ISO/IEC International Standard 10646-1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ST.36 Page: 3.36.1
HANDBOOK ON INDUSTRIAL PROPERTY INFORMATION AND DOCUMENTATION Ref.: Standards – ST.36 page: 3.36.1 STANDARD ST.36 Version 1.2 RECOMMENDATION FOR THE PROCESSING OF PATENT INFORMATION USING XML (EXTENSIBLE MARKUP LANGUAGE) Revision adopted by ST.36 Task Force of the Standards and Documentation Working Group (SDWG) on November 23, 2007 TABLE OF CONTENTS INTRODUCTION ............................................................................................................................................................ 2 DEFINITIONS ................................................................................................................................................................. 3 SCOPE OF THE STANDARD ........................................................................................................................................ 3 REQUIREMENTS OF THE STANDARD........................................................................................................................ 4 General ......................................................................................................................................................................... 4 Characters .................................................................................................................................................................... 5 Naming international common elements....................................................................................................................... 6 Naming office-specific elements -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

COSC345 Week 24 Internationalisation And
COSC345 Week 24 Internationalisation and Localisation 29 September 2015 Richard A. O'Keefe 1 From a Swedish h^otelroom Hj¨alposs att v¨arnerom v˚armilj¨o! F¨oratt minska utsl¨appav tv¨attmedel, byter vi Er handduk bara n¨arNi vill: 1. Handduk p˚agolvet | betyder att Ni vill ha byte 2. ... 2 The translation Help us to care for our environment! To reduce the use of laundry detergents, we shall change your towel as follows: 1. Towel on the floor | you want to have a new towel. 2. Towel hung up | you want to use it again. 3 People should be able to use computers in their own language. | It's just right not to make people struggle with unfamiliar lin- guistic and cultural codes. | Sensible people won't pay for programs that are hard to use. | Internationalisation (I18N) means making a program so that it does not enforce a particular language or set of cultural conventions | Localisation (L10N) means adapting an internationalised pro- gram to a particular language etc. | UNIX, VMS, Windows, all support internationalisation and lo- calisation; the Macintosh operating system has done this better for longer. 4 Characters You know that there are 26 letters in 2 cases. But Swedish has ˚a,¨a,¨o, A,˚ A,¨ and O¨ (29 letters), Croatian has d j, D j, D J, and others (3 cases), German has ß, which has no single upper case version (might be SS, might be SZ, both of which are two letters), Latin-1 has 58 letters in 2 cases (including 2 lower case letters with no upper case version), Arabic letters have 4 contextual shapes (beginning, middle, or end of word, or isolated), which are not case variants (Greek has one such letter, and Hebrew has several; even English used to), and Chinese has tens of thousands of characters. -

Bopomofo Extended Range: 31A0–31BF
Bopomofo Extended Range: 31A0–31BF This file contains an excerpt from the character code tables and list of character names for The Unicode Standard, Version 14.0 This file may be changed at any time without notice to reflect errata or other updates to the Unicode Standard. See https://www.unicode.org/errata/ for an up-to-date list of errata. See https://www.unicode.org/charts/ for access to a complete list of the latest character code charts. See https://www.unicode.org/charts/PDF/Unicode-14.0/ for charts showing only the characters added in Unicode 14.0. See https://www.unicode.org/Public/14.0.0/charts/ for a complete archived file of character code charts for Unicode 14.0. Disclaimer These charts are provided as the online reference to the character contents of the Unicode Standard, Version 14.0 but do not provide all the information needed to fully support individual scripts using the Unicode Standard. For a complete understanding of the use of the characters contained in this file, please consult the appropriate sections of The Unicode Standard, Version 14.0, online at https://www.unicode.org/versions/Unicode14.0.0/, as well as Unicode Standard Annexes #9, #11, #14, #15, #24, #29, #31, #34, #38, #41, #42, #44, #45, and #50, the other Unicode Technical Reports and Standards, and the Unicode Character Database, which are available online. See https://www.unicode.org/ucd/ and https://www.unicode.org/reports/ A thorough understanding of the information contained in these additional sources is required for a successful implementation. -

Proposal for Ethiopic Script Root Zone LGR
Proposal for Ethiopic Script Root Zone LGR LGR Version 2 Date: 2017-05-17 Document version:5.2 Authors: Ethiopic Script Generation Panel Contents 1 General Information/ Overview/ Abstract ........................................................................................ 3 2 Script for which the LGR is proposed ................................................................................................ 3 3 Background on Script and Principal Languages Using It .................................................................... 4 3.1 Local Languages Using the Script .............................................................................................. 4 3.2 Geographic Territories of the Language or the Language Map of Ethiopia ................................ 7 4 Overall Development Process and Methodology .............................................................................. 8 4.1 Sources Consulted to Determine the Repertoire....................................................................... 8 4.2 Team Composition and Diversity .............................................................................................. 9 4.3 Analysis of Code Point Repertoire .......................................................................................... 10 4.4 Analysis of Code Point Variants .............................................................................................. 11 5 Repertoire .................................................................................................................................... -

Hong Kong Supplementary Character Set – 2016 (Draft)
中 文 界 面 諮 詢 委 員 會 工 作 小 組 文 件 編 號 2017/02 (B) Hong Kong Supplementary Character Set – 2016 (Draft) Office of the Government Chief Information Officer & Official Languages Division, Civil Service Bureau The Government of the Hong Kong Special Administrative Region April 2017 1/21 中 文 界 面 諮 詢 委 員 會 工 作 小 組 文 件 編 號 2017/02 (B) Table of Contents Preface Section 1 Overview……………….……………………………………………. 1 - 1 Section 2 Coding Scheme of the HKSCS–2016….……………………………. 2 - 1 Section 3 HKSCS–2016 under the Architecture of the ISO/IEC 10646………. 3 - 1 Table 1: Code Table of the HKSCS–2016……………………………………….. i - 1 Table 2: Newly Included Characters in the HKSCS–2016...………………….…. ii - 1 Table 3: Compatibility Characters in the HKSCS–2016…......………………..…. iii - 1 2/21 中 文 界 面 諮 詢 委 員 會 工 作 小 組 文 件 編 號 2017/02 (B) Preface After the first release of the Hong Kong Supplementary Character Set (HKSCS) in 1999, there have been three updated versions. The HKSCS-2001, HKSCS-2004 and HKSCS-2008 were published with 116, 123 and 68 new characters added respectively. A total of 5 009 characters were included in the HKSCS-2008. These publications formed the foundation for promoting the adoption of the ISO/IEC 10646 international coding standard, and were widely supported and adopted by the IT sector and members of the public. The ISO/IEC 10646 international coding standard is developed by the International Organization for Standardization (ISO) to provide a common technical basis for the storage and exchange of electronic information. -

Digital Editions of Premodern Chinese Texts: Methods and Problems – Exemplified Using the Daozang Jiyao1道藏輯要
Chung-Hwa Buddhist Journal (2012, 25:167-194) Taipei: Chung-Hwa Institute of Buddhist Studies 中華佛學學報第二十五期 頁 167-194 (民國一百零一年),臺北:中華佛學研究所 ISSN:1017-7132 Digital Editions of Premodern Chinese Texts: Methods and Problems – Exemplified Using the Daozang Jiyao1道藏輯要 Christian Wittern Kyoto University Abstract Digital editions do have a great potential for new avenues of research, but they also pose vexing research questions that have to be resolved adequately in order to make the resulting edition useful in the long run. One of the many differences between printed editions of texts and digital editions is the open-endedness of the latter, which means that it can be done incrementally and updated without incurring substantial expenses. The medium of digital editions requires the creator to make many assumptions about the texts explicit and record them in a way that can be processed automatically. This is a new concept, which seems foreign to the agenda of a scholar whose ultimate aim is to engage with the text. This article demonstrates that what seems like a detour is actually advancing the understanding of the text and the need objectify a text in this gives access to new dimensions of a text. It then goes on to provide details of a conceptual model for describing a premodern text digitally that has been developed working on a digital edition of the early Qing Daoist collection Daozang jiyao. Keywords: Text Encoding, Digital Editions, Character Encoding, XML, Doaist Studies 1 I would like to thank the anonymous reviewers for this journal for their very helpful suggestions for clarifications and general improvement of the article. -
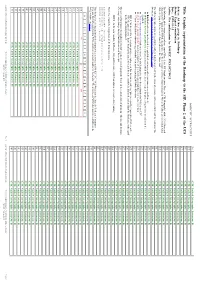
Netscape: Roadmap to Plane 2 (SIP) of ISO/IEC 10646 and Unicode
14 (CJK Unified Ideographs Extension B) ISO/IEC JTC1/SC2/WG2 N2115 15 (CJK Unified Ideographs Extension B) Title: Graphic representation of the Roadmap to the SIP, Plane 2 of the UCS 16 (CJK Unified Ideographs Extension B) 17 (CJK Unified Ideographs Extension B) Source: Ad hoc group on Roadmap 18 (CJK Unified Ideographs Extension B) Status: Expert contribution 19 (CJK Unified Ideographs Extension B) Date: 1999-09-15 Action: For confirmation by ISO/IEC JTC1/SC2/WG2 1A (CJK Unified Ideographs Extension B) 1B (CJK Unified Ideographs Extension B) The following tables comprise a real-size map of Plane 2, the SIP (Supplementary Plane for CJK Ideographs) of the UCS (Universal 1C (CJK Unified Ideographs Extension B) Character Set). To print the HTML document it may be necessary to set the print percentage to 90% as the tables are wider than A4 or US Letter paper. The tables are formatted to use the Times font. 1D (CJK Unified Ideographs Extension B) 1E (CJK Unified Ideographs Extension B) The following conventions are used in the table to help the user identify the status of (colours can be seen in the online version of this document, http://www.dkuug.dk/jtc1/sc2/wg2/docs/n2115.pdf): 1F (CJK Unified Ideographs Extension B) 20 (CJK Unified Ideographs Extension B) Bold text indicates an allocated (i.e. published) character collection (none as yet in Plane 2). (Bold text between parentheses) indicates scripts which have been accepted for processing toward inclusion in the 21 (CJK Unified Ideographs Extension B) standard. 22 (CJK Unified Ideographs Extension B) (Text between parentheses) indicates scripts for which proposals have been submitted to WG2 or the UTC. -

IRG N2153 IRG Principles and Procedures 2016-10-20 Version 8Confirmed Page 1 of 40 2.3.3
INTERNATIONAL ORGANIZATION FOR STANDARDIZATION ORGANISATION INTERNATIONALE DE NORMALISATION ISO/IEC JTC 1/SC 2/WG 2/IRG Universal Coded Character Set (UCS) ISO/IEC JTC 1/SC 2/WG 2/IRGN2153 SC2N5405 (Revision of IRG N1503/N1772/N1823/N1920/N1942/N1975/N2016/N2092) 2016-10-20 Title: IRG Principles and Procedures(IRG PnP) Version 9 Source: IRG Rapporteur Action: For review by the IRG and WG2 Distribution: IRG Member Bodies and Ideographic Experts Editor in chief: Lu Qin, IRG Rapporteur References: IRG Meeting No. 45 Recommendations(IRGN2150), IRG Special Meeting No. 44 discussions and recommendation No. 44.6(IRGN2080), IRGN2016, and IRGN 1975 and IRG Meeting No. 42 discussions IRGN 1952 and feedback from HKSARG, Japan, ROK and TCA, IRG 1920 Draft(2012-11-15), Draft 2(2013-05-04) and Draft 3(2013-05-22); feedback from Japan(2013-04-23) and ROK(2013-05-16 and 2013-05-21); and IRG Meeting No. 40 discussions IRG 1823 Draft 3 and feedback from HKSAR, Korea and IRG Meeting No. 39 discussions IRGN1823 Draft2 feedback from HKSAR and Japan IRG N1823Draft_gimgs2_Feedback IRG N1781 and N1782 Feedback from KIM Kyongsok IRGN1772 (P&P Version 5) IRG N1646 (P&P Version 4 draft) IRG N1602 (P&P Draft 4) and IRG N1633 (P&P Editorial Report) IRG N1601 (P&P Draft 3 Feedback from HKSAR) IRG N1590 and IRGN 1601(P&P V2 and V3 draft and all feedback) IRG N1562 (P&P V3 Draft 1 and Feedback from HKSAR) IRG N1561 (P&P V2 and all feedback) IRG N1559 (P&P V2 Draft and all feedback) IRG N1516 (P&P V1 Feedback from HKSAR) IRG N1489 (P&P V1 Feedback from Taichi Kawabata) IRG N1487 (P&P V1 Feedback from HKSAR) IRG N1465, IRG N1498 and IRG N1503 (P&P V1 drafts) Table of Contents 1. -

Microej Documentation
MicroEJ Documentation MicroEJ Corp. Revision 155af8f7 Jul 08, 2021 Copyright 2008-2020, MicroEJ Corp. Content in this space is free for read and redistribute. Except if otherwise stated, modification is subject to MicroEJ Corp prior approval. MicroEJ is a trademark of MicroEJ Corp. All other trademarks and copyrights are the property of their respective owners. CONTENTS 1 MicroEJ Glossary 2 2 Overview 4 2.1 MicroEJ Editions.............................................4 2.1.1 Introduction..........................................4 2.1.2 Determine the MicroEJ Studio/SDK Version..........................5 2.2 Licenses.................................................7 2.2.1 License Manager Overview...................................7 2.2.2 Evaluation Licenses......................................7 2.2.3 Production Licenses...................................... 10 2.3 MicroEJ Runtime............................................. 15 2.3.1 Language............................................ 15 2.3.2 Scheduler............................................ 15 2.3.3 Garbage Collector....................................... 15 2.3.4 Foundation Libraries...................................... 15 2.4 MicroEJ Libraries............................................ 16 2.5 MicroEJ Central Repository....................................... 16 2.5.1 Introduction.......................................... 16 2.5.2 Use............................................... 17 2.5.3 Content Organization..................................... 17 2.5.4 Javadoc............................................ -

Universal Multiple-Octet Coded Character Set (UCS) —
ISO/IEC JTC1 SC2/WG2 N2845 all Final Proposed Draft Amendment (FPDAM) 1 ISO/IEC 10646:2003/Amd.1:2004 (E) Information technology — Universal Multiple-Octet Coded Character Set (UCS) — AMENDMENT 1: Glagolitic, Coptic, Georgian and other characters In the definition of Graphic character (formerly sub- Page 1, Clause 1 Scope clause 4.20, now 4.22), insert “or a format character” In the note, update the Unicode Standard version after “control function”. from 4.0 to 4.1. Page 2, Clause 3 Normative references Page 14, Clause 19 Characters in bidirectional context Update the reference to the Unicode Bidirectional Algorithm and the Unicode Normalization Forms as Add ‘Mirrored’ before ‘Character’ in clause title and follows: replace the text of the clause by the following: Unicode Standard Annex, UAX#9, The Unicode Bidi- A class of character has special significance in the rectional Algorithm, Version 4.1.0, [date TBD]. context of bidirectional text. The interpretation and rendering of any of these characters depend on the Unicode Standard Annex, UAX#15, Unicode Nor- state related to the symmetric swapping characters malization Forms, Version 4.1.0, [date TBD]. (see clause F.2.2) and on the direction of the char- acter being rendered that are in effect at the point in the CC-data-element where the coded representa- Page 2, Clause Terms and definitions tion of the character appears. The list of these char- Insert the following text as sub-clause 4.1 and Note; acters is provided in Annex E.1. update all following sub-clause numbers accord- NOTE – That list also represents all characters which have ingly. -

The Effect of Pinyin in Chinese Vocabulary Acquisition with English-Chinese Bilingual Learners
St. Cloud State University theRepository at St. Cloud State Culminating Projects in TESL Department of English 12-2019 The Effect of Pinyin in Chinese Vocabulary Acquisition with English-Chinese Bilingual Learners Yahui Shi Follow this and additional works at: https://repository.stcloudstate.edu/tesl_etds Recommended Citation Shi, Yahui, "The Effect of Pinyin in Chinese Vocabulary Acquisition with English-Chinese Bilingual Learners" (2019). Culminating Projects in TESL. 17. https://repository.stcloudstate.edu/tesl_etds/17 This Thesis is brought to you for free and open access by the Department of English at theRepository at St. Cloud State. It has been accepted for inclusion in Culminating Projects in TESL by an authorized administrator of theRepository at St. Cloud State. For more information, please contact [email protected]. The Effect of Pinyin in Chinese Vocabulary Acquisition with English-Chinese Bilingual learners by Yahui Shi A Thesis Submitted to the Graduate Faculty of St. Cloud State University in Partial Fulfillment of the Requirements for the Degree Master of Arts in English: Teaching English as a Second Language December, 2019 Thesis Committee: Choonkyong Kim, Chairperson John Madden Zengjun Peng 2 Abstract This study investigates Chinese vocabulary acquisition of Chinese language learners in English-Chinese bilingual contexts; the 20 participants in this study were English native speakers, who were enrolled in a Chinese immersion program in central Minnesota. The study used a matching test, and the test contains seven sets of test items. In each set, there were six Chinese vocabulary words and the English translations of three of them. The six words are listed in one column on the left, and the three translations were in another column on the right.