CGI Developer's Guide by Eugene Eric Kim
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

{Download PDF} High Five with Julius
HIGH FIVE WITH JULIUS PDF, EPUB, EBOOK Paul Frank | 10 pages | 24 Feb 2010 | CHRONICLE BOOKS | 9780811871471 | English | California, United States High Five with Julius PDF Book Rate this:. My 3-year-old loved giving each character a high-five and then her hand would linger as she felt the different textures. English On Shelf. How Can We Help? As two-way G-League point guard Kadeem Allen bounced away the final seconds, a large throng of Knicks fans stood up and roared as the club moved to Big Deal, Baby. McGraw Hill. Nice Partner! Randle and others talked about a lack of focus at the morning shootaround Monday. You are commenting using your WordPress. Table of Contents. Universal Conquest Wiki. Smiling this much is so heartwarming! It did the trick. On Shelf. I think focusing primarily on the individual is definitely the first step. A medical study found that fist bumps and high fives spread fewer germs than handshakes. Welcome to another Write a Review Wednesday , a meme started by Tara Lazar as a way to show support to authors of kids literature. Each spread encourages kids to celebrate amazing everyday achievementsfrom sharing their toys to just being themselvesand features a touch-and-feel texture that will keep little ones engaged as they strive to be and do their very best. Redirected from High-five. National High Five Day is a project to give out high fives and is typically held on the third Thursday in April. Categories : introductions American cultural conventions Hand gestures. By continuing to use this website, you agree to their use. -

Discontinued Browsers List
Discontinued Browsers List Look back into history at the fallen windows of yesteryear. Welcome to the dead pool. We include both officially discontinued, as well as those that have not updated. If you are interested in browsers that still work, try our big browser list. All links open in new windows. 1. Abaco (discontinued) http://lab-fgb.com/abaco 2. Acoo (last updated 2009) http://www.acoobrowser.com 3. Amaya (discontinued 2013) https://www.w3.org/Amaya 4. AOL Explorer (discontinued 2006) https://www.aol.com 5. AMosaic (discontinued in 2006) No website 6. Arachne (last updated 2013) http://www.glennmcc.org 7. Arena (discontinued in 1998) https://www.w3.org/Arena 8. Ariadna (discontinued in 1998) http://www.ariadna.ru 9. Arora (discontinued in 2011) https://github.com/Arora/arora 10. AWeb (last updated 2001) http://www.amitrix.com/aweb.html 11. Baidu (discontinued 2019) https://liulanqi.baidu.com 12. Beamrise (last updated 2014) http://www.sien.com 13. Beonex Communicator (discontinued in 2004) https://www.beonex.com 14. BlackHawk (last updated 2015) http://www.netgate.sk/blackhawk 15. Bolt (discontinued 2011) No website 16. Browse3d (last updated 2005) http://www.browse3d.com 17. Browzar (last updated 2013) http://www.browzar.com 18. Camino (discontinued in 2013) http://caminobrowser.org 19. Classilla (last updated 2014) https://www.floodgap.com/software/classilla 20. CometBird (discontinued 2015) http://www.cometbird.com 21. Conkeror (last updated 2016) http://conkeror.org 22. Crazy Browser (last updated 2013) No website 23. Deepnet Explorer (discontinued in 2006) http://www.deepnetexplorer.com 24. Enigma (last updated 2012) No website 25. -

Introduction What’S Race Got to Do with It? Postwar German History in Context
After the Nazi Racial State: Difference and Democracy in Germany and Europe Rita Chin, Heide Fehrenbach, Geoff Eley, and Atina Grossmann http://www.press.umich.edu/titleDetailDesc.do?id=354212 The University of Michigan Press, 2009. Introduction What’s Race Got to Do With It? Postwar German History in Context Rita Chin and Heide Fehrenbach In June 2006, just prior to the start of the World Cup in Germany, the New York Times ran a front-page story on a “surge in racist mood” among Germans attending soccer events and anxious of‹cials’ efforts to discour- age public displays of racism before a global audience. The article led with the recent experience of Nigerian forward Adebowale Ogungbure, who, af- ter playing a match in the eastern German city of Halle, was “spat upon, jeered with racial remarks, and mocked with monkey noises” as he tried to exit the ‹eld. “In rebuke, he placed two ‹ngers under his nose to simulate a Hitler mustache and thrust his arm in a Nazi salute.”1 Although the press report suggested the contrary, the racist behavior directed at Ogungbure was hardly resurgent or unique. Spitting, slurs, and offensive stereotypes have a long tradition in the German—and broader Euro-American—racist repertoire. Ogungbure’s wordless gesture, more- over, gave the lie to racism as a worrisome product of the New Europe or even the new Germany. Rather, his mimicry ef‹ciently suggested continu- ity with a longer legacy of racist brutality reaching back to the Third Reich. In effect, his response to the antiblack bigotry of German soccer fans was accusatory and genealogically precise: it screamed “Nazi!” and la- beled their actions recidivist holdovers from a fanatical fascist past. -

Research Article Automated Region Extraction from Thermal Images for Peripheral Vascular Disease Monitoring
Hindawi Journal of Healthcare Engineering Volume 2018, Article ID 5092064, 14 pages https://doi.org/10.1155/2018/5092064 Research Article Automated Region Extraction from Thermal Images for Peripheral Vascular Disease Monitoring Jean Gauci ,1 Owen Falzon ,1 Cynthia Formosa ,2 Alfred Gatt ,2 Christian Ellul,2 Stephen Mizzi ,2 Anabelle Mizzi ,2 Cassandra Sturgeon Delia,3 Kevin Cassar,3 Nachiappan Chockalingam ,4 and Kenneth P. Camilleri 1 1Centre for Biomedical Cybernetics, University of Malta, Msida MSD2080, Malta 2Department of Podiatry, University of Malta, Msida MSD2080, Malta 3Department of Surgery, University of Malta, Msida MSD2080, Malta 4Faculty of Health Sciences, Staffordshire University, Staffordshire ST4 2DE, UK Correspondence should be addressed to Jean Gauci; [email protected] Received 18 June 2018; Revised 26 October 2018; Accepted 15 November 2018; Published 13 December 2018 Guest Editor: Orazio Gambino Copyright © 2018 Jean Gauci et al. )is is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. )is work develops a method for automatically extracting temperature data from prespecified anatomical regions of interest from thermal images of human hands, feet, and shins for the monitoring of peripheral arterial disease in diabetic patients. Binarisation, morphological operations, and geometric transformations are applied in cascade to automatically extract the required data from 44 predefined regions of interest. )e implemented algorithms for region extraction were tested on data from 395 participants. A correct extraction in around 90% of the images was achieved. )e process of automatically extracting 44 regions of interest was performed in a total computation time of approximately 1 minute, a substantial improvement over 10 minutes it took for a corresponding manual extraction of the regions by a trained individual. -

Drome De ROSENTHAL (II) 14944 Rc)SSLE's Syndrome
ROSSLE'S 14944-14967 Saccharomyces halluzinatorisches Angst-Syndrom) / syn 14954 rules, pregnancy control / Schwanger drome de ROSENTHAL (II) schaftskontrollregeln f (1. moglichst nicht 14944 Rc)SSLE'S syndrome / ROSSLE' Syndrom (Se invasiv [Ultraschall], 2. nur mit kurzlebigen xogener Kleinwuchs) / nanisme sexoge Radionukliden, vor allem zur Diagnose der nique Nieren- und Plazentafunktion, erst ab 3. 14945 rotation, chromosomal / Rotation, chromo Trimenon [JANISCH]) / regles de controle de somale f (in Bivalenten mit Chiasma zwi grossesse f schen Diplotan und Diakinese eintretende 14955 rules, sense for / Gefuhl fur Regeln n Formverandrung) / rotation chromosomi (psych.) / regles, sens pour m quef 14956 ruling forecast; science forecasting / Richtli 14946 round pronator syndrome / Pronator-teres nienprognose; Wissenschaftsprognose f / Syndrom (Schwache in den langen Finger prevision directrice; prevision scientifique f beugem) / syndrome de pronateur rond 14957 rumors / Geriichte n (konnen aus Traumen 14947 ROVIRALTA'S syndrome / ROVIRALTA' Syn entstehen) / rumeurs f drom (Pylorusstenose und Hiatushemie 14958 running, dancing / Laufen, tanzerisches n mit Magenektopie beim Saugling) / syn (tagliches ohne Leistungsdruck bis zur Er drome phrenopylorique (ROVIRALTA) miidung, besser als Radfahren, Schwim 14948 ROWLEY'S syndrome / ROWLEY' Syndrom men, Reiten, halt aerobe Kapazitat kon (SchwerhOrigkeit mit Halsfisteln) / syn stant, eroffnet Kollateralen und vermehrt drome de ROWLEY Zahl und GroBe der Mitochondrien) / cou 14949 ROWLEy-ROSENBERG syndrome / ROWLEY rir dansant m ROSENBERG' Syndrom (Gestorte Riickab 14959 rupture of the bladder / Blaseruptur f(klin. sorption fast aller Aminosauren) / syn Leitsymptom: blutige Dysurie; sichre Dia drome de ROWLEy-ROSENBERG gnose: Zystographie mit Kontrastmittel, 14950 rubb~~g, emotional/ Reibung, emotionale f wenn nicht moglich, Probelaparotomie und (bei UbervOlkrung groBres Problem als bei jeder gesicherten Ruptur sofortige Op. -

Animatronic Wireless Hand
ANIMATRONIC WIRELESS HAND A PROJECT REPORT Submitted by J. JANET M. KAVITHA R. KIRAN CHANDER in partial fulfillment for the award of the degree of BACHELOR OF ENGINEERING IN ELECTRICAL AND ELECTRONICS ENGINEERING EASWARI ENGINEERING COLLEGE, CHENNAI-89 ANNA UNIVERSITY: CHENNAI-600 025 APRIL 2019 ii ANNA UNIVERSITY: CHENNAI 600 025 BONAFIDE CERTIFICATE Certified that this project report “ANIMATRONIC WIRELESS HAND” is the bonafide work of “J.JANET (310615105030), M.KAVITHA (310615105033) and R.KIRAN CHANDER (310615105035)” who carried out the project work under my supervision. SIGNATURE SIGNATURE Dr.E.KALIAPPAN,M.Tech., Ph.D., Ms.B.PONKARTHIKA,M.E., HEAD OF THE DEPARTMENT SUPERVISOR ASSISTANT PROFESSOR DEPARTMENT OF ELECTRICAL AND DEPARTMENT OF ELECRICAL AND ELECTRONICS ENGINEERING ELECTRONICS ENGINEERING EASWARI ENGINEERING COLLEGE EASWARI ENGINEERING COLLEGE RAMAPURAM - 600089 RAMAPURAM – 600089 Submitted for the University examination held for project work at Easwari Engineering College on ……………………… INTERNAL EXAMINER EXTERNAL EXAMINER iii ACKNOWLEDGEMENT We would like to express our sincere thanks to our respected chairman, Dr. R. SHIVAKUMAR, M.D., Ph.D., for providing us with requisite infrastructure throughout the course. We would like to express our sincere thanks to our beloved Principal Dr. K. KATHIRAVAN, M.Tech., Ph.D., for his encouragement. We are highly indebted to the Department of Electrical and Electronics Engineering for providing all the facilities for the successful completion of the project. With a deep sense of gratitude, we would like to sincerely thank our Head of the Department Dr.E.KALIAPPAN, M.Tech., Ph.D., for his constant support, encouragement and valuable guidance for our project work. We are extremely grateful to our project supervisor Ms.B.PONKARTHIKA M.E., Assistant Professor, Department of Electrical and Electronics Engineering for her consent guidance, suggestions and kind help in bringing out this project within scheduled time frame. -

World Wide Web
Informationsdienste im Internet World Wide Web Diese Reisen durch's Internet sollen jetzt auch viel Wissenschaftler, die an gemeinsamen Projekten ar- komfortabler geworden sein - und teurer. Man reist beiten, sind oft über die ganze Welt verstreut. Mitar- jetzt mit Mosaic. Gopher kennt kaum noch einer (?). beiter, Studenten, Gast-Wissenschaftler wechseln Was mein Nachbar bei seiner letzten Reise so alles zwischen den Forschungszentren, bleiben aber Mit- gesehen hat ... glieder dieser verteilten Arbeitsgruppen. Dazu kommt Anstelle einer Vorrede hier ein Auszug aus den Noti- die Vielfalt der Hard- und Software. Wer den Ar- zen jenes ,Datenreisenden’: beitsort wechselte, mußte mit neuen Rechnernamen, Paßworten, Terminalemulationen, Kommandos usw. W3 Search Engines zurechtkommen (Sie kennen das?). Für eine effekti- World Wide Web FAQ vere Zusammenarbeit wurde deshalb dringend ein The Best of WWW Contest System benötigt, das orts- und rechnerunabhängig Oldenburg Archie Gateway den Zugang zu Informationen und deren Austausch HypArt - The Project vereinfacht. Linux Software Map Dieses System heißt heute World Wide Web, hat sich Studienberatung für das Lehramt sehr schnell über das gesamte Internet verbreitet und Lernen und Lehren im WWW ist inzwischen einer der wichtigsten Informations- Yoga für alle dienste. Esperanto HyperCourse Dieser Artikel sollen allen „Newbies“ (Lektion1: Shoemaker-Levy 9/Jupiter Collision Internet-Sprachgebrauch) einen Überblick verschaf- Libraries via Internet fen und mit einer kurzen Beschreibung des Mosaic- German -
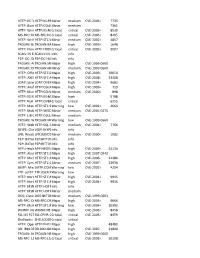
HTTP: IIS "Propfind" Rem HTTP:IIS:PROPFIND Minor Medium
HTTP: IIS "propfind"HTTP:IIS:PROPFIND RemoteMinor DoS medium CVE-2003-0226 7735 HTTP: IkonboardHTTP:CGI:IKONBOARD-BADCOOKIE IllegalMinor Cookie Languagemedium 7361 HTTP: WindowsHTTP:IIS:NSIISLOG-OF Media CriticalServices NSIISlog.DLLcritical BufferCVE-2003-0349 Overflow 8035 MS-RPC: DCOMMS-RPC:DCOM:EXPLOIT ExploitCritical critical CVE-2003-0352 8205 HTTP: WinHelp32.exeHTTP:STC:WINHELP32-OF2 RemoteMinor Buffermedium Overrun CVE-2002-0823(2) 4857 TROJAN: BackTROJAN:BACKORIFICE:BO2K-CONNECT Orifice 2000Major Client Connectionhigh CVE-1999-0660 1648 HTTP: FrontpageHTTP:FRONTPAGE:FP30REG.DLL-OF fp30reg.dllCritical Overflowcritical CVE-2003-0822 9007 SCAN: IIS EnumerationSCAN:II:IIS-ISAPI-ENUMInfo info P2P: DC: DirectP2P:DC:HUB-LOGIN ConnectInfo Plus Plus Clientinfo Hub Login TROJAN: AOLTROJAN:MISC:AOLADMIN-SRV-RESP Admin ServerMajor Responsehigh CVE-1999-0660 TROJAN: DigitalTROJAN:MISC:ROOTBEER-CLIENT RootbeerMinor Client Connectmedium CVE-1999-0660 HTTP: OfficeHTTP:STC:DL:OFFICEART-PROP Art PropertyMajor Table Bufferhigh OverflowCVE-2009-2528 36650 HTTP: AXIS CommunicationsHTTP:STC:ACTIVEX:AXIS-CAMERAMajor Camerahigh Control (AxisCamControl.ocx)CVE-2008-5260 33408 Unsafe ActiveX Control LDAP: IpswitchLDAP:OVERFLOW:IMAIL-ASN1 IMail LDAPMajor Daemonhigh Remote BufferCVE-2004-0297 Overflow 9682 HTTP: AnyformHTTP:CGI:ANYFORM-SEMICOLON SemicolonMajor high CVE-1999-0066 719 HTTP: Mini HTTP:CGI:W3-MSQL-FILE-DISCLSRSQL w3-msqlMinor File View mediumDisclosure CVE-2000-0012 898 HTTP: IIS MFCHTTP:IIS:MFC-EXT-OF ISAPI FrameworkMajor Overflowhigh (via -

Schweizer / WS 09/10 - 1 - 18
Schweizer / WS 09/10 - 1 - 18. Feb. 2011 Schweizer / WS 09/10 - 2 - 18. Feb. 2011 Pragmatik I - Beschreibung von 1. Impulse zur Arbeitsfeldumschreibung 1.1 Sprachkritik als Ideologiekritik: "Im Interesse..." Text, Ko-Text und situativem Kontext 1.2 Wortsinn und Kommunikationssituation: Kaspar Hauser 1.3 Stilistik, Rhetorik - Regeln zur Textgestaltung? 1.4 Segmentierung einer Kommunikation: top down: A users gram- - Harald Schweizer - mar 1.5 Streit unter ComputerlinguistInnen: top down oder bottom Di 17-19 Uhr Sand 6, Hs 2 up? 1.6 Wortformen-Syntax vs. kontextbezogene Semantik (TG) = eigen- ständige Strukturen: Poet K. Marti Unter: http://www-ct.informatik.uni-tuebingen.de/index.htm LEH- 1.7 Schrittweise Enthüllung der gemeinten Bedeutung: Wertungen RE LEHRANGEBOT ist dieses file (Gliederung/Literaturliste/Mate- 1.8 Politische Semantik: Vordenker 1.9 Theoretische Aufarbeitung rialien) zugänglich 1.91 Definitionsversuch 1.92 Einbeziehung nicht-sprachlicher Botschaften 1.93 Kommunikationsmodell - etwas verändert 1.94 GRICE: Implikatur (im Gegensatz zu Implikation) Fakultät für Informations- und Kognitionswissenschaften 1.95 Implikation (im Gegensatz zu Implikatur) 1.96 Besteht eine Grammatik aus Regeln? Arbeitsbereich Textwissenschaft 1.97 Versuch einer Zusammenfassung 2. Kontextbildende Elementare Mechanismen/textgrammatisch 2.1 Überprüfung der Prädikatbedeutungen 2.11 "Echte" Prädikate = Außenweltveränderungen, persönlich zure- Sand 13 chenbar, nicht lediglich Ortsveränderung 2.12 Illokutionssignale 72076 Tübingen 2.13 Interpretamente (Adjunktion) [email protected] 2.14 Weitgefaßter Terminus "Modalverb" 2.15 Deixis: Topologie/Chronologie Fon: 29-75248 2.16 Weitere Rezeptionssteuerungen Fax: 29-5060 2.2 Kontextbildung im Wortsinn 2.3 Revision der semantischen Prädikation: tg Verschiebung 2.4 Textdeiktische Elemente: Anaphern/Kataphern Sprechstunden: Mi 11-13 (bzw. -

“In the Name of the Holy Trinity”: Examining Credibility Under Anarchy Through 250 Years of Treaty-Making
\In The Name of the Holy Trinity": Examining Credibility Under Anarchy Through 250 Years of Treaty-Making Krzysztof Pelcy November 2019, Prepared for IPES 2019 Abstract Where does the binding force of international treaties come from? This article considers three centuries of international peace treaties to chart how signatories have sought to convince one another of the viability of their commitments. I show how one means of doing so was by invoking divine authority: treaty violations were punished by divine sanction in heaven and excommunication on earth. Anarchy, \the fundamental assumption of international politics," is commonly defined as \the absence of a supreme power." Yet an examination of peace treaties from the 1600s onwards suggests that for much of the post-Westphalian era, sovereigns would not have envisioned themselves as operating under anarchy. Rather, they strategically invoked divine authority to add credibility to their commitments. Signatories facing a high probability of war are seen relying more heavily on invocations of divine authority. Strikingly, treaties that invoke divine authority then show a greater conflict-abating effect. Using automated text analysis of two thousand peace, commerce, and navigation treaties spanning 250 years, I show how treaty performance was affected when signatories lost the ability to invoke the divine as a means of binding themselves. God appears to be statistically significant. yDepartment of Political Science, McGill University, [email protected]. 1 Introduction \The Ratification of the -

The Internet Companion, 2Nd Edition
The Internet Companion, 2nd edition The Internet Companion A Beginner's Guide to Global Networking (2nd edition) by Tracy LaQuey The OBS is pleased to present our free, "distributive" full-text HTML version of the second edition of this bestselling title, linked to resources around the world. As with all our distributive publications, we invite you to browse, comment, and send in your link suggestions. We are also pleased to offer paths to a sibling version of the Internet Companion, produced as a class project at the University of North Carolina. This use of online files points the way to a new form of reading and publishing on the Net: true interactivity where the students or readers can affect a book's content by finding, choosing, and implementing links for it. About the Internet Companion What World Media is Saying About the Internet Companion About Tracy LaQuey Copyright The Internet Companion at the University of North Carolina Buy this Book http://www.obs-us.com/obs/english/books/editinc/top.htm (1 of 3) [5/1/1999 11:46:04 PM] The Internet Companion, 2nd edition Contents Front Matter Foreword Preface Chapter 1 What Is the Internet and Why Should You Know About It? Whence It Came It Keeps Going and Going . The Equalizer Peeling Back the Layers: Differences between Networks Convergence: A Traffic Circle on the Information Highway Mrs. Smith Connects to Washington Business Use Backing Out of the Driveway The Future Chapter 2 Internet: The Lowdown A Network of Networks In the Beginning How Computers Talk Who Runs the Internet? Acceptable -

Author Guidelines for 8
HAND GESTURE RECOGNITION USING A SKELETON-BASED FEATURE REPRESENTATION WITH A RANDOM REGRESSION FOREST Shaun Canavan, Walter Keyes, Ryan Mccormick, Julie Kunnumpurath, Tanner Hoelzel, and Lijun Yin Binghamton University ABSTRACT In this paper, we propose a method for automatic hand gesture recognition using a random regression forest with a novel set of feature descriptors created from skeletal data acquired from the Leap Motion Controller. The efficacy of our proposed approach is evaluated on the publicly available University of Padova Microsoft Kinect and Leap Motion dataset, as well as 24 letters of the English alphabet in American Sign Language. The letters that are dynamic (e.g. j and z) are not evaluated. Using a random regression forest Figure 1. Proposed gesture recognition overview. to classify the features we achieve 100% accuracy on the University of Padova Microsoft Kinect and Leap Motion and because of this it is natural to use this camera for hand dataset. We also constructed an in-house dataset using the gesture recognition. The Leap skeletal tracking model gives 24 static letters of the English alphabet in ASL. A us access to the following information that we use to create classification rate of 98.36% was achieved on this dataset. our feature descriptors; (1) palm center; (2) hand direction We also show that our proposed method outperforms the (3) fingertip positions; (4) total number of fingers (extended current state of the art on the University of Padova and non-extended); and (5) finger pointing directions. Using Microsoft Kinect and Leap Motion dataset. this information from the Leap we propose six new feature descriptors which include (1) extended finger binary Index Terms— Gesture, Leap, ASL, recognition representation; (2) max finger range; (3) total finger area; (4) finger length-width ratio; and (5-6) finger directions and 1.