Web Search for Translation: an Exploratory Study on Six Chinese Trainee Translators’ Behaviour
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Uila Supported Apps
Uila Supported Applications and Protocols updated Oct 2020 Application/Protocol Name Full Description 01net.com 01net website, a French high-tech news site. 050 plus is a Japanese embedded smartphone application dedicated to 050 plus audio-conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also 10086.cn classifies the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese web portal operated by YLMF Computer Technology Co. Chinese cloud storing system of the 115 website. It is operated by YLMF 115.com Computer Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr Korean shopping website 11st. It is operated by SK Planet Co. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt Lithuanian news portal Chinese web portal 163. It is operated by NetEase, a company which 163.com pioneered the development of Internet in China. 17173.com Website distributing Chinese games. 17u.com Chinese online travel booking website. 20 minutes is a free, daily newspaper available in France, Spain and 20minutes Switzerland. This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Shared 2shared is an online space for sharing and storage. -

Final Study Report on CEF Automated Translation Value Proposition in the Context of the European LT Market/Ecosystem
Final study report on CEF Automated Translation value proposition in the context of the European LT market/ecosystem FINAL REPORT A study prepared for the European Commission DG Communications Networks, Content & Technology by: Digital Single Market CEF AT value proposition in the context of the European LT market/ecosystem Final Study Report This study was carried out for the European Commission by Luc MEERTENS 2 Khalid CHOUKRI Stefania AGUZZI Andrejs VASILJEVS Internal identification Contract number: 2017/S 108-216374 SMART number: 2016/0103 DISCLAIMER By the European Commission, Directorate-General of Communications Networks, Content & Technology. The information and views set out in this publication are those of the author(s) and do not necessarily reflect the official opinion of the Commission. The Commission does not guarantee the accuracy of the data included in this study. Neither the Commission nor any person acting on the Commission’s behalf may be held responsible for the use which may be made of the information contained therein. ISBN 978-92-76-00783-8 doi: 10.2759/142151 © European Union, 2019. All rights reserved. Certain parts are licensed under conditions to the EU. Reproduction is authorised provided the source is acknowledged. 2 CEF AT value proposition in the context of the European LT market/ecosystem Final Study Report CONTENTS Table of figures ................................................................................................................................................ 7 List of tables .................................................................................................................................................. -
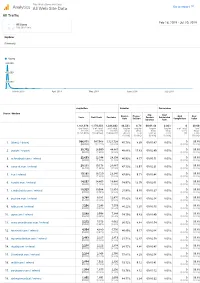
Thiswaifudoesnotexist.Net: Google Analytics: All Traffic 20190218-20190720
This Waifu Does Not Exist Analytics All Web Site Data Go to report All Traffic Feb 18, 2019 - Jul 20, 2019 All Users 100.00% Users Explorer Summary Users 600,000 400,000 200,000 March 2019 April 2019 May 2019 June 2019 July 2019 Acquisition Behavior Conversions Source / Medium Avg. Goal Bounce Pages / Goal Goal Users New Users Sessions Session Conversion Rate Session Completions Value Duration Rate 1,161,978 1,170,333 1,384,602 46.58% 8.74 00:01:48 0.00% 0 $0.00 % of Total: % of Total: % of Total: Avg for Avg for Avg for Avg for % of Total: % of 100.00% 100.07% 100.00% View: View: View: View: 0.00% Total: (1,161,978) (1,169,566) (1,384,602) 46.58% 8.74 00:01:48 0.00% (0) 0.00% (0.00%) (0.00%) (0.00%) (0.00%) ($0.00) 1. (direct) / (none) 966,071 967,968 1,121,738 45.78% 8.39 00:01:47 0.00% 0 $0.00 (82.06%) (82.71%) (81.02%) (0.00%) (0.00%) 2. google / organic 30,702 28,990 44,887 48.86% 15.63 00:02:49 0.00% 0 $0.00 (2.61%) (2.48%) (3.24%) (0.00%) (0.00%) 3. m.facebook.com / referral 22,693 22,544 24,304 46.93% 4.77 00:00:51 0.00% 0 $0.00 (1.93%) (1.93%) (1.76%) (0.00%) (0.00%) 4. away.vk.com / referral 20,111 19,178 26,667 47.13% 13.97 00:02:31 0.00% 0 $0.00 (1.71%) (1.64%) (1.93%) (0.00%) (0.00%) 5. -

List of Search Engines
A blog network is a group of blogs that are connected to each other in a network. A blog network can either be a group of loosely connected blogs, or a group of blogs that are owned by the same company. The purpose of such a network is usually to promote the other blogs in the same network and therefore increase the advertising revenue generated from online advertising on the blogs.[1] List of search engines From Wikipedia, the free encyclopedia For knowing popular web search engines see, see Most popular Internet search engines. This is a list of search engines, including web search engines, selection-based search engines, metasearch engines, desktop search tools, and web portals and vertical market websites that have a search facility for online databases. Contents 1 By content/topic o 1.1 General o 1.2 P2P search engines o 1.3 Metasearch engines o 1.4 Geographically limited scope o 1.5 Semantic o 1.6 Accountancy o 1.7 Business o 1.8 Computers o 1.9 Enterprise o 1.10 Fashion o 1.11 Food/Recipes o 1.12 Genealogy o 1.13 Mobile/Handheld o 1.14 Job o 1.15 Legal o 1.16 Medical o 1.17 News o 1.18 People o 1.19 Real estate / property o 1.20 Television o 1.21 Video Games 2 By information type o 2.1 Forum o 2.2 Blog o 2.3 Multimedia o 2.4 Source code o 2.5 BitTorrent o 2.6 Email o 2.7 Maps o 2.8 Price o 2.9 Question and answer . -

Information Rereival, Part 1
11/4/2019 Information Retrieval Deepak Kumar Information Retrieval Searching within a document collection for a particular needed information. 1 11/4/2019 Query Search Engines… Altavista Entireweb Leapfish Spezify Ask Excite Lycos Stinky Teddy Baidu Faroo Maktoob Stumpdedia Bing Info.com Miner.hu Swisscows Blekko Fireball Monster Crawler Teoma ChaCha Gigablast Naver Walla Dogpile Google Omgili WebCrawler Daum Go Rediff Yahoo! Dmoz Goo Scrub The Web Yandex Du Hakia Seznam Yippy Egerin HotBot Sogou Youdao ckDuckGo Soso 2 11/4/2019 Search Engine Marketshare 2019 3 11/4/2019 Search Engine Marketshare 2017 Matching & Ranking matched pages ranked pages 1. 2. query 3. muddy waters matching ranking “hits” 4 11/4/2019 Index Inverted Index • A mapping from content (words) to location. • Example: the cat sat on the dog stood on the cat stood 1 2 3 the mat the mat while a dog sat 5 11/4/2019 Inverted Index the cat sat on the dog stood on the cat stood 1 2 3 the mat the mat while a dog sat a 3 cat 1 3 dog 2 3 mat 1 2 on 1 2 sat 1 3 stood 2 3 the 1 2 3 while 3 Inverted Index the cat sat on the dog stood on the cat stood 1 2 3 the mat the mat while a dog sat a 3 cat 1 3 dog 2 3 mat 1 2 Every word in every on 1 2 web page is indexed! sat 1 3 stood 2 3 the 1 2 3 while 3 6 11/4/2019 Searching the cat sat on the dog stood on the cat stood 1 2 3 the mat the mat while a dog sat a 3 cat 1 3 query dog 2 3 mat 1 2 cat on 1 2 sat 1 3 stood 2 3 the 1 2 3 while 3 Searching the cat sat on the dog stood on the cat stood 1 2 3 the mat the mat while a dog sat a 3 cat -

Evaluating the Suitability of Web Search Engines As Proxies for Knowledge Discovery from the Web
Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 96 ( 2016 ) 169 – 178 20th International Conference on Knowledge Based and Intelligent Information and Engineering Systems, KES2016, 5-7 September 2016, York, United Kingdom Evaluating the suitability of Web search engines as proxies for knowledge discovery from the Web Laura Martínez-Sanahuja*, David Sánchez UNESCO Chair in Data Privacy, Department of Computer Engineering and Mathematics, Universitat Rovira i Virgili Av.Països Catalans, 26, 43007 Tarragona, Catalonia, Spain Abstract Many researchers use the Web search engines’ hit count as an estimator of the Web information distribution in a variety of knowledge-based (linguistic) tasks. Even though many studies have been conducted on the retrieval effectiveness of Web search engines for Web users, few of them have evaluated them as research tools. In this study we analyse the currently available search engines and evaluate the suitability and accuracy of the hit counts they provide as estimators of the frequency/probability of textual entities. From the results of this study, we identify the search engines best suited to be used in linguistic research. © 20162016 TheThe Authors. Authors. Published Published by by Elsevier Elsevier B.V. B.V. This is an open access article under the CC BY-NC-ND license (http://creativecommons.org/licenses/by-nc-nd/4.0/). Peer-review under responsibility of KES International. Peer-review under responsibility of KES International Keywords: Web search engines; hit count; information distribution; knowledge discovery; semantic similarity; expert systems. 1. Introduction Expert and knowledge-based systems rely on data to build the knowledge models required to perform inferences or answer questions. -

Download Your FREE Copy of the LT2013
THE FORUM FOR EUROPE'S LANGUAGE TECHNOLOGY INDUSTRY Language Technologies LT2013: Status and Potential of the European Language Technology Markets March 2013 www.lt‐innovate.eu ‐ contact@lt‐innovate.eu www.lt‐innovate.eu ‐ contact@lt‐innovate.eu TABLE OF CONTENTS Table of Contents .....................................................................................................................................1 Executive Summary ..................................................................................................................................2 Key Extracts....................................................................................................................................3 1. A New ICT Ecosystem ...........................................................................................................................6 1.1 The deep transformation of the competitive landscape .........................................................6 1.2 A Mobile/Social/Global Ecosystem ..........................................................................................7 2. Markets for Language Technology ......................................................................................................11 2.1 The Market Context for LT ......................................................................................................11 2.2 The LT‐Innovate Market Model ...............................................................................................14 2.3 Trends & Growth by Segment.................................................................................................17 -

Bing 2017: Bing Annual 2017 Free
FREE BING 2017: BING ANNUAL 2017 PDF none | 64 pages | 25 Aug 2016 | HarperCollins Publishers | 9780008122386 | English | London, United Kingdom The Bing Times | Bing Nursery School Are you interested in testing our corporate solutions? Please do not hesitate to contact me. Additional Information. Bing 2017: Bing Annual 2017 source. Show sources information Show publisher information. Market share of search engines in the United States Google vs. Microsoft Advertising: U. This feature is limited to our corporate solutions. Please contact us to get started with full access to dossiers, forecasts, studies and international data. Try our corporate solution for free! Single Accounts Corporate Solutions Universities. Popular Statistics Topics Markets. This statistic shows the worldwide search market share of Bing as of August in leading online markets. During the measured period, Bing accounted for 17 percent of search traffic in Canada. The Microsoft-owned platform accounted for nine percent of search traffic worldwide. Worldwide search market share of Bing as of Augustby country. Loading Bing 2017: Bing Annual 2017 Download for free You need to log in to download this statistic Register for free Already a member? Log in. Show detailed source information? Register for free Already a member? Show sources information. Show publisher information. More information. Supplementary notes. Other statistics on the topic. Research expert covering internet and e-commerce. Profit from additional features with an Employee Account. Please create an employee account to Bing 2017: Bing Annual 2017 able to Bing 2017: Bing Annual 2017 statistics as favorites. Then you can access your favorite statistics via the star in the header. -

Margin Under Pressure but Positive on Top-Line Growth
股 票 研 [Table_Title] Jason Zhou 周桓葳 Company Report: NetEase (NTES US) 究 (852) 2509 5347 Equity Research 公司报告: 网易 (NTES US) [email protected] 20 November 2020 Margin[Table_S ummaryUnder] Pressure but Positive on Top-Line Growth 利润率承压但对收入增长持正面看法 NetEase's 3Q2020 Non-GAAP net income from continuing operations Rating:[Table_Rank ] Buy attributable to the Company's shareholders was higher than market Maintained 公 estimates by 70.3% but lower than our estimates by 17.9%, respectively, mainly due to higher-than-expected sales and marketing expense related to 司 评级: 买入 (维持) Youdao and online games services. 报 We have revised up online games services revenue from 2020 to 2022 6[Table_Price-18m TP 目标价] : US$106.00 告 by 0.5%, 0.6% and 0.8%, respectively, due to i) expected steady cash flow US$108.20 Company Report from main existing titles, ii) outstanding games operating capability of the Company and iii) rich games pipeline. We believe that the main existing ADS price ADS价格: US$89.220 signature games could still maintain steady cash flow in the following quarters under expected stable time spent on games of hardcore players. Stock performance We believe that non-game segments will gain further growth 股价表现 momentum in our forecasted period. With expected enhancement of learning experience and further user expansion, we have further revised up 100.0 % of return 2020-2022 Youdao business revenue by 13.5%, 21.5% and 26.6%. Online 80.0 music is expected to be the main revenue driver on innovative business. In 60.0 addition, operating margin is expected to be further under pressure due to expected promotion expense on the Company's learning products. -

Nº E11 Revista Ibérica De Sistemas E Tecnologias De Informação Iberian Journal of Information Systems and Technologies
ISSN: 1646-9895 Revista Ibérica de Sistemas e Tecnologias de Informação Iberian Journal of Information Systems and Technologies Novembro 16 • November 16 ©AISTI 2016 http://www.aisti.eu Nº E11 Revista Ibérica de Sistemas e Tecnologias de Informação Iberian Journal of Information Systems and Technologies Edição / Edition Nº. E11, 11/2016 ISSN: 1646-9895 i Indexação / Indexing Academic Journals Database, CiteFactor, Dialnet, DOAJ, DOI, EBSCO, EI-Compendex, GALE, IndexCopernicus, Index of Information Systems Journals, Latindex, ProQuest, QUALIS, SCImago, SCOPUS, SIS, Ulrich’s. Propriedade e Publicação / Ownership and Publication AISTI – Associação Ibérica de Sistemas e Tecnologias de Informação Rua Quinta do Roseiral 76, 4435-209 Rio Tinto, Portugal E-mail: [email protected] Web: http://www.aisti.eu RISTI, N.º E11, 11/2016 i Director Álvaro Rocha, Universidade de Coimbra, PT Coordenadores da Edição / Issue Coordinators Shao Fei, School of Computer engineering, Jinling Institute of Technology, China Conselho Editorial / Editorial Board Carlos Ferrás Sexto, Universidad de Santiago de Compostela, ES Gonçalo Paiva Dias, Universidade de Aveiro, PT Jose Antonio Calvo-Manzano Villalón, Universidad Politécnica de Madrid, ES Manuel Pérez Cota, Universidad de Vigo, ES Ramiro Gonçalves, Universidade de Trás-os-Montes e Alto Douro, PT Conselho Científico / Scientific Board Adolfo Lozano-Tello, Universidad de Extremadura, ES Adriano Pasqualotti, Universidade de Passo Fundo, BR Alberto Fernández, Universidad Rey Juan Carlos, ES Alberto Bugarín, Universidad de Santiago de Compostela, ES Alejandro Medina, Universidad Politécnica de Chiapas, MX Alejandro Rodríguez González, Universidad Politécnica de Madrid, ES Alejandro Peña, Escuela de Ingeniería de Antioquia, CO Alexandre L’Erario, Universidade Tecnológica Federal do Paraná, BR Alma María Gómez-Rodríguez, Universidad de Vigo, ES Álvaro E. -

The Next Space Race
WHYVALUESTOCKSHAVEROOMTORUN•PAGES7,M1 VOL. CI NO. 12 MARCH 22, 2021 $5.00 THE NEXT SPACE RACE As technology advances, the competition to send rockets and their payloads into orbit has turned into a business worth tens of billions of dollars. We size up the companies and their stocks. PAGE 14 > 63142 CONTENTS 03.22.21 VOL.CI NO.12 P. 10 P. 4 P. 26 Signs of Hope for Economy: Reasons to Alzheimer’s Treatments A Steep Selloff Is Unlikely Expect Strong Growth While Eli Lilly’s recent test results Up&DownWallStreet:The bond vigilantes are back, pushing up interest rates, which By MATTHEW C. KLEIN fell short of high expectations, they is punishing highflying stocks. But the Federal Reserve is likely to step in to stop them if suggest that drugmakers are on the they start to go too far. By RANDALL W. FORSYTH P. 27 right track. Here’s how to invest. Income: High-Yielding By JOSH NATHAN-KAZIS Parting Ways Bank Stocks Beckon P. 11 Whilethetech-heavyNasdaqusedtorunroughlyinlockstepwith10-yearTreasuryyields, By CARLETON ENGLISH the two have diverged sharply. Rising rates are pounding growth stocks. NFT Investing Mania P. M1 CouldBeHeretoStay 1.75% 15,000 Trader: Sticking With Investors’ embrace of nonfungible tokens is opening new avenues for Banks and Energy commerce while helping to elevate By BEN LEVISOHN a new generation of creators. 1.50 14,000 By AVI SALZMAN P. M4 P. 12 Euro Trader: FanDuel 1.25 13,000 IPO Could Lift Flutter Light at the End of Nasdaq By RUPERT STEINER the Tunnel for Splunk The data miner’s new subscription P. -

Giant List of Search Engines
Giant List of Search Engines Search & find, try new dataset, new methods & ways to break the monotony of their ministry. Add extra power to your IR. Fast finding dear scholar. All links open in new windows. 1. 100 Search Engines https://www.100searchengines.com 2. 360Daily http://www.360daily.com 3. AddressSearch http://addresssearch.com 4. Alibaba https://www.alibaba.com 5. Alleba http://www.alleba.com 6. Allrecipes http://allrecipes.com 7. Alumni http://www.alumni.net 8. Amazon https://www.amazon.com 9. American Hospital Directory https://www.ahd.com 10. Answers.com https://www.answers.com 11. AnyWho http://www.anywho.com 12. Ask.com https://www.ask.com 13. Baidu https://www.baidu.com 14. Bankersalmanac https://www.bankersalmanac.com 15. BeenVerified https://www.beenverified.com 16. BigOven http://www.bigoven.com 17. Bing https://www.bing.com 18. Bing Maps https://www.bing.com/maps 19. Blockchain Explorer https://www.blockchain.com/explorer 20. Blockchair https://blockchair.com 21. Boardreader http://boardreader.com 22. BuiltWith http://builtwith.com 23. BuzzSumo http://buzzsumo.com 24. Canadian Law List https://www.canadianlawlist.com 25. CareerBuilder http://www.careerbuilder.com 26. CC Search https://ccsearch.creativecommons.org 27. Cheat Search http://www.cheatsearch.net 28. Check Usernames https://checkusernames.com 29. Chegg https://www.chegg.com 30. Classmates http://www.classmates.com 31. ClinicalTrials.gov https://clinicaltrials.gov 32. CookThing http://www.cookthing.com 33. Court Record Finder https://www.courtrecordfinder.com 34. Craigsist https://www.craigslist.org 35. DataparkSearch Engine http://www.dataparksearch.org 36. Daum https://www.daum.net 37.