Unicode Emoji Technical Reports
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Hearsay in the Smiley Face: Analyzing the Use of Emojis As Evidence Erin Janssen St
St. Mary's Law Journal Volume 49 | Number 3 Article 5 6-2018 Hearsay in the Smiley Face: Analyzing the Use of Emojis as Evidence Erin Janssen St. Mary's University School of Law Follow this and additional works at: https://commons.stmarytx.edu/thestmaryslawjournal Part of the Civil Procedure Commons, Courts Commons, Criminal Procedure Commons, Evidence Commons, Internet Law Commons, Judges Commons, Law and Society Commons, Legal Remedies Commons, and the State and Local Government Law Commons Recommended Citation Erin Janssen, Hearsay in the Smiley Face: Analyzing the Use of Emojis as Evidence, 49 St. Mary's L.J. 699 (2018). Available at: https://commons.stmarytx.edu/thestmaryslawjournal/vol49/iss3/5 This Article is brought to you for free and open access by the St. Mary's Law Journals at Digital Commons at St. Mary's University. It has been accepted for inclusion in St. Mary's Law Journal by an authorized editor of Digital Commons at St. Mary's University. For more information, please contact [email protected]. Janssen: Analyzing the Use of Emojis as Evidence COMMENT HEARSAY IN THE SMILEY FACE: ANALYZING THE USE OF EMOJIS AS EVIDENCE ERIN JANSSEN* I. Introduction ............................................................................................ 700 II. Background ............................................................................................. 701 A. Federal Rules of Evidence ............................................................. 701 B. Free Speech and Technology ....................................................... -

Emoji Article
20 Headnotes l D allas B ar A s s o c iatio n A pr il 2019 Do You Speak Emoji? District of Michigan determined that uses of emojis as evidence came dur- used by the plaintiffs in emails and BY CAROL PAYNE AND TERAH MOXLEY an emoticon—a “-D,” which the court ing a 2015 trial involving Silk Road, self-assessments as evidence that the It all started with a . Throw in a viewed as a wide open-mouth smile— an online black market. In that case, plaintiffs did not subjectively believe , , , , , and a and two would- “did not materially alter the meaning the federal district judge presiding over their working conditions were abusive. be renters in Tel Aviv found themselves of a text message” included in an affi- the trial sustained an objection by the So, what does all this mean? For on the wrong side of a judgment in davit in support of a search warrant. defense after the prosecutor read text one thing, employers should have favor of a landlord who took a vacant Conversely, in a 2014 opinion from messages without mentioning smiley- strong electronic communications apartment off the market based on a Michigan appellate court, a similar face emojis contained in the messages. policies that explicitly cover symbols enthusiastic text messages he received emoticon—“:P”—sank a defamation The judge instructed the jury that it like emojis and emoticons (and even from the prospective tenants. After the case brought by a public official. In should take note of any such symbols GIFs, hashtags, and memes). -

Rave-Culture-And-Thatcherism-Sam
Altered Perspectives: UK Rave Culture, Thatcherite Hegemony and the BBC Sam Bradpiece, University of Bristol Image 1: Boys Own Magazine (London), Spring 1988 1 Contents Introduction……………………………………………………………………………………………………...……… 7 Chapter 1. The Rave as a Counter-Hegemonic Force: The Spatial Element…….…………….13 Chapter 2. The Rave as a Counter Hegemonic Force: Confirmation and Critique..…..…… 20 Chapter 3. The BBC and the Rave: An Agent of Moral Panic……………………………………..… 29 Conclusion…………………………………………………………………………………………………………….... 37 Appendices…………………………………………………………………………………………………………...... 39 Bibliography………………………………………………………………………………………………………...... 50 2 ‘You cannot break it! The bonding between the ravers is too strong! The police and councils will never tear us apart.’ In-ter-dance Magazine1 1 ‘Letters’, In-Ter-Dance (Worthing), Jul. 1993. 3 Introduction Rave culture arrived in Britain in the late 1980s, almost a decade into the premiership of Margaret Thatcher, and reached its zenith in the mid 1990s. Although academics contest the definition of the term 'rave’, Sheila Henderson’s characterization encapsulates the basic formula. She describes raves as having ‘larger than average venues’, ‘music with 120 beats per minute or more’, ‘ubiquitous drug use’, ‘distinctive dress codes’ and ‘extensive special effects’.2 Another significant ‘defining’ feature of the rave subculture was widespread consumption of the drug methylenedioxyphenethylamine (MDMA), otherwise known as Ecstasy.3 In 1996, the government suggested that over one million Ecstasy tablets were consumed every week.4 Nicholas Saunders claims that at the peak of the drug’s popularity, 10% of 16-25 year olds regularly consumed Ecstasy.5 The mass media has been instrumental in shaping popular understanding of this recent phenomenon. The ideological dominance of Thatcherism, in the 1980s and early 1990s, was reflected in the one-sided discourse presented by the British mass media. -

Perception of Meaning and Usage Motivations of Emoticons Among Americans and Chinese Users
Rochester Institute of Technology RIT Scholar Works Theses 9-14-2004 Perception of meaning and usage motivations of emoticons among Americans and Chinese users Yujiao Wang Follow this and additional works at: https://scholarworks.rit.edu/theses Recommended Citation Wang, Yujiao, "Perception of meaning and usage motivations of emoticons among Americans and Chinese users" (2004). Thesis. Rochester Institute of Technology. Accessed from This Thesis is brought to you for free and open access by RIT Scholar Works. It has been accepted for inclusion in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact [email protected]. Emoticons Usage and Meaning 1 EMOTICONS USAGE AND MEANING Perception of Meaning and Usage Motivations of Emoticons Among Americans and Chinese Users By Yujiao Wang Paper Presented in Partial Fulfillment of the Master of Science Degree in Communication & Media Technologies September 14, 2004 Emoticons Usage and Meaning 2 The following members ofthe thesis committee approve the thesis of Yujiao Wang presented on September 14,2004. Dr. Susan B. Barnes Department ofCommunication Thesis Advisor Dr. Evelyn Rozanski B. Thomas Golisano College of Computing and Information Sciences Thesis Advisor Dr. Bruce Austin Department ofCommunication Chairman Emoticons Usage and Meaning 3 Thesis Author Permission Statement Title of thesis or dissertation: Perception of Meaning and Usage Motivations of Emoticons Among Americans and Chinese Users Name of author: Yujiao Wang Degree: Master of Science Program: Communication Media and Technologies College: College of Liberal Arts I understand that I must submit a print copy of my thesis or dissertation to the RIT Archives, per current RIT guidelines for the completion of my degree. -

Baby Raves: Youth, Adulthood and Ageing in Contemporary British EDM Culture
Baby Raves: Youth, Adulthood and Ageing in Contemporary British EDM Culture Feature Article Zoe Armour De Montfort University (UK) Abstract This article begins with a reconsideration of the parameters ofage in translocal EDM sound system and (super)club culture through the conceptualisation of a fluid multigenerationality in which attendees at EDM-events encompass a spectrum of ages from 0–75 years. Since the 1980s, it remains the case that the culture is fuelled through a constant influx of newcomers who are predominantly emerging youth, yet there are post-youth members in middle adulthood and later life that are also a growing body that continues to attend EDM-events. In this context, the baby rave initiative (2004–present) has capitalised on a gap in the family entertainment market and created a new chapter in (super)club and festival culture. I argue that the event is a catalyst for live heritage in which the accompanying children (aged from 0–12 years) temporarily become the beneficiaries of their parent’s attendee heritage and performance of an unauthored heritage. Keywords: fluid multigenerationality, EDM-family, baby rave, live heritage, unauthored heritage Zoe Armour is completing a PhD in electronic dance music culture. Her work is interdisciplinary and draws from the fields of cultural sociology, popular music, memory studies, media and communication and film. She is the author of two book chapters on Ageing Clubbers and the Internet and the British Free Party Counterculture in the late 1990s. She is a member of the Media Discourse Centre, IASPM and follows the group for Subcultures, Popular Music and Social Change. -

CREATIVITY and INNOVATION in the MUSIC INDUSTRY Creativity and Innovation in the Music Industry
CREATIVITY AND INNOVATION IN THE MUSIC INDUSTRY Creativity and Innovation in the Music Industry by PETER TSCHMUCK Institute of Culture Management and Culture Science, University of Music and Performing Arts Vienna, Austria A C.I.P. Catalogue record for this book is available from the Library of Congress. ISBN-10 1-4020-4274-4 (HB) ISBN-13 978-1-4020-4274-4 (HB) ISBN-10 1-4020-4275-2 (e-book) ISBN-13 978-1-4020-4275-1 (e-book) Published by Springer, P.O. Box 17, 3300 AA Dordrecht, The Netherlands. www.springer.com Printed on acid-free paper Printed with the support of the Austrian Ministery of Education, Science, and Culture All Rights Reserved © 2006 Springer No part of this work may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, microfilming, recording or otherwise, without written permission from the Publisher, with the exception of any material supplied specifically for the purpose of being entered and executed on a computer system, for exclusive use by the purchaser of the work. Printed in the Netherlands. TABLE OF CONTENTS Preface ix Acknowledgements xi Introduction xiii 1. Aim and Structure of the Book xiii 2. Implications of Culture Institutions Studies xvi Chapter 1: The Emergence of the Phonographic Industry 1 Within the Music Industry 1. The Phonograph as Business Machine 1 2. “Coin-in-the-Slot:”-Machine 6 3. Records and Gramophones 9 4. “Herr Doctor Brahms Plays the Piano” 15 Chapter 2: The Music Industry Boom until 1920 19 1. -

Homegrown Issue 74
REGULARS !"th Century German Back in the 1980s, the world experienced the of electronic music as a genre – Australia’s own birth of a completely new musical breed of electronic music artists began realising poets and chance phenomena. Punk had seemingly run its course greater popularity. One such act was Itch-E meetings with rap and the world was growing weary of guitars and and Scratch-E, who made their debut at one of rock. The breakthrough genre was a cacophony of Sydney’s seminal outdoor raves – Happy Valley 2. artists in New York trance-inducing music, composed entirely from This gig was the first to host Paul Mac and Andy can result in some electronic instruments such as drum machines, Rantzen’s slant on electronic auditory hedonism, samplers, synthesisers and sequencers. The and the early morning time-slot saw the first favourable outcomes. inspiration had developed from sounds forged by airing of an amiable little tune by the name of Not to mention throwing acts such as Kraftwerk and the quirky 1970s disco Sweetness and Light. The track went on to win culture. It was stark, simple, and brash. an ARIA award for the pair – the presentation featuring the somewhat notorious incident where everything you know The movement had started in mid-1987, taking Paul thanked Australia’s ecstasy dealers during about collaboration out its lead from the acid-house movement and tracks his acceptance speech. Perhaps not so politically such as Steve ‘Silk’ Hurley’s TR808-infused Jack correct, but it certainly made it clear who the the window. -

From Disco to Electronic Music: Following the Evolution of Dance Culture Through Music Genres, Venues, Laws, and Drugs
Claremont Colleges Scholarship @ Claremont CMC Senior Theses CMC Student Scholarship 2010 From Disco to Electronic Music: Following the Evolution of Dance Culture Through Music Genres, Venues, Laws, and Drugs. Ambrose Colombo Claremont McKenna College Recommended Citation Colombo, Ambrose, "From Disco to Electronic Music: Following the Evolution of Dance Culture Through Music Genres, Venues, Laws, and Drugs." (2010). CMC Senior Theses. Paper 83. http://scholarship.claremont.edu/cmc_theses/83 This Open Access Senior Thesis is brought to you by Scholarship@Claremont. It has been accepted for inclusion in this collection by an authorized administrator. For more information, please contact [email protected]. Table of Contents I. Introduction 1 II. Disco: New York, Philadelphia, Chicago, and Detroit in the 1970s 3 III. Sound and Technology 13 IV. Chicago House 17 V. Drugs and the UK Acid House Scene 24 VI. Acid house parties: the precursor to raves 32 VII. New genres and exportation to the US 44 VIII. Middle America and Large Festivals 52 IX. Conclusion 57 I. Introduction There are many beginnings to the history of Electronic Dance Music (EDM). It would be a mistake to exclude the impact that disco had upon house, techno, acid house, and dance music in general. While disco evolved mostly in the dance capital of America (New York), it proposed the idea that danceable songs could be mixed smoothly together, allowing for long term dancing to previously recorded music. Prior to the disco era, nightlife dancing was restricted to bands or jukeboxes, which limited variety and options of songs and genres. The selections of the DJs mattered more than their technical excellence at mixing. -

Emoji Additions: Animals, Compatibility, and More Popular Requests To: UTC Date: May 8, 2015 (Font Updated May 21, 2015) From: Emoji Subcommittee
Emoji Additions: Animals, Compatibility, and More Popular Requests To: UTC Date: May 8, 2015 (font updated May 21, 2015) From: Emoji Subcommittee This document supersedes: Revision 3: 2015.05.08 Revision 2: 2015.05.03 Revision 1: 2015.02.05 Revision 0: 2015.02.02 Introduction The Unicode emoji subcommittee recommends the following set of 38 characters for encoding in version 9.0 of the Unicode Standard. These symbols are considered for incorporation into Unicode for reasons such as compatibility usage, popular requests from online communities, and filling the gaps in the existing set of Unicode emoji. For each proposed symbols, the rationale is added in the “Notes” column in the tables and there are further details in the “Discussion” section after the charts. It should be noted that the web search engine results in the “Notes” is not a definitive selection factor; it is an indicator, but may not fully reflect the potential popularity of the corresponding image among online communities. Color images below are for illustrative purposes and are not included in all cases. Likewise halftone characters are also illustrative. A font will be supplied for characters that are approved. Proposed Characters Faces and Body Code Halftone Color Name Notes FACE WITH COWBOY HAT Compatibility: Yahoo Messenger 1F920 CLOWN FACE Compatibility: Yahoo Messenger 1F921 NAUSEATED FACE Emojipedia most requested list tier 1; Compatibility: Yahoo Messenger, MSN Messenger 1F922 ROLLING ON THE FLOOR Compatibility: Yahoo Messenger LAUGHING 1F923 DROOLING FACE Compatibility: Yahoo Messenger 1F924 LYING FACE Compatibility: Yahoo Messenger 1F925 CALL ME HAND May be used after a face or smiley. -

Mr Smiley: My Last Pill and Testament Free
FREE MR SMILEY: MY LAST PILL AND TESTAMENT PDF Howard Marks | 400 pages | 24 Sep 2015 | Pan MacMillan | 9781509809660 | English | London, United Kingdom ‘Mr Nice’ Howard Marks dies of cancer aged 70 Levertijd We doen er alles aan om dit artikel op tijd te bezorgen. Het is echter in een enkel geval mogelijk dat door omstandigheden de Mr Smiley: My Last Pill and Testament vertraagd is. Bezorgopties We bieden verschillende opties aan voor het bezorgen of ophalen van je bestelling. Welke opties voor jouw bestelling beschikbaar zijn, zie je bij het afronden van de bestelling. Taal: Engels. Schrijf een review. Auteur: Howard Marks. Uitgever: Pan Macmillan. Samenvatting Howard Marks is the most famous drug smuggler of his age, and a hero to a generation. On his release from one of America's toughest prisons, Howard made a promise to himself to go straight. No more drugs, no more smuggling, no more fake passports. He would retire to a quiet life with his family in the Balearic Islands of Spain. It didn't quite work out that way. This was the mid-nineties, the height of the ecstasy and clubbing boom, and Ibiza was at the very centre of the vortex for the 'E generation'. Pills had taken the place of marijuana, Paul Oakenfold had replaced The Rolling Stones as the music of the masses, but some people are just born for life on the other side of the law. It wasn't long before Howard found himself trying pure ecstasy and rubbing shoulders with some of the king-pins of the pill trade. -

Learning the Steps to Become a Successful Nightclub Dancer
Learning the Steps to Become a Successful Nightclub Dancer Lucy Sims Submitted in fulfilment of the requirements for the degree of Doctor of Philosophy 2012 Cardiff University School of Social Sciences i Thesis Summary This study focuses on nightclub dancers. This includes freestyle podium dancers, choreographed stage dancers and pole performers that are paid to provide entertainment in nightclubs. The aim of this thesis is to answer the following main research question: how do individuals learn to become successful nightclub dancers? This can be broken into two constituent research questions: 1) what skills and attributes do individuals require in order to become successful nightclub dancers and 2) how do nightclub dancers learn to be successful and professional in their occupation. These questions are addressed through the analysis of data collected through semi-structured interviews with nightclub dancers, nightclub managers, events entertainment managers and dance teachers. The data suggested that in order to be successful, nightclub dancers need to be proficient in three types of labour that comprise their work: physical dance labour, aesthetic labour and emotional labour. Drawing on theories of workplace learning, it is argued that nightclub dancers learn the various skills required for dance labour through a range of different types of pre-job and on-the-job, formal and non-formal learning. Their learning of aesthetic and emotional labour is mainly characterised by non-formal on-the-job learning from other dancers. ii DECLARATION This work has not previously been accepted in substance for any degree and is not concurrently submitted in candidature for any degree. Signed …………………………………………………………. -
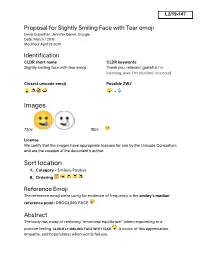
Slightly Smiling Face with Tear Emoji Emoji Submitter: Jennifer Daniel, Google Date: March 1 2019 Modified: April 23 2019
Proposal for Slightly Smiling Face with Tear emoji Emoji Submitter: Jennifer Daniel, Google Date: March 1 2019 Modified: April 23 2019 Identification CLDR short name CLDR keywords Slightly smiling face with tear emoji Thank you, relieved, grateful, I'm listening, awe, I’m touched, so proud Closest unicode emoji Possible ZWJ + Images 72px: 1 8px: License We certify that the images have appropriate licenses for use by the Unicode Consortium and are the creation of the document’s author. Sort location A. Category - Smileys-Positive B. Ordering Reference Emoji The reference emoji we're using for evidence of frequency is the smiley’s median reference point: DROOLING FACE Abstract The body has a way of restoring “emotional equilibrium” when responding to a positive feeling. SLIGHTLY SMILING FACE WITH TEAR is iconic of this appreciation, empathy, and hopefulness when words fail you. Introduction 1 “Happy tears”. “Happy cry”. “Tears of gratitude.” “I’m so happy … why am I crying?” “Kvelling”. Whatever you call this feeling and however it is evoked slightly smiling face with single tear embodies a naturally occurring physical response that allows people to better recover from strong emotions.2 Why should Unicode care? According to the Association for Psychological Science, “These insights advance our understanding of how people express and control their emotions, which is importantly related to mental and physical health, the quality of relationships with others, and even how well people work together.” Observed in religious scripture (Christianity, Hinduism, Lutheranism, and others), referenced in languages around the world (Arabic, tk tk tk) and in modern pop culture (Buffy the Vampire Slayer).