Lecture Notes in Assembly Language
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

AMD Athlon™ Processor X86 Code Optimization Guide
AMD AthlonTM Processor x86 Code Optimization Guide © 2000 Advanced Micro Devices, Inc. All rights reserved. The contents of this document are provided in connection with Advanced Micro Devices, Inc. (“AMD”) products. AMD makes no representations or warranties with respect to the accuracy or completeness of the contents of this publication and reserves the right to make changes to specifications and product descriptions at any time without notice. No license, whether express, implied, arising by estoppel or otherwise, to any intellectual property rights is granted by this publication. Except as set forth in AMD’s Standard Terms and Conditions of Sale, AMD assumes no liability whatsoever, and disclaims any express or implied warranty, relating to its products including, but not limited to, the implied warranty of merchantability, fitness for a particular purpose, or infringement of any intellectual property right. AMD’s products are not designed, intended, authorized or warranted for use as components in systems intended for surgical implant into the body, or in other applications intended to support or sustain life, or in any other applica- tion in which the failure of AMD’s product could create a situation where per- sonal injury, death, or severe property or environmental damage may occur. AMD reserves the right to discontinue or make changes to its products at any time without notice. Trademarks AMD, the AMD logo, AMD Athlon, K6, 3DNow!, and combinations thereof, AMD-751, K86, and Super7 are trademarks, and AMD-K6 is a registered trademark of Advanced Micro Devices, Inc. Microsoft, Windows, and Windows NT are registered trademarks of Microsoft Corporation. -

Unix Protection
View access control as a matrix Protection Ali Mashtizadeh Stanford University Subjects (processes/users) access objects (e.g., files) • Each cell of matrix has allowed permissions • 1 / 39 2 / 39 Specifying policy Two ways to slice the matrix Manually filling out matrix would be tedious • Use tools such as groups or role-based access control: • Along columns: • - Kernel stores list of who can access object along with object - Most systems you’ve used probably do this dir 1 - Examples: Unix file permissions, Access Control Lists (ACLs) Along rows: • dir 2 - Capability systems do this - More on these later. dir 3 3 / 39 4 / 39 Outline Example: Unix protection Each process has a User ID & one or more group IDs • System stores with each file: • 1 Unix protection - User who owns the file and group file is in - Permissions for user, any one in file group, and other Shown by output of ls -l command: 2 Unix security holes • user group other owner group - rw- rw- r-- dm cs140 ... index.html 3 Capability-based protection - Eachz}|{ groupz}|{ z}|{ of threez}|{ lettersz }| { specifies a subset of read, write, and execute permissions - User permissions apply to processes with same user ID - Else, group permissions apply to processes in same group - Else, other permissions apply 5 / 39 6 / 39 Unix continued Non-file permissions in Unix Directories have permission bits, too • Many devices show up in file system • - Need write permission on a directory to create or delete a file - E.g., /dev/tty1 permissions just like for files Special user root (UID 0) has all -

Automatic Extraction of X86 Formal Semantics from Its Natural Language Description
Automatic extraction of x86 formal semantics from its natural language description NGUYEN, Lam Hoang Yen Graduate School of Advanced Science and Technology Japan Advanced Institute of Science and Technology March, 2018 Master's Thesis Automatic extraction of x86 formal semantics from its natural language description 1610062 NGUYEN, Lam Hoang Yen Supervisor : Professor Mizuhito Ogawa Main Examiner : Professor Mizuhito Ogawa Examiners : Associate Professor Nguyen Minh Le Professor Kazuhiro Ogata Associate Professor Nao Hirokawa Graduate School of Advanced Science and Technology Japan Advanced Institute of Science and Technology [Information Science] February, 2018 Abstract Nowadays, computers have become an essential device of almost every activity for every- body at any age. From personal demands to industrial and business sectors, they are used to improve human life as well as the efficiency and the productivity. The more important they are, the more attractive target they become for being attacked and serving malicious purposes. There are various threats to a computer system. One of the most common manners that penetrates or damages a system with bad impacts to most of the computer users is malware. Malware detection and malware classification are two of the most at- tractive problems in not only industry area but also academic research. The bits-based fingerprint also known as the signature-based pattern recognition is applied popularly in commercial anti-virus software due to its light-weight and fast features. However, it is easily cheated by advanced polymorphic techniques in malware. Therefore, malware analyses based on control flow graph (CFG) have been attracting a lot of attention, e.g., VxClass at Google. -

A Practical UNIX Capability System
A Practical UNIX Capability System Adam Langley <[email protected]> 22nd June 2005 ii Abstract This report seeks to document the development of a capability security system based on a Linux kernel and to follow through the implications of such a system. After defining terms, several other capability systems are discussed and found to be excellent, but to have too high a barrier to entry. This motivates the development of the above system. The capability system decomposes traditionally monolithic applications into a number of communicating actors, each of which is a separate process. Actors may only communicate using the capabilities given to them and so the impact of a vulnerability in a given actor can be reasoned about. This design pattern is demonstrated to be advantageous in terms of security, comprehensibility and mod- ularity and with an acceptable performance penality. From this, following through a few of the further avenues which present themselves is the two hours traffic of our stage. Acknowledgments I would like to thank my supervisor, Dr Kelly, for all the time he has put into cajoling and persuading me that the rest of the world might have a trick or two worth learning. Also, I’d like to thank Bryce Wilcox-O’Hearn for introducing me to capabilities many years ago. Contents 1 Introduction 1 2 Terms 3 2.1 POSIX ‘Capabilities’ . 3 2.2 Password Capabilities . 4 3 Motivations 7 3.1 Ambient Authority . 7 3.2 Confused Deputy . 8 3.3 Pervasive Testing . 8 3.4 Clear Auditing of Vulnerabilities . 9 3.5 Easy Configurability . -

Microprocessori
Microprocessori R.k.e. edizioni Antonio Pucci Microprocessori R.k.e. edizioni Indice Introduzione Cpu o microprocessore pagina 7 Il primo processore pagina 8 Elenco dei processori per anno pagina 11 Elenco dei processori per codice pagina 27 Net-o-grafia pagina 61 5 Introduzione CPU o microprocessore Un microprocessore spesso abbreviato con µP è esempio di microprocessore un componente elettronico digitale formato da permise di ridurre transistor racchiuso in uno significativamente i costi dei o più circuiti integrati. calcolatori. Uno o più processori sono Dagli anni 80 in poi i utilizzati come Cpu da un microprocessori sono sistema di elaborazione praticamente l’unica digitale come può essere un implementazione di Cpu. personal computer, un palmare, un telefono cellulare o un altro dispositivo digitale. La costruzione dei microprocessori fu resa possibile dall’avvento della tecnologia Lsi: integrando una Cpu completa in un solo chip 7 Il primo processore L’ obbiettivo del progetto era pre-programmate. Comunque sia nel 1971 equipaggiare il nuovo F-14 Il 17 settembre 1971 che nel 1976 Intel e Ti Tomcat che allora era in annunciò il modello Tms stipularono un accordo sviluppo. 1802 Nc, programmabile, in cui Intel pagava a Ti Il progetto venne che poteva essere i diritti per l’utilizzo del completato nel 1970 e utilizzato per implementare suo brevetto. Un riassunto utilizzava integrati mos per un calcolatore. della storia e contenuto nella il core della Cpu. L’ Intel 4004, processore a documentazione che Intel Il microprocessore Il proggetto era semplice e 4 Bit, venne presentato il 15 presentò in tribunale quando apparve appena la tecnologia innovativo e novembre 1971 e fu fu chiamata in giudizio da lo consentì dato che l’idea vinse sui competitori sviluppato da Federico Cyrix per violazione dei di integrare i componenti elettromeccanici Faggin. -

System Calls System Calls
System calls We will investigate several issues related to system calls. Read chapter 12 of the book Linux system call categories file management process management error handling note that these categories are loosely defined and much is behind included, e.g. communication. Why? 1 System calls File management system call hierarchy you may not see some topics as part of “file management”, e.g., sockets 2 System calls Process management system call hierarchy 3 System calls Error handling hierarchy 4 Error Handling Anything can fail! System calls are no exception Try to read a file that does not exist! Error number: errno every process contains a global variable errno errno is set to 0 when process is created when error occurs errno is set to a specific code associated with the error cause trying to open file that does not exist sets errno to 2 5 Error Handling error constants are defined in errno.h here are the first few of errno.h on OS X 10.6.4 #define EPERM 1 /* Operation not permitted */ #define ENOENT 2 /* No such file or directory */ #define ESRCH 3 /* No such process */ #define EINTR 4 /* Interrupted system call */ #define EIO 5 /* Input/output error */ #define ENXIO 6 /* Device not configured */ #define E2BIG 7 /* Argument list too long */ #define ENOEXEC 8 /* Exec format error */ #define EBADF 9 /* Bad file descriptor */ #define ECHILD 10 /* No child processes */ #define EDEADLK 11 /* Resource deadlock avoided */ 6 Error Handling common mistake for displaying errno from Linux errno man page: 7 Error Handling Description of the perror () system call. -

Advanced Components on Top of a Microkernel
Faculty of Computer Science Institute for System Architecture, Operating Systems Group Advanced Components on Top of A Microkernel Björn Döbel What we talked about so far • Microkernels are cool! • Fiasco.OC provides fundamental mechanisms: – Tasks (address spaces) • Container of resources – Threads • Units of execution – Inter-Process Communication • Exchange Data • Timeouts • Mapping of resources TU Dresden, 2012-07-24 L4Re: Advanced Components Slide 2 / 54 Lecture Outline • Building a real system on top of Fiasco.OC • Reusing legacy libraries – POSIX C library • Device Drivers in user space – Accessing hardware resources – Reusing Linux device drivers • OS virtualization on top of L4Re TU Dresden, 2012-07-24 L4Re: Advanced Components Slide 3 / 54 Reusing Existing Software • Often used term: legacy software • Why? – Convenience: • Users get their “favorite” application on the new OS – Effort: • Rewriting everything from scratch takes a lot of time • But: maintaining ported software and adaptions also does not come for free TU Dresden, 2012-07-24 L4Re: Advanced Components Slide 4 / 54 Reusing Existing Software • How? – Porting: • Adapt existing software to use L4Re/Fiasco.OC features instead of Linux • Efficient execution, large maintenance effort – Library-level interception • Port convenience libraries to L4Re and link legacy applications without modification – POSIX C libraries, libstdc++ – OS-level interception • Wine: implement Windows OS interface on top of new OS – Hardware-level: • Virtual Machines TU Dresden, 2012-07-24 L4Re: -

Targeting Embedded Powerpc
Freescale Semiconductor, Inc. EPPC.book Page 1 Monday, March 28, 2005 9:22 AM CodeWarrior™ Development Studio PowerPC™ ISA Communications Processors Edition Targeting Manual Revised: 28 March 2005 For More Information: www.freescale.com Freescale Semiconductor, Inc. EPPC.book Page 2 Monday, March 28, 2005 9:22 AM Metrowerks, the Metrowerks logo, and CodeWarrior are trademarks or registered trademarks of Metrowerks Corpora- tion in the United States and/or other countries. All other trade names and trademarks are the property of their respective owners. Copyright © 2005 by Metrowerks, a Freescale Semiconductor company. All rights reserved. No portion of this document may be reproduced or transmitted in any form or by any means, electronic or me- chanical, without prior written permission from Metrowerks. Use of this document and related materials are governed by the license agreement that accompanied the product to which this manual pertains. This document may be printed for non-commercial personal use only in accordance with the aforementioned license agreement. If you do not have a copy of the license agreement, contact your Metrowerks representative or call 1-800-377- 5416 (if outside the U.S., call +1-512-996-5300). Metrowerks reserves the right to make changes to any product described or referred to in this document without further notice. Metrowerks makes no warranty, representation or guarantee regarding the merchantability or fitness of its prod- ucts for any particular purpose, nor does Metrowerks assume any liability arising -

Introduction to X86 Assembly
CS342 Computer Security Handout # 5 Prof. Lyn Turbak Monday, Oct. 04, 2010 Wellesley College Lab 4: Introduction to x86 Assembly Reading: Hacking, 0x250, 0x270 Overview Today, we continue to cover low-level programming details that are essential for understanding software vulnerabilities like buffer overflow attacks and format string exploits. You will get exposure to the following: • Understanding conventions used by compiler to translate high-level programs to low-level assembly code (in our case, using Gnu C Compiler (gcc) to compile C programs). • The ability to read low-level assembly code (in our case, Intel x86). • Understanding how assembly code instructions are represented as machine code. • Being able to use gdb (the Gnu Debugger) to read the low-level code produced by gcc and understand its execution. In tutorials based on this handout, we will learn about all of the above in the context of some simple examples. Intel x86 Assembly Language Since Intel x86 processors are ubiquitous, it is helpful to know how to read assembly code for these processors. We will use the following terms: byte refers to 8-bit quantities; short word refers to 16-bit quantities; word refers to 32-bit quantities; and long word refers to 64-bit quantities. There are many registers, but we mostly care about the following: • EAX, EBX, ECX, EDX are 32-bit registers used for general storage. • ESI and EDI are 32-bit indexing registers that are sometimes used for general storage. • ESP is the 32-bit register for the stack pointer, which holds the address of the element currently at the top of the stack. -
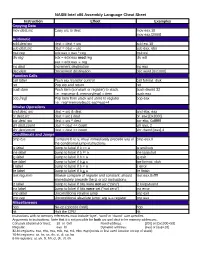
NASM Intel X86 Assembly Language Cheat Sheet
NASM Intel x86 Assembly Language Cheat Sheet Instruction Effect Examples Copying Data mov dest,src Copy src to dest mov eax,10 mov eax,[2000] Arithmetic add dest,src dest = dest + src add esi,10 sub dest,src dest = dest – src sub eax, ebx mul reg edx:eax = eax * reg mul esi div reg edx = edx:eax mod reg div edi eax = edx:eax reg inc dest Increment destination inc eax dec dest Decrement destination dec word [0x1000] Function Calls call label Push eip, transfer control call format_disk ret Pop eip and return ret push item Push item (constant or register) to stack. push dword 32 I.e.: esp=esp-4; memory[esp] = item push eax pop [reg] Pop item from stack and store to register pop eax I.e.: reg=memory[esp]; esp=esp+4 Bitwise Operations and dest, src dest = src & dest and ebx, eax or dest,src dest = src | dest or eax,[0x2000] xor dest, src dest = src ^ dest xor ebx, 0xfffffff shl dest,count dest = dest << count shl eax, 2 shr dest,count dest = dest >> count shr dword [eax],4 Conditionals and Jumps cmp b,a Compare b to a; must immediately precede any of cmp eax,0 the conditional jump instructions je label Jump to label if b == a je endloop jne label Jump to label if b != a jne loopstart jg label Jump to label if b > a jg exit jge label Jump to label if b > a jge format_disk jl label Jump to label if b < a jl error jle label Jump to label if b < a jle finish test reg,imm Bitwise compare of register and constant; should test eax,0xffff immediately precede the jz or jnz instructions jz label Jump to label if bits were not set (“zero”) jz looparound jnz label Jump to label if bits were set (“not zero”) jnz error jmp label Unconditional relative jump jmp exit jmp reg Unconditional absolute jump; arg is a register jmp eax Miscellaneous nop No-op (opcode 0x90) nop hlt Halt the CPU hlt Instructions with no memory references must include ‘byte’, ‘word’ or ‘dword’ size specifier. -

BIOS Boot Specification
Compaq Computer Corporation Phoenix Technologies Ltd. Intel Corporation BIOS Boot Specification Version 1.01 January 11, 1996 This specification has been made available to the public. You are hereby granted the right to use, implement, reproduce, and distribute this specification with the foregoing rights at no charge. This specification is, and shall remain, the property of Compaq Computer Corporation (“Compaq”), Phoenix Technologies Ltd (“Phoenix”), and Intel Corporation (“Intel”). NEITHER COMPAQ, PHOENIX NOR INTEL MAKE ANY REPRESENTATION OR WARRANTY REGARDING THIS SPECIFICATION OR ANY PRODUCT OR ITEM DEVELOPED BASED ON THIS SPECIFICATION. USE OF THIS SPECIFICATION FOR ANY PURPOSE IS AT THE RISK OF THE PERSON OR ENTITY USING IT. COMPAQ, PHOENIX AND INTEL DISCLAIM ALL EXPRESS AND IMPLIED WARRANTIES, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND FREEDOM FROM INFRINGEMENT. WITHOUT LIMITING THE GENERALITY OF THE FOREGOING, NEITHER COMPAQ, PHOENIX NOR INTEL MAKE ANY WARRANTY OF ANY KIND THAT ANY ITEM DEVELOPED BASED ON THIS SPECIFICATION, OR ANY PORTION OF IT, WILL NOT INFRINGE ANY COPYRIGHT, PATENT, TRADE SECRET OR OTHER INTELLECTUAL PROPERTY RIGHT OF ANY PERSON OR ENTITY IN ANY COUNTRY. Table of Contents 1.0 INTRODUCTION 5 1.1 REVISION HISTORY 5 1.2 RELATED DOCUMENTS 5 1.3 PURPOSE 5 1.4 TERMS 6 2.0 OVERVIEW 9 2.1 DESCRIPTION 9 3.0 IPL DEVICES 10 3.1 REQUIREMENTS FOR IPL DEVICES 10 3.1.1 IPL TABLE 10 3.1.2 PRODUCT NAME STRING 11 3.2 BAIDS 11 3.3 DEVICES WITH PNP EXPANSION HEADERS -

(PSW). Seven Bits Remain Unused While the Rest Nine Are Used
8086/8088MP INSTRUCTOR: ABDULMUTTALIB A. H. ALDOURI The Flags Register It is a 16-bit register, also called Program Status Word (PSW). Seven bits remain unused while the rest nine are used. Six are status flags and three are control flags. The control flags can be set/reset by the programmer. 1. DF (Direction Flag) : controls the direction of operation of string instructions. (DF=0 Ascending order DF=1 Descending order) 2. IF (Interrupt Flag): controls the interrupt operation in 8086µP. (IF=0 Disable interrupt IF=1 Enable interrupt) 3. TF (Trap Flag): controls the operation of the microprocessor. (TF=0 Normal operation TF=1 Single Step operation) The status flags are set/reset depending on the results of some arithmetic or logical operations during program execution. 1. CF (Carry Flag) is set (CF=1) if there is a carry out of the MSB position resulting from an addition operation or subtraction. 2. AF (Auxiliary Carry Flag) AF is set if there is a carry out of bit 3 resulting from an addition operation. 3. SF (Sign Flag) set to 1 when result is negative. When result is positive it is set to 0. 4. ZF (Zero Flag) is set (ZF=1) when result of an arithmetic or logical operation is zero. For non-zero result this flag is reset (ZF=0). 5. PF (Parity Flag) this flag is set to 1 when there is even number of one bits in result, and to 0 when there is odd number of one bits. 6. OF (Overflow Flag) set to 1 when there is a signed overflow.