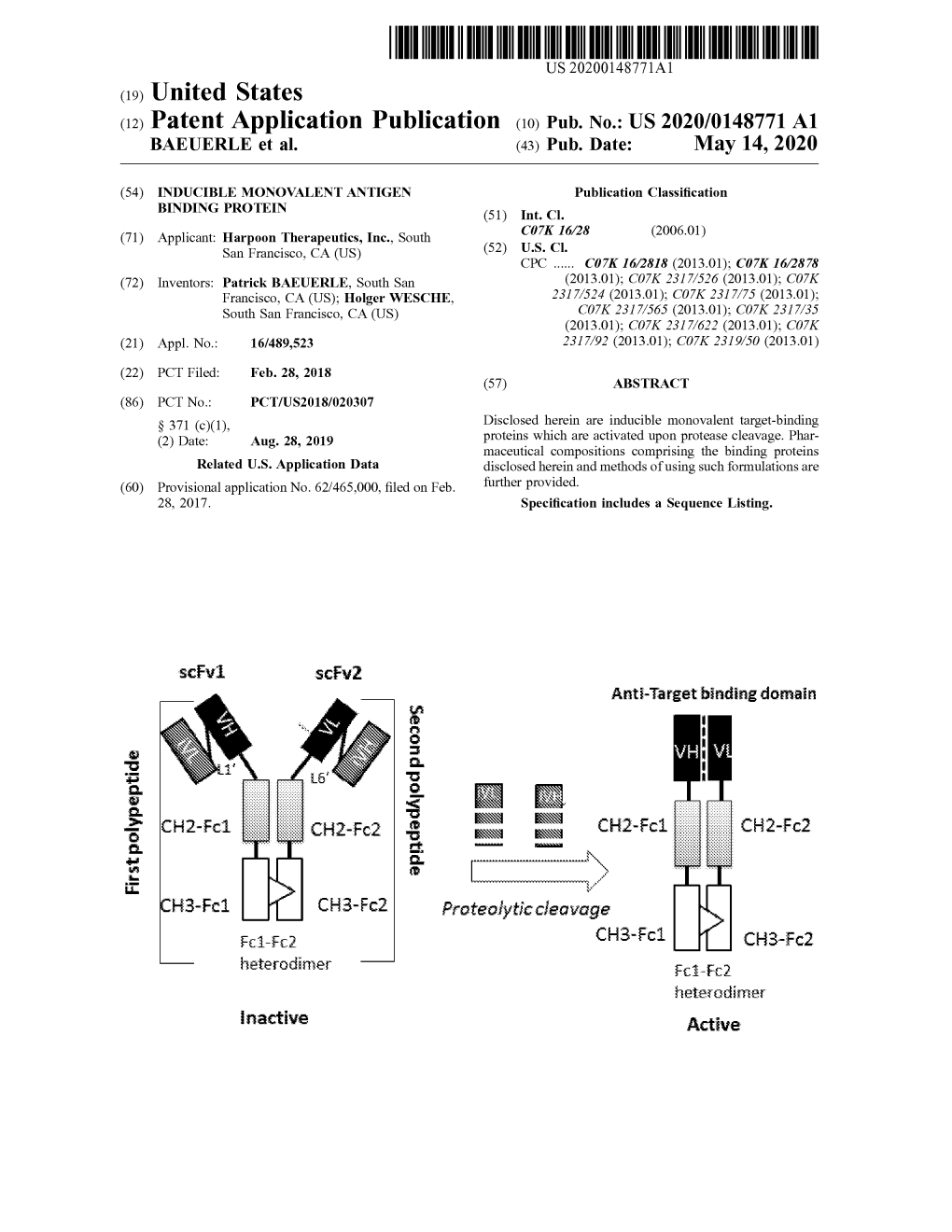
First Polypetide
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Enzymatic Encoding Methods for Efficient Synthesis Of
(19) TZZ__T (11) EP 1 957 644 B1 (12) EUROPEAN PATENT SPECIFICATION (45) Date of publication and mention (51) Int Cl.: of the grant of the patent: C12N 15/10 (2006.01) C12Q 1/68 (2006.01) 01.12.2010 Bulletin 2010/48 C40B 40/06 (2006.01) C40B 50/06 (2006.01) (21) Application number: 06818144.5 (86) International application number: PCT/DK2006/000685 (22) Date of filing: 01.12.2006 (87) International publication number: WO 2007/062664 (07.06.2007 Gazette 2007/23) (54) ENZYMATIC ENCODING METHODS FOR EFFICIENT SYNTHESIS OF LARGE LIBRARIES ENZYMVERMITTELNDE KODIERUNGSMETHODEN FÜR EINE EFFIZIENTE SYNTHESE VON GROSSEN BIBLIOTHEKEN PROCEDES DE CODAGE ENZYMATIQUE DESTINES A LA SYNTHESE EFFICACE DE BIBLIOTHEQUES IMPORTANTES (84) Designated Contracting States: • GOLDBECH, Anne AT BE BG CH CY CZ DE DK EE ES FI FR GB GR DK-2200 Copenhagen N (DK) HU IE IS IT LI LT LU LV MC NL PL PT RO SE SI • DE LEON, Daen SK TR DK-2300 Copenhagen S (DK) Designated Extension States: • KALDOR, Ditte Kievsmose AL BA HR MK RS DK-2880 Bagsvaerd (DK) • SLØK, Frank Abilgaard (30) Priority: 01.12.2005 DK 200501704 DK-3450 Allerød (DK) 02.12.2005 US 741490 P • HUSEMOEN, Birgitte Nystrup DK-2500 Valby (DK) (43) Date of publication of application: • DOLBERG, Johannes 20.08.2008 Bulletin 2008/34 DK-1674 Copenhagen V (DK) • JENSEN, Kim Birkebæk (73) Proprietor: Nuevolution A/S DK-2610 Rødovre (DK) 2100 Copenhagen 0 (DK) • PETERSEN, Lene DK-2100 Copenhagen Ø (DK) (72) Inventors: • NØRREGAARD-MADSEN, Mads • FRANCH, Thomas DK-3460 Birkerød (DK) DK-3070 Snekkersten (DK) • GODSKESEN, -

B Number Gene Name Mrna Intensity Mrna
sample) total list predicted B number Gene name assignment mRNA present mRNA intensity Gene description Protein detected - Membrane protein membrane sample detected (total list) Proteins detected - Functional category # of tryptic peptides # of tryptic peptides # of tryptic peptides detected (membrane b0002 thrA 13624 P 39 P 18 P(m) 2 aspartokinase I, homoserine dehydrogenase I Metabolism of small molecules b0003 thrB 6781 P 9 P 3 0 homoserine kinase Metabolism of small molecules b0004 thrC 15039 P 18 P 10 0 threonine synthase Metabolism of small molecules b0008 talB 20561 P 20 P 13 0 transaldolase B Metabolism of small molecules chaperone Hsp70; DNA biosynthesis; autoregulated heat shock b0014 dnaK 13283 P 32 P 23 0 proteins Cell processes b0015 dnaJ 4492 P 13 P 4 P(m) 1 chaperone with DnaK; heat shock protein Cell processes b0029 lytB 1331 P 16 P 2 0 control of stringent response; involved in penicillin tolerance Global functions b0032 carA 9312 P 14 P 8 0 carbamoyl-phosphate synthetase, glutamine (small) subunit Metabolism of small molecules b0033 carB 7656 P 48 P 17 0 carbamoyl-phosphate synthase large subunit Metabolism of small molecules b0048 folA 1588 P 7 P 1 0 dihydrofolate reductase type I; trimethoprim resistance Metabolism of small molecules peptidyl-prolyl cis-trans isomerase (PPIase), involved in maturation of b0053 surA 3825 P 19 P 4 P(m) 1 GenProt outer membrane proteins (1st module) Cell processes b0054 imp 2737 P 42 P 5 P(m) 5 GenProt organic solvent tolerance Cell processes b0071 leuD 4770 P 10 P 9 0 isopropylmalate -

Product Sheet Info
Master Clone List for NR-19279 ® Vibrio cholerae Gateway Clone Set, Recombinant in Escherichia coli, Plates 1-46 Catalog No. NR-19279 Table 1: Vibrio cholerae Gateway® Clones, Plate 1 (NR-19679) Clone ID Well ORF Locus ID Symbol Product Accession Position Length Number 174071 A02 367 VC2271 ribD riboflavin-specific deaminase NP_231902.1 174346 A03 336 VC1877 lpxK tetraacyldisaccharide 4`-kinase NP_231511.1 174354 A04 342 VC0953 holA DNA polymerase III, delta subunit NP_230600.1 174115 A05 388 VC2085 sucC succinyl-CoA synthase, beta subunit NP_231717.1 174310 A06 506 VC2400 murC UDP-N-acetylmuramate--alanine ligase NP_232030.1 174523 A07 132 VC0644 rbfA ribosome-binding factor A NP_230293.2 174632 A08 322 VC0681 ribF riboflavin kinase-FMN adenylyltransferase NP_230330.1 174930 A09 433 VC0720 phoR histidine protein kinase PhoR NP_230369.1 174953 A10 206 VC1178 conserved hypothetical protein NP_230823.1 174976 A11 213 VC2358 hypothetical protein NP_231988.1 174898 A12 369 VC0154 trmA tRNA (uracil-5-)-methyltransferase NP_229811.1 174059 B01 73 VC2098 hypothetical protein NP_231730.1 174075 B02 82 VC0561 rpsP ribosomal protein S16 NP_230212.1 174087 B03 378 VC1843 cydB-1 cytochrome d ubiquinol oxidase, subunit II NP_231477.1 174099 B04 383 VC1798 eha eha protein NP_231433.1 174294 B05 494 VC0763 GTP-binding protein NP_230412.1 174311 B06 314 VC2183 prsA ribose-phosphate pyrophosphokinase NP_231814.1 174603 B07 108 VC0675 thyA thymidylate synthase NP_230324.1 174474 B08 466 VC1297 asnS asparaginyl-tRNA synthetase NP_230942.2 174933 B09 198 -

Downloading the Nucleotide Sequences and Scanning Them Against the Database
An in silico analysis, purification and partial kinetic characterisation of a serine protease from Gelidium pristoides A dissertation submitted in fulfilment of the requirement for the degree of Master of Science (MSc) Biochemistry by Zolani Ntsata Supervisor: Prof. Graeme Bradley 2020 Department of Biochemistry and Microbiology Declaration I, Zolani Ntsata (201106067), declare that this dissertation, entitled ‘An in silico analysis and kinetic characterisation of proteases from red algae’ submitted to the University of Fort Hare for the Master’s degree (Biochemistry) award, is my original work and has NOT been submitted to any other university. Signature: __________________ I, Zolani Ntsata (201106067), declare that I am highly cognisant of the University of Fort Hare policy on plagiarism and I have been careful to comply with these regulations. Furthermore, all the sources of information have been cited as indicated in the bibliography. Signature: __________________ I, Zolani Ntsata (201106067), declare that I am fully aware of the University of Fort Hare’s policy on research ethics, and I have taken every precaution to comply with these regulations. There was no need for ethical clearance. Signature: _________________ i Dedication I dedicate this work to my grandmother, Nyameka Mabi. ii Acknowledgements Above all things, I would like to give thanks to God for the opportunity to do this project and for the extraordinary strength to persevere in spite of the challenges that came along. I am thankful to my family, especially my grandmother, for her endless support. I would also like to acknowledge Prof Graeme Bradley for his supervision and guidance. Thanks to my friends and colleagues, especially Yanga Gogela and Ntombekhaya Nqumla, and the plant stress group for their help and support. -

Galhenage Thanusha Ranithri Abeynayake
Development of hydrolysates with antioxidant effects from brewers’ spent grain proteins by Galhenage Thanusha Ranithri Abeynayake A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Food Science and Technology Department of Agricultural, Food and Nutritional Science University of Alberta © Galhenage Thanusha Ranithri Abeynayake, 2020 Abstract Brewers’ spent grain (BSG), the most abundant brewing by-product contains up to 24% (w/w) of protein on dry basis. Despite of a rich protein source, it is still mainly used as low value animal feed. This study was conducted to develop hydrolysates with antioxidant effects from BSG proteins by enzymatic hydrolysis, and study BSG peptide antioxidant activities in relation to molecular structures. The BSG proteins were extracted by alkaline method with a protein content of 62.6% (w/w) and a protein recovery of 46.3%. The proteins were then hydrolyzed by selected proteases or protease combinations having different specificities. Resulting hydrolysates were analyzed for their molecular structures such as hydrolysis degree, amino acid composition, molecular weight and conformation, and their antioxidant effects were measured by reducing power, DPPH radical scavenging, ferrous chelating and superoxide radical scavenging assays. Hydrolysates prepared by alcalase and alcalase combined treatments with neutrase, flavourzyme and everlase showed the highest DPPH radical scavenging activities ranged between 72.6-74.9% at the hydrolysate concentration of 1.0 mg/mL. It could be due to specific activity of alcalase to produce amino acid sequences with greater DPPH radical scavenging potential. Similarly, high proton donation ability of the imidazole ring present in the side chain of histidine may have strong ability to scavenge the DPPH radical. -
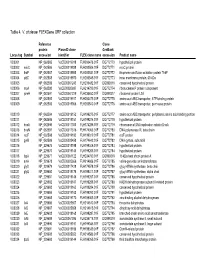
Table 4. V. Cholerae Flexgene ORF Collection
Table 4. V. cholerae FLEXGene ORF collection Reference Clone protein PlasmID clone GenBank Locus tag Symbol accession identifier FLEX clone name accession Product name VC0001 NP_062585 VcCD00019918 FLH200476.01F DQ772770 hypothetical protein VC0002 mioC NP_062586 VcCD00019938 FLH200506.01F DQ772771 mioC protein VC0003 thdF NP_062587 VcCD00019958 FLH200531.01F DQ772772 thiophene and furan oxidation protein ThdF VC0004 yidC NP_062588 VcCD00019970 FLH200545.01F DQ772773 inner membrane protein, 60 kDa VC0005 NP_062589 VcCD00061243 FLH236482.01F DQ899316 conserved hypothetical protein VC0006 rnpA NP_062590 VcCD00025697 FLH214799.01F DQ772774 ribonuclease P protein component VC0007 rpmH NP_062591 VcCD00061229 FLH236450.01F DQ899317 ribosomal protein L34 VC0008 NP_062592 VcCD00019917 FLH200475.01F DQ772775 amino acid ABC transporter, ATP-binding protein VC0009 NP_062593 VcCD00019966 FLH200540.01F DQ772776 amino acid ABC transproter, permease protein VC0010 NP_062594 VcCD00019152 FLH199275.01F DQ772777 amino acid ABC transporter, periplasmic amino acid-binding portion VC0011 NP_062595 VcCD00019151 FLH199274.01F DQ772778 hypothetical protein VC0012 dnaA NP_062596 VcCD00017363 FLH174286.01F DQ772779 chromosomal DNA replication initiator DnaA VC0013 dnaN NP_062597 VcCD00017316 FLH174063.01F DQ772780 DNA polymerase III, beta chain VC0014 recF NP_062598 VcCD00019182 FLH199319.01F DQ772781 recF protein VC0015 gyrB NP_062599 VcCD00025458 FLH174642.01F DQ772782 DNA gyrase, subunit B VC0016 NP_229675 VcCD00019198 FLH199346.01F DQ772783 hypothetical protein -

Supplemental Table 1A. Differential Gene Expression Profile of Adehcd40l and Adehnull Treated Cells Vs Untreated Cells
Supplemental Table 1a. Differential Gene Expression Profile of AdEHCD40L and AdEHNull treated cells vs Untreated Cells Fold change Regulation Fold change Regulation ([AdEHCD40L] vs ([AdEHCD40L] ([AdEHNull] vs ([AdEHNull] vs Probe Set ID [Untreated]) vs [Untreated]) [Untreated]) [Untreated]) Gene Symbol Gene Title RefSeq Transcript ID NM_001039468 /// NM_001039469 /// NM_004954 /// 203942_s_at 2.02 down 1.00 down MARK2 MAP/microtubule affinity-regulating kinase 2 NM_017490 217985_s_at 2.09 down 1.00 down BAZ1A fibroblastbromodomain growth adjacent factor receptorto zinc finger 2 (bacteria-expressed domain, 1A kinase, keratinocyte NM_013448 /// NM_182648 growth factor receptor, craniofacial dysostosis 1, Crouzon syndrome, Pfeiffer 203638_s_at 2.10 down 1.01 down FGFR2 syndrome, Jackson-Weiss syndrome) NM_000141 /// NM_022970 1570445_a_at 2.07 down 1.01 down LOC643201 hypothetical protein LOC643201 XM_001716444 /// XM_001717933 /// XM_932161 231763_at 3.05 down 1.02 down POLR3A polymerase (RNA) III (DNA directed) polypeptide A, 155kDa NM_007055 1555368_x_at 2.08 down 1.04 down ZNF479 zinc finger protein 479 NM_033273 /// XM_001714591 /// XM_001719979 241627_x_at 2.15 down 1.05 down FLJ10357 hypothetical protein FLJ10357 NM_018071 223208_at 2.17 down 1.06 down KCTD10 potassium channel tetramerisation domain containing 10 NM_031954 219923_at 2.09 down 1.07 down TRIM45 tripartite motif-containing 45 NM_025188 242772_x_at 2.03 down 1.07 down Transcribed locus 233019_at 2.19 down 1.08 down CNOT7 CCR4-NOT transcription complex, subunit 7 NM_013354 -

Studies on the Malting Properties and Proteolytic Enzyme Activities of a Nigerian Maize Variety by Agbo, Anthony Ogbonnia Na
STUDIES ON THE MALTING PROPERTIES AND PROTEOLYTIC ENZYME ACTIVITIES OF A NIGERIAN MAIZE VARIETY BY AGBO, ANTHONY OGBONNIA NAU/PG/Ph. D/2012487001P A DISSERTATION SUBMITTED TO THE DEPARTMENT OF APPLIED MICROBIOLOGY AND BREWING, FACULTY OF BIOSCENCES, NNAMDI AZIKIWE UNIVERSITY, AWKA IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE AWARD OF DEGREE OF DOCTOR OF PHILOSOPHY (Ph. D) IN INDUSTRIAL MICROBIOLOGY. SUPERVISOR: PROF. F. J. C. ODIBO MAY, 2021 i CERTIFICATION This is to certify that this research work titled “Studies on the Malting Properties and Proteolytic Enzyme Activities of Nigerian Maize Variety” was carried out by Agbo, Anthony Ogbonnia, with Registration number NAU/PG/Ph. D/2012487001P under the supervision of Prof. F. J. C. Odibo in the Department of Applied Microbiology and Brewing, Faculty of Biosciences, Nnamdi Azikiwe University, Awka Anambra State, Nigeria and that this work is original and has not been submitted in part or full to this University or any other Institution for the award of a degree or a Diploma. ……………………………. ………………………..... Agbo, Anthony Ogbonnia Date ii APPROVAL This Dissertation titled “Studies on the Malting Properties and Proteolytic Enzyme Activities of a Nigerian Maize Variety” by Agbo, Anthony Ogbonnia with Registration Number NAU/PG/Ph. D/2012487001P has been examined and approved for the award of Doctor of Philosophy (Ph.D) in Industrial Microbiology in the Department of Applied Microbiology and Brewing, Faculty of Biosciences, Nnamdi Azikiwe University, Awka. .…………………………………… ……………………………… Prof. F. J. C. Odibo Date (Supervisor) …………………………………… ……………………………… Prof. E. I. Chukwura Date (HOD, Applied Microbiology and Brewing) …………………………………… ……………………………… Dr. S. C. Onuorah Date (Postgraduate Sub Dean) …………………………………. …………………………...... Prof. S. -

WO 2018/187754 Al 11 October 2018 (11.10.2018) W !P O PCT
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization International Bureau (10) International Publication Number (43) International Publication Date WO 2018/187754 Al 11 October 2018 (11.10.2018) W !P O PCT (51) International Patent Classification: (74) Agent: HAN, Jong-Jin et al; Cooley LLP, 1299 Penn syl AOlH l/00 (2006.01) C12N 15/12 (2006.01) vania Avenue, NW, Suite 700, Washington, District of C o AOlH S/00 (2018.01) C12N 15/63 (2006.01) lumbia 20004 (US). A23J3/04 (2006.01) C12N 15/82 (2006.01) (81) Designated States (unless otherwise indicated, for every C12N 15/11 (2006.01) kind of national protection available): AE, AG, AL, AM, (21) International Application Number: AO, AT, AU, AZ, BA, BB, BG, BH, BN, BR, BW, BY, BZ, PCT/US2018/026572 CA, CH, CL, CN, CO, CR, CU, CZ, DE, DJ, DK, DM, DO, DZ, EC, EE, EG, ES, FI, GB, GD, GE, GH, GM, GT, HN, (22) International Filing Date: HR, HU, ID, IL, IN, IR, IS, JO, JP, KE, KG, KH, KN, KP, 06 April 2018 (06.04.2018) KR, KW, KZ, LA, LC, LK, LR, LS, LU, LY, MA, MD, ME, (25) Filing Language: English MG, MK, MN, MW, MX, MY, MZ, NA, NG, NI, NO, NZ, OM, PA, PE, PG, PH, PL, PT, QA, RO, RS, RU, RW, SA, (26) Publication Language: English SC, SD, SE, SG, SK, SL, SM, ST, SV, SY,TH, TJ, TM, TN, (30) Priority Data: TR, TT, TZ, UA, UG, US, UZ, VC, VN, ZA, ZM, ZW. -

MOL #82305 TITLE PAGE Title: Induced CYP3A4 Expression In
Downloaded from molpharm.aspetjournals.org at ASPET Journals on September 28, 2021 1 This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. -

Peptide-Based Probes to Monitor Cysteine-Mediated Protein Activities
Peptide-Based Probes To Monitor Cysteine-Mediated Protein Activities Author: Nicholas Pace Persistent link: http://hdl.handle.net/2345/bc-ir:104128 This work is posted on eScholarship@BC, Boston College University Libraries. Boston College Electronic Thesis or Dissertation, 2015 Copyright is held by the author, with all rights reserved, unless otherwise noted. Boston College The Graduate School of Arts and Sciences Department of Chemistry PEPTIDE-BASED PROBES TO MONITOR CYSTEINE-MEDIATED PROTEIN ACTIVITIES Dissertation by NICHOLAS J. PACE submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy May 2015 © copyright by NICHOLAS J. PACE 2015 Peptide-Based Probes to Monitor Cysteine-Mediated Protein Activities by Nicholas J. Pace Thesis Advisor: Eranthie Weerapana Abstract Cysteine residues are known to perform an array of functional roles in proteins, including nucleophilic and redox catalysis, regulation, metal binding, and structural stabilization, on proteins across diverse functional classes. These functional cysteine residues often display hyperreactivity, and electrophilic chemical probes can be utilized to modify reactive cysteines and modulate their protein functions. A particular focus was placed on three peptide-based cysteine-reactive chemical probes (NJP2, NJP14. and NJP15) and their particular biological applications. NJP2 was discovered to be an apoptotic cell-selective inhibitor of glutathione S-transferase omega 1 and shows additional utility as an imaging agent of apoptosis. NJP14 aided in the development of a chemical-proteomic platform to detect Zn2+-cysteine complexes. This platform identified both known and unknown Zn2+-cysteine complexes across diverse protein classes and should serve as a valuable complement to existing methods to characterize functional Zn2+-cysteine complexes. -

Clpxp-Mediated Proteolysis in Resculpting the Proteome After DNA Damage
The Role of ClpXP-mediated Proteolysis in Resculpting the Proteome after DNA Damage by Saskia B. Neher B.S. Biochemistry University of Oregon, 2000 SUBMITTED TO THE DEPARTMENT OF BIOLOGY IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY AT THE MASSACHUSETTS INSTITUTE OF TECHNOLOGY JUNE 2005 © 2005 Saskia B. Neher. All Rights Reserved The author herby grants to MIT permission to reproduce and to distribute publicly paper and electronic copies of this thesis document in whole or in part. Signature of Author: .- Department of Biology X/ (13 May 2005) Certified by: Tania A. Baker Professor of Biology Thesis Supervisor Accepted by: Stephen P. Bell Professor of Biology Chair, Biology Graduate Committee &Votiy a ,4b. .·. 1___1_11_ _ ·_··_ I· _·____ The Role of ClpXP-mediated Proteolysis in Resculpting the Proteome after DNA Damage By Saskia B. Neher Submitted to the Department of Biology on May 20, 2005 in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy At the Massachusetts Institute of Technology ABSTRACT When faced with environmental assaults, E. coli can take extreme measures to survive. For example, starving bacteria consume their own proteins, and bacteria with severe DNA damage introduce mutations into their genomes. These survival tactics require restructuring of the bacterial proteomic landscape. To reshape the proteome, bacteria alter both protein synthesis and protein degradation. For important regulatory proteins and proteins potentially harmful to the cell under non-stress conditions, these changes must be environmentally responsive and specific. This thesis explores the role of the ClpXP protease in the response to DNA damage.