An Unsupervised Crop Classification Method Based on Principal
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
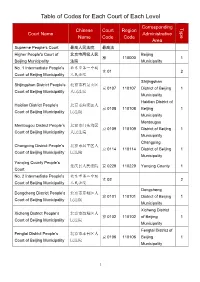
Table of Codes for Each Court of Each Level
Table of Codes for Each Court of Each Level Corresponding Type Chinese Court Region Court Name Administrative Name Code Code Area Supreme People’s Court 最高人民法院 最高法 Higher People's Court of 北京市高级人民 Beijing 京 110000 1 Beijing Municipality 法院 Municipality No. 1 Intermediate People's 北京市第一中级 京 01 2 Court of Beijing Municipality 人民法院 Shijingshan Shijingshan District People’s 北京市石景山区 京 0107 110107 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Haidian District of Haidian District People’s 北京市海淀区人 京 0108 110108 Beijing 1 Court of Beijing Municipality 民法院 Municipality Mentougou Mentougou District People’s 北京市门头沟区 京 0109 110109 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Changping Changping District People’s 北京市昌平区人 京 0114 110114 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Yanqing County People’s 延庆县人民法院 京 0229 110229 Yanqing County 1 Court No. 2 Intermediate People's 北京市第二中级 京 02 2 Court of Beijing Municipality 人民法院 Dongcheng Dongcheng District People’s 北京市东城区人 京 0101 110101 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Xicheng District Xicheng District People’s 北京市西城区人 京 0102 110102 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Fengtai District of Fengtai District People’s 北京市丰台区人 京 0106 110106 Beijing 1 Court of Beijing Municipality 民法院 Municipality 1 Fangshan District Fangshan District People’s 北京市房山区人 京 0111 110111 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Daxing District of Daxing District People’s 北京市大兴区人 京 0115 -

Heilongjiang Road Development II Project (Yichun-Nenjiang)
Technical Assistance Consultant’s Report Project Number: TA 7117 – PRC October 2009 People’s Republic of China: Heilongjiang Road Development II Project (Yichun-Nenjiang) FINAL REPORT (Volume II of IV) Submitted by: H & J, INC. Beijing International Center, Tower 3, Suite 1707, Beijing 100026 US Headquarters: 6265 Sheridan Drive, Suite 212, Buffalo, NY 14221 In association with WINLOT No 11 An Wai Avenue, Huafu Garden B-503, Beijing 100011 This consultant’s report does not necessarily reflect the views of ADB or the Government concerned, ADB and the Government cannot be held liable for its contents. All views expressed herein may not be incorporated into the proposed project’s design. Asian Development Bank Heilongjiang Road Development II (TA 7117 – PRC) Final Report Supplementary Appendix A Financial Analysis and Projections_SF1 S App A - 1 Heilongjiang Road Development II (TA 7117 – PRC) Final Report SUPPLEMENTARY APPENDIX SF1 FINANCIAL ANALYSIS AND PROJECTIONS A. Introduction 1. Financial projections and analysis have been prepared in accordance with the 2005 edition of the Guidelines for the Financial Governance and Management of Investment Projects Financed by the Asian Development Bank. The Guidelines cover both revenue earning and non revenue earning projects. Project roads include expressways, Class I and Class II roads. All will be built by the Heilongjiang Provincial Communications Department (HPCD). When the project started it was assumed that all project roads would be revenue earning. It was then discovered that national guidance was that Class 2 roads should be toll free. The ADB agreed that the DFR should concentrate on the revenue earning Expressway and Class I roads, 2. -
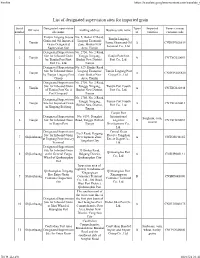
List of Designated Supervision Sites for Imported Grain
Firefox https://translate.googleusercontent.com/translate_f List of designated supervision sites for imported grain Serial Designated supervision Types Imported Venue (venue) Off zone mailing address Business unit name number site name of varieties customs code Tianjin Lingang Jiayue No. 5, Bohai 37 Road, Tianjin Lingang Grain and Oil Imported Lingang Economic 1 Tianjin Jiayue Grain and Oil A CNDGN02S619 Grain Designated Zone, Binhai New Terminal Co., Ltd. Supervision Site Area, Tianjin Designated Supervision No. 2750, No. 2 Road, Site for Inbound Grain Tanggu Xingang, Tianjin Port First 2 Tianjin A CNTXG020051 by Tianjin Port First Binhai New District, Port Co., Ltd. Port Co., Ltd. Tianjin Designated Supervision No. 529, Hunhe Road, Site for Inbound Grain Lingang Economic Tianjin Lingang Port 3 Tianjin A CNDGN02S620 by Tianjin Lingang Port Zone, Binhai New Group Co., Ltd. Group Area, Tianjin Designated Supervision No. 2750, No. 2 Road, Site for Inbound Grain Tanggu Xingang, Tianjin Port Fourth 4 Tianjin A CNTXG020448 of Tianjin Port No. 4 Binhai New District, Port Co., Ltd. Port Company Tianjin No. 2750, No. 2 Road, Designated Supervision Tanggu Xingang, Tianjin Port Fourth 5 Tianjin Site for Imported Grain A CNTXG020413 Binhai New District, Port Co., Ltd. in Xingang Beijiang Tianjin Tianjin Port Designated Supervision No. 6199, Donghai International Sorghum, corn, 6 Tianjin Site for Inbound Grain Road, Tanggu District, Logistics B CNTXG020051 sesame in Tianjin Port Tianjin Development Co., Ltd. Designated Supervision Central Grain No.9 Road, Haigang Site for Inbound Grain Reserve Tangshan 7 Shijiazhuang Development Zone, A CNTGS040165 at Jingtang Port Grocery Direct Depot Co., Tangshan City Terminal Ltd. -

Environmental Issues in China's Northeast
Environmental Issues in China’s Northeast By Sian Eiles, July 2014 Chinese environmental issues tend to centre around three particular issues: air pollution, water resources and desertification/ soil erosion. Air and water pollution are the most serious environmental problems in NE China Air pollution Air pollution is largely a result of China’s rapid period of industrialisation since the death of Mao and the economic reform era ushered in by his successor Deng Xiaoping. This has led to a growth in demand for power and in China this has been provided largely by coal, which has been the mainstay of electrical power generation as well as household energy for many years. Chinese domestic coal production is covered in another paper, but it is important to note the peculiarities of Chinese coal: which is that it is unusually ‘dirty’, particularly in the level of particulates it is likely to produce, along with a high sulphur content. Although the north east has seen a loss of industry since the beginning of the reform era the pollution problem still remains. In the south and the eastern coastal areas there been, over the past two decades, a movement away from ‘heavy’ industries such as steel smelting and car production. These are less energy intensive and have helped reduce pollution levels to some degree (although these areas now produce a lot of pollution via cars due to the increased wealth and increased demand for electricity, which is largely still coal fired). There is also a clear argument that pollution is an inevitable component of the development process, and that pollution levels reduce as economic wealth is more established. -

China - Provisions of Administration on Border Trade of Small Amount and Foreign Economic and Technical Cooperation of Border Regions, 1996
China - Provisions of Administration on Border Trade of Small Amount and Foreign Economic and Technical Cooperation of Border Regions, 1996 MOFTEC copy @ lexmercatoria.org Copyright © 1996 MOFTEC SiSU lexmercatoria.org ii Contents Contents Provisions of Administration on Border Trade of Small Amount and Foreign Eco- nomic and Technical Cooperation of Border Regions (Promulgated by the Ministry of Foreign Trade Economic Cooperation and the Customs General Administration on March 29, 1996) 1 Chapter 1 - General Provisions 1 Article 1 ......................................... 1 Article 2 ......................................... 1 Article 3 ......................................... 1 Chapter 2 - Border Trade of Small Amount 1 Article 4 ......................................... 1 Article 5 ......................................... 2 Article 6 ......................................... 2 Article 7 ......................................... 2 Article 8 ......................................... 3 Article 9 ......................................... 3 Article 10 ........................................ 3 Article 11 ........................................ 3 Article 12 ........................................ 4 Article 13 ........................................ 4 Article 14 ........................................ 4 Article 15 ........................................ 4 Article 16 ........................................ 5 Article 17 ........................................ 5 Chapter 3 - Foreign Economic and Technical Cooperation in Border Regions -

Environmental Monitoring Report PRC: Songhua River Basin Pollution
Environmental Monitoring Report Project Number: 40665 October 2013 PRC: Songhua River Basin Pollution Control and Management Project (Heilongjiang component) Prepared by the Project Management Office of Heilongjiang Provincial Government, with assistance of NREM International Inc. For: Heilongjiang Provincial Government Tangyuan County Water Supply Company; Tonghe County Water Supply and Drainage Company; Yanshou County Water Supply Company; Fangzheng County Water Supply and Drainage Company; Harbin City Inland River Comprehensive Development Company; New Era Urban Infrastructure Construction Investment Jiamusi Company Limited; Nenjiang County Water Supply Company; Qiqihaer City Hecheng Wastewater Treatment Company Limited; Qitaihe City Qingyuan Drainage Company Limited; Shuangyashan City Changyuan Drainage Company Limited; and Tangyuan County Xingyuan Urban Construction Investment Company Limited. This report has been submitted to ADB by the Project Management Office of Heilongjiang Provincial Government and is made publicly available in accordance with ADB’s public communications policy (2011). It does not necessarily reflect the views of ADB. Your attention is directed to the “Terms of Use” section of this website. ENVIRONMENTAL MONITORING REPORT (COVERING THE PERIOD OF JULY 2012 - JUNE 2013) People’s Republic of China: Songhua River Basin Pollution Control and Management Project (Heilongjiang Component) ADB Loan No.: 2360-PRC Submitted to: Heilongjiang Provincial Government and Asian Development Bank Prepared by: Heilongjiang Project -

Cultivated Land Use Zoning Based on Soil Function Evaluation from the Perspective of Black Soil Protection
land Article Cultivated Land Use Zoning Based on Soil Function Evaluation from the Perspective of Black Soil Protection Rui Zhao 1,†, Junying Li 2,†, Kening Wu 1,3,4,* and Long Kang 1 1 School of Land Science and Technology, China University of Geosciences, Beijing 100083, China; zhaoruifi[email protected] (R.Z.); [email protected] (L.K.) 2 College of Resources and Environment, Shandong Agricultural University, Taian 271018, China; [email protected] 3 Key Laboratory of Land Consolidation and Rehabilitation, Ministry of Natural Resources, Beijing 100035, China 4 Technology Innovation Center of Land Engineering, Ministry of Natural Resources, Beijing 100083, China * Correspondence: [email protected] † These authors contributed equally to this work. Abstract: Given that cultivated land serves as a strategic resource to ensure national food security, blind emphasis on improvement of food production capacity can lead to soil overutilization and impair other soil functions. Therefore, we took Heilongjiang province as an example to conduct a multi-functional evaluation of soil at the provincial scale. A combination of soil, climate, topography, land use, and remote sensing data were used to evaluate the functions of primary productivity, provi- sion and cycling of nutrients, provision of functional and intrinsic biodiversity, water purification and regulation, and carbon sequestration and regulation of cultivated land in 2018. We designed a soil function discriminant matrix, constructed the supply-demand ratio, and evaluated the current status of supply and demand of soil functions. Soil functions demonstrated a distribution pattern Citation: Zhao, R.; Li, J.; Wu, K.; of high grade in the northeast and low grade in the southwest, mostly in second-level areas. -

Financial Analysis
Heilongjiang Green Urban and Economic Revitalization Project (RRP PRC 49021-002) FINANCIAL ANALYSIS A. Introduction and Methodology 1. The financial analysis for the proposed project was undertaken in accordance with the Asian Development Bank (ADB) guidelines.1 A financial analysis was conducted for all revenue- generating subcomponents—i.e., those concerning water supply, wastewater management, and district heating (Table 1)—to test if their financial internal rate of return (FIRR) is above the weighted average cost of capital (WACC). A tariff and affordability assessment was carried out. Additionally, a financial sustainability analysis was done to assess the capacity of the project cities of Hegang, Jixi, Qitaihe, and Shuangyashan to service debt, meet operation and maintenance costs as well as recurring costs, and provide counterpart funding as required by the project. Table 1: Revenue-Generating Subcomponents Output 3: Key infrastructure and SME facilities in non-coal industrial parks in project cities constructed 1. Hegang Luobei County high-tech graphite-based materials and e-mobility industrial park—wastewater treatment plant and SME support facilities 2. Jixi wastewater treatment plant and discharge infrastructure in Jiguan District Industrial Park Output 5: Integrated urban infrastructure and services in project cities improved 1. Hegang District heating system energy efficiency improvements 2. Jixi No. 3 water treatment plant upgrade and expansion 3. Qitaihe water treatment plant upgrade and water supply pipe replacement and -

Sanjiang Plain Wetlands Protection Project
Performance People’s Republic of China: Evaluation Sanjiang Plain Wetlands Report Protection Project Independent Evaluation Performance Evaluation Report December 2015 People’s Republic of China: Sanjiang Plain Wetlands Protection Project This document is being disclosed to the public in accordance with ADB’s Public Communications Policy 2011. Reference Number: PPE:PRC 2015-15 Project Number: 35289 Loan and Grant Numbers: 2157 and 4571 Independent Evaluation: PE-783 NOTE In this report, “$” refers to US dollars. Director General V. Thomas, Independent Evaluation Department (IED) Director W. Kolkma, Independent Evaluation Division 1, IED Team leader G. Kilroy, Evaluation Specialist, IED Team members M. Dimayuga, Senior Evaluation Officer, IED C. Marvilla. Evaluation Assistant, IED In preparing any evaluation report, or by making any designation of or reference to a particular territory or geographic area in this document, the Independent Evaluation Department does not intend to make any judgments as to the legal or other status of any territory or area. The guidelines formally adopted by IED on avoiding conflict of interest in its independent evaluations were observed in the preparation of this report. To the knowledge of the management of IED, there were no conflicts of interest of the persons preparing, reviewing, or approving this report. Abbreviations ADB - Asian Development Bank EIRR – economic internal rate of return FIRR – financial internal rate of return GEF – Global Environment Facility GIS – geographic information system ha – -

Preliminary Metallogenic Belt and Mineral Deposit Maps for Northeast Asia
Preliminary Metallogenic Belt and Mineral Deposit Maps for Northeast Asia By Sergey M. Rodionov1, Alexander A. Obolenskiy2, Elimir G. Distanov2, Gombosuren Badarch3, Gunchin Dejidmaa4, Duk Hwan Hwang5, Alexander I.Khanchuk6, Masatsugu Ogasawara7, Warren J. Nokleberg8, Leonid M. Parfenov9, Andrei V. Prokopiev9, Zhan V. Seminskiy10, Alexander P. Smelov9, Hongquan Yan11, Gennandiy V. Birul'kin9, Yuriy V. V. Davydov9, Valeriy Yu. Fridovskiy12 , Gennandiy N. Gamyanin9, Ochir Gerel13, Alexei V. Kostin9, Sergey A. Letunov14, Xujun Li11, Valeriy M. Nikitin12, Sadahisa Sudo7 Vitaly I. Sotnikov2, Alexander V. Spiridonov14, Vitaly A. Stepanov15, Fengyue Sun11, Jiapeng Sun11, Weizhi Sun11, Valeriy M. Supletsov9, Vladimir F. Timofeev9, Oleg A. Tyan9, Valeriy G. Vetluzhskikh9, Koji Wakita7, Yakov V. Yakovlev9, and Lydia M. Zorina14 Open-File Report 03-204 2003 This report is preliminary and has not been reviewed for conformity with U.S. Geological Survey editorial standards or with the North American Stratigraphic Code. Any use of trade, firm, or product names in this publication is for descriptive purposes only and does not imply endorsement by the U.S. Government. 1 Russian Academy of Sciences, Khabarovsk 2 Russian Academy of Sciences, Novosibirsk 3 Mongolian Academy of Sciences, Ulaanbaatar 4 Mineral Resources Authority of Mongolia, Ulaanbaatar 5 Korean Institute of Geology, Mining, and Materials, Taejon 6 Russian Academy of Sciences, Vladivostok 7 Geological Survey of Japan/AIST, Tsukuba 8 U.S. Geological Survey, Menlo Park 9 Russian Academy of Sciences, Yakutsk 10 Irkutsk State Technical University, Irkutsk 11 Jilin University, Changchun 12 Yakutian State University, Yakutsk 13 Mongolian University of Science and Technology, Ulaanbaatar 14 Russian Academy of Sciences, Irkutsk 15 Russian Academy of Sciences, Blagoveschensk 1 Prepared in Collaboration with Russian Academy of Sciences, Mongolian Academy of Sciences, Jilin University (Changchun Branch), Korean Institute of Geology, Mining, and Materials, and Geological Survey of Japan/AIST. -

Sgs Qualifor Forest Management Certification
SGS QUALIFOR Doc. Number: AD 36-A-05 (Associated Document) Doc. Version date: 9 April 2010 Page: 1 of 53 FOREST MANAGEMENT CERTIFICATION REPORT 森林管理认证报告 SECTION A: PUBLIC SUMMARY 第第第 A 部部部分分分:公公公开开开摘摘摘要要要 Project Nr 项目编号: CN DLC-5686 Jiayin County Forest Bureau Client 客户: 嘉荫县林业局 Web Page 网页: www.yhlyj.ocm Yichun City, Heilongjiang Province, P.R. China Address 地址: 中国黑龙江省伊春市 Country 国家: China 中国 SGS-FM/CoC- Certificate Type: Certificate Nr 证书编号. Forest Management 森林经营认证 008110 Date of Issue 发证日期 6 Oct 2010 Date of expiry: 5 Oct 2015 SGS Generic Forest Stewardship Standard adapted for P.R. China, AD33-CN-05 of Feb 13 2009 Evaluation Standard 审审审 核标准 针对中国区作出适当修订后的 SGS 森林认证通用标准 AD33-CN-05 (修订后生效日期 2009 年 2 月 13 日) Forest Zone 森林类型: Temperate 温带林 Total Certified Area 认认认 62563 ha 62563 公顷 证面积 Scope 范围: Forest Management of Jiayin County Forest Bureau in the Heilongjiang Province of P.R. China for the production of softwood and hardwood timber. 中国黑龙江省嘉荫县林业局的森林经营是为了进行针叶树、阔叶树木材的生产。 Location of the FMUs Yichun City, Heilongjiang Province, P.R. China included in the scope 认证范围内林场的位置 中国黑龙江省伊春市 Company Contact Mr. Mr. Fan LI 李凡 先生 Person 联系人: SGS services are rendered in accordance with the applicable SGS General Conditions of Service accessible at http://www.sgs.com/terms_and_conditions.htm SGS South Africa (Qualifor Programme) 58 Melville Road, Booysens - PO Box 82582, Southdale 2185 -SouthSouth AAfricafrica Systems and Services Certification Division Contact Programme Director at t. +27 11 681- 2500 [email protected] www.sgs.com/forestry AD 36-A-05 Page 2 of 53 Address 地址: Yichun City, Heilongjiang Province, P.R. -

Financial Analysis
Additional Financing for the Heilongjiang Green Urban and Economic Revitalization Project (RRP PRC 49021-004) FINANCIAL ANALYSIS A. Introduction and Methodology 1. The financial analysis for the current project was undertaken, and updated for the additional financing, in accordance with the Asian Development Bank (ADB) guidelines. 1 A financial analysis was conducted for all revenue-generating subcomponents—i.e., those concerning water supply, wastewater management, and district heating (Table 1)—to test if their financial internal rate of return (FIRR) is above the weighted average cost of capital (WACC). A tariff and affordability assessment was carried out. Additionally, a financial sustainability analysis was done to assess the capacity of the project cities of Hegang, Jixi, Qitaihe, and Shuangyashan to service debt, meet operation and maintenance costs as well as recurring costs, and provide counterpart funding as required by the project. Table 1: Revenue-Generating Subcomponents Output 3: Key infrastructure and facilities for SMEs in non-coal industrial parks in project cities constructed 1. Hegang Luobei County high-tech graphite-based materials and e-mobility industrial park—wastewater treatment plant and SME support facilities 2. Jixi wastewater treatment plant and discharge infrastructure in Jiguan District Industrial Park Output 5: Integrated urban infrastructure and services in project cities improved 1. Hegang district heating system energy efficiency improvements 2. Jixi No. 3 water treatment plant upgrade and expansion