Universal Multiple-Octet Coded Character Set (UCS) —
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Staff Budget Briefing Fy 2021-22
STAFF BUDGET BRIEFING FY 2021-22 DEPARTMENT OF HIGHER EDUCATION JBC WORKING DOCUMENT - SUBJECT TO CHANGE STAFF RECOMMENDATION DOES NOT REPRESENT COMMITTEE DECISION PREPARED BY: AMANDA BICKEL, JBC STAFF DECEMBER 14, 2020 JOINT BUDGET COMMITTEE STAFF 200 E. 14TH AVENUE, 3RD FLOOR · DENVER · COLORADO · 80203 TELEPHONE: (303) 866-2061 · TDD: (303) 866-3472 https://leg.colorado.gov/agencies/joint-budget-committee CONTENTS Department Overview........................................................................................................................................................ 1 Department Budget: Recent Appropriations.................................................................................................................. 3 Department Budget: Graphic Overview ......................................................................................................................... 4 General Factors Driving the Budget................................................................................................................................ 6 Summary: FY 2020-21 Appropriation & FY 2021-22 Request ................................................................................23 Budget Requests impacting FY 2020-21 – COVID-19 Stimulus Package ..............................................................28 Informational Issue: 2020 Session Budget Balancing Actions .................................................................................30 Informational Issue: Public Higher Education Finance -- Budget Balancing -

+1. Introduction 2. Cyrillic Letter Rumanian Yn
MAIN.HTM 10/13/2006 06:42 PM +1. INTRODUCTION These are comments to "Additional Cyrillic Characters In Unicode: A Preliminary Proposal". I'm examining each section of that document, as well as adding some extra notes (marked "+" in titles). Below I use standard Russian Cyrillic characters; please be sure that you have appropriate fonts installed. If everything is OK, the following two lines must look similarly (encoding CP-1251): (sample Cyrillic letters) АабВЕеЗКкМНОопРрСсТуХхЧЬ (Latin letters and digits) Aa6BEe3KkMHOonPpCcTyXx4b 2. CYRILLIC LETTER RUMANIAN YN In the late Cyrillic semi-uncial Rumanian/Moldavian editions, the shape of YN was very similar to inverted PSI, see the following sample from the Ноул Тестамент (New Testament) of 1818, Neamt/Нямец, folio 542 v.: file:///Users/everson/Documents/Eudora%20Folder/Attachments%20Folder/Addons/MAIN.HTM Page 1 of 28 MAIN.HTM 10/13/2006 06:42 PM Here you can see YN and PSI in both upper- and lowercase forms. Note that the upper part of YN is not a sharp arrowhead, but something horizontally cut even with kind of serif (in the uppercase form). Thus, the shape of the letter in modern-style fonts (like Times or Arial) may look somewhat similar to Cyrillic "Л"/"л" with the central vertical stem looking like in lowercase "ф" drawn from the middle of upper horizontal line downwards, with regular serif at the bottom (horizontal, not slanted): Compare also with the proposed shape of PSI (Section 36). 3. CYRILLIC LETTER IOTIFIED A file:///Users/everson/Documents/Eudora%20Folder/Attachments%20Folder/Addons/MAIN.HTM Page 2 of 28 MAIN.HTM 10/13/2006 06:42 PM I support the idea that "IA" must be separated from "Я". -
Dyalog APL Binding Strengths
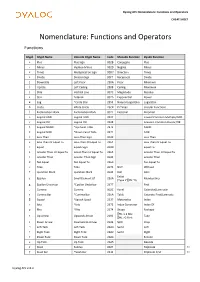
Dyalog APL Nomenclature: Functions and Operators CHEAT SHEET Nomenclature: Functions and Operators Functions Glyph Glyph Name Unicode Glyph Name Code Monadic Function Dyadic Function + Plus Plus Sign 002B Conjugate Plus - Minus Hyphen-Minus 002D Negate Minus × Times Multiplication Sign 00D7 Direction Times ÷ Divide Division Sign 00F7 Reciprocal Divide ⌊ Downstile Left Floor 230A Floor Minimum ⌈ Upstile Left Ceiling 2308 Ceiling Maximum | Stile Vertical Line 007C Magnitude Residue * Star Asterisk 002A Exponential Power ⍟ Log *Circle Star 235F Natural Logarithm Logarithm ○ Circle White Circle 25CB Pi Times Circular Functions ! Exclamation Mark Exclamation Mark 0021 Factorial Binomial ∧ Logical AND Logical AND 2227 Lowest Common Multiple/AND ∨ Logical OR Logical OR 2228 Greatest Common Divisor/OR ⍲ Logical NAND *Up Caret Tilde 2372 NAND ⍱ Logical NOR *Down Caret Tilde 2371 NOR < Less Than Less-Than Sign 003C Less Than ≤ Less Than Or Equal To Less-Than Or Equal To 2264 Less Than Or Equal To = Equal Equals Sign 003D Equal To ≥ Greater Than Or Equal To Great-Than Or Equal To 2265 Greater Than Or Equal To > Greater Than Greater-Than Sign 003E Greater Than ≠ Not Equal Not Equal To 2260 Not Equal To ~ Tilde Tilde 007E NOT Without ? Question Mark Question Mark 003F Roll Deal Enlist ∊ Epsilon Small Element Of 220A Membership (Type if ⎕ML=0) ⍷ Epsilon Underbar *Epsilon Underbar 2377 Find , Comma Comma 002C Ravel Catenate/Laminate ⍪ Comma Bar *Comma Bar 236A Table Catenate First/Laminate ⌷ Squad *Squish Quad 2337 Materialise Index ⍳ Iota *Iota 2373 -

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

A Capacity Survey of California's Cultural Heritage Organizations
A Capacity Survey of California’s Cultural Heritage Organizations and Recommendations for Financing by Mimi Morris Executive Officer California Cultural and Historical Endowment November 2012 www.endowment.library.ca.gov www.californiastreasures.org (916) 653-1330 A Capacity Survey of California’s Cultural Heritage Organizations and Financing Recommendations TABLE OF CONTENTS Introduction ........................................................................................................................... 3 Executive Summary .............................................................................................................. 5 Acknowledgements .............................................................................................................. 7 The Capacity of Cultural Heritage Organizations in California ........................................ 9 Methodology for the Survey of California’s Cultural Organizations .............................. 11 Survey Transmittal Letter ........................................................................................... 13 Survey Introduction .................................................................................................... 15 Survey Questions ....................................................................................................... 17 Survey Results ........................................................................................................... 19 Table 1: Response Totals for Structural Integrity Improvement Funding Needs .. 20 -

Old Cyrillic in Unicode*
Old Cyrillic in Unicode* Ivan A Derzhanski Institute for Mathematics and Computer Science, Bulgarian Academy of Sciences [email protected] The current version of the Unicode Standard acknowledges the existence of a pre- modern version of the Cyrillic script, but its support thereof is limited to assigning code points to several obsolete letters. Meanwhile mediæval Cyrillic manuscripts and some early printed books feature a plethora of letter shapes, ligatures, diacritic and punctuation marks that want proper representation. (In addition, contemporary editions of mediæval texts employ a variety of annotation signs.) As generally with scripts that predate printing, an obvious problem is the abundance of functional, chronological, regional and decorative variant shapes, the precise details of whose distribution are often unknown. The present contents of the block will need to be interpreted with Old Cyrillic in mind, and decisions to be made as to which remaining characters should be implemented via Unicode’s mechanism of variation selection, as ligatures in the typeface, or as code points in the Private space or the standard Cyrillic block. I discuss the initial stage of this work. The Unicode Standard (Unicode 4.0.1) makes a controversial statement: The historical form of the Cyrillic alphabet is treated as a font style variation of modern Cyrillic because the historical forms are relatively close to the modern appearance, and because some of them are still in modern use in languages other than Russian (for example, U+0406 “I” CYRILLIC CAPITAL LETTER I is used in modern Ukrainian and Byelorussian). Some of the letters in this range were used in modern typefaces in Russian and Bulgarian. -

COSC345 Week 24 Internationalisation And
COSC345 Week 24 Internationalisation and Localisation 29 September 2015 Richard A. O'Keefe 1 From a Swedish h^otelroom Hj¨alposs att v¨arnerom v˚armilj¨o! F¨oratt minska utsl¨appav tv¨attmedel, byter vi Er handduk bara n¨arNi vill: 1. Handduk p˚agolvet | betyder att Ni vill ha byte 2. ... 2 The translation Help us to care for our environment! To reduce the use of laundry detergents, we shall change your towel as follows: 1. Towel on the floor | you want to have a new towel. 2. Towel hung up | you want to use it again. 3 People should be able to use computers in their own language. | It's just right not to make people struggle with unfamiliar lin- guistic and cultural codes. | Sensible people won't pay for programs that are hard to use. | Internationalisation (I18N) means making a program so that it does not enforce a particular language or set of cultural conventions | Localisation (L10N) means adapting an internationalised pro- gram to a particular language etc. | UNIX, VMS, Windows, all support internationalisation and lo- calisation; the Macintosh operating system has done this better for longer. 4 Characters You know that there are 26 letters in 2 cases. But Swedish has ˚a,¨a,¨o, A,˚ A,¨ and O¨ (29 letters), Croatian has d j, D j, D J, and others (3 cases), German has ß, which has no single upper case version (might be SS, might be SZ, both of which are two letters), Latin-1 has 58 letters in 2 cases (including 2 lower case letters with no upper case version), Arabic letters have 4 contextual shapes (beginning, middle, or end of word, or isolated), which are not case variants (Greek has one such letter, and Hebrew has several; even English used to), and Chinese has tens of thousands of characters. -

5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721
Internet Engineering Task Force (IETF) P. Faltstrom, Ed. Request for Comments: 5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721 The Unicode Code Points and Internationalized Domain Names for Applications (IDNA) Abstract This document specifies rules for deciding whether a code point, considered in isolation or in context, is a candidate for inclusion in an Internationalized Domain Name (IDN). It is part of the specification of Internationalizing Domain Names in Applications 2008 (IDNA2008). Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 5741. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at http://www.rfc-editor.org/info/rfc5892. Copyright Notice Copyright (c) 2010 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License. -

AIX Globalization
AIX Version 7.1 AIX globalization IBM Note Before using this information and the product it supports, read the information in “Notices” on page 233 . This edition applies to AIX Version 7.1 and to all subsequent releases and modifications until otherwise indicated in new editions. © Copyright International Business Machines Corporation 2010, 2018. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents About this document............................................................................................vii Highlighting.................................................................................................................................................vii Case-sensitivity in AIX................................................................................................................................vii ISO 9000.....................................................................................................................................................vii AIX globalization...................................................................................................1 What's new...................................................................................................................................................1 Separation of messages from programs..................................................................................................... 1 Conversion between code sets............................................................................................................. -

Proposal for Ethiopic Script Root Zone LGR
Proposal for Ethiopic Script Root Zone LGR LGR Version 2 Date: 2017-05-17 Document version:5.2 Authors: Ethiopic Script Generation Panel Contents 1 General Information/ Overview/ Abstract ........................................................................................ 3 2 Script for which the LGR is proposed ................................................................................................ 3 3 Background on Script and Principal Languages Using It .................................................................... 4 3.1 Local Languages Using the Script .............................................................................................. 4 3.2 Geographic Territories of the Language or the Language Map of Ethiopia ................................ 7 4 Overall Development Process and Methodology .............................................................................. 8 4.1 Sources Consulted to Determine the Repertoire....................................................................... 8 4.2 Team Composition and Diversity .............................................................................................. 9 4.3 Analysis of Code Point Repertoire .......................................................................................... 10 4.4 Analysis of Code Point Variants .............................................................................................. 11 5 Repertoire .................................................................................................................................... -

Microej Documentation
MicroEJ Documentation MicroEJ Corp. Revision 155af8f7 Jul 08, 2021 Copyright 2008-2020, MicroEJ Corp. Content in this space is free for read and redistribute. Except if otherwise stated, modification is subject to MicroEJ Corp prior approval. MicroEJ is a trademark of MicroEJ Corp. All other trademarks and copyrights are the property of their respective owners. CONTENTS 1 MicroEJ Glossary 2 2 Overview 4 2.1 MicroEJ Editions.............................................4 2.1.1 Introduction..........................................4 2.1.2 Determine the MicroEJ Studio/SDK Version..........................5 2.2 Licenses.................................................7 2.2.1 License Manager Overview...................................7 2.2.2 Evaluation Licenses......................................7 2.2.3 Production Licenses...................................... 10 2.3 MicroEJ Runtime............................................. 15 2.3.1 Language............................................ 15 2.3.2 Scheduler............................................ 15 2.3.3 Garbage Collector....................................... 15 2.3.4 Foundation Libraries...................................... 15 2.4 MicroEJ Libraries............................................ 16 2.5 MicroEJ Central Repository....................................... 16 2.5.1 Introduction.......................................... 16 2.5.2 Use............................................... 17 2.5.3 Content Organization..................................... 17 2.5.4 Javadoc............................................ -

1 Symbols (2286)
1 Symbols (2286) USV Symbol Macro(s) Description 0009 \textHT <control> 000A \textLF <control> 000D \textCR <control> 0022 ” \textquotedbl QUOTATION MARK 0023 # \texthash NUMBER SIGN \textnumbersign 0024 $ \textdollar DOLLAR SIGN 0025 % \textpercent PERCENT SIGN 0026 & \textampersand AMPERSAND 0027 ’ \textquotesingle APOSTROPHE 0028 ( \textparenleft LEFT PARENTHESIS 0029 ) \textparenright RIGHT PARENTHESIS 002A * \textasteriskcentered ASTERISK 002B + \textMVPlus PLUS SIGN 002C , \textMVComma COMMA 002D - \textMVMinus HYPHEN-MINUS 002E . \textMVPeriod FULL STOP 002F / \textMVDivision SOLIDUS 0030 0 \textMVZero DIGIT ZERO 0031 1 \textMVOne DIGIT ONE 0032 2 \textMVTwo DIGIT TWO 0033 3 \textMVThree DIGIT THREE 0034 4 \textMVFour DIGIT FOUR 0035 5 \textMVFive DIGIT FIVE 0036 6 \textMVSix DIGIT SIX 0037 7 \textMVSeven DIGIT SEVEN 0038 8 \textMVEight DIGIT EIGHT 0039 9 \textMVNine DIGIT NINE 003C < \textless LESS-THAN SIGN 003D = \textequals EQUALS SIGN 003E > \textgreater GREATER-THAN SIGN 0040 @ \textMVAt COMMERCIAL AT 005C \ \textbackslash REVERSE SOLIDUS 005E ^ \textasciicircum CIRCUMFLEX ACCENT 005F _ \textunderscore LOW LINE 0060 ‘ \textasciigrave GRAVE ACCENT 0067 g \textg LATIN SMALL LETTER G 007B { \textbraceleft LEFT CURLY BRACKET 007C | \textbar VERTICAL LINE 007D } \textbraceright RIGHT CURLY BRACKET 007E ~ \textasciitilde TILDE 00A0 \nobreakspace NO-BREAK SPACE 00A1 ¡ \textexclamdown INVERTED EXCLAMATION MARK 00A2 ¢ \textcent CENT SIGN 00A3 £ \textsterling POUND SIGN 00A4 ¤ \textcurrency CURRENCY SIGN 00A5 ¥ \textyen YEN SIGN 00A6