Bopomofo Extended Range: 31A0–31BF
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -
Unifoundry.Com GNU Unifont Glyphs
Unifoundry.com GNU Unifont Glyphs Home GNU Unifont Archive Unicode Utilities Unicode Tutorial Hangul Fonts Unifont 9.0 Chart Fontforge Poll Downloads GNU Unifont is part of the GNU Project. This page contains the latest release of GNU Unifont, with glyphs for every printable code point in the Unicode 9.0 Basic Multilingual Plane (BMP). The BMP occupies the first 65,536 code points of the Unicode space, denoted as U+0000..U+FFFF. There is also growing coverage of the Supplemental Multilingual Plane (SMP), in the range U+010000..U+01FFFF, and of Michael Everson's ConScript Unicode Registry (CSUR). These font files are licensed under the GNU General Public License, either Version 2 or (at your option) a later version, with the exception that embedding the font in a document does not in itself constitute a violation of the GNU GPL. The full terms of the license are in LICENSE.txt. The standard font build — with and without Michael Everson's ConScript Unicode Registry (CSUR) Private Use Area (PUA) glyphs. Download in your favorite format: TrueType: The Standard Unifont TTF Download: unifont-9.0.01.ttf (12 Mbytes) Glyphs above the Unicode Basic Multilingual Plane: unifont_upper-9.0.01.ttf (1 Mbyte) Unicode Basic Multilingual Plane with CSUR PUA Glyphs: unifont_csur-9.0.01.ttf (12 Mbytes) Glyphs above the Unicode Basic Multilingual Plane with CSUR PUA Glyphs: unifont_upper_csur-9.0.01.ttf (1 Mbyte) PCF: unifont-9.0.01.pcf.gz (1 Mbyte) BDF: unifont-9.0.01.bdf.gz (1 Mbyte) Specialized versions — built by request: SBIT: Special version at the request -

Outline of the Course
Outline of the course Introduction to Digital Libraries (15%) Description of Information (30%) Access to Information (()30%) User Services (10%) Additional topics (()15%) Buliding of a (small) digital library Reference material: – Ian Witten, David Bainbridge, David Nichols, How to build a Digital Library, Morgan Kaufmann, 2010, ISBN 978-0-12-374857-7 (Second edition) – The Web FUB 2012-2013 Vittore Casarosa – Digital Libraries Part 7 -1 Access to information Representation of characters within a computer Representation of documents within a computer – Text documents – Images – Audio – Video How to store efficiently large amounts of data – Compression How to retrieve efficiently the desired item(s) out of large amounts of data – Indexing – Query execution FUB 2012-2013 Vittore Casarosa – Digital Libraries Part 7 -2 Representation of characters The “natural” wayyp to represent ( (palphanumeric ) characters (and symbols) within a computer is to associate a character with a number,,g defining a “coding table” How many bits are needed to represent the Latin alphabet ? FUB 2012-2013 Vittore Casarosa – Digital Libraries Part 7 -3 The ASCII characters The 95 printable ASCII characters, numbdbered from 32 to 126 (dec ima l) 33 control characters FUB 2012-2013 Vittore Casarosa – Digital Libraries Part 7 -4 ASCII table (7 bits) FUB 2012-2013 Vittore Casarosa – Digital Libraries Part 7 -5 ASCII 7-bits character set FUB 2012-2013 Vittore Casarosa – Digital Libraries Part 7 -6 Representation standards ASCII (late fifties) – AiAmerican -

Iso/Iec 10646:2011 Fdis
ISO/IEC International Standard ISO/IEC 10646 Final Draft International Standard Information technology – Universal Coded Character Set (UCS) Technologie de l‘information – Jeu universel de caractères codés (JUC) Second edition, 2011 \fdis10646.docx ISO/IEC 10646:2011 (E) PDF disclaimer This PDF file may contain embedded typefaces. In accordance with Adobe's licensing policy, this file may be printed or viewed but shall not be edited unless the typefaces which are embedded are licensed to and installed on the computer performing the editing. In downloading this file, parties accept therein the responsibility of not infringing Adobe's licensing policy. The ISO Central Secretariat accepts no liability in this area. Adobe is a trademark of Adobe Systems Incorporated. Details of the software products used to create this PDF file can be found in the General Info relative to the file; the PDF- creation parameters were optimized for printing. Every care has been taken to ensure that the file is suitable for use by ISO member bodies. In the unlikely event that a problem relating to it is found, please inform the Central Secretariat at the address given below. © ISO/IEC 2011 All rights reserved. Unless otherwise specified, no part of this publication may be reproduced or utilized in any form or by any means, electronic or mechanical, including photocopying and microfilm, without permission in writing from either ISO at the ad- dress below or ISO's member body in the country of the requester. ISO copyright office Case postale 56 CH-1211 Geneva 20 Tel. + 41 22 749 01 11 Fax + 41 22 749 09 47 E-mail [email protected] Web www.iso.ch Printed in Switzerland 2 © ISO/IEC 2011 – All rights reserved ISO/IEC 10646:2011 (E) CONTENTS Foreword............................................................................................................................................... -

Fonts in Mpdf Version 5.X Mpdf Version 5 Supports Truetype Fonts, Reading and Embedding Directly from the .Ttf Font Files
mPDF Fonts in mPDF Version 5.x mPDF version 5 supports Truetype fonts, reading and embedding directly from the .ttf font files. Fonts must follow the Truetype specification and use Unicode mapping to the characters. Truetype collections (.ttc files) and Opentype files (.otf) in Truetype format are also supported. EASY TO ADD NEW FONTS 1. Upload the Truetype font file to the fonts directory (/ttfonts) 2. Define the font file details in the configuration file (config_fonts.php) 3. Access the font by specifying it in your HTML code as the CSS font-family These are some examples of Windows fonts: Arial - The quick, sly fox jumped over the lazy brown dog. Comic Sans MS - The quick, sly fox jumped over the lazy brown dog. Trebuchet - The quick, sly fox jumped over the lazy brown dog. Calibri - The quick, sly fox jumped over the lazy brown dog. QuillScript - The quick, sly fox jumped over the lazy brown dog. Lucidaconsole - The quick, sly fox jumped over the lazy brown dog. Tahoma - The quick, sly fox jumped over the lazy brown dog. AlbaSuper - The quick, sly fox jumped over the lazy brown dog. FULL UNICODE SUPPORT The DejaVu fonts distributed with mPDF contain an extensive set of characters, but it is easy to add fonts to access uncommon characters. Georgian (DejaVuSansCondensed) Ⴀ Ⴁ Ⴂ Ⴃ Ⴄ Ⴅ Ⴆ Ⴇ Ⴈ Ⴉ Ⴊ Ⴋ Ⴌ Ⴍ Ⴎ Ⴏ Ⴐ Ⴑ Ⴒ Ⴓ Cherokee (Quivira) Ꭰ Ꭱ Ꭲ Ꭳ Ꭴ Ꭵ Ꭶ Ꭷ Ꭸ Ꭹ Ꭺ Ꭻ Ꭼ Ꭽ Ꭾ Ꭿ Ꮀ Ꮁ Ꮂ Runic (Junicode) ᚠ ᚡ ᚢ ᚣ ᚤ ᚥ ᚦ ᚧ ᚨ ᚩ ᚪ ᚫ ᚬ ᚭ ᚮ ᚯ ᚰ ᚱ ᚲ ᚳ ᚴ ᚵ ᚶ ᚷ ᚸ ᚹ ᚺ ᚻ ᚼ Greek Extended (Quivira) ἀ ἁ ἂ ἃ ἄ ἅ ἆ ἇ Ἀ Ἁ Ἂ Ἃ Ἄ Ἅ Ἆ Ἇ ἐ ἑ ἒ ἓ ἔ ἕ IPA Extensions (Quivira) -

ISO/IEC International Standard 10646-1
JTC1/SC2/WG2 N3658 Proposed Draft Amendment (PDAM) 8 ISO/IEC 10646:2003/Amd.8:2009 (E) Information technology — Universal Multiple-Octet Coded Character Set (UCS) — AMENDMENT 8: Additional symbols, Bamum supplement, CJK Unified Ideographs Extension D, and other characters Page 2, Clause 3, Normative references Replace the list describing the fields of the linked con- tent (CJKU_SR.txt) and the following paragraph with Update the reference to the Unicode Bidirectional Algo- the following text: rithm and the Unicode Normalization Forms as follows: st • 1 field: BMP or SIP code point (0hhhh), Unicode Standard Annex, UAX#9, The Unicode Bidi- (2hhhh) rectional Algorithm: • 2nd field: Radical Stroke index http://www.unicode.org/reports/tr9/tr9-21.html. (d{1,3}’.d{1,2}), (Radical is one to three di- gits, optionally followed by an apostrophe for alter- Unicode Standard Annex, UAX#15, Unicode Normali- nate radical, followed by a full stop, and ending by zation Forms: one or two digits for the stroke count). http://www.unicode.org/reports/tr15/tr15-31.html. rd • 3 field: Hanzi G sources(G0-hhhh), (G1- hhhh), (G3-hhhh), (G5-hhhh), (G7- Editor’s Note: The versions for the Unicode Standard hhhh), (GS-hhhh), (G8-hhhh), (G9- Annexes mentioned above will be updated as appropri- hhhh), (GE-hhhh), (G_4K), (G_BK), ate in future phases of this amendment process. (G_BKddddd), (G_CH), (G_CY), (G_CYYddddd), (G_CHddddd), (G_FZ), Page 21, Sub-clause 23.1 Source references (G_FZddddd), (G_GHddddd), for CJK Unified Ideographs (G_GFHZBddd), (G_GJZddddd), (G_HC), -

Iso/Iec 30112 Wd12 Standard
INTERNATIONAL ISO/IEC 30112 WD12 STANDARD ISO/IEC 30112 WD12 2018-02-12 Information technology — Specification methods for cultural conventions Technologies de l'information — Méthodes de modélisation des conventions culturelles This page left for ISO/IEC copyright notices. ISO/IEC 30112 WD12 Contents Page CONTENTS iii FOREWORD iv INTRODUCTION v 1 SCOPE 1 2 NORMATIVE REFERENCES 1 3 TERMS, DEFINITIONS AND NOTATIONS 1 4 FDCC-set 7 4.1 FDCC-set description 8 4.2 LC_IDENTIFICATION 13 4.3 LC_CTYPE 15 4.4 LC_COLLATE 48 4.5 LC_MONETARY 62 4.6 LC_NUMERIC 67 4.7 LC_TIME 68 4.8 LC_MESSAGES 77 4.9 LC_XLITERATE 78 4.10 LC_NAME 80 4.11 LC_ADDRESS 82 4.12 LC_TELEPHONE 85 4.13 LC_PAPER 86 4.14 LC_MEASUREMENT 86 4.15 LC_KEYBOARD 87 5 CHARMAP 87 6 REPERTOIREMAP 93 7 FUNCTIONALITY 127 8 MESSAGE FORMAT 127 Annex A (informative) DIFFERENCES FROM POSIX 127 Annex B (informative) RATIONALE 129 Annex C (informative) BNF GRAMMAR 145 Annex D (informative) RELATION TO TAXONOMY 151 Annex E (informative) IMPLEMENTATION IN GLIBC 154 Annex F (informative) INDEX 155 BIBLIOGRAPHY 158 2 © ISO/IEC 2018 – All rights reserved ISO/IEC 30112 WD12 Foreword ISO (the International Organization for Standardization) and IEC (the International Electrotechnical Commission) form the specialized system for worldwide standardization. National bodies that are members of ISO or IEC participate in the development of International Standards through technical committees established by the respective organization to deal with particular fields of technical activity. ISO and IEC technical committees collaborate in fields of mutual interest. Other international organizations, governmental and non-governmental, in liaison with ISO and IEC, also take part in the work. -

Chinese Taalverwerking Op De Computer
FACULTEIT LETTEREN DEPARTEMENT OOSTERSE EN SLAVISCHE STUDIES KATHOLIEKE UNIVERSITEIT LEUVEN CHINESE TAALVERWERKING OP DE COMPUTER Deel I : Theoretisch Overzicht Promotor : Prof. Dr. Fred Truyen Verhandeling aangeboden tot het verkrijgen van de graad van licentiaat in de Sinologie door: Sébastien Bruggeman - 2001-2002 - VOORWOORD Dit theoretische overzicht handelt over de Chinese taalverwerking op de computer. Het heeft de bedoeling om zo volledig mogelijk te zijn, maar zal het helaas nooit kunnen zijn door de uitgebreidheid van dit onderwerp. Hoewel dit deel veel technische details bevat is er geen voorkennis vereist. Naast dit theoretisch overzicht is er ook nog een praktische handleiding voor mensen die Chinees in de praktijk op hun computer willen gebruiken. Ook voor dit deel is geen voorkennis vereist, wel wordt er gerekend op een basiskennis van Microsoft Windows. Het voorhanden hebben van een computer met internetverbinding maakt het mogelijk om alles onmiddellijk in de praktijk om te zetten. Het derde luik van deze verhandeling is een website. Op deze website kunnen extra documentatie, voorbeelden en links gevonden worden. Daarnaast kan men ook terecht op het forum voor extra vragen en antwoorden. Tot slot wens ik U nog veel leesplezier en hoop ik dat U door deze licentiaatsverhandeling een betere kijk krijgt op de Chinese taalverwerking op de computer. Sébastien Bruggeman Thesis Sébastien Bruggeman Pagina 2 Thesis Sébastien Bruggeman Pagina 3 INHOUDSTAFEL 0. Gebruikte conventies......................................................................................................11 -

Proposal to Encode Cantonese Bopomofo Characters 1
Proposal to encode Cantonese Bopomofo Characters Ben Yang Eiso Chan (陈永聪) Director of Technology PanLex — The Long Now Foundation [email protected] May 02, 02019 (last revised) 1. Introduction This proposal is a followup to L2/19-100 Preliminary proposal to encode four extended Bopomofo letters for Cantonese in BMP by Eiso Chan (陈永聪). Cantonese (�東�, �东话, Gwong2 Dung1 Waa2) is a variety of Chinese spoken by approximately 80 million native speakers. Between the 01930s and 01950s, Bopomofo (or Zhuyin Fuhao) was adapted to transcribe Cantonese by adding 4 additional characters, currently unencoded in Unicode. These additional characters are proposed below. 2. Request This proposal requests the addition of 4 new characters in the Bopomofo Extended block with the following names and code points: U+31BC BOPOMOFO LETTER GW U+31BD BOPOMOFO LETTER KW U+31BE BOPOMOFO LETTER OE U+31BF BOPOMOFO LETTER AH Additionally, this proposal requests the following changes to the Unicode Core Spec, section 18.3 Bopomofo (under Extended Bopomofo): Replace the following line from the first paragraph: There are no standard Bopomofo letters for the phonetics of Cantonese or several other Southern Chinese dialects. with the following: The use of Bopomofo letters for the phonetics of Cantonese and several other Southern Chinese dialects was never fully standardized. However, there have been several attempts, some of which have been represented in published documents. 1 of 14 Add the following to the end of the first paragraph: The four characters encoded at U+31BC..U+31BF were designed to cover additional sounds found in Cantonese. Add the following subsection after the second paragraph: In Cantonese, final consonants not covered by the set of standard Bopomofo with final “N” and “NG” are marked with a standard-sized character (ㄆ, ㄇ, ㄊ, ㄋ, ㄎ, ㄫ). -
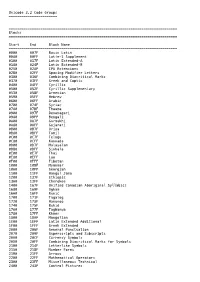
Unicode Groups
Unicode 3.2 Code Groups ======================= ================================================================================ Blocks ================================================================================ Start End Block Name -------------------------------------------------------------------------------- 0000 007F Basic Latin 0080 00FF Latin-1 Supplement 0100 017F Latin Extended-A 0180 024F Latin Extended-B 0250 02AF IPA Extensions 02B0 02FF Spacing Modifier Letters 0300 036F Combining Diacritical Marks 0370 03FF Greek and Coptic 0400 04FF Cyrillic 0500 052F Cyrillic Supplementary 0530 058F Armenian 0590 05FF Hebrew 0600 06FF Arabic 0700 074F Syriac 0780 07BF Thaana 0900 097F Devanagari 0980 09FF Bengali 0A00 0A7F Gurmukhi 0A80 0AFF Gujarati 0B00 0B7F Oriya 0B80 0BFF Tamil 0C00 0C7F Telugu 0C80 0CFF Kannada 0D00 0D7F Malayalam 0D80 0DFF Sinhala 0E00 0E7F Thai 0E80 0EFF Lao 0F00 0FFF Tibetan 1000 109F Myanmar 10A0 10FF Georgian 1100 11FF Hangul Jamo 1200 137F Ethiopic 13A0 13FF Cherokee 1400 167F Unified Canadian Aboriginal Syllabics 1680 169F Ogham 16A0 16FF Runic 1700 171F Tagalog 1720 173F Hanunoo 1740 175F Buhid 1760 177F Tagbanwa 1780 17FF Khmer 1800 18AF Mongolian 1E00 1EFF Latin Extended Additional 1F00 1FFF Greek Extended 2000 206F General Punctuation 2070 209F Superscripts and Subscripts 20A0 20CF Currency Symbols 20D0 20FF Combining Diacritical Marks for Symbols 2100 214F Letterlike Symbols 2150 218F Number Forms 2190 21FF Arrows 2200 22FF Mathematical Operators 2300 23FF Miscellaneous Technical 2400 243F Control -

Greek Abcdefghijklmno
Autoclick - typing UNICODE - http://pcl.to/unicode © RedTitan™ Technology 2005 ÊËÌÍÎÏ&'Ï(ËÎ)ÎÏ*Ë+,-./01Ï234567Ï89:0Ï;<Ï=4Ï>04?;+Í&Ïê To view this document as UNICODE.TXT you need Notepad conf igured for font Arial on Windows XP Most Windows XP text utilities support Unicode using UTF - see http://pcl.to/unicode/utf .xml Many Windows XP fonts have more than 255 character glyphs defined. For example, the font Arial has 1419 glyphs defined which covers many foreign languages and a lot of technical symbols. Check your favourite font on http://pcl.to/pclt/ The question remains - How do you insert UTF encoded UNICODE into a docum ent like this text file? You can buy specialist editors and a new keyboard but if you just want to insert a small amount of ÊËÌÍÎËÏ Arabic text there has got to be an easier way! The AUTOCLICK utility from RedTitan provides an answer. Just click on the character and you too can - ABCÏDEFGHIJCÏKFLBMNÏ (type in Greek) Unicode code plane 0x03: JDOPBCQHGMIKRCLSTENUVWXYZ[Ï- Greek Unicode code plane 0x04: \]^_`abcdefghijklmnopqrstuvwxyz{Ï- Russian Unicode code plane 0x05: &'()*+ - Hebrew Unicode code plane 0x06: ÊËÌÍÎËÏ -Arabic Print this document with a PCL driver and use RedTitan EscapeE to convert to PDF. Note: AutoClick supports characters in the rang e 0x0000 to 0xFFFF. i.e. two byte. Version 3 UNICODE defines 3 bytes and moves some of the original glyph ranges (e.g Chinese). The full list looks like this Unicode version 3.0 - range start codes. 0000 Basic Latin 0080 Latin-1 Supplem ent 0100 Latin Extended-A 0180 Latin -

Arne Götje CJK Unifonts Project Outlook
CJK-Unifonts Project Outlook – June/July 2007 Arne Götje 高盛華 [email protected] http://www.freedesktop.org/wiki/Software/CJKUnifonts CJK-Unifonts Project ● Started in 2003 ● Aims to provide a free set of Pan-CJK Unicode fonts ● 4 font styles: – Ming ( 明體 )/Song ( 宋體 ) : Print style – Kai ( 楷體 ) : Brush stroke style – Hei ( 黑體 ) : Sans-serif style – Yuan ( 圓體 ) : Round, Gothic style Current Status ● 2 fonts: – AR PL ShanHeiSun Uni (Ming/Song style) – AR PL ZenKai Uni (Kai style) ● License: Arphic Public License (APL) ● Each fonts comes in 2 flavors: – Uni – MBE (Modern Bopomofo Extensions) Flavor Differences ● The Bopomofo Extended characters (U+31A0 ~ U+31B7) – Pronunciation alphabet used for Minnan and Hakka languages in Taiwan. – Characters are in CNS 11643 standard – Uni flavor: the glyph shapes are according to the Unicode and CNS 11643 publications – MBE flavor: the glyph shapes are according to dictionary and teaching material publications by Mr. Yang Qing-Chu ( 楊青矗 ) Uni vs. MBE Uni: 0123456789ABCDEF 31A ㆠㆡㆢㆣㆤㆥㆦㆧㆨㆩㆪㆫㆬㆭㆮㆯ 31B ㆰㆱㆲㆳㆴㆵㆶㆷ MBE: 0123456789ABCDEF 31A ㆠㆡㆢㆣㆤㆥㆦㆧㆨㆩㆪㆫㆬㆭㆮㆯ 31B ㆰㆱㆲㆳㆴㆵㆶㆷ Challenges ● Some glyphs have a different writing style in different CJK Regions ● Example: U+9AA8 (bone) Hong Kong China Taiwan Japan Korea Solution ● TrueType Collections (TTC) – one TTC file with multiple “virtual” fonts: ● original and original Mono: the glyphs look like in the original Arphic fonts ● CN and CN Mono: simplified style (China, Singapore) ● HK and HK Mono: traditional style (Hong Kong, Macao) ● JP and JP Mono: JISX0213:2004 style (Japan) ● KR and KR Mono: Korea style ● TW, TW MBE, TW Mono and TW MBE Mono: traditional style (Taiw an) Caveats ● TTC only works with Pango/GTK2 and QT4 (>=4.3.0) ● KDE4 (scheduled for late October 2007) will also be able to use TTC fonts.