Learning From# Barcelona Instagram Data What Locals and Tourists Post
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Humanizing Streets the Superblocks in the Eixample, Barcelona
HUMANIZING STREETS THE SUPERBLOCKS IN THE EIXAMPLE, BARCELONA Pamela AcuÑA Kuchenbecker Msc Thesis LanDscape Architecture WAGeninGen UniVersitY October 2019 HUMANIZING STREETS THE SUPERBLOCKS IN THE EIXAMPLE, BARCELONA Pamela ANDrea AcuÑA Kuchenbecker Msc Thesis LanDscape Architecture WAGeninGen UniVersitY October 2019 © Pamela Acuña Kuchenbecker Chair Group Landscape Architecture Wageningen University October 2019 All rights reserved. No part of this thesis may be reproduced, stored in a retrieval system, or transmitted in any form or any means, electronic, mechanical, photocopying, recording or otherwise, without the prior written permission of either the author or the Wageningen University Landscape Architecture Chairgroup. Pamela Andrea Acuña Kuchenbecker Registration number: 111184005150 [email protected] LAR-80436/39 Master Thesis Landscape Architecture Chair Group Landscape Architecture Phone: +31 317 484 056 Fax: +31 317 482 166 E-mail: [email protected] www.lar.wur.nl Postbus 47 6700 AA, Wageningen The Netherlands Examiner Dr. ir. Rudi van Etteger MA Wageningen University, Landscape Architecture group Supervisor & examiner Dr. dipl. ing. Sanda Lenzholzer Wageningen University, Landscape Architecture group Humanizing streets ABSTRACT People’s behavior is affected by the combination of sight, Therefore, the purpose of this thesis is to generate sounds, smells, textures, tastes, and thermal conditions, knowledge for the intersections of superblocks, which can determine how long a place will be used. The which present a deficiency in providing citizens with built environment, due to its population growth over the a comfortable and positive sensory experience. This centuries and with its consequent reduction of green thesis fills the knowledge gap by inferring a new multi- urban areas, has deprived citizens of many pleasures and sensory approach, which aims towards a pleasurable introduced new unpleasant sensations. -

Bolstering Community Ties and Its Effect on Crime
Bolstering community ties and its effect on crime: Evidence from a quasi-random experiment Magdalena Dom´ınguez and Daniel Montolio∗ Work in progress - Do not cite without permission This version: February 2019 Abstract In this paper we study the effect of bolstering community ties on local crime rates. To do so, we take advantage of the quasi-random nature of the implementation of a community health policy in the city of Barcelona. Salut als Barris (BSaB) is a policy that through community-based initiatives and empowerment of citizenship aims at improving health outcomes and reducing inequalities of the most disadvantaged neighborhoods. Based on economic and sociological literature it is also arguable that it may affect other relevant variables for overall welfare, such as crime rates. In order to test such a hypothesis, we use monthly data at the neighborhood level and a staggered Differences-in-Differences approach. Overall we find that BSaB highly reduces crimes related to non-cognitive features as well as those where there is a very close personal link (labeled as home crimes), with responses ranging from 9% to 18%. Additionally, female victimization rates drop for all age groups as well as the offense rates of younger cohorts. We argue that such outcomes are due to stronger community ties. Such results provide evidence in favor of non-traditional crime preventing policies. Keywords: crime; community action; differences-in-differences. JEL codes: C23, I18, I28, J18. ∗Dept. of Economics, University of Barcelona and IEB: [email protected] ; [email protected] We are grateful to Elia Diez and Maribel Pasarin at the Barcelona Public Health Agency (ASPB) and IGOP researchers Raquel Gallego and Ernesto Morales at Autonomous University of Barcelona (UAB) for their insightful comments on the program. -

Analyzing Last Mile Delivery Operations in Barcelona's Urban
Analyzing Last Mile Delivery Operations in Barcelona’s Urban Freight Transport Network Burcu Kolbay1, Petar Mrazovic2, and Josep Llus Larriba-Pey1 1 DAMA-UPC Data Management, Universitat Politecnica de Catalunya C/Jordi Girona, 1 3 UPC Campus Nord 08034 Barcelona, Spain {burcu, larri}@ac.upc.edu http://www.dama.upc.edu/en 2 Dept. of Software and Computer Systems, Royal Institute of Technology, Stockholm, Sweden [email protected] http://www.kth.se Abstract. Barcelona has recently started a new strategy to control and understand Last Mile Delivery, AreaDUM. The strategy is to provide freight delivery vehicle drivers with a mobile app that has to be used every time their vehicle is parked in one of the designated AreaDUM surface parking spaces in the streets of the city. This provides a significant amount of data about the activity of the freight delivery vehicles, their patterns, the occupancy of the spaces, etc. In this paper, we provide a preliminary set of analytics preceded by the procedures employed for the cleansing of the dataset. During the analysis we show that some data blur the results and using a simple strategy to detect when a vehicle parks repeatedly in close-by parking slots, we are able to obtain different, yet more reliable results. In our paper, we show that this behavior is common among users with 80% prevalence. We conclude that we need to analyse and understand the user behaviors further with the purpose of providing predictive algorithms to find parking lots and smart routing algorithms to minimize traffic. Keywords: Urban Freight, Clustering, Partitioning Around Medoids, User Behavior, Smart City, AreaDUM 1 Introduction Barcelona is considered to be among the smartest cities in the planet. -

2025 BARCELONA RIGHT to HOUSING PLAN EXECUTIVE SUMMARY BCN Developed by the Councillorship of Housing and Dependent Bodies
2016 - 2025 BARCELONA RIGHT TO HOUSING PLAN EXECUTIVE SUMMARY BCN Developed by the Councillorship of Housing and dependent bodies Councillorship of Housing Gerència d’habitatge Josep Maria Montaner Martorell Javier Burón Cuadrado Vanesa Valiño Esparducer Ivan Gallardo Ruiz Montse Prats López Eva Jou Caballero Dámaris Fernandez Barceló IMU- Barcelona Gestió Urbanística SA Josep Maria de Torres Sanahuja Jordi Amela i Abella Carme Blasi Carrera Gerard Capó Fuentes Glòria Oller Luengo Esther Ródenas Estopiñà Camino Suárez Garcia Patronat Municipal de l’habitatge de Barcelona (Barcelona’s Municipal Board of Housing) Àngels Mira Cortadellas Xavier Gonzalez Garuz Isidre Costa Manuel Gómez Joaquim Pasqual Housing Offices’ management Drafting and coordination Cooperatives Celobert and estudi LaCol Project monitoring by Dolors Clavell Nadal Economic and financial Project by Mur&Clusa Economistes Legal study by professors Juli Ponce Solé and Domènec Sibina Tomàs Sociodemographic study by Institut d’Estudis Regionals i Metropolitans de Barcelona Public Participation process coordination by cooperatives Celobert and LaCol With contributions from: Social Rights Area Carles Gil Miquel, Esther Quintana Escarra, Núria Menta Sala, Jordi Sánchez Masip, Emília Pallàs Zenke, direccions territorials de districte Ecology, urban planning and mobility Area Jaume Barnada López, Antoni Font Ferrer, Roger Clot Dunach, Montserrat Hosta Privat, Miquel García Sanjuan, Direccions de serveis tècnics IMunicipal Institute of Urban Landscape and Quality of Life Xavier Olivella -

Artists, Cultural Gentrification and Public Policy
S104 DOI: 10.5379/urbani-izziv-en-2012-23-supplement-1-010 Artists, Cultural Gentrification and Public Policy Antònia Casellas, Esteve Dot-Jutgla and Montserrat Pallares-Barbera Antònia Casellas, Department of Geography, Universitat Autònoma de Barcelona, Barcelona, Spain ([email protected]) Esteve Dot-Jutgla, Department of Geography, Universitat Autònoma de Barcelona, Barcelona, Spain ([email protected]) Montserrat Pallares-Barbera, Department of Geography, Universitat Autònoma de Barcelona, Barcelona, Spain ([email protected]) Abstract Since the 1980s, artists have been studied as agents of urban gentrification. Well established theories and case studies have provided numerous evidences of the role of artists as initiators of the gentrification process in working-class neighborhoods. From a productive-side perspective, placing an emphasis on the rent-gap and land development, as well as consumption-side perspective, analyzing the features of individuals, art production and artists have been identified as a source of initial gentrification. Complementary theorizations have studied the second wave of displacement produced by the massive arrival of private capital, which often has affected the artists themselves. The present paper adds to the body of literature than identifies the public sector as another key agent of gentrification. The paper analyzes the role of Barcelona’s public sector in the process of implementing this redevelopment program, and its interaction with artists in the neighborhood. In specific terms, it discusses the case of the Hangar Collective, located in Can Ricart, an old factory building which had been the home of small firms and artist groups. This center was at the heart of the urban struggle to maintain the status of firms and artists in the neighborhood, and to preserve the architectonic structure of the old factory complex. -

El Modelo Barcelona De Espacio Público Y Diseño Urbano
EL MODELO BARCELONA DE ESPACIO PÚBLICO Y DISEÑO URBANO: DE LA MANCHESTER CATALANA AL 22@ CALLE PERE IV - EL EJE OBRERO DEL POBLENOU Màster en Diseño Urbano: Arte, Ciudad, Sociedad. Facultat de Belles Arts EL MODELO BARCELONA DE ESPACIO PÚBLICO Y DISEÑO URBANO: DE LA MANCHESTER CATALANA AL 22@ CALLE PERE IV – EL EJE OBRERO DEL POBLENOU Autor: Reinaldo de Jesus Cônsoli Trabajo final para la obtención del grado de Master en Diseño Urbano: Arte, Ciudad, Sociedad Tutor/es: Dr. Antoni Remesar JUNIO 2013 MA en Diseño Urbano: Arte, Ciudad, Sociedad EL MODELO BARCELONA DE ESPACIO PÚBLICO Y DISEÑO URBANO: DE LA “MANCHESTER CATALANA” AL 22@ CALLE PERE IV – EL EJE OBRERO DEL POBLENOU 1 MA en Diseño Urbano: Arte, Ciudad, Sociedad ABSTRACT The objectives of this Master´s thesis are to analiyze the urban transformation processes that turned out in the generation of the street Pere IV, its peculiar situation in the Poblenou territory, neighborhood where it is located, as well as to outline some guidelines for its future regeneration. Starting from the so called “Modelo Barcelona” (The Barcelona Model) general framework, emphasizing on the premises that worked as its background, its different phases and finally questioning its own definition as model. The investigation goes through an itinerary that presupposes two significant changes of scale, in order to get closer to object of study: the Pere IV street. The first change takes place when delimiting Poblenou as an intermediate study area, neighborhood that has its origins in activities related to shepherding and agriculture back in the 18th century, then becoming Catalonia´s main area of industrial development at the end of 19th century until its decadence from the 1960´s on. -

Ciutat Vella
Ciutat Vella Estudi de l'oferta i la demanda per a identificar potencials mancances a l'oferta de productes necessaris per a una vida quotidiana sostenible al Districte de Ciutat Vella Barcelona, 13 juny 2017 1 Índex 1. Antecedents 3 2. Objecte i àmbit de l'estudi 5 3. Metodologia 7 4. Perfil sociodemogràfic 13 5. Anàlisi de béns i serveis a la llar 18 6. Anàlisi de preus de productes de consum quotidià 34 7. Conclusions 44 8. Fonts 45 9. Equip 46 2 1. Antecedents 3 1. Antecedents Com a exemple cal destacar que el Districte té una mitjana del 42,4% de població 1.1 Antecedents. estrangera. En el cas del Raval el 40% d'aquesta població està composada per paquistanesos i filipins. Per contra, al barri de San Pere, Santa Caterina i La El present estudi respon a les línies estratègiques i mesures necessàries Ribera la nacionalitat predominant és la italiana, amb un 15% dels estrangers. O detectades al Pla de Desenvolupament Econòmic Ciutat Vella 2016-2021. Amb la Barceloneta, que té el percentatge més baix d'estrangers, un 31,3%, però on l'objectiu de promoure la diversitat i el comerç de proximitat (Línia estratègica 1), el la diversitat de les nacionalitats es multiplica, essent un altre cop la italiana la Pla preveu diverses accions a dur a terme, entre elles la "realització d'un estudi predominant, amb un 16%. de l'oferta i la demanda per a identificar potencials mancances a l'oferta de productes necessaris per a una vida quotidiana sostenible". L'estudi determina D'altra banda es pot destacar que, mentre a Barcelona les llars composades per l'oferta de béns i serveis com l'alimentació fresca, l'equipament personal i de la una sola persona representen el 30,79%, a Ciutat Vella representen el 37,58%, llar, la salut i la higiene, entre d'altres, posant-la en relació a la diversitat de la amb un important 40,28% al barri de Sant Pere, Canta Caterina i la Ribera. -

Sant Martí Tindrà Un Nou Casal De Joves Al Carrer Pallars
10_SANT_MARTI_68.qxp:bcn 26/1/11 20:55 Página 1 BARRISDE www.bcn.cat | Febrer 2011 SANT MARTÍ EL CAMP DE L'ARPA DEL CLOT · EL CLOT · EL PARC I LA LLACUNA DEL POBLENOU · LA VILA OLÍMPICA DEL POBLENOU · EL POBLENOU · DIAGONAL MAR I EL FRONT MARÍTIM DEL POBLENOU · EL BESÒS I EL MARESME · PROVENÇALS DEL POBLENOU · SANT MARTÍ DE PROVENÇALS · LA VERNEDA I LA PAU SUPLEMENT ENTREVISTA Pàg. 8 Sant Martí tindrà un nou casal de joves al carrer Pallars PATRIMONI ACTIVITATS PARTICIPACIÓ S’ubicarà en una El casal serà lloc de Han participat en antiga fàbrica tèxtil trobada dels joves el projecte col·lectius JOSEP MARIA CONTEL del carrer Pallars del barri i entitats juvenils Clàudia Prat Pàg. 3 Gimnasta de trampolí “La meva vida gira al voltant de l’esport, al qual dedico moltes hores” SOLIDARITAT Pàg. 4 Associació per a la reinserció de dones Ajuda persones amb problemes personals greus ENTITATS Pàg. 6 Club Bàsquet Alisos Gestionarà la pista Joan Pujades VICENTE ZAMBRANO Joves a la ludoteca Maria Gràcia Pont. SERVEIPÚBLIC Pàg. 7 Casa d’acollida per a Un accés situat al cor de la rambla dones que pateixen El Poblenou guanya del Poblenou (números 77-91) violència masclista condueix a l’edifici de la Ludoteca Maria Gràcia Pont. Fins ara, una nova zona verda aquest equipament municipal es- POLIESPORTIU Pàg. 7 tava isolat al mig d’un interior d’i- lla, amb l’única companyia de dues Pirena 2011 petites àrees enjardinades. La pro- La presentació omple funda transformació de la zona la Nova Icària causada per la construcció del dis- tricte 22@ n’ha canviat el paisatge. -
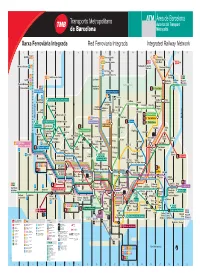
TMB Int Central 9-08
Xarxa Ferroviària Integrada Red Ferroviaria Integrada Integrated Railway Network 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Igualada R6 S1 Terrassa-Rambla R4 Manresa Montcada i Reixac S2 Sabadell-Rambla R7 Santa Maria R3 Vic Manresa-Baixador R5 Cerdanyola Universitat / Martorell Montcada i Reixac Manresa S5 Sant Cugat - Rubí S55 Universitat Autònoma Montcada R4 Sant Vicenç de Calders Ripollet R2 S33 Les Planes Can Ros Montcada Montcada Maçanet Bifurcació i Reixac Massanes Olesa de Montserrat S4 Parc Natural de Collserola R1 Baixador de Martorell-Enllaç S8 Vallvidrera Can Cuiàs P Molins de Rei Vallvidrera-Superior Ciutat Meridiana P Tibidabo Sant Feliu Sant Feliu | Consell Comarcal Torre Baró Torre Montbau de Llobregat Carretera de Mundet Vallbona del Baró les Aigües Canyelles Roquetes Torreblanca Peu del Vall d’Hebron Casa de Funicular Vallvidrera l’Aigua Sant Walden Inferior Pl. del Joan Despí Funicular Valldaura Rambla de Sant Just L3 Trinitat Nova Riu Llobregat L6 Penitents L4 Trinitat Nova Besòs Riu L7 Sant Martí de l’Erm Sant Martí de l’Erm Reina Elisenda L5 Horta Trinitat Nova Bon Viatge La Fontsanta L3 Sarrià Av. Tibidabo Pont d’Esplugues Vallcarca Via Júlia Trinitat Zona Universitària Parc Vilapicina Vella Centre Miquel La Llucmajor Sardana Can Clota Güell Fontsanta Martí i Pol Zona El Putxet Montesa Universitària Palau Reial Fatjò Cornellà Les Tres Torres Sant Andreu Torras Centre El Pedró Ca n’Oliveres i Bages Baró de Les Aigües Pius XII Lesseps Arenal Viver Ignasi Iglésias La Bonanova Pàdua Virrei Amat L8 Molí Nou- Av. -

Equivalència Territorial En La Planificació Educativa a Barcelona: Diagnòstic I Propostes
Equivalència territorial en la planificació educativa a Barcelona: Diagnòstic i propostes Xavier Bonal i Adrián Zancajo, GEPS-UAB ÍNDEX INTRODUCCIÓ ................................................................................................................................... 3 CAPÍTOL 1: EQUIVALÈNCIA TERRITORIAL EN LA IGUALTAT D’OPORTUNITATS EDUCATIVES ..................................................................................................................................... 5 1.1. El concepte d’equivalència aplicat a la planificació educativa ................................................ 5 1.2. Equivalència en accés, procés i resultats ................................................................................ 6 CAPÍTOL 2: EQUILIBRIS I DESEQUILIBRIS EN LA DISTRIBUCIÓ DE L’OFERTA EDUCATIVA ..................................................................................................................................... 11 2.1. L’equilibri territorial de places escolars de P3 ....................................................................... 11 2.2. Estructura espacial de l’oferta i valor de la proximitat ........................................................... 14 CAPÍTOL 3: ELS FLUXOS DE MOBILITAT DE L’ALUMNAT ENTRE TERRITORIS .................. 19 3.1. Sobreescolarització i infraescolarització per zones educatives ............................................ 19 3.2. Fluxos de mobilitat entre territoris .......................................................................................... 21 3.3. Factors -

Mapa De La Nova Xarxa De Bus [PDF: 201
FUNICULAR Plànol DEL TIBIDABO PARC DEL Ciutat Meridiana Can Marcet LABERINT Mundet V25 Horta nova xarxa FUNICULAR DE D50 VALLVIDRERA V23 CEMENTIRI Av. Pl. Alfonso Montbau Pg. de bus Sarrià VallD’HORTA d’Hebron Sarrià Isaac Newton– Tibidabo Comín PARC VALL V27 Canyelles Av. Tibidabo HOSPITAL DE LA V21 D’HEBRON Can Caralleu V7 Vall d’Hebron V3 V9 Anglí-Terré V13 VALL D’HEBRON Canyelles V15 Pl. Karl Marx Vallbona Av. V19 D40 de l’Estatut Can Caralleu Bonanova Vall d’Hebron . Guineueta Roquetes St. Joan Foix . V17 V29 Av V de Déu . Pl. Borràs J Pl. Borràs P i Puig . Av. Tibidabo g v V11 Pedralbes Pl. Alfonso Santa RosaliaArenys . V5 A Maragall Via Augusta Via H2 Pg. Reina Iradier Trinitat Nova Comín . Fabra Artesania Aiguablava Av. d’Esplugues H2 Elisenda Pg Almansa Rda. Pedralbes Carmel Parc Central PARC CREUETA Nou Barris de Dalt Sarrià Av. d’Esplugues Pg. Bonanova DEL COLL Via Júlia V1 Reina Av. d’Esplugues Bonanova V13 Pg. Sant Gervasi Santuari Bisbe Elisenda Anglí-Iradier Rbla. Pedrell Pg V31 Trinitat Vella Català . M. Déu . Valldaura Pl. Pg Llucmajor NUS DE H4 del Coll Rambla del Meridiana UPC CAMPUS Mandri Dr. Pi Anglí Carmel i Molist Pl. de la República Av. Pg. Sta.LA TRINITAT Coloma Zona Universitària NORD Mandri Kennedy Horta Calatrava Muntaner Gran PALAU DE Sant s Virrei Amat Ganduxer Balmes H6 Gervasi PARC GÜELL a St. Andreu Pg. Llorenç PEDRALBES TÚNEL v Serra Tres Torres Rda. Vallcarca o PARC ESPORTIU DE LA ROVIRA n Palomar Zona Av. Pedralbes CAN DRAGÓ Sant Andreu Metro Ernest Lluch H8 Av. -

Class, Culture and Conflict in Barcelona 1898–1937
Class, Culture and Conflict in Barcelona 1898–1937 This is a study of social protest and repression in one of the twentieth century’s most important revolutionary hotspots. It explains why Barcelona became the undisputed capital of the European anarchist movement and explores the sources of anarchist power in the city. It also places Barcelona at the centre of Spain’s economic, social, cultural and political life between 1898 and 1937. During this period, a range of social groups, movements and institutions competed with one another to impose their own political and urban projects on the city: the central authorities struggled to retain control of Spain’s most unruly city; nationalist groups hoped to create the capital of Catalonia; local industrialists attempted to erect a modern industrial city; the urban middle classes planned to democratise the city; and meanwhile, the anarchists sought to liberate the city’s workers from oppression and exploitation. This resulted in a myriad of frequently violent conflicts for control of the city, both before and during the civil war. This is a work of great importance in the field of contemporary Spanish history and fills a significant gap in the current literature. Chris Ealham is Senior Lecturer in the Department of History, Lancaster University. He is co-editor of The Splintering of Spain: Historical Perspectives on the Spanish Civil War. His work focuses on labour and social protest in Spain, and he is currently working on a history of urban conflict in 1930s Spain. Routledge/Cañada Blanch Studies