X86 Assembly Language Reference Manual
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

6.004 Computation Structures Spring 2009
MIT OpenCourseWare http://ocw.mit.edu 6.004 Computation Structures Spring 2009 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms. M A S S A C H U S E T T S I N S T I T U T E O F T E C H N O L O G Y DEPARTMENT OF ELECTRICAL ENGINEERING AND COMPUTER SCIENCE 6.004 Computation Structures β Documentation 1. Introduction This handout is a reference guide for the β, the RISC processor design for 6.004. This is intended to be a complete and thorough specification of the programmer-visible state and instruction set. 2. Machine Model The β is a general-purpose 32-bit architecture: all registers are 32 bits wide and when loaded with an address can point to any location in the byte-addressed memory. When read, register 31 is always 0; when written, the new value is discarded. Program Counter Main Memory PC always a multiple of 4 0x00000000: 3 2 1 0 0x00000004: 32 bits … Registers SUB(R3,R4,R5) 232 bytes R0 ST(R5,1000) R1 … … R30 0xFFFFFFF8: R31 always 0 0xFFFFFFFC: 32 bits 32 bits 3. Instruction Encoding Each β instruction is 32 bits long. All integer manipulation is between registers, with up to two source operands (one may be a sign-extended 16-bit literal), and one destination register. Memory is referenced through load and store instructions that perform no other computation. Conditional branch instructions are separated from comparison instructions: branch instructions test the value of a register that can be the result of a previous compare instruction. -

New Instruction Set Extensions
New Instruction Set Extensions Instruction Set Innovation in Intels Processor Code Named Haswell [email protected] Agenda • Introduction - Overview of ISA Extensions • Haswell New Instructions • New Instructions Overview • Intel® AVX2 (256-bit Integer Vectors) • Gather • FMA: Fused Multiply-Add • Bit Manipulation Instructions • TSX/HLE/RTM • Tools Support for New Instruction Set Extensions • Summary/References Copyright© 2012, Intel Corporation. All rights reserved. Partially Intel Confidential Information. 2 *Other brands and names are the property of their respective owners. Instruction Set Architecture (ISA) Extensions 199x MMX, CMOV, Multiple new instruction sets added to the initial 32bit instruction PAUSE, set of the Intel® 386 processor XCHG, … 1999 Intel® SSE 70 new instructions for 128-bit single-precision FP support 2001 Intel® SSE2 144 new instructions adding 128-bit integer and double-precision FP support 2004 Intel® SSE3 13 new 128-bit DSP-oriented math instructions and thread synchronization instructions 2006 Intel SSSE3 16 new 128-bit instructions including fixed-point multiply and horizontal instructions 2007 Intel® SSE4.1 47 new instructions improving media, imaging and 3D workloads 2008 Intel® SSE4.2 7 new instructions improving text processing and CRC 2010 Intel® AES-NI 7 new instructions to speedup AES 2011 Intel® AVX 256-bit FP support, non-destructive (3-operand) 2012 Ivy Bridge NI RNG, 16 Bit FP 2013 Haswell NI AVX2, TSX, FMA, Gather, Bit NI A long history of ISA Extensions ! Copyright© 2012, Intel Corporation. All rights reserved. Partially Intel Confidential Information. 3 *Other brands and names are the property of their respective owners. Instruction Set Architecture (ISA) Extensions • Why new instructions? • Higher absolute performance • More energy efficient performance • New application domains • Customer requests • Fill gaps left from earlier extensions • For a historical overview see http://en.wikipedia.org/wiki/X86_instruction_listings Copyright© 2012, Intel Corporation. -

Binary and Hexadecimal
Binary and Hexadecimal Binary and Hexadecimal Introduction This document introduces the binary (base two) and hexadecimal (base sixteen) number systems as a foundation for systems programming tasks and debugging. In this document, if the base of a number might be ambiguous, we use a base subscript to indicate the base of the value. For example: 45310 is a base ten (decimal) value 11012 is a base two (binary) value 821716 is a base sixteen (hexadecimal) value Why do we need binary? The binary number system (also called the base two number system) is the native language of digital computers. No matter how elegantly or naturally we might interact with today’s computers, phones, and other smart devices, all instructions and data are ultimately stored and manipulated in the computer as binary digits (also called bits, where a bit is either a 0 or a 1). CPUs (central processing units) and storage devices can only deal with information in this form. In a computer system, absolutely everything is represented as binary values, whether it’s a program you’re running, an image you’re viewing, a video you’re watching, or a document you’re writing. Everything, including text and images, is represented in binary. In the “old days,” before computer programming languages were available, programmers had to use sequences of binary digits to communicate directly with the computer. Today’s high level languages attempt to shield us from having to deal with binary at all. However, there are a few reasons why it’s important for programmers to understand the binary number system: 1. -

Lecture Notes in Assembly Language
Lecture Notes in Assembly Language Short introduction to low-level programming Piotr Fulmański Łódź, 12 czerwca 2015 Spis treści Spis treści iii 1 Before we begin1 1.1 Simple assembler.................................... 1 1.1.1 Excercise 1 ................................... 2 1.1.2 Excercise 2 ................................... 3 1.1.3 Excercise 3 ................................... 3 1.1.4 Excercise 4 ................................... 5 1.1.5 Excercise 5 ................................... 6 1.2 Improvements, part I: addressing........................... 8 1.2.1 Excercise 6 ................................... 11 1.3 Improvements, part II: indirect addressing...................... 11 1.4 Improvements, part III: labels............................. 18 1.4.1 Excercise 7: find substring in a string .................... 19 1.4.2 Excercise 8: improved polynomial....................... 21 1.5 Improvements, part IV: flag register ......................... 23 1.6 Improvements, part V: the stack ........................... 24 1.6.1 Excercise 12................................... 26 1.7 Improvements, part VI – function stack frame.................... 29 1.8 Finall excercises..................................... 34 1.8.1 Excercise 13................................... 34 1.8.2 Excercise 14................................... 34 1.8.3 Excercise 15................................... 34 1.8.4 Excercise 16................................... 34 iii iv SPIS TREŚCI 1.8.5 Excercise 17................................... 34 2 First program 37 2.1 Compiling, -

ARM Instruction Set
4 ARM Instruction Set This chapter describes the ARM instruction set. 4.1 Instruction Set Summary 4-2 4.2 The Condition Field 4-5 4.3 Branch and Exchange (BX) 4-6 4.4 Branch and Branch with Link (B, BL) 4-8 4.5 Data Processing 4-10 4.6 PSR Transfer (MRS, MSR) 4-17 4.7 Multiply and Multiply-Accumulate (MUL, MLA) 4-22 4.8 Multiply Long and Multiply-Accumulate Long (MULL,MLAL) 4-24 4.9 Single Data Transfer (LDR, STR) 4-26 4.10 Halfword and Signed Data Transfer 4-32 4.11 Block Data Transfer (LDM, STM) 4-37 4.12 Single Data Swap (SWP) 4-43 4.13 Software Interrupt (SWI) 4-45 4.14 Coprocessor Data Operations (CDP) 4-47 4.15 Coprocessor Data Transfers (LDC, STC) 4-49 4.16 Coprocessor Register Transfers (MRC, MCR) 4-53 4.17 Undefined Instruction 4-55 4.18 Instruction Set Examples 4-56 ARM7TDMI-S Data Sheet 4-1 ARM DDI 0084D Final - Open Access ARM Instruction Set 4.1 Instruction Set Summary 4.1.1 Format summary The ARM instruction set formats are shown below. 3 3 2 2 2 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 9876543210 1 0 9 8 7 6 5 4 3 2 1 0 9 8 7 6 5 4 3 2 1 0 Cond 0 0 I Opcode S Rn Rd Operand 2 Data Processing / PSR Transfer Cond 0 0 0 0 0 0 A S Rd Rn Rs 1 0 0 1 Rm Multiply Cond 0 0 0 0 1 U A S RdHi RdLo Rn 1 0 0 1 Rm Multiply Long Cond 0 0 0 1 0 B 0 0 Rn Rd 0 0 0 0 1 0 0 1 Rm Single Data Swap Cond 0 0 0 1 0 0 1 0 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 1 Rn Branch and Exchange Cond 0 0 0 P U 0 W L Rn Rd 0 0 0 0 1 S H 1 Rm Halfword Data Transfer: register offset Cond 0 0 0 P U 1 W L Rn Rd Offset 1 S H 1 Offset Halfword Data Transfer: immediate offset Cond 0 -

Hyper-Threading Performance with Intel Cpus for Linux SAP Deployment on Proliant Servers
Hyper-Threading Performance with Intel CPUs for Linux SAP Deployment on ProLiant Servers Session #3798 Hein van den Heuvel Performance Engineer Hewlett-Packard © 2004 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice Topics • Hyper-Threading Intro • Implementation details Intel, IBM, Sun • Linux implementation • My own tests • SAP (SD) benchmark • Benchmark Results • Conclusions: (18% improvement for SAP 2-tier) Intel Hyper-Threading Overview “Hyper-Threading Technology is a form of simultaneous multithreading technology (SMT), where multiple threads of software applications can be run simultaneously on one processor. This is achieved by duplicating the architectural state on each processor, while sharing one set of processor execution resources. The architectural state tracks the flow of a program or thread, and the execution resources are the units on the processor that do the work: add, multiply, load, etc. “ http://www.intel.com/business/bss/products/hyperthreading/server/ht_server.pdf http://www.intel.com/technology/hyperthread/ Intel HT in a picture To-be-updated Hyper-Threading Versus Dual Core • HP (PA + ipf) opted for ‘dual core’ technology. − Each processor has full set of resources − Only limitation is shared ‘system’ connection. − Allows for dense (8p – 4u – 4640) − minimally constrained systems • Software licensing impact (Oracle!) • Hyper-Threading technology effectiveness will depend on application IBM P5 SMT Summary Enhanced Simultaneous Multi-Threading features To improve SMT performance for various workload mixes and provide robust quality of service, POWER5 provides two features: • Dynamic resource balancing – The objective of dynamic resource balancing is to ensure that the two threads executing on the same processor flow smoothly through the system. -

Cognitive Programming Language (CPL) Programmer's Guide
Cognitive Programming Language (CPL) Programmer's Guide 105-008-02 Revision C2 – 3/17/2006 *105-008-02* Copyright © 2006, Cognitive. Cognitive™, Cxi™, and Ci™ are trademarks of Cognitive. Microsoft® and Windows™ are trademarks of Microsoft Corporation. Other product and corporate names used in this document may be trademarks or registered trademarks of other companies, and are used only for explanation and to their owner’s benefit, without intent to infringe. All information in this document is subject to change without notice, and does not represent a commitment on the part of Cognitive. No part of this document may be reproduced for any reason or in any form, including electronic storage and retrieval, without the express permission of Cognitive. All program listings in this document are copyrighted and are the property of Cognitive and are provided without warranty. To contact Cognitive: Cognitive Solutions, Inc. 4403 Table Mountain Drive Suite A Golden, CO 80403 E-Mail: [email protected] Telephone: +1.800.525.2785 Fax: +1.303.273.1414 Table of Contents Introduction.............................................................................................. 1 Label Format Organization .................................................................. 2 Command Syntax................................................................................ 2 Important Programming Rules............................................................. 3 Related Publications........................................................................... -

A Compiler for a Simple Language. V0.16
Project step 1 – a compiler for a simple language. v0.16 Change log: v0.16, changes from 0.15 Make all push types in compiler actions explicit. Simplified and better documentation of call and callr instruction compiler actions. Let the print statement print characters and numbers. Added a printv statement to print variables. Changed compiler actions for retr to push a variable value, not a literal value. Changes are shown in orange. v0.15, changes from 0.14 Change compiler actions for ret, retr, jmp. Change the description and compiler actions for poke. Change the description for swp. Change the compiler actions for call and callr. Changes shown in green. v0.14, changes from 0.13 Add peek, poke and swp instructions. Change popm compiler actions. Change callr compiler actions. Other small changes to wording. Changes are shown in blue. v0.13, changes from 0.12 Add a count field to subr, call and callr to simplify code generation. Changes are shown in red. v0.12 Changes from 0.11. Added a callr statement that takes a return type. Fix the generated code for this and for call to allow arguments to be pushed by the call. Add a retr that returns a value and update the reg. v0.11: changes from 0.10. Put typing into push operators. Put opcodes for compare operators. fix actions for call. Make declarations reserve a stack location. Remove redundant store instruction (popv does the same thing.) v0.10: changes from 0.0. Comparison operators (cmpe, cmplt, cmpgt) added. jump conditional (jmpc) added. bytecode values added. -

Introduction to X86 Assembly
CS342 Computer Security Handout # 5 Prof. Lyn Turbak Monday, Oct. 04, 2010 Wellesley College Lab 4: Introduction to x86 Assembly Reading: Hacking, 0x250, 0x270 Overview Today, we continue to cover low-level programming details that are essential for understanding software vulnerabilities like buffer overflow attacks and format string exploits. You will get exposure to the following: • Understanding conventions used by compiler to translate high-level programs to low-level assembly code (in our case, using Gnu C Compiler (gcc) to compile C programs). • The ability to read low-level assembly code (in our case, Intel x86). • Understanding how assembly code instructions are represented as machine code. • Being able to use gdb (the Gnu Debugger) to read the low-level code produced by gcc and understand its execution. In tutorials based on this handout, we will learn about all of the above in the context of some simple examples. Intel x86 Assembly Language Since Intel x86 processors are ubiquitous, it is helpful to know how to read assembly code for these processors. We will use the following terms: byte refers to 8-bit quantities; short word refers to 16-bit quantities; word refers to 32-bit quantities; and long word refers to 64-bit quantities. There are many registers, but we mostly care about the following: • EAX, EBX, ECX, EDX are 32-bit registers used for general storage. • ESI and EDI are 32-bit indexing registers that are sometimes used for general storage. • ESP is the 32-bit register for the stack pointer, which holds the address of the element currently at the top of the stack. -
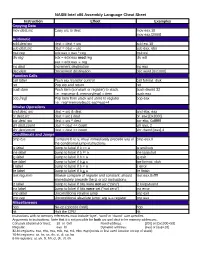
NASM Intel X86 Assembly Language Cheat Sheet
NASM Intel x86 Assembly Language Cheat Sheet Instruction Effect Examples Copying Data mov dest,src Copy src to dest mov eax,10 mov eax,[2000] Arithmetic add dest,src dest = dest + src add esi,10 sub dest,src dest = dest – src sub eax, ebx mul reg edx:eax = eax * reg mul esi div reg edx = edx:eax mod reg div edi eax = edx:eax reg inc dest Increment destination inc eax dec dest Decrement destination dec word [0x1000] Function Calls call label Push eip, transfer control call format_disk ret Pop eip and return ret push item Push item (constant or register) to stack. push dword 32 I.e.: esp=esp-4; memory[esp] = item push eax pop [reg] Pop item from stack and store to register pop eax I.e.: reg=memory[esp]; esp=esp+4 Bitwise Operations and dest, src dest = src & dest and ebx, eax or dest,src dest = src | dest or eax,[0x2000] xor dest, src dest = src ^ dest xor ebx, 0xfffffff shl dest,count dest = dest << count shl eax, 2 shr dest,count dest = dest >> count shr dword [eax],4 Conditionals and Jumps cmp b,a Compare b to a; must immediately precede any of cmp eax,0 the conditional jump instructions je label Jump to label if b == a je endloop jne label Jump to label if b != a jne loopstart jg label Jump to label if b > a jg exit jge label Jump to label if b > a jge format_disk jl label Jump to label if b < a jl error jle label Jump to label if b < a jle finish test reg,imm Bitwise compare of register and constant; should test eax,0xffff immediately precede the jz or jnz instructions jz label Jump to label if bits were not set (“zero”) jz looparound jnz label Jump to label if bits were set (“not zero”) jnz error jmp label Unconditional relative jump jmp exit jmp reg Unconditional absolute jump; arg is a register jmp eax Miscellaneous nop No-op (opcode 0x90) nop hlt Halt the CPU hlt Instructions with no memory references must include ‘byte’, ‘word’ or ‘dword’ size specifier. -

Assembly Language
Assembly Language University of Texas at Austin CS310H - Computer Organization Spring 2010 Don Fussell Human-Readable Machine Language Computers like ones and zeros… 0001110010000110 Humans like symbols… ADD R6,R2,R6 ; increment index reg. Assembler is a program that turns symbols into machine instructions. ISA-specific: close correspondence between symbols and instruction set mnemonics for opcodes labels for memory locations additional operations for allocating storage and initializing data University of Texas at Austin CS310H - Computer Organization Spring 2010 Don Fussell 2 An Assembly Language Program ; ; Program to multiply a number by the constant 6 ; .ORIG x3050 LD R1, SIX LD R2, NUMBER AND R3, R3, #0 ; Clear R3. It will ; contain the product. ; The inner loop ; AGAIN ADD R3, R3, R2 ADD R1, R1, #-1 ; R1 keeps track of BRp AGAIN ; the iteration. ; HALT ; NUMBER .BLKW 1 SIX .FILL x0006 ; .END University of Texas at Austin CS310H - Computer Organization Spring 2010 Don Fussell 3 LC-3 Assembly Language Syntax Each line of a program is one of the following: an instruction an assember directive (or pseudo-op) a comment Whitespace (between symbols) and case are ignored. Comments (beginning with “;”) are also ignored. An instruction has the following format: LABEL OPCODE OPERANDS ; COMMENTS optional mandatory University of Texas at Austin CS310H - Computer Organization Spring 2010 Don Fussell 4 Opcodes and Operands Opcodes reserved symbols that correspond to LC-3 instructions listed in Appendix A ex: ADD, AND, LD, LDR, … Operands registers -

Exposing Native Device Apis to Web Apps
Exposing Native Device APIs to Web Apps Arno Puder Nikolai Tillmann Michał Moskal San Francisco State University Microsoft Research Microsoft Research Computer Science One Microsoft Way One Microsoft Way Department Redmond, WA 98052 Redmond, WA 98052 1600 Holloway Avenue [email protected] [email protected] San Francisco, CA 94132 [email protected] ABSTRACT language of the respective platform, HTML5 technologies A recent survey among developers revealed that half plan to gain traction for the development of mobile apps [12, 4]. use HTML5 for mobile apps in the future. An earlier survey A recent survey among developers revealed that more than showed that access to native device APIs is the biggest short- half (52%) are using HTML5 technologies for developing mo- coming of HTML5 compared to native apps. Several dif- bile apps [22]. HTML5 technologies enable the reuse of the ferent approaches exist to overcome this limitation, among presentation layer and high-level logic across multiple plat- them cross-compilation and packaging the HTML5 as a na- forms. However, an earlier survey [21] on cross-platform tive app. In this paper we propose a novel approach by using developer tools revealed that access to native device APIs a device-local service that runs on the smartphone and that is the biggest shortcoming of HTML5 compared to native acts as a gateway to the native layer for HTML5-based apps apps. Several different approaches exist to overcome this running inside the standard browser. WebSockets are used limitation. Besides the development of native apps for spe- for bi-directional communication between the web apps and cific platforms, popular approaches include cross-platform the device-local service.