIOS and operating system.