Modern X86 Assembly Language Programming.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Fog Gateways:The Cornerstone of Iot Security
WHITE PAPER Fog Gateways: The Cornerstone of IoT Security Fog Gateways: The Cornerstone of IoT Security By Nicholas Cravotta The IoT offers tremendous value, safety. Utilities can dynamically change rates and shift loads—thus preventing overinvestment in power but also introduces major security generation. IoT-based medical devices can monitor challenges. Connecting previously offline patients continuously to identify trends and alert systems increases the attack surface for hackers— caregivers before an emergency arises. and the diversity of these systems makes it difficult to But all these benefits depend on secure data flow. deploy and manage consistent security. If the network is compromised, the result can be The nature of internal networks—such as the automation disastrous. For industrial applications, the cost could be networks that connect factory machinery—add to the the shutdown of operations or equipment damage. In a problem. Legacy networks provide minimal authorization, utilities environment, invalid data could result in black- little authentication, and not enough encryption. There outs and lost revenue. For retail applications, security is often no protection against intrusion, unauthorized breaches could halt sales and expose customer data. reconfiguration of edge equipment, or DDoS attacks. If an attacker gains access to these unsecure networks, the What Makes IoT Security Different entire organization can be at risk. In some ways, security concerns are nothing new. Most Fog computing can address these security issues today organizations already have security precautions in place and help you prepare for new challenges on the horizon. to protect sensitive IT systems and physical assets. But Fog gateways provide secure connectivity to local equip- the IoT introduces new threats that can catch businesses ment, intelligent data processing, and end-to-end off guard. -

Distributed Cloud-Based Approaches to the Genomic Data Analysis
08 Fall Czech Technical University Faculty of Electrical Engineering Distributed cloud-based approaches to the genomic data analysis (Master’s thesis) Bc. Filip Mihalovič Supervisor: doc. Ing. Jiří Kléma, PhD. Study programme: Open Informatics Specialization: Software Engineering May 2016 ii Acknowledgements I wish to express my sincere thanks to my supervisor doc. Ing. Jiří Kléma, PhD. for sharing his expertise and for his continuous guidance. I am grateful to my family and friends for their encouragement and support during my studies. Access to computing and storage facilities owned by parties and projects contributing to the National Grid Infrastructure MetaCentrum, provided under the programme "Projects of Large Research, Development, and Innovations Infrastructures" (CESNET LM2015042), is greatly appreciated. iii iv vi Declaration I declare that I worked out the presented thesis independently and I quoted all used sources of information in accord with Methodical instructions about ethical principles for writing academic thesis. In Prague on 24th May 2016 …………………………………….. Author vii Abstract The advance of genome analysis bound to next-generation sequencing has allowed scientists to conduct research to deeper understand the biological structure of organisms. A problem of computationally demanding genome assembly based on a high volume of sequence reads is introduced. Several sequential solutions for de novo genome assembly are reviewed. Two fundamental types of genome assembly approaches exist, the sequence reconstruction via de Bruijn graph and the overlap graph method. We focus on parallelization of the genome assembly task using the overlap graph approach and the utilization of Apache Spark big data engine. We demonstrate that subtasks of genome assembly can be parallelized and computed in a distributed manner. -

Download and Unpack It: Tar -Zxvf Leptospirashermanidata.Tar.Gz
Hsieh et al. BMC Bioinformatics (2020) 21:528 https://doi.org/10.1186/s12859‑020‑03788‑9 SOFTWARE Open Access Clover: a clustering‑oriented de novo assembler for Illumina sequences Ming‑Feng Hsieh1, Chin Lung Lu1 and Chuan Yi Tang1,2* *Correspondence: [email protected] Abstract 1 Department of Computer Background: Next‑generation sequencing technologies revolutionized genomics Science, National Tsing Hua University, Hsinchu 30013, by producing high‑throughput reads at low cost, and this progress has prompted the Taiwan recent development of de novo assemblers. Multiple assembly methods based on de Full list of author information Bruijn graph have been shown to be efcient for Illumina reads. However, the sequenc‑ is available at the end of the article ing errors generated by the sequencer complicate analysis of de novo assembly and infuence the quality of downstream genomic researches. Results: In this paper, we develop a de Bruijn assembler, called Clover (clustering‑ oriented de novo assembler), that utilizes a novel k‑mer clustering approach from the overlap‑layout‑consensus concept to deal with the sequencing errors generated by the Illumina platform. We further evaluate Clover’s performance against several de Bruijn graph assemblers (ABySS, SOAPdenovo, SPAdes and Velvet), overlap‑layout‑con‑ sensus assemblers (Bambus2, CABOG and MSR‑CA) and string graph assembler (SGA) on three datasets (Staphylococcus aureus, Rhodobacter sphaeroides and human chromo‑ some 14). The results show that Clover achieves a superior assembly quality in terms of corrected N50 and E‑size while remaining a signifcantly competitive in run time except SOAPdenovo. In addition, Clover was involved in the sequencing projects of bacterial genomes Acinetobacter baumannii TYTH‑1 and Morganella morganii KT. -

Lecture Notes in Assembly Language
Lecture Notes in Assembly Language Short introduction to low-level programming Piotr Fulmański Łódź, 12 czerwca 2015 Spis treści Spis treści iii 1 Before we begin1 1.1 Simple assembler.................................... 1 1.1.1 Excercise 1 ................................... 2 1.1.2 Excercise 2 ................................... 3 1.1.3 Excercise 3 ................................... 3 1.1.4 Excercise 4 ................................... 5 1.1.5 Excercise 5 ................................... 6 1.2 Improvements, part I: addressing........................... 8 1.2.1 Excercise 6 ................................... 11 1.3 Improvements, part II: indirect addressing...................... 11 1.4 Improvements, part III: labels............................. 18 1.4.1 Excercise 7: find substring in a string .................... 19 1.4.2 Excercise 8: improved polynomial....................... 21 1.5 Improvements, part IV: flag register ......................... 23 1.6 Improvements, part V: the stack ........................... 24 1.6.1 Excercise 12................................... 26 1.7 Improvements, part VI – function stack frame.................... 29 1.8 Finall excercises..................................... 34 1.8.1 Excercise 13................................... 34 1.8.2 Excercise 14................................... 34 1.8.3 Excercise 15................................... 34 1.8.4 Excercise 16................................... 34 iii iv SPIS TREŚCI 1.8.5 Excercise 17................................... 34 2 First program 37 2.1 Compiling, -

INTEL CORPORATION (Exact Name of Registrant As Specified in Its Charter) Delaware 94-1672743 State Or Other Jurisdiction of (I.R.S
UNITED STATES SECURITIES AND EXCHANGE COMMISSION Washington, D.C. 20549 FORM 10-K (Mark One) x ANNUAL REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 For the fiscal year ended December 31, 2016. or ¨ TRANSITION REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 For the transition period from to . Commission File Number 000-06217 INTEL CORPORATION (Exact name of registrant as specified in its charter) Delaware 94-1672743 State or other jurisdiction of (I.R.S. Employer incorporation or organization Identification No.) 2200 Mission College Boulevard, Santa Clara, California 95054-1549 (Address of principal executive offices) (Zip Code) Registrant’s telephone number, including area code (408) 765-8080 Securities registered pursuant to Section 12(b) of the Act: Title of each class Name of each exchange on which registered Common stock, $0.001 par value The NASDAQ Global Select Market* Securities registered pursuant to Section 12(g) of the Act: None Indicate by check mark if the registrant is a well-known seasoned issuer, as defined in Rule 405 of the Securities Act. Yes x No ¨ Indicate by check mark if the registrant is not required to file reports pursuant to Section 13 or Section 15(d) of the Act. Yes ¨ No x Indicate by check mark whether the registrant (1) has filed all reports required to be filed by Section 13 or 15(d) of the Securities Exchange Act of 1934 during the preceding 12 months (or for such shorter period that the registrant was required to file such reports), and (2) has been subject to such filing requirements for the past 90 days. -

Wind River Linux 5.X and Intel Gateway Solutions for Iot
Subject to Wind River Terms of Use - Do Not Copy – Do Not Distribute EDUCATION SERVICES Wind River Linux 5.x and Intel Gateway Solutions for IoT Version 1.0 A LECTURE GUIDE Volume 1 of 2 Subject to Wind River Terms of Use - Do Not Copy – Do Not Distribute LECTURE GUIDE Wind River Linux 5.x and Intel Gateway Solutions for IoT, Version 1.0 A Education Services Production Date: October 2014 Copyright c 2014 Wind River Systems, Inc. All rights reserved. No part of this publication may be reproduced or transmitted in any form or by any means without the prior written permission of Wind River Systems, Inc. Wind River, Tornado, and VxWorks are registered trademarks of Wind River Systems, Inc. The Wind River logo is a trademark of Wind River Systems, Inc. Any third-party trademarks refer- enced are the property of their respective owners. For further information regarding Wind River trademarks, please see: http://www.windriver.com/company/terms/trademark.html Wind River may refer to third-party documentation by listing publications or providing links to third-party Web sites for informational purposes. Wind River accepts no responsibility for the information provided in such third-party documentation. This document is designed to support the Wind River Linux 5.x and Intel Gateway Solutions for IoT course. It is not designed as a stand-alone document, nor is it intended as a substitute for documentation that accompanies Tornado, VxWorks, or Wind River Workbench or any other Wind River Systems, Inc. software or hardware product. http://education.windriver.com Education Services Department Wind River Systems, Inc. -

Introduction to X86 Assembly
CS342 Computer Security Handout # 5 Prof. Lyn Turbak Monday, Oct. 04, 2010 Wellesley College Lab 4: Introduction to x86 Assembly Reading: Hacking, 0x250, 0x270 Overview Today, we continue to cover low-level programming details that are essential for understanding software vulnerabilities like buffer overflow attacks and format string exploits. You will get exposure to the following: • Understanding conventions used by compiler to translate high-level programs to low-level assembly code (in our case, using Gnu C Compiler (gcc) to compile C programs). • The ability to read low-level assembly code (in our case, Intel x86). • Understanding how assembly code instructions are represented as machine code. • Being able to use gdb (the Gnu Debugger) to read the low-level code produced by gcc and understand its execution. In tutorials based on this handout, we will learn about all of the above in the context of some simple examples. Intel x86 Assembly Language Since Intel x86 processors are ubiquitous, it is helpful to know how to read assembly code for these processors. We will use the following terms: byte refers to 8-bit quantities; short word refers to 16-bit quantities; word refers to 32-bit quantities; and long word refers to 64-bit quantities. There are many registers, but we mostly care about the following: • EAX, EBX, ECX, EDX are 32-bit registers used for general storage. • ESI and EDI are 32-bit indexing registers that are sometimes used for general storage. • ESP is the 32-bit register for the stack pointer, which holds the address of the element currently at the top of the stack. -

Multiprocessing Contents
Multiprocessing Contents 1 Multiprocessing 1 1.1 Pre-history .............................................. 1 1.2 Key topics ............................................... 1 1.2.1 Processor symmetry ...................................... 1 1.2.2 Instruction and data streams ................................. 1 1.2.3 Processor coupling ...................................... 2 1.2.4 Multiprocessor Communication Architecture ......................... 2 1.3 Flynn’s taxonomy ........................................... 2 1.3.1 SISD multiprocessing ..................................... 2 1.3.2 SIMD multiprocessing .................................... 2 1.3.3 MISD multiprocessing .................................... 3 1.3.4 MIMD multiprocessing .................................... 3 1.4 See also ................................................ 3 1.5 References ............................................... 3 2 Computer multitasking 5 2.1 Multiprogramming .......................................... 5 2.2 Cooperative multitasking ....................................... 6 2.3 Preemptive multitasking ....................................... 6 2.4 Real time ............................................... 7 2.5 Multithreading ............................................ 7 2.6 Memory protection .......................................... 7 2.7 Memory swapping .......................................... 7 2.8 Programming ............................................. 7 2.9 See also ................................................ 8 2.10 References ............................................. -
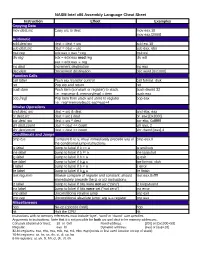
NASM Intel X86 Assembly Language Cheat Sheet
NASM Intel x86 Assembly Language Cheat Sheet Instruction Effect Examples Copying Data mov dest,src Copy src to dest mov eax,10 mov eax,[2000] Arithmetic add dest,src dest = dest + src add esi,10 sub dest,src dest = dest – src sub eax, ebx mul reg edx:eax = eax * reg mul esi div reg edx = edx:eax mod reg div edi eax = edx:eax reg inc dest Increment destination inc eax dec dest Decrement destination dec word [0x1000] Function Calls call label Push eip, transfer control call format_disk ret Pop eip and return ret push item Push item (constant or register) to stack. push dword 32 I.e.: esp=esp-4; memory[esp] = item push eax pop [reg] Pop item from stack and store to register pop eax I.e.: reg=memory[esp]; esp=esp+4 Bitwise Operations and dest, src dest = src & dest and ebx, eax or dest,src dest = src | dest or eax,[0x2000] xor dest, src dest = src ^ dest xor ebx, 0xfffffff shl dest,count dest = dest << count shl eax, 2 shr dest,count dest = dest >> count shr dword [eax],4 Conditionals and Jumps cmp b,a Compare b to a; must immediately precede any of cmp eax,0 the conditional jump instructions je label Jump to label if b == a je endloop jne label Jump to label if b != a jne loopstart jg label Jump to label if b > a jg exit jge label Jump to label if b > a jge format_disk jl label Jump to label if b < a jl error jle label Jump to label if b < a jle finish test reg,imm Bitwise compare of register and constant; should test eax,0xffff immediately precede the jz or jnz instructions jz label Jump to label if bits were not set (“zero”) jz looparound jnz label Jump to label if bits were set (“not zero”) jnz error jmp label Unconditional relative jump jmp exit jmp reg Unconditional absolute jump; arg is a register jmp eax Miscellaneous nop No-op (opcode 0x90) nop hlt Halt the CPU hlt Instructions with no memory references must include ‘byte’, ‘word’ or ‘dword’ size specifier. -

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
Case 2:16-cv-02026-DMF Document 1 Filed 06/22/16 Page 1 of 25 1 AIKEN SCHENK HAWKINS & RICCIARDI P.C. 2390 East Camelback Road, Suite 400 2 Phoenix, Arizona 85016 Telephone: (602) 248-8203 3 Facsimile: (602) 248-8840 E-Mail: [email protected] 4 E-Mail: [email protected] 5 Joseph A. Schenk – 009260 6 Bradley W. Caldwell (pro hac vice to be filed) Jason D. Cassady (pro hac vice to be filed) 7 J. Austin Curry (pro hac vice to be filed) Warren J. McCarty (pro hac vice to be filed) 8 Jason S. McManis (pro hac vice to be filed) CALDWELL CASSADY CURRY P.C. 9 2101 Cedar Springs Rd., Suite 1000 Dallas, Texas 75201 10 Telephone: (214) 888-4848 Facsimile: (214) 888-4849 11 Email: [email protected] Email: [email protected] 12 Email: [email protected] Email: [email protected] 13 Email: [email protected] 14 ATTORNEYS FOR PLAINTIFF CONTINENTAL CIRCUITS, LLC 15 IN THE UNITED STATES DISTRICT COURT 16 FOR THE DISTRICT OF ARIZONA 17 CONTINENTAL CIRCUITS, LLC, CASE NO. 18 Plaintiff, 19 COMPLAINT FOR PATENT v. INFRINGEMENT 20 INTEL CORP.; IBIDEN U.S.A. CORP.; 21 IBIDEN CO., LTD., JURY TRIAL DEMANDED 22 Defendants. 23 24 Plaintiff Continental Circuits LLC files this Complaint against Defendants Intel 25 Corporation, Ibiden U.S.A. Corporation, and Ibiden Co., Ltd. (collectively, “Defendants”) 26 for patent infringement under 35 U.S.C. § 271 and alleges, based on its own personal 27 knowledge with respect to its own actions and based upon information and belief with 28 respect to all others’ actions, as follows: 582424.1 Case 2:16-cv-02026-DMF Document 1 Filed 06/22/16 Page 2 of 25 1 THE PARTIES 2 1. -

Intel® Quark™ SE Microcontroller
Bringing intelligence to the internet of things Introducing the Intel® Quark™ SE Microcontroller John Moore Intel IoT Application Engineer 2nd Nov 2016 Legal Disclaimers You may not use or facilitate the use of this document in connection with any infringement or other legal analysis concerning Intel products described herein. You agree to grant Intel a non-exclusive, royalty- free license to any patent claim thereafter drafted which includes subject matter disclosed herein No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. All information provided here is subject to change without notice. Contact your Intel representative to obtain the latest Intel product specifications and roadmaps. The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Copies of documents which have an order number and are referenced in this document may be obtained by calling 1-800-548-4725 or by visiting: http://www.intel.com/design/literature.htm Tests document performance of components on a particular test, in specific systems. Differences in hardware, software, or configuration will affect actual performance. Consult other sources of information to evaluate performance as you consider your purchase. For more complete information about performance and benchmark results, visit http://www.intel.com/performance. Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. No computer system can be absolutely secure. Check with your system manufacturer or retailer or learn more at intel.com. -

X86 Disassembly Exploring the Relationship Between C, X86 Assembly, and Machine Code
x86 Disassembly Exploring the relationship between C, x86 Assembly, and Machine Code PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 07 Sep 2013 05:04:59 UTC Contents Articles Wikibooks:Collections Preface 1 X86 Disassembly/Cover 3 X86 Disassembly/Introduction 3 Tools 5 X86 Disassembly/Assemblers and Compilers 5 X86 Disassembly/Disassemblers and Decompilers 10 X86 Disassembly/Disassembly Examples 18 X86 Disassembly/Analysis Tools 19 Platforms 28 X86 Disassembly/Microsoft Windows 28 X86 Disassembly/Windows Executable Files 33 X86 Disassembly/Linux 48 X86 Disassembly/Linux Executable Files 50 Code Patterns 51 X86 Disassembly/The Stack 51 X86 Disassembly/Functions and Stack Frames 53 X86 Disassembly/Functions and Stack Frame Examples 57 X86 Disassembly/Calling Conventions 58 X86 Disassembly/Calling Convention Examples 64 X86 Disassembly/Branches 74 X86 Disassembly/Branch Examples 83 X86 Disassembly/Loops 87 X86 Disassembly/Loop Examples 92 Data Patterns 95 X86 Disassembly/Variables 95 X86 Disassembly/Variable Examples 101 X86 Disassembly/Data Structures 103 X86 Disassembly/Objects and Classes 108 X86 Disassembly/Floating Point Numbers 112 X86 Disassembly/Floating Point Examples 119 Difficulties 121 X86 Disassembly/Code Optimization 121 X86 Disassembly/Optimization Examples 124 X86 Disassembly/Code Obfuscation 132 X86 Disassembly/Debugger Detectors 137 Resources and Licensing 139 X86 Disassembly/Resources 139 X86 Disassembly/Licensing 141 X86 Disassembly/Manual of Style 141 References Article Sources and Contributors 142 Image Sources, Licenses and Contributors 143 Article Licenses License 144 Wikibooks:Collections Preface 1 Wikibooks:Collections Preface This book was created by volunteers at Wikibooks (http:/ / en.