A Multi-Agent System Model to Integrate Virtual Learning Environments and Intelligent Tutoring Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Marketing the FUTURE IS ALREADY HERE the Program This Program, Fully Taught in English, Provides Managers with the Latest Trends in International
SPECIALIZED PROGRAM International marketing THE FUTURE IS ALREADY HERE The program This program, fully taught in English, provides managers with the latest trends in international equips them with extensive training in intercultural communication skills. The selection of international distribution channels is a marketing variable also deeply analyzed. In addition, global operations require constant adaptation of internet business tools which participants need to be familiar with. The complexities of internationalization of industrial goods also deserves special attention together with the peculiarities of doing business in Asia. Furhermore, they will test intercultural communication skills in our PURCHASING GAME© where students will negotiate with textile suppliers based in Morocco, Bangladesh, India, or Turkey. Suppliers will give them personal feedback and all the negotiations will be recorded and provided to participants for skills improvement. 100% of the programme is taught in English. Content briefing 15 h Intercultural communication 10 h Negotiation skills 10 h Purchasing game 10 h Distribution channels 10 h Digital marketing 5 h Industrial marketing 5 h Global forum 10 h Launch of new products 10 h Brand positioning Genius is one percent inspiration, ninety-nine percent perspiration Aimed at 1 2 International Managers Purchasing Managers 5 3 International Consultants Managing Directors of SMS firms 4 Marketing Managers ENTRY REQUIREMENTS Two-year professional experience and B2 level of English. Faculty Felipe Botayá García PhD in Business Administration Maastrich School of Management and IESME, MBA IESME, BSBA South Carolina, Marketing Management ESADE. He is profesor in UAB Bellaterra Campus, IESE, EADA, EAE, Abat Oliba-CEU, Humboldt Universität Berlín, Université Toulouse, Universidad de Anáhuac, México and ESAN Business School in Lima, Perú. -

Miriam-Sanchez-Moreiras.Pdf
MIRIAM SÁNCHEZ MOREIRAS Curriculum Vitae Department of Modern and Classical Languages Carroll Hall 211 Regis University 3333 Regis Blvd. Denver, CO 80221-1099 (303) 458-4175 [email protected] AREAS OF EMPHASIS Spanish and Latin American Contemporary Literature, Literary Theory, Creative Writing, Galician Studies, Poetry of Knowledge, Alain Badiou’s “Inaesthetics”, Poetics of New Speculative Realism, Spanish as a Second Language Teaching, Spanish as a Second Language Online Teaching. EDUCATION 2009 Ph.D., Spanish Literature. Department of Spanish and Portuguese Languages, University of Colorado Boulder, USA. Dissertation thesis: Contra la piedra y el pájaro. El conocimiento poético en Andrés Sánchez Robayna y Olvido García Valdés. 1996 M.A., Spanish Literature. Department of Spanish Philology, Theory of Literature and General Linguistics, University of Santiago de Compostela, Galicia, Spain. Master thesis: “El traje del fantasma” y “El jorobadito”. Dos menipeas de Roberto Arlt. 1993 B.A., Spanish Philology, University of Santiago de Compostela, Galicia, Spain. PROFESSIONAL TEACHING EXPERIENCE 2013-present Spanish Term-Instructor (2017-present). Spanish Affiliate (2013-2017). Modern and Classical Languages Department, Regis University, USA. Courses taught: “Elementary Spanish I” (SP 209A); “Elementary Spanish” II (SP 209B); “Intermediate Spanish I” (SP 309A); “Intermediate Spanish II” (SP 309B); “Spanish for Heritage Speakers (SP 408A); “Latin American Civilization” (SP 461); “Senior Project” (SP 496); “Independent Study” (SP 490; PT 490); short course on “Creative Writing”. 2016-present Spanish Lecturer. Modern Languages Department, University of Colorado Denver, USA. Courses taught: “Intermediate Spanish I” (SPAN 2110) online course and on-campus course. 2014 Instructor of Spanish. Department of Modern Languages, Metropolitan State University of Denver, USA. -

Business Institute
BUSINESS INSTITUTE 4 // IESIDE LEADING UNIVERSITY BUSINESS EDUCATION FOR MORE THAN 30 YEARS The Intercontinental Higher Education Business Institute (IESIDE) IESIDE is a private higher education institution, with a strong international orientation and specialized in the broad scope of business, with a diverse interdisciplinary quality offer and with more than 30 years of experience in the field. IESIDE is the strategic project of higher education of Afundación, the non-profit social and cultural institution of ABANCA. It is the first financial institution of Galicia, committed to social and economic development of the northwest of Spain and Portugal. In addition to IESIDE’s undergraduate and graduate higher education programs, it has in combination with Afundación, two community colleges and vocational education institutions. One in A Coruña, specialized in areas of administration and technology applied to management, and the other one in Vigo, specialized in the industrial, robotics and technological fields. Business Institute // 5 ABANCA shows its social commitment through its financial activity, contributing to the + 17,000 economic progress of the region. It provides 2 the finance and development of Afundación m of first-class facilities and IESIDE as part of its corporate social responsibility. ABANCA is also committed We offer decentralized presence to financial activities that boost social throughout Galicia improvement and sustainable growth, and does so in a transparent manner, in accordance with the 10 principles of the Global Compact, as well as with the development objectives + 60,000 approved by the United Nations. students At IESIDE, we look to educate students as have studied at our campuses leaders of the future and to contribute toward improving the competitiveness of national and international enterprises. -

EBL) Is a New Online Quarterly Peer-Reviewed International Journal Published by University of Oviedo Press
CALL FOR PAPERS Economics and Business Letters Dear Researcher: Economics and Business Letters (EBL) is a new online quarterly peer-reviewed international journal published by University of Oviedo Press . Both theoretical and empirical short papers in all the fields of Economics and Business are welcome. Original contributions will be pre-screened by the Editorial Board and subsequently reviewed by one referee in a double-blind system. An editorial decision will be taken within 12 weeks and major revision will not be considered (only accept/minor revision/reject). In order to achieve a rapid review process and publication of the articles, the length of the letters is limited to 2,500 words. The journal’s first issue is expected to be published in May 2012. We kindly encourage you to submit your work to EBL. In doing so, please use the online submission system at: http://www.unioviedo.es/reunido/index.php/EBL Please circulate this CFP among your colleagues. Best regards, Francisco J. Delgado & Eduardo González - Editors University of Oviedo – Spain [email protected] Features No publishing fees: no processing or publishing fees are charged to authors or institutions Open Access: free for readers to view and download, which increases citations Rapid publication: quick peer-review process and publication online Language: English Editorial Board Herman Aguinis, Indiana University - USA Maria José Luengo, Northeastern University Boston - USA Rubén Arrondo, University of Oviedo - Spain Thierry Madies, Fribourg University - Switzerland Bernardino -

Masters Erasmus Mundus Coordonnés Par Ou Associant Un EESR Français
Les Masters conjoints « Erasmus Mundus » Masters conjoints « Erasmus Mundus » coordonnés par un établissement français ou associant au moins un établissement français Liste complète des Masters conjoints Erasmus Mundus : http://eacea.ec.europa.eu/erasmus_mundus/results_compendia/selected_projects_action_1_master_courses_en.php *Master n’offrant pas de bourses Erasmus Mundus *ACES - Joint Masters Degree in Aquaculture, Environment and Society (cursus en 2 ans) UK-University of the Highlands and Islands LBG FR- Université de Nantes GR- University of Crete http://www.sams.ac.uk/erasmus-master-aquaculture ADVANCES - MA Advanced Development in Social Work (cursus en 2 ans) UK-UNIVERSITY OF LINCOLN, United Kingdom DE-AALBORG UNIVERSITET - AALBORG UNIVERSITY FR-UNIVERSITÉ PARIS OUEST NANTERRE LA DÉFENSE PO-UNIWERSYTET WARSZAWSKI PT-UNIVERSIDADE TECNICA DE LISBOA www.socialworkadvances.org AMASE - Joint European Master Programme in Advanced Materials Science and Engineering (cursus en 2 ans) DE – Saarland University ES – Polytechnic University of Catalonia FR – Institut National Polytechnique de Lorraine SE – Lulea University of Technology http://www.amase-master.net ASC - Advanced Spectroscopy in Chemistry Master's Course FR – Université des Sciences et Technologies de Lille – Lille 1 DE - University Leipzig IT - Alma Mater Studiorum - University of Bologna PL - Jagiellonian University FI - University of Helsinki http://www.master-asc.org Août 2016 Page 1 ATOSIM - Atomic Scale Modelling of Physical, Chemical and Bio-molecular Systems (cursus -

The Digital Divide Among University Freshmen
TOJET: The Turkish Online Journal of Educational Technology – April 2013, volume 12 Issue 2 THE DIGITAL DIVIDE AMONG UNIVERSITY FRESHMEN Associate Prof. Dr. Carmen Ricoy Corresponding Author: Faculty of Education, University of Vigo (Spain) Avd / Castelao, s / n 32004 Ourense, Spain. Email: [email protected] Associate Prof. Dr. Tiberio Feliz Faculty of Education, National University of Distance Education (Spain) [email protected] Prof. Maria João Couto Faculty of Education, University of Vigo (Spain) [email protected] ABSTRACT Use of new technologies in university training is an ongoing reality today. However, the inequalities that exist among university students are the source of an important problem. Such inequalities need to be detected and analyzed and therefore a study of college freshmen can be very valuable. This qualitative study intends to analyze the digital divide of such freshmen by using techno-autobiographies, i.e.; the students’ account of their situation. A total of 91 such students from the University of Vigo, Spain, participated in this research. Results obtained show the presence of asymmetries in the use of ICTs and indicate the presence of a digital divide. Such inequalities with respect to technology imply fewer ICT resources for some of these newcomers and difficulties to access the Internet. Worth highlighting is the fact that not all university freshmen use digital technology in a standardized manner for academic purposes but they nevertheless use such technology more frequently for private purposes. INTRODUCTION Within the Spanish university context, the teaching methodology needed to adapt to the European Higher Education Area (EHEA) requires the integration of Information and Communications Technologies (ICTs) into the training process. -

Reviewer Acknowledgements
Review of European Studies; Vol. 10, No. 4; 2018 ISSN 1918-7173 E-ISSN 1918-7181 Published by Canadian Center of Science and Education Reviewer Acknowledgements Review of European Studies wishes to acknowledge the following individuals for their assistance with peer review of manuscripts for this issue. Their help and contributions in maintaining the quality of the journal are greatly appreciated. Review of European Studies is recruiting reviewers for the journal. If you are interested in becoming a reviewer, we welcome you to join us. Please find the application form and details at http://recruitment.ccsenet.org and e-mail the completed application form to [email protected]. Reviewers for Volume 10, Number 4 Alejandra Moreno Alvarez, Universidad de Oviedo, Spain Alex Almici, Università degli Studi di Brescia, Italy Annalisa Pavan, University of Padova, ITALY Carmen Ramos, University of Oviedo, Spain Edwards, Beverly L, Fayetteville State University Department of Social Work, United States Efstathios Stefos, University of the Aegean, Greece Eleni Zervogianni, Aristotle University of Thessaloniki, Greece Eugenia Panitsides, University of Macedonia, Greece Florin Ionita, The Bucharest Academy of Economic Studies, Romania Frantisek Svoboda, Masaryk University, Czech republic Gabriela Gruber, Lucian Blaga University of Sibiu, Romania George Touche, Texas A&M University, USA Ghaiath M. A. Hussein, University of Birmingham, UK Hyung Min Kim, Myongji University, Republic of Korea Hyunsook Kang, Stephen F. Austin State University, United States -

Notes on Contributors
Notes on contributors Abril-Hernández, Ana is an independent Scholar, PhD Cum Laude in Comparative Literature from Universidad Complutense de Madrid (UCM), Master’s Degree in Literary Studies (UCM), Master’s Degree in Teacher Training for Compulsory Secondary Education, Upper Secondary Education, Vocational Training and Language Teaching (UCM), and Master’s Degree in Literary and Cultural Studies in Great Britain and Anglophone Countries: Literature, Culture, Communication and Translation (Universidad Autónoma de Madrid). Ana’s research follows a semiotic approach to literature and intermedial adaptations of it on different formats. Her publications in different books and journals revolve around the same fields with a special interest in comparative approaches to world literatures. Ahmetspahić, Adisa works as a teaching assistant at the Faculty of Philosophy Zenica, Bosnia and Herzegovina. She teaches Anglophone literature and history courses. She holds a BA degree in English Language and Literature and is currently a graduate student at the Faculty of Philosophy in Sarajevo. She is a member of American Studies Association in Bosnia and Herzegovina. Her research interests encompass identity problems and manifestation of minority groups in the modern era. Carrere, Anaïs since 2016 September a Ph. D student and assistant junior professor at the University Bordeaux-Montaigne at the English Department of the English Studies, member of the CLIMAS laboratory. Her doctoral dissertation focuses on “What language and gender studies might reveal about the conversational style of committed women in the public sphere: a historical and empirical perspective” under the supervision of Jean- Rémi LAPAIRE, a certified professor at the University of Bordeaux Montaigne in English linguistics, cognitive linguistics and gesture studies. -
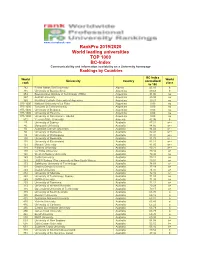
Rankpro 2019/2020 World Leading Universities TOP 1000 BC-Index Communicability and Information Availability on a University Homepage Rankings by Countries
www.cicerobook.com RankPro 2019/2020 World leading universities TOP 1000 BC-Index Communicability and information availability on a University homepage Rankings by Countries BC-Index World World University Country normalized rank class to 100 782 Ferhat Abbas Sétif University Algeria 45.16 b 715 University of Buenos Aires Argentina 49.68 b 953 Buenos Aires Institute of Technology (ITBA) Argentina 31.00 no 957 Austral University Argentina 29.38 no 969 Pontifical Catholic University of Argentina Argentina 20.21 no 975-1000 National University of La Plata Argentina 0.00 no 975-1000 Torcuato Di Tella University Argentina 0.00 no 975-1000 University of Belgrano Argentina 0.00 no 975-1000 University of Palermo Argentina 0.00 no 975-1000 University of San Andrés - UdeSA Argentina 0.00 no 812 Yerevan State University Armenia 42.96 b 27 University of Sydney Australia 87.31 a++ 46 Macquarie University Australia 84.66 a++ 56 Australian Catholic University Australia 84.02 a++ 80 University of Melbourne Australia 82.41 a++ 93 University of Wollongong Australia 81.97 a++ 100 University of Newcastle Australia 81.78 a++ 118 University of Queensland Australia 81.11 a++ 121 Monash University Australia 81.05 a++ 128 Flinders University Australia 80.21 a++ 140 La Trobe University Australia 79.42 a+ 140 Western Sydney University Australia 79.42 a+ 149 Curtin University Australia 79.11 a+ 149 UNSW Sydney (The University of New South Wales) Australia 79.01 a+ 173 Swinburne University of Technology Australia 78.03 a+ 191 Charles Darwin University Australia 77.19 -

Something Rotten in the State of Spain, Say Whistleblowers
NEWS Something rotten in the state of Spain, say whistleblowers will not come to court until summer MY by former Vigo dean Jesús Vázquez A Critics condemn culture of cronyism and 2014. AL Abad. corruption in the academy. Paul Jump reports In the meantime, he is entitled to In October, Astray’s name topped neither salary nor unemployment a list of Vigo students eligible for an As Spain struggles under the weight to have been subjected by the benefit, he says. “excellence award” for the best PhD of unsustainable borrowing costs University of Murcia after he went “This is how justice functions in thesis of 2011. After pressure from and an unemployment rate touch to court in 2007 to obtain a chair Spain,” he told THE. “Nobody but the international media and scien ing 25 per cent, its higher education in education that he says had been a judge can alter the decision of a tists, the university removed his sector has not escaped the turmoil. earmarked for a lessqualified rector, and my case will not be heard candidature on the eve of awarding Academic salaries have been cut academic who was a friend of until more than two years after the the prize. several times and the country’s Murcia’s rector, José Antonio events occurred.” The dean of Vigo’s Faculty of science budget has been slashed by Cobacho Gómez. The university did not respond Sciences, Pedro Antonio Araujo nearly 25 per cent. The government Penalva was sacked for alleged to a request for comment. Nespereira – a former PhD student has also set up a committee to absenteeism shortly after the book Stories also abound of alleged of Mejuto – told THE that the consider reforming Spain’s univer was published. -

SPAIN? and Most Inclusive Ranking Showcasing the Diversity in 5 WHAT ARE the PERFORMANCE Higher Education Around the PROFILES of SPAIN’S World
U-MULTIRANK 2019 Spanish Universities in Global Comparison WWW.UMULTIRANK.ORG U-MULTIRANK 2019 U-Multirank is a unique, multi- dimensional and international CONTENTS ranking of higher education institutions. It compares university performance across 3 AT A GLANCE: teaching and learning, research, HOW DO SPANISH UNIVERSITIES knowledge transfer, interna- FARE IN U-MULTIRANK? tional orienta tion and regional 4 WHICH ARE THE TOP PERFORMING engagement. It is the largest UNIVERSITIES IN SPAIN? and most inclusive ranking showcasing the diversity in 5 WHAT ARE THE PERFORMANCE higher education around the PROFILES OF SPAIN’S world. It is not a league table TOP SCORING UNIVERSITIES? and does not use composite 6 WHAT DO SPANISH indicators, nor reputation UNIVERSITIES DO BEST? weights. Therefore, there is no one best university in U- 7 HOW DO SPANISH UNIVERSITIES Multirank. The performance of PERFORM GLOBALLY? a university is presented with individual scores – graded from 8 APPENDIX: HOW CAN DETAILED RESULTS BE PRESENTED? ‘A’ (very good) to ‘E’ (weak) across the different areas. 9 WHAT IS U-MULTIRANK? U-Multirank’s 2019 edition presents data on 77 Spanish higher education institutions. For the full list of all universi- ties from Spain included in U-Multirank, please visit our website. 2 U-Multirank AT A GLANCE: HOW DO SPANISH UNIVERSITIES FARE IN U-MULTIRANK? • U-Multirank covers almost all Spanish universities. • Spanish universities show a strong regional focus which becomes visible in view of the indicators of Regional Joint Publications, Internships in the Region, and Graduate Employment in the Region. • At the same time, Spanish universities perform strongly in Student Mobility. -

Global Partners —
EXCHANGE PROGRAM Global DESTINATION GROUPS Group A: USA/ASIA/CANADA Group B: EUROPE/UK/LATIN AMERICA partners Group U: UTRECHT NETWORK CONTACT US — Office of Global Student Mobility STUDENTS MUST CHOOSE THREE PREFERENCES FROM ONE GROUP ONLY. Student Central (Builing 17) W: uow.info/study-overseas GROUP B AND GROUP U HAVE THE SAME APPLICATION DEADLINE. E: [email protected] P: +61 2 4221 5400 INSTITUTION GROUP INSTITUTION GROUP INSTITUTION GROUP AUSTRIA CZECH REPUBLIC HONG KONG University of Graz Masaryk University City University of Hong Kong Hong Kong Baptist University DENMARK BELGIUM The Education University of Aarhus University Hong Kong University of Antwerp University of Copenhagen The Hong Kong Polytechnic KU Leuven University of Southern University BRAZIL Denmark UOW College Hong Kong Federal University of Santa ESTONIA HUNGARY Catarina University of Tartu Eötvös Loránd University (ELTE) Pontifical Catholic University of Campinas FINLAND ICELAND Pontifical Catholic University of Rio de Janeiro University of Eastern Finland University of Iceland University of São Paulo FRANCE INDIA CANADA Audencia Business School Birla Institute of Management Technology (BIMTECH) Concordia University ESSCA School of Management IFIM Business School HEC Montreal Institut Polytechnique LaSalle Manipal Academy of Higher McMaster University Beauvais Education University of Alberta Lille Catholic University (IÉSEG School of Management) O.P. Jindal Global University University of British Columbia National Institute of Applied University of Calgary