Fire Weather Climatology Dataset for Victoria
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

MINUTES AAA VIC Division Meeting
MINUTES AAA VIC Division Meeting Wednesday 7 August 2019 08:30 – 15:30 Holiday Inn Melbourne Airport Grand Centre Room, 10-14 Centre Road, Melbourne Airport Chair: Katie Cooper Attendees & Apologies: Please see attached 1. Introduction from Victorian Chair, Apologies, Minutes and Chair’s Report (Katie Cooper) • Introduced Daniel Gall, Deputy Chair for Vic Division • Provided overview of speakers for the day. • Dinner held previous evening which was a great way to meet and network – feedback welcome on if it is something you would like to see as an ongoing event Chairman’s Report Overview – • Board and Stakeholder dinner in Canberra with various industry and political leader and influences in attendance • AAA represented at the ACI Asia Pacific Conference and World AGM in Hong Kong • AAA Pavement & Lighting Forum held in Melbourne CBD with excellent attendance and positive feedback on its value to the industry • June Board Meeting in Brisbane coinciding with Qld Div meeting and dinner • Announcement of Federal Government $100M for regional airports • For International Airports, the current revisions of the Port Operators Guide for new and redeveloping ports which puts a lot of their costs onto industry is gaining focus from those affected industry members • MOS 139 changes update • Airport Safety Week in October • National Conference in November on the Gold Coast incl Women in Airports Forum • Launch of the new Corporate Member Advisory Panel (CMAP) which will bring together a panel of corporate members to gain feedback on issues impacting the AAA and wider airport sector and chaired by the AAA Chairman Thanks to Smiths Detection as the Premium Division Meetings Partner 2. -

Regional Development Victoria Regional Development Victoria
Regional Development victoRia Annual Report 12-13 RDV ANNUAL REPORT 12-13 CONTENTS PG1 CONTENTS Highlights 2012-13 _________________________________________________2 Introduction ______________________________________________________6 Chief Executive Foreword 6 Overview _________________________________________________________8 Responsibilities 8 Profile 9 Regional Policy Advisory Committee 11 Partners and Stakeholders 12 Operation of the Regional Policy Advisory Committee 14 Delivering the Regional Development Australia Initiative 15 Working with Regional Cities Victoria 16 Working with Rural Councils Victoria 17 Implementing the Regional Growth Fund 18 Regional Growth Fund: Delivering Major Infrastructure 20 Regional Growth Fund: Energy for the Regions 28 Regional Growth Fund: Supporting Local Initiatives 29 Regional Growth Fund: Latrobe Valley Industry and Infrastructure Fund 31 Regional Growth Fund: Other Key Initiatives 33 Disaster Recovery Support 34 Regional Economic Growth Project 36 Geelong Advancement Fund 37 Farmers’ Markets 37 Thinking Regional and Rural Guidelines 38 Hosting the Organisation of Economic Cooperation and Development 38 2013 Regional Victoria Living Expo 39 Good Move Regional Marketing Campaign 40 Future Priorities 2013-14 42 Finance ________________________________________________________ 44 RDV Grant Payments 45 Economic Infrastructure 63 Output Targets and Performance 69 Revenue and Expenses 70 Financial Performance 71 Compliance 71 Legislation 71 Front and back cover image shows the new $52.6 million Regional and Community Health Hub (REACH) at Deakin University’s Waurn Ponds campus in Geelong. Contact Information _______________________________________________72 RDV ANNUAL REPORT 12-13 RDV ANNUAL REPORT 12-13 HIGHLIGHTS PG2 HIGHLIGHTS PG3 September 2012 December 2012 > Announced the date for the 2013 Regional > Supported the $46.9 million Victoria Living Expo at the Good Move redevelopment of central Wodonga with campaign stand at the Royal Melbourne $3 million from the Regional Growth Show. -

VFR Flight Into Dark Night Conditions and Loss of Control Involving Piper PA-28-180, VH-POJ
VFR flight into dark night Insertconditions document and loss titleof control involving Piper PA-28-180, VH-POJ Location31 km north | Date of Horsham Airport, Victoria | 15 August 2011 ATSB Transport Safety Report Investigation [InsertAviation Mode] Occurrence Occurrence Investigation Investigation XX-YYYY-####AO -2011-10 0 Final – 3 December 2013 Released in accordance with section 25 of the Transport Safety Investigation Act 2003 Publishing information Published by: Australian Transport Safety Bureau Postal address: PO Box 967, Civic Square ACT 2608 Office: 62 Northbourne Avenue Canberra, Australian Capital Territory 2601 Telephone: 1800 020 616, from overseas +61 2 6257 4150 (24 hours) Accident and incident notification: 1800 011 034 (24 hours) Facsimile: 02 6247 3117, from overseas +61 2 6247 3117 Email: [email protected] Internet: www.atsb.gov.au © Commonwealth of Australia 2013 Ownership of intellectual property rights in this publication Unless otherwise noted, copyright (and any other intellectual property rights, if any) in this publication is owned by the Commonwealth of Australia. Creative Commons licence With the exception of the Coat of Arms, ATSB logo, and photos and graphics in which a third party holds copyright, this publication is licensed under a Creative Commons Attribution 3.0 Australia licence. Creative Commons Attribution 3.0 Australia Licence is a standard form license agreement that allows you to copy, distribute, transmit and adapt this publication provided that you attribute the work. The ATSB’s preference is that you attribute this publication (and any material sourced from it) using the following wording: Source: Australian Transport Safety Bureau Copyright in material obtained from other agencies, private individuals or organisations, belongs to those agencies, individuals or organisations. -
The Table of Services (PDF)
APPENDIX 1: TABLE OF SERVICES Proposed Service Contract type Availability Brief Service Description Airframe Aircraft Type Nominated Operational Base Firebombing Delivery System Passenger Carriage Fuelling Service Period Approximate timing Specimen Contract applicable Schedules Additional Information ID Primary / Absolute / Partial RW / FW Type 1 / Type 2 / Type 3 Tank / Bucket / (Bucket) / Long line bucket / Tank or Required / Optional Wet-A Hire / Wet- (in addition to Schedules 1, 2, 3,4, & 5) Secondary bucket / Tank (preferred) or Bucket B Hire / Dry Hire (Note 7) (Note 11) (Note 1) (Note 2) (Note 5) (Note 9) (Note 10) (Note 3) (Note 4) (Note 4) (Note 6) (Note 8) AAS Firefighter & Cargo Transport RW21302 Primary Absolute ROTARY WING Type 3 Moorabbin Airport, Victoria Bucket (Optional) Required Wet-B 14 weeks Dec-Mar Schedules A & B Burning (Note 14) Firebombing (optional) AAS Firefighter & Cargo Transport RW21303 Primary Absolute ROTARY WING Type 3 Ovens helibase, Victoria (Note A) Bucket Required Wet-B 14 weeks Dec-Mar Schedules A & B Firebombing Burning (Note 14) AAS Firefighter & Cargo Transport RW21304 Primary Absolute ROTARY WING Type 3 Bairnsdale, Victoria Bucket Required Wet-B 14 weeks Dec-Mar Schedules A & B Firebombing Burning (Note 14) AAS RW21305 Primary Absolute ROTARY WING Type 3 Bendigo Airport, Victoria (Bucket) Required Wet-B 14 weeks Dec-Mar Schedules B Burning (preferred) (Note 14) Airborne Information Gathering (AIG) (Note 16) This Service requires a specific configuration to support regular 'airborne information gathering' operations (Refer to Section 2.1 of Part B RW21307 Primary Absolute AAS ROTARY WING Type 3 Moorabbin Airport, Victoria (Bucket) Required Wet-B 14 weeks Dec-Mar Schedules B & C in the Invitation to Tender document). -

Airport Categorisation List
UNCLASSIFIED List of Security Controlled Airport Categorisation September 2018 *Please note that this table will continue to be updated upon new category approvals and gazettal Category Airport Legal Trading Name State Category Operations Other Information Commencement CATEGORY 1 ADELAIDE Adelaide Airport Ltd SA 1 22/12/2011 BRISBANE Brisbane Airport Corporation Limited QLD 1 22/12/2011 CAIRNS Cairns Airport Pty Ltd QLD 1 22/12/2011 CANBERRA Capital Airport Group Pty Ltd ACT 1 22/12/2011 GOLD COAST Gold Coast Airport Pty Ltd QLD 1 22/12/2011 DARWIN Darwin International Airport Pty Limited NT 1 22/12/2011 Australia Pacific Airports (Melbourne) MELBOURNE VIC 1 22/12/2011 Pty. Limited PERTH Perth Airport Pty Ltd WA 1 22/12/2011 SYDNEY Sydney Airport Corporation Limited NSW 1 22/12/2011 CATEGORY 2 BROOME Broome International Airport Pty Ltd WA 2 22/12/2011 CHRISTMAS ISLAND Toll Remote Logistics Pty Ltd WA 2 22/12/2011 HOBART Hobart International Airport Pty Limited TAS 2 29/02/2012 NORFOLK ISLAND Norfolk Island Regional Council NSW 2 22/12/2011 September 2018 UNCLASSIFIED UNCLASSIFIED PORT HEDLAND PHIA Operating Company Pty Ltd WA 2 22/12/2011 SUNSHINE COAST Sunshine Coast Airport Pty Ltd QLD 2 29/06/2012 TOWNSVILLE AIRPORT Townsville Airport Pty Ltd QLD 2 19/12/2014 CATEGORY 3 ALBURY Albury City Council NSW 3 22/12/2011 ALICE SPRINGS Alice Springs Airport Pty Limited NT 3 11/01/2012 AVALON Avalon Airport Australia Pty Ltd VIC 3 22/12/2011 Voyages Indigenous Tourism Australia NT 3 22/12/2011 AYERS ROCK Pty Ltd BALLINA Ballina Shire Council NSW 3 22/12/2011 BRISBANE WEST Brisbane West Wellcamp Airport Pty QLD 3 17/11/2014 WELLCAMP Ltd BUNDABERG Bundaberg Regional Council QLD 3 18/01/2012 CLONCURRY Cloncurry Shire Council QLD 3 29/02/2012 COCOS ISLAND Toll Remote Logistics Pty Ltd WA 3 22/12/2011 COFFS HARBOUR Coffs Harbour City Council NSW 3 22/12/2011 DEVONPORT Tasmanian Ports Corporation Pty. -

St Helens Aerodrome Assess Report
MCa Airstrip Feasibility Study Break O’ Day Council Municipal Management Plan December 2013 Part A Technical Planning & Facility Upgrade Reference: 233492-001 Project: St Helens Aerodrome Prepared for: Break Technical Planning and Facility Upgrade O’Day Council Report Revision: 1 16 December 2013 Document Control Record Document prepared by: Aurecon Australia Pty Ltd ABN 54 005 139 873 Aurecon Centre Level 8, 850 Collins Street Docklands VIC 3008 PO Box 23061 Docklands VIC 8012 Australia T +61 3 9975 3333 F +61 3 9975 3444 E [email protected] W aurecongroup.com A person using Aurecon documents or data accepts the risk of: a) Using the documents or data in electronic form without requesting and checking them for accuracy against the original hard copy version. b) Using the documents or data for any purpose not agreed to in writing by Aurecon. Report Title Technical Planning and Facility Upgrade Report Document ID 233492-001 Project Number 233492-001 File St Helens Aerodrome Concept Planning and Facility Upgrade Repot Rev File Path 0.docx Client Break O’Day Council Client Contact Rev Date Revision Details/Status Prepared by Author Verifier Approver 0 05 April 2013 Draft S.Oakley S.Oakley M.Glenn M. Glenn 1 16 December 2013 Final S.Oakley S.Oakley M.Glenn M. Glenn Current Revision 1 Approval Author Signature SRO Approver Signature MDG Name S.Oakley Name M. Glenn Technical Director - Title Senior Airport Engineer Title Airports Project 233492-001 | File St Helens Aerodrome Concept Planning and Facility Upgrade Repot Rev 1.docx | -

Seasonal Climate Summary for the Southern Hemisphere (Autumn 2018): a Weak La Nin˜A Fades, the Austral Autumn Remains Warmer and Drier
CSIRO PUBLISHING Journal of Southern Hemisphere Earth Systems Science, 2020, 70, 328–352 Seasonal Climate Summary https://doi.org/10.1071/ES19039 Seasonal climate summary for the southern hemisphere (autumn 2018): a weak La Nin˜a fades, the austral autumn remains warmer and drier Bernard ChapmanA,B and Katie RosemondA,B ABureau of Meteorology, GPO Box 413, Brisbane, Qld 4001, Australia. BCorresponding authors. Email: [email protected]; [email protected] Abstract. This is a summary of the austral autumn 2018 atmospheric circulation patterns and meteorological indices for the southern hemisphere, including an exploration of the season’s rainfall and temperature for the Australian region. The weak La Nin˜a event during summer 2017–18 was in retreat as the southern hemisphere welcomed the austral autumn, and before midseason, it had faded. With the El Nin˜o Southern Oscillation and the Indian Ocean Dipole in neutral phases, their influence on the climate was weakened. Warmer than average sea surface temperatures dominated much of the subtropical South Pacific Ocean and provided favourable conditions for the formation of a rare subtropical cyclone over the southeast Pacific Ocean in May. The southern hemisphere sea ice extent was slightly below the autumn seasonal average. The southern hemisphere overall during autumn was drier and warmer than the seasonal average. The season brought warmer than average temperatures and average rains to parts of the continents of Africa and South America. Australia recorded its fourth-warmest autumn, partly due to an intense, extensive and persistent heatwave, which occurred during the midseason. An extraordinary and record-breaking rainfall event occurred over Tasmania’s southeast, under the influence of a negative Southern Annular Mode. -

2010-11 Victorian Floods Rainfall and Streamflow Assessment Project
Review by: 2010-11 Victorian Floods Rainfall and Streamflow Assessment Project December 2012 ISO 9001 QEC22878 SAI Global Department of Sustainability and Environment 2010-11 Victorian Floods – Rainfall and Streamflow Assessment DOCUMENT STATUS Version Doc type Reviewed by Approved by Date issued v01 Report Warwick Bishop 02/06/2012 v02 Report Michael Cawood Warwick Bishop 07/11/2012 FINAL Report Ben Tate Ben Tate 07/12/2012 PROJECT DETAILS 2010-11 Victorian Floods – Rainfall and Streamflow Project Name Assessment Client Department of Sustainability and Environment Client Project Manager Simone Wilkinson Water Technology Project Manager Ben Tate Report Authors Ben Tate Job Number 2106-01 Report Number R02 Document Name 2106R02_FINAL_2010-11_VIC_Floods.docx Cover Photo: Flooding near Kerang in January 2011 (source: www.weeklytimesnow.com.au). Copyright Water Technology Pty Ltd has produced this document in accordance with instructions from Department of Sustainability and Environment for their use only. The concepts and information contained in this document are the copyright of Water Technology Pty Ltd. Use or copying of this document in whole or in part without written permission of Water Technology Pty Ltd constitutes an infringement of copyright. Water Technology Pty Ltd does not warrant this document is definitive nor free from error and does not accept liability for any loss caused, or arising from, reliance upon the information provided herein. 15 Business Park Drive Notting Hill VIC 3168 Telephone (03) 9558 9366 Fax (03) 9558 9365 ACN No. 093 377 283 ABN No. 60 093 377 283 2106-01 / R02 FINAL - 07/12/2012 ii Department of Sustainability and Environment 2010-11 Victorian Floods – Rainfall and Streamflow Assessment GLOSSARY Annual Exceedance Refers to the probability or risk of a flood of a given size occurring or being exceeded in any given year. -

FLOT.327 Final Report
final reportp Project code: FLOT.327 Prepared by: Mr Tim Byrne, Dr Simon Lott, Mr Peter Binns, Dr John Gaughan, Mrs Christine Killip, Mr Frank Quintarelli, Ms Natalie Leishman E.A. Systems Pty Limited, The University of Queensland, Katestone Environmental Pty Limited Date published: February 2005 ISBN: 9781741917529 PUBLISHED BY Meat & Livestock Australia Limited Locked Bag 991 NORTH SYDNEY NSW 2059 Reducing the Risk of Heat Load for the Australian Feedlot Industry Meat & Livestock Australia acknowledges the matching funds provided by the Australian Government to support the research and development detailed in this publication. This publication is published by Meat & Livestock Australia Limited ABN 39 081 678 364 (MLA). Care is taken to ensure the accuracy of the information contained in this publication. However MLA cannot accept responsibility for the accuracy or completeness of the information or opinions contained in the publication. You should make your own enquiries before making decisions concerning your interests. Reproduction in whole or in part of this publication is prohibited without prior written consent of MLA. Page 1 of 69 pages Table of Contents Abstract ........................................................................................................................................................4 Executive Summary ....................................................................................................................................5 1. Introduction .......................................................................................................................................6 -
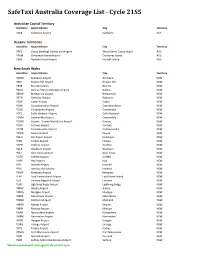
Safetaxi Australia Coverage List - Cycle 21S5
SafeTaxi Australia Coverage List - Cycle 21S5 Australian Capital Territory Identifier Airport Name City Territory YSCB Canberra Airport Canberra ACT Oceanic Territories Identifier Airport Name City Territory YPCC Cocos (Keeling) Islands Intl Airport West Island, Cocos Island AUS YPXM Christmas Island Airport Christmas Island AUS YSNF Norfolk Island Airport Norfolk Island AUS New South Wales Identifier Airport Name City Territory YARM Armidale Airport Armidale NSW YBHI Broken Hill Airport Broken Hill NSW YBKE Bourke Airport Bourke NSW YBNA Ballina / Byron Gateway Airport Ballina NSW YBRW Brewarrina Airport Brewarrina NSW YBTH Bathurst Airport Bathurst NSW YCBA Cobar Airport Cobar NSW YCBB Coonabarabran Airport Coonabarabran NSW YCDO Condobolin Airport Condobolin NSW YCFS Coffs Harbour Airport Coffs Harbour NSW YCNM Coonamble Airport Coonamble NSW YCOM Cooma - Snowy Mountains Airport Cooma NSW YCOR Corowa Airport Corowa NSW YCTM Cootamundra Airport Cootamundra NSW YCWR Cowra Airport Cowra NSW YDLQ Deniliquin Airport Deniliquin NSW YFBS Forbes Airport Forbes NSW YGFN Grafton Airport Grafton NSW YGLB Goulburn Airport Goulburn NSW YGLI Glen Innes Airport Glen Innes NSW YGTH Griffith Airport Griffith NSW YHAY Hay Airport Hay NSW YIVL Inverell Airport Inverell NSW YIVO Ivanhoe Aerodrome Ivanhoe NSW YKMP Kempsey Airport Kempsey NSW YLHI Lord Howe Island Airport Lord Howe Island NSW YLIS Lismore Regional Airport Lismore NSW YLRD Lightning Ridge Airport Lightning Ridge NSW YMAY Albury Airport Albury NSW YMDG Mudgee Airport Mudgee NSW YMER Merimbula -
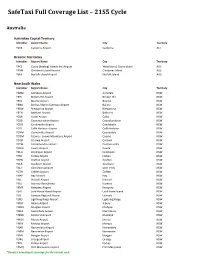
Safetaxi Full Coverage List – 21S5 Cycle
SafeTaxi Full Coverage List – 21S5 Cycle Australia Australian Capital Territory Identifier Airport Name City Territory YSCB Canberra Airport Canberra ACT Oceanic Territories Identifier Airport Name City Territory YPCC Cocos (Keeling) Islands Intl Airport West Island, Cocos Island AUS YPXM Christmas Island Airport Christmas Island AUS YSNF Norfolk Island Airport Norfolk Island AUS New South Wales Identifier Airport Name City Territory YARM Armidale Airport Armidale NSW YBHI Broken Hill Airport Broken Hill NSW YBKE Bourke Airport Bourke NSW YBNA Ballina / Byron Gateway Airport Ballina NSW YBRW Brewarrina Airport Brewarrina NSW YBTH Bathurst Airport Bathurst NSW YCBA Cobar Airport Cobar NSW YCBB Coonabarabran Airport Coonabarabran NSW YCDO Condobolin Airport Condobolin NSW YCFS Coffs Harbour Airport Coffs Harbour NSW YCNM Coonamble Airport Coonamble NSW YCOM Cooma - Snowy Mountains Airport Cooma NSW YCOR Corowa Airport Corowa NSW YCTM Cootamundra Airport Cootamundra NSW YCWR Cowra Airport Cowra NSW YDLQ Deniliquin Airport Deniliquin NSW YFBS Forbes Airport Forbes NSW YGFN Grafton Airport Grafton NSW YGLB Goulburn Airport Goulburn NSW YGLI Glen Innes Airport Glen Innes NSW YGTH Griffith Airport Griffith NSW YHAY Hay Airport Hay NSW YIVL Inverell Airport Inverell NSW YIVO Ivanhoe Aerodrome Ivanhoe NSW YKMP Kempsey Airport Kempsey NSW YLHI Lord Howe Island Airport Lord Howe Island NSW YLIS Lismore Regional Airport Lismore NSW YLRD Lightning Ridge Airport Lightning Ridge NSW YMAY Albury Airport Albury NSW YMDG Mudgee Airport Mudgee NSW YMER -

Vr6an Qrowtli Strategy
I I I I Vr6an qrowtli I I Strategy I I 1996 I I I I I I I I I I I CITY PLANNIII6 I ·~ I INTRODUCTION · "~~j~j~~~~~Njjjf I M0044244 The City of Greater Geelong Urban Growth Strategy was I prepared for Council by planning consultants Perrott Lyon . I Mathieson Pty Ltd during 1995 and 1996 to provide advice on the areas considered most suitable for urban I development to accommodate Geelong's expected growth up until the year 2020. On the most optimistic population I projections available, the consultants have catered for an I additional 71,000 persons or some 26,000 households. I In undertaking their work, the consultants have had the benefit of many background reports and information I . produceq over past years by the (former) Geelong ' . Regional Commission, together with more recent planning I studies undertaken either by or on behalf of Council (e.g. I North Eastern Area Strategic Land· Use Plan, Mt Duneed Armstrong Creek Urban Development rstudy; Residential I Lot Supply Report and Inventory of Industrial Lots). I The Urban Growth Strategy was· ·exhibited: for a 4 month period during 1996 at which time wide publicity was given I of its availability including an invitation for interested or I affected persons to make a submission. Preparation of this Strategy and its exhibition was also coordinated with I Council's Arterial Roads Study. I The exhibition comprised 8 background Discussion Papers and an overall Strategy report which were made publicly I . available at Council's Service Centres and throughout local /,.--- -- libraries.