Triggered Code Switching Evidence from Dutch – English and Russian – English Bilinguals
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introduction: Reconciling Approaches to Intra-Individual Variation in Psycholinguistics and Variationist Sociolinguistics
Linguistics Vanguard 2021; 7(s2): 20200027 Lars Bülow* and Simone E. Pfenninger Introduction: Reconciling approaches to intra-individual variation in psycholinguistics and variationist sociolinguistics https://doi.org/10.1515/lingvan-2020-0027 Abstract: The overall theme of this special issue is intra-individual variation, that is, the observable variation within individuals’ behaviour, which plays an important role in the humanities area as well as in the social sciences. While various fields have recognised the complexity and dynamism of human thought and behav- iour, intra-individual variation has received less attention in regard to language acquisition, use and change. Linguistic research so far lacks both empirical and theoretical work that provides detailed information on the occurrence of intra-individual variation, the reasons for its occurrence and its consequences for language development as well as for language variation and change. The current issue brings together two sub- disciplines – psycholinguistics and variationist sociolinguistics – in juxtaposing systematic and non- systematic intra-individual variation, thereby attempting to build a cross-fertilisation relationship between two disciplines that have had surprisingly little connection so far. In so doing, we address critical stock-taking, meaningful theorizing and methodological innovation. Keywords: psycholinguistics, variationist sociolinguistics, intra-individual variation, intra-speaker variation, SLA, language variation and change, language development 1 Intra-individual variation in psycholinguistics and variationist sociolinguistics The overall theme of this special issue is intra-individual variation, that is, the observable variation within individuals’ behaviour, which plays an important role in the humanities area as well as in the social sciences. While various fields have acknowledged the complexity and dynamism of human behaviour, intra-individual variation has received less attention in regard to language use. -

Viewpoints W 113
International Journal of Applied Linguistics w Vol. 15 w No. 1 w 2005Viewpoints w 113 Viewpoints “Globalisation” and Applied Linguistics: post-imperial questions of identity and the construction of applied linguistics discourse Janina Brutt-Griffler University of York “Where are you from?” It’s a question we’ve all been asked at some point, in some place, in some language. It’s probably a question we’ve all put to someone else. When we ask it of others we attribute it to curiosity. When it is put to us, we attribute it to difference, since when posed by strangers, as it most often is, it is as a general rule based either on how we sound or how we look. And yet both our interrogator and we ourselves understand at some level that the question is meaningless, even impertinent. It is rooted in a mythical sense of space and place. Lurking just below the surface is an unasked, ultimately unanswerable question: “Where do you belong?” Like every other notion, that of belonging is not some natural idea with which all of us come into the world but one constructed socially, and therefore ultimately historically. It is rooted in a particular social order, one that seeks to assign persons to definite geographical and social spaces. When we invoke this notion of space and place – the attempt to assign, as if by natural dispensation, persons to particular ethnic, national or other origins or identities – we draw, consciously or unconsciously, on received notions inherited from the past. Linguistics has long established that any child born into this world can learn any language natively. -

Language Attrition: the Next Phase Barbara Köpke, Monika Schmid
Language Attrition: The next phase Barbara Köpke, Monika Schmid To cite this version: Barbara Köpke, Monika Schmid. Language Attrition: The next phase. Monika S. Schmid, Barbara Köpke, Merel Keijzer, Lina Weilemar. First Language Attrition: Interdisciplinary perspectives on methodological issues, John Benjamins, pp.1-43, 2004, Studies in Bilingualism, 9027241392. hal- 00879106 HAL Id: hal-00879106 https://hal.archives-ouvertes.fr/hal-00879106 Submitted on 31 Oct 2013 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Language Attrition: The Next Phase Barbara Köpke (Université de Toulouse – Le Mirail) and Monika S. Schmid Vrije Universiteit Amsterdam Barbara Köpke Laboratoire de Neuropsycholinguistique Jacques Lordat Institut des Sciences du Cerveau de Toulouse Université de Toulouse-Le Mirail 31058 Toulouse Cedex France [email protected] Monika S. Schmid Engelse Taal en Cultuur Faculteit der Letteren Vrije Universiteit 1081 HV Amsterdam The Netherlands [email protected] Published in : M.S. Schmid, B. Köpke, M. Keijzer & L. Weilemar (2004). First Language Attrition. Interdisciplinary perspectives on methodological issues (pp. 1-43). Amsterdam: John Benjamins. Köpke, B. & Schmid, M.S. (2004). Language Attrition: The Next Phase. In M.S. Schmid, B. -

An Introduction to Applied Linguistics This Page Intentionally Left Blank an Introduction to Applied Linguistics
An Introduction to Applied Linguistics This page intentionally left blank An Introduction to Applied Linguistics edited by Norbert Schmitt Orders: please contact Bookpoint Ltd, 130 Milton Park, Abingdon, Oxon OX14 4SB. Telephone: (44) 01235 827720. Fax: (44) 01235 400454. Lines are open from 9.00 to 5.00, Monday to Saturday, with a 24-hour message answering service. You can also order through our website www.hoddereducation.co.uk If you have any comments to make about this, or any of our other titles, please send them to [email protected] British Library Cataloguing in Publication Data A catalogue record for this title is available from the British Library ISBN: 978 0 340 98447 5 First Edition Published 2002 This Edition Published 2010 Impression number 10 9 8 7 6 5 4 3 2 1 Year 2014, 2013, 2012, 2011, 2010 Copyright © 2010 Hodder & Stoughton Ltd All rights reserved. No part of this publication may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopy, recording, or any information storage and retrieval system, without permission in writing from the publisher or under licence from the Copyright Licensing Agency Limited. Further details of such licences (for reprographic reproduction) may be obtained from the Copyright Licensing Agency Limited, of Saffron House, 6–10 Kirby Street, London EC1N 8TS. Hachette UK’s policy is to use papers that are natural, renewable and recyclable products and made from wood grown in sustainable forests. The logging and manufacturing processes are expected to conform to the environmental regulations of the country of origin. -

Proximate and Ultimate Explanations of Individual Differences in Language Use and Language Acquisition
Proximate and ultimate explanations of individual differences in language use and language acquisition Jan Hulstijn University of Amsterdam I evaluate three schools in linguistics (structuralism; generative linguistics; usage based linguistics) from the perspective of Karl Popper’s critical ratio- nalism. Theories (providing proximate explanations) may be falsified at some point in time. In contrast, metatheories, such as Darwin’s theory of evolution and the theory of Language as a Complex Adaptive System (LCAS) (providing ultimate explanations) are falsifiable in principle, but not likely to be falsified. I then argue that LCAS provides a fruitful frame- work for the explanation of individual differences in language acquisition and use. Unequal frequency distributions of linguistic elements constitute a necessary characteristic of language production, in line with LCAS. How- ever, explaining individual differences implies explaining commonalities (Hulstijn, 2015, 2019). While attributes such as people’s level of education and profession are visible in knowledge of the standard language (declara- tive knowledge acquired in school), they may be invisible in the spoken ver- nacular (linguistic cognition shared by all native speakers). Keywords: basic language cognition, language as a complex adaptive system, Darwin’s theory of evolution, falsifiability, theory versus metatheory, individual differences, language use, language acquisition Uncertainty, that is perhaps the best word with which I should characterize the most frequent feelings that I experienced throughout my intellectual journey, since I entered university until the present.Uncertainty about what to think of a new theoretical viewpoint.What to think of an ongoing debate between scholars defending different theories? What to think of new methodologies? My intellec- tual journey consisted of ups and downs and the downs were really unpleasant. -

Review Article: the Imaging of What in the Multilingual Mind? Kees De Bot
Review article: The imaging of what in the multilingual mind? Kees de Bot To cite this version: Kees de Bot. Review article: The imaging of what in the multilingual mind?. Second Language Research, SAGE Publications, 2008, 24 (1), pp.111-133. 10.1177/0267658307083034. hal-00570740 HAL Id: hal-00570740 https://hal.archives-ouvertes.fr/hal-00570740 Submitted on 1 Mar 2011 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Review_SLR_111-134.qxd 12/11/07 10:01 AM Page 111 Second Language Research 24,1 (2008); pp. 111–133 Review article The imaging of what in the multilingual mind? Kees de Bot University of Groningen Received December 2006; revised February 2007; accepted July 2007 In this review article it is argued that while the number of neuro-imag- ing (NI) studies on multilingual processing has exploded over the last few years, the contribution of such studies to enhance our understand- ing of the process of multilingual processing has not been very sub- stantial. There are problems on various levels, which include the following issues: ownership of the field of NI and multilingualism, whether relevant background characteristics are assessed adequately, whether we consider variation as a problem or a source of information, what NI tells us about multilingual development, whether the native speaker is the norm in NI research, the added value of NI data, what information NI provides, and what the contribution of NI research is to theories about the multilingual brain. -

Code-Switching and Predictability of Meaning In
CODE-SWITCHING AND PREDICTABILITY OF MEANING IN DISCOURSE Mark Myslín Roger Levy University of California, San Diego University of California, San Diego What motivates a fluent bilingual speaker to switch languages within a single utterance? We propose a novel discourse-functional motivation: less predictable, high information-content mean- ings are encoded in one language, and more predictable, lower information-content meanings are encoded in another language. Switches to a speaker’s less frequently used, and hence more salient, language offer a distinct encoding that highlights information-rich material that comprehenders should attend to especially carefully. Using a corpus of natural Czech-English bilingual discourse, we test this hypothesis against an extensive set of control factors from sociolinguistic, psycholin- guistic, and discourse-functional lines of research using mixed-effects logistic regression, in the first such quantitative multifactorial investigation of code-switching in discourse. We find, using a Shannon guessing game to quantify predictability of meanings in conversation, that words with difficult-to-guess meanings are indeed more likely to be code-switch sites, and that this is in fact one of the most highly explanatory factors in predicting the occurrence of code-switching in our data. We argue that choice of language thus serves as a formal marker of information content in discourse, along with familiar means such as prosody and syntax. We further argue for the utility of rigorous, multifactorial approaches to sociolinguistic speaker-choice phenomena in natural conversation.* Keywords: code-switching, bilingualism, discourse, predictability, audience design, statistical modeling 1. Introduction. In an early sketch of language contact, André Martinet (1953:vii) observed that in multilingual speech, choice of language is not dissimilar to the ‘choice[s] among lexical riches and expressive resources’available in monolingual speech. -

Gestures and Some Key Issues in the Study of Language Development Gullberg, Marianne; De Bot, Kees; Volterra, Virginia
Gestures and some key issues in the study of language development Gullberg, Marianne; de Bot, Kees; Volterra, Virginia Published in: Gesture DOI: 10.1075/gest.8.2.03gul 2008 Link to publication Citation for published version (APA): Gullberg, M., de Bot, K., & Volterra, V. (2008). Gestures and some key issues in the study of language development. Gesture, 8(2), 149-179. https://doi.org/10.1075/gest.8.2.03gul Total number of authors: 3 General rights Unless other specific re-use rights are stated the following general rights apply: Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights. • Users may download and print one copy of any publication from the public portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain • You may freely distribute the URL identifying the publication in the public portal Read more about Creative commons licenses: https://creativecommons.org/licenses/ Take down policy If you believe that this document breaches copyright please contact us providing details, and we will remove access to the work immediately and investigate your claim. LUND UNIVERSITY PO Box 117 221 00 Lund +46 46-222 00 00 Running title: Key issues in language development Gestures and some key issues in the study of language development Marianne Gullberg1, Kees de Bot2, & Virginia Volterra3 1 Max Planck Institute for Psycholinguistics, 2 Rijksuniversiteit Groningen, 3 Istituto di Scienze e Tecnologie della Cognizione, CNR In Gesture, 8(2), Special issue Gestures in language development, eds. -
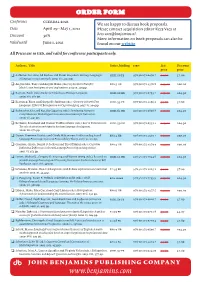
Discount Order Form (PDF)
ORDER FORM Conference CCERBAL 2021 We are happy to discuss book proposals. Date April 29 - May 1, 2021 Please contact acquisition editor Kees Vaes at Discount 30% [email protected]. More information on book proposals can also be Valid until June 1, 2021 found on our website All Prices are in usd, and valid for conference participants only. Authors, Title Series, binding isbn List Discount price price ❑ Aalberse, Suzanne, Ad Backus and Pieter Muysken: Heritage Languages: SiBiL 58 PB 978 90 272 0470 7 54.00 37.80 A language contact approach. 2019. xix, 302 pp. ❑ Angelovska, Tanja and Angela Hahn (eds.): L3 Syntactic Transfer: BPA 5 HB 978 90 272 4376 8 143.00 100.10 Models, new developments and implications. 2017. x, 329 pp. ❑ Bayram, Fatih (ed.): Studies in Turkish as a Heritage Language. SiBiL 60 HB 978 90 272 0793 7 149.00 104.30 2020. xiv, 287 pp. ❑ Bialystok, Ellen and Margot D. Sullivan (eds.): Growing Old with Two SiBiL 53 PB 978 90 272 4196 2 54.00 37.80 Languages: Effects of Bilingualism on Cognitive Aging.2017. vi, 304 pp. ❑ Bohnacker, Ute and Natalia Gagarina (eds.): Developing Narrative SiBiL 61 HB 978 90 272 0808 8 149.00 104.30 Comprehension: Multilingual Assessment Instrument for Narratives. 2020. vii, 341 pp. ❑ Brehmer, Bernhard and Jeanine Treffers-Daller (eds.): Lost in Transmission: SiBiL 59 HB 978 90 272 0539 1 149.00 104.30 The role of attrition and input in heritage language development. 2020. vii, 276 pp. ❑ Dyson, Bronwen Patricia and Gisela Håkansson: Understanding Second BPA 4 HB 978 90 272 4375 1 143.00 100.10 Language Processing: A focus on Processability Theory. -

Marjolijn Verspoor, Kees De Bot, and Wander Lowie University of Groningen Departments of English and Applied Linguistics
Published as: Verspoor, M.H., K. de Bot & W.M. Lowie, “Dynamic systems theory and variation: a case study in L2 writing.” In H. Aertsen, M. Hannay & R. Lyall, Words in their places: a Festschrift for J. Lachlan Mackenzie . Amsterdam: VU, 2004. pp. 407-421. MANUSCRIPT 1 Marjolijn Verspoor, Kees de Bot, and Wander Lowie University of Groningen Departments of English and Applied Linguistics Dynamic Systems Theory and Variation: a case study in L2 writing 1 Introduction As colleagues in another English Department, we have worked with Lachlan Mackenzie’s publications on a day-to-day basis in our classes: Principles and pitfalls of English grammar is used in our practical English grammar classes and Effective writing in English: a resource guide is often consulted when we run into persistent writing problems. In this paper we would like to address these common points of interest from a radically different perspective, namely Dynamic Systems Theory (DST), and rather than concentrating on how grammar and writing can be taught, we will examine if and how the writing and grammar of two beginning students develops without any specific teaching. We intend to raise one particular issue that presents a link between DST and SLA: variation. Our aim is to stimulate discussion on how variation should be viewed and interpreted, but we want to stress here that DST and its views on variation is not a theory on SLA in itself. It is merely a framework that offers a different perspective on language as a system. The structure of this contribution is as follows. -

Code-Switching Between Structural and Sociolinguistic Perspectives Linguae & Litterae
Code-switching Between Structural and Sociolinguistic Perspectives linguae & litterae Publications of the School of Language & Literature Freiburg Institute for Advanced Studies Edited by Peter Auer, Gesa von Essen and Frick Werner Editorial Board Michel Espagne (Paris), Marino Freschi (Rom), Ekkehard König (Berlin), Michael Lackner (Erlangen-Nürnberg), Per Linell (Linköping), Angelika Linke (Zürich), Christine Maillard (Strasbourg), Lorenza Mondada (Basel), Pieter Muysken (Nijmegen), Wolfgang Raible (Freiburg), Monika Schmitz-Emans (Bochum) Volume 43 Code-switching Between Structural and Sociolinguistic Perspectives Edited by Gerald Stell and Kofi Yakpo DE GRUYTER ISBN 978-3-11-034354-0 e-ISBN (PDF) 978-3-11-034687-9 e-ISBN (EPUB) 978-3-11-038394-2 ISSN 1869-7054 Library of Congress Cataloging-in-Publication Data A CIP catalog record for this book has been applied for at the Library of Congress. Bibliographic information published by the Deutsche Nationalbibliothek The Deutsche Nationalbibliothek lists this publication in the Deutsche Nationalbibliografie; detailed bibliographic data are available on the Internet at http://dnb.dnb.de. © 2015 Walter de Gruyter GmbH, Berlin/Munich/Boston Typesetting: Meta Systems Publishing & Printservices GmbH, Wustermark Printing and binding: Hubert & Co. GmbH & Co. KG, Göttingen ♾ Printed on acid-free paper Printed in Germany www.degruyter.com Contents Acknowledgements VII Gerald Stell, Kofi Yakpo Elusive or self-evident? Looking for common ground in approaches to code-switching 1 Part 1: Code-switching -

The Cambridge Handbook of Linguistic Multi-Competence Edited by Vivian Cook and Li Wei Frontmatter More Information
Cambridge University Press 978-1-107-05921-4 - The Cambridge Handbook of Linguistic Multi-competence Edited by Vivian Cook and Li Wei Frontmatter More information The Cambridge Handbook of Linguistic Multi-competence How are two or more languages learned and contained in the same mind or the same community? This handbook presents an up-to-date view of the concept of multi-competence, exploring the research questions it has generated and the methods that have been used to investigate it. The book brings together psychologists, sociolinguists, Second Language Acquisition (SLA) researchers, and language teachers from across the world to look at how multi-competence relates to their own areas of study. This comprehensive, state-of-the-art exploration of multi-competence research and ideas offers a powerful critique of the values and methods of classical SLA research, and an exciting preview of the future implications of multi-competence for research and thinking about language. It is an essential reference for all those concerned with language learning, language use and language teaching. VIVIAN COOK is Emeritus Professor of Applied Linguistics at Newcastle University and Visiting Professor at the University of York. He previously taught Applied Linguistics at Essex University, and EFL and Linguistics in London. LI WEI is Chair of Applied Linguistics and Director of the UCL Centre for Applied Linguistics, at UCL Institute of Education, University College London. He has previously worked at Birkbeck College, University of London, Newcastle University, and Beijing Normal University. © in this web service Cambridge University Press www.cambridge.org Cambridge University Press 978-1-107-05921-4 - The Cambridge Handbook of Linguistic Multi-competence Edited by Vivian Cook and Li Wei Frontmatter More information cambridge handbooks in language and linguistics Genuinely broad in scope, each handbook in this series provides a complete state-of-the-field overview of a major sub-discipline within language study and research.