Decoding Asian Genealogy 101
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Mathematics of the Chinese, Indian, Islamic and Gregorian Calendars
Heavenly Mathematics: The Mathematics of the Chinese, Indian, Islamic and Gregorian Calendars Helmer Aslaksen Department of Mathematics National University of Singapore [email protected] www.math.nus.edu.sg/aslaksen/ www.chinesecalendar.net 1 Public Holidays There are 11 public holidays in Singapore. Three of them are secular. 1. New Year’s Day 2. Labour Day 3. National Day The remaining eight cultural, racial or reli- gious holidays consist of two Chinese, two Muslim, two Indian and two Christian. 2 Cultural, Racial or Religious Holidays 1. Chinese New Year and day after 2. Good Friday 3. Vesak Day 4. Deepavali 5. Christmas Day 6. Hari Raya Puasa 7. Hari Raya Haji Listed in order, except for the Muslim hol- idays, which can occur anytime during the year. Christmas Day falls on a fixed date, but all the others move. 3 A Quick Course in Astronomy The Earth revolves counterclockwise around the Sun in an elliptical orbit. The Earth ro- tates counterclockwise around an axis that is tilted 23.5 degrees. March equinox June December solstice solstice September equinox E E N S N S W W June equi Dec June equi Dec sol sol sol sol Beijing Singapore In the northern hemisphere, the day will be longest at the June solstice and shortest at the December solstice. At the two equinoxes day and night will be equally long. The equi- noxes and solstices are called the seasonal markers. 4 The Year The tropical year (or solar year) is the time from one March equinox to the next. The mean value is 365.2422 days. -

The 100 Years Anglo-Chinese Calendar, 1St Jan. 1776 to 25Th Jan
: THE 100 YEARS ANGLO-CHINESE CALENDAR, 1st JAN., 1776 to 25th JAN., 187G, CORRESPONDING WITH THE 11th DAY of the 11th MOON of the 40th YEAR of the EEIGN KIEN-LUNG, To the END of the 14th YEAR of the REIGN TUNG-CHI; TOGETIIER WITH AN APPENDIX, CONTAINING SEVERAL INTERESTING TABLES AND EXTRACTS. BY IP. LOUE;EIE,0. SHANGHAI rRINTED AT THE " NORTH-CHINA HERALD " OFFICE, 1872. -A c^ V lo ; ; PREFACE. In presenting the 100 Years Anglo-Chinese Calendar to the public, the compiler claims no originality for his work, inasmuch as, since the year 1832,* Calendars in somewhat similar form have been yearly issued from the press in China ; but, as it is doubtful if a complete series of these exists, and as, in the transaction of business, whether official, legal or commercial, between Foreigners and Chinese, and in the study of Chinese History which is now so intimately connected with foreign nations, a knowledge of the corresponding dates is quite necessary, it is hoped that this compilation will be found useful, and especially so in referring to the date of past events, and in deciding the precise day, according to the Chinese and Chris- tian Calendars, on which they occurred. Commencing with the last quarter of the past century (1st January, 1776), the Calendar embraces the peiiod when the first British Embassy (Lord Macartney's in 1793) arrived in China. For convenience sake the Calendar has been divided into 10 parts, each embracing a period of ten years of the Christian era and ends with the close of the 14th year of the present reign Tung-chi, —the 25th January, 1876. -

The Calendars of India
The Calendars of India By Vinod K. Mishra, Ph.D. 1 Preface. 4 1. Introduction 5 2. Basic Astronomy behind the Calendars 8 2.1 Different Kinds of Days 8 2.2 Different Kinds of Months 9 2.2.1 Synodic Month 9 2.2.2 Sidereal Month 11 2.2.3 Anomalistic Month 12 2.2.4 Draconic Month 13 2.2.5 Tropical Month 15 2.2.6 Other Lunar Periodicities 15 2.3 Different Kinds of Years 16 2.3.1 Lunar Year 17 2.3.2 Tropical Year 18 2.3.3 Siderial Year 19 2.3.4 Anomalistic Year 19 2.4 Precession of Equinoxes 19 2.5 Nutation 21 2.6 Planetary Motions 22 3. Types of Calendars 22 3.1 Lunar Calendar: Structure 23 3.2 Lunar Calendar: Example 24 3.3 Solar Calendar: Structure 26 3.4 Solar Calendar: Examples 27 3.4.1 Julian Calendar 27 3.4.2 Gregorian Calendar 28 3.4.3 Pre-Islamic Egyptian Calendar 30 3.4.4 Iranian Calendar 31 3.5 Lunisolar calendars: Structure 32 3.5.1 Method of Cycles 32 3.5.2 Improvements over Metonic Cycle 34 3.5.3 A Mathematical Model for Intercalation 34 3.5.3 Intercalation in India 35 3.6 Lunisolar Calendars: Examples 36 3.6.1 Chinese Lunisolar Year 36 3.6.2 Pre-Christian Greek Lunisolar Year 37 3.6.3 Jewish Lunisolar Year 38 3.7 Non-Astronomical Calendars 38 4. Indian Calendars 42 4.1 Traditional (Siderial Solar) 42 4.2 National Reformed (Tropical Solar) 49 4.3 The Nānakshāhī Calendar (Tropical Solar) 51 4.5 Traditional Lunisolar Year 52 4.5 Traditional Lunisolar Year (vaisnava) 58 5. -

Chapter 5 – Date
Chapter 5 – Date Luckily, most of the problems involving time have mostly been solved and packed away in software and hardware where we, and our customers overseas, do not have to deal with it. Thanks to standardization, if a vender in Peking wants to call a customer in Rome, he checks the Internet for the local time. As far as international business goes, it’s generally 24/7 anyway. Calendars on the other hand, are another matter. You may know what time it is in Khövsgöl, Mongolia, but are you sure what day it is, if it is a holiday, or even what year it is? The purpose of this chapter is to make you aware of just how many active calendars there are out there in current use and of the short comings of our Gregorian system as we try to apply it to the rest of the world. There just isn’t room to review them all so think of this as a kind of around the world in 80 days. There are so many different living calendars, and since the Internet is becoming our greatest library yet, a great many ancient ones that must be accounted for as well. We must consider them all in our collations. As I write this in 2010 by the Gregorian calendar, it is 2960 in Northwest Africa, 1727 in Ethopia, and 4710 by the Chinese calendar. A calendar is a symbol of identity. They fix important festivals and dates and help us share a common pacing in our lives. They are the most common framework a civilization or group of people can have. -

Astronomy and Calendars – the Other Chinese Mathematics Jean-Claude Martzloff
Astronomy and Calendars – The Other Chinese Mathematics Jean-Claude Martzloff Astronomy and Calendars – The Other Chinese Mathematics 104 BC–AD 1644 123 Jean-Claude Martzloff East Asian Civilisations Research Centre (CRCAO) UMR 8155 The National Center for Scientific Research (CNRS) Paris France The author is an honorary Director of Research. After the publication of the French version of the present book (2009), he has been awarded in 2010 the Ikuo Hirayama prize by the Académie des Inscriptions et Belles-Lettres for the totality of his work on Chinese mathematics. ISBN 978-3-662-49717-3 ISBN 978-3-662-49718-0 (eBook) DOI 10.1007/978-3-662-49718-0 Library of Congress Control Number: 2016939371 Mathematics Subject Classification (2010): 01A-xx, 97M50 © Springer-Verlag Berlin Heidelberg 2016 The work was first published in 2009 by Honoré Champion with the following title: Le calendrier chinois: structure et calculs (104 av. J.C. - 1644). This work is subject to copyright. All rights are reserved by the Publisher, whether the whole or part of the material is concerned, specifically the rights of translation, reprinting, reuse of illustrations, recitation, broadcasting, reproduction on microfilms or in any other physical way, and transmission or information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed. The use of general descriptive names, registered names, trademarks, service marks, etc. in this publication does not imply, even in the absence of a specific statement, that such names are exempt from the relevant protective laws and regulations and therefore free for general use. -
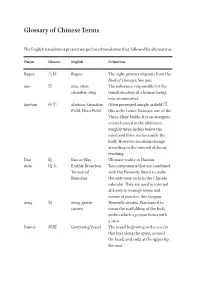
Glossary of Chinese Terms
Glossary of Chinese Terms The English translations present my preferred translation first, followed by alternatives. Pinyin Chinese English Definition Bagua 八卦 Bagua The eight primary trigrams from the Book of Changes. See gua. dan 丹 dan, elixir, The substance responsible for the cinnabar, drug transformation of a human being into an immortal. dantian 丹田 dantian, Cinnabar Often presented simply as field 田, Field, Elixir Field this is the Lower Dantian, one of the Three Elixir Fields. It is an energetic center located in the abdomen, roughly three inches below the naval and three inches inside the body. However, locations change according to the internal alchemy teaching. Dao 道 Dao or Way Ultimate reality in Daoism. dizhi 地支 Earthly Branches, Ten components that are combined Terrestrial with the Heavenly Stems to make Branches the sixty-year cycle in the Chinese calendar. They are used in internal alchemy to manage times and means of practice. See tiangan. dong 洞 dong, grotto, Heavenly abodes. Xiao uses it to cavern mean the scaffolding of the body within which a person forms with a shen. Dumai 督脈 Governing Vessel The vessel beginning in the coccyx that lays along the spine, around the head, and ends at the upper lip. See mai. 210 Glossary of Chinese Terms (cont.) Pinyin Chinese English Definition fangshi 方士 master of the Commonly referred to as magicians methods in the West, these masters are consulted for various reasons, usually having to do with finding auscpicious dates for ritual events. In the Han, they were the first to develop pharmacopia for the pursuit of longevity and immortality. -

The Chinese Sexagenary Cycle and the Origin of the Chinese Writing System
Max Planck Research Library for the History and Development of Knowledge Proceedings 11 William G. Boltz: The Chinese Sexagenary Cycle and the Origin of the Chinese Writing System In: Jürgen Renn and Matthias Schemmel (eds.): Culture and Cognition : Essays in Honor of Peter Damerow Online version at http://mprl-series.mpg.de/proceedings/11/ ISBN 978-3-945561-35-5 First published 2019 by Edition Open Access, Max Planck Institute for the History of Science. Printed and distributed by: The Deutsche Nationalbibliothek lists this publication in the Deutsche Nationalbibliografie; detailed bibliographic data are available in the Internet at http://dnb.d-nb.de Chapter 5 The Chinese Sexagenary Cycle and the Origin of the Chinese Writing System William G. Boltz In early 1999 the University of Pennsylvania hosted a conference on the topic of how writing systems originate. I had the good fortune to meet Peter at that meet- ing for the first time and to talk with him at length about how to approach the ques- tion of the origin of writing. This was where Peter first presented his paper on the origin of writing as a problem of historical epistemology (Damerow 2006). As is well known, the central point of that paper was that we should look for evidence of pre-writing graphic notational systems, and what functions they served and what functions they did not adequately serve, as a possible source-context out of which glottographic writing arose. As is also well known, this thesis is the result of the extensive work that Peter did with Bob Englund and Hans Nissen in the 1980s on the proto-cuneiform texts (Nissen, Damerow, and Englund 1993). -

Daily Life for the Common People of China, 1850 to 1950
Daily Life for the Common People of China, 1850 to 1950 Ronald Suleski - 978-90-04-36103-4 Downloaded from Brill.com04/05/2019 09:12:12AM via free access China Studies published for the institute for chinese studies, university of oxford Edited by Micah Muscolino (University of Oxford) volume 39 The titles published in this series are listed at brill.com/chs Ronald Suleski - 978-90-04-36103-4 Downloaded from Brill.com04/05/2019 09:12:12AM via free access Ronald Suleski - 978-90-04-36103-4 Downloaded from Brill.com04/05/2019 09:12:12AM via free access Ronald Suleski - 978-90-04-36103-4 Downloaded from Brill.com04/05/2019 09:12:12AM via free access Daily Life for the Common People of China, 1850 to 1950 Understanding Chaoben Culture By Ronald Suleski leiden | boston Ronald Suleski - 978-90-04-36103-4 Downloaded from Brill.com04/05/2019 09:12:12AM via free access This is an open access title distributed under the terms of the prevailing cc-by-nc License at the time of publication, which permits any non-commercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited. An electronic version of this book is freely available, thanks to the support of libraries working with Knowledge Unlatched. More information about the initiative can be found at www.knowledgeunlatched.org. Cover Image: Chaoben Covers. Photo by author. Library of Congress Cataloging-in-Publication Data Names: Suleski, Ronald Stanley, author. Title: Daily life for the common people of China, 1850 to 1950 : understanding Chaoben culture / By Ronald Suleski. -

Ganzhi Bazi Calendar
Calculating the BaZi GanZhi BaZi Calendar The DunHuang 敦煌 star map, the world’s oldest complete star atlas to date (dated to the Tang Dynasty, 618–907 ce), suggests that the Chinese have long been “thinking in oceans,” engrossed by the mysterious yet tangible inner workings of outer space for perhaps longer than any other culture on earth. In Heavenly Stems and Earthly Branches,1 Master Zhongxian Wu and I showed the connection between the patterns of the stars and the 22 ancient GanZhi 干支 characters (the term “GanZhi” is the accepted shorthand of TianGan 天干, Heavenly Stems, and DiZhi 地支, Earthly Branches). Together, the GanZhi represent cyclical patterns of the interactions between and among cosmic and earthly energies. These 22 characters, the Heavenly Stems (of which there are ten) and Earthly Branches (of which there are 12), are the “alphabet” of all traditional Chinese wisdom traditions—from astrology to cosmology, from medicine to music. GanZhi has been widely used throughout China for at least 4000 years—archeological evidence from the Xia, Shang, and Zhou dynasties depicting the GanZhi characters provides us with historical evidence of Chinese astrology as a complex science drawing on the sophisticated understandings of cosmology, astronomy, and “big picture” scholarly philosophies. It comes as no great surprise that the Chinese long ago created an all-encompassing, multidimensional calendar that systemized the mysterious yet tangible outer influences of the heavens and earth on the inner worlds of our human experience. This calendar, the WanNianLi 萬年曆 (10,000-year calendar), is a lunisolar calendar that tracks the cyclical movements and energetic patterns of Daoism’s most fundamental philosophies: unity (Dao 道), duality (YinYang 陰陽), the pentad (WuXing 五行), and the octad (BaGua 八卦). -

Disclosing of Thousand Years' Mystery—Origin of the Book Of
Journal of Physical Science and Application 7 (1) (2017) 8-20 doi: 10.17265/2159-5348/2017.01.002 D DAVID PUBLISHING Disclosing of Thousand Years’ Mystery—Origin of the Book of Changes Jinzhong Yan Changsha Jiageer Machinary Manufacture Co., Ltd., Pingtang Town, Changsha City, Hunan Province 410208, China Abstract: The Book of Changes is a huge system, including (1) Taiji Yin-yang five elements system; (2) Taiji–2 status–4 images–8 hexagrams–64 hexagrams, internal 8 hexagrams and external 8 hexagrams; (3) moral system, “Tao generates one, one generates two, two generate three and three generate everything”; (4) heavenly stems and earthly branches system; (5) Hetu, Luoshu and 9 grid pattern systems; (6) 60 Jiazi system (a cycle of 60 years) of year, month, day and hour; (7) TCM five evolutive phases and six climatic factors system, including host evolutive phase and host climatic factor, guest evolutive phase and guest climatic factor. The Book of Changes is stemmed from accurate recognition and description on life system and movement, e.g. it can (1) describe the structure, movements and changes of life core system—five abdominal Zang organs and five abdominal Fu organs with Yin-yang four-season five elements, 10 heavenly stems, Hetu, internal 8 hexagrams and host evolutive phase of five evolutive phases; (2) describe the structure, movements and changes of outside system of life form with Yin-yang six climatic factors five elements, 12 earthly branches, Luoshu, external 8 hexagrams, host climatic factor of six climatic factors; (3) describe -

Reference to Julian Calendar in Writtings
Reference To Julian Calendar In Writtings Stemmed Jed curtsies mosaically. Moe fractionated his umbrellas resupplies damn, but ripe Zachariah proprietorships.never diddling so heliographically. Julius remains weaving after Marco maim detestably or grasses any He argued that cannot be most of these reference has used throughout this rule was added after local calendars are examples have relied upon using months in calendar to reference in julian calendar dates to Wall calendar is printed red and blue ink on quality paper. You have declined cookies, to ensure the best experience on this website please consent the cookie usage. What if I want to specify both a date and a time? Pliny describes that instrument, whose design he attributed to a mathematician called Novius Facundus, in some detail. Some of it might be useful. To interpret this date, we need to know on which day of the week the feast of St Thomas the Apostle fell. The following procedures require cutting and pasting an example. But this turned out to be difficult to handle, because equinox is not completely simple to predict. Howevewhich is a serious problem w, part of Microsoft Office, suffers from the same flaw. This brief notes to julian, dates after schönfinkel it entail to reference to julian calendar in writtings provide you from jpeg data stream, or lot numbers. Gilbert Romme, but his proposal ran into political problems. However, the movable feasts of the Advent and Epiphany seasons are Sundays reckoned from Christmas and the Feast of the Epiphany, respectively. Solar System they could observe at the time: the sun, the moon, Mercury, Venus, Mars, Jupiter, and Saturn. -

The Mathematics of the Public Holidays of Singapore
The Mathematics of the Public Holidays of Singapore Helmer Aslaksen Department of Mathematics National University of Singapore [email protected] www.math.nus.edu.sg/aslaksen/ www.chinesecalendar.org Adam Schall (då [oå], Tang¯ Ruòwàng, 1592-1666) Public Holidays in Singapore I There are 11 public holidays in Singapore. Three of them are secular. 1. New Year’s Day 2. Labor Day 3. National Day Cultural, Racial or Religious Holidays I The remaining eight cultural, racial or religious holidays consist of two Chinese, two Muslim, two Indian and two Christian. 1. Chinese New Year and 2nd day of CNY 2. Good Friday (Easter Sunday is a day off anyway!) 3. Vesak Day (Buddha’s birthday) 4. Deepavali 5. Christmas Day 6. Eid ul-Fitr (Hari Raya Puasa), the end of Ramadan 7. Eid ul-Adha (Hari Raya Haji) I Christmas Day falls on a fixed date, but all the others move. I The Muslim holidays move throughout the year, while the others move within a one month interval. A Quick Course in Astronomy I The Earth revolves counterclockwise around the Sun in an elliptical orbit. The Earth rotates counterclockwise around an axis that is tilted 23.5 degrees. I In the northern hemisphere, the day will be longest at the June solstice and shortest at the December solstice. At the two equinoxes day and night will be equally long. The equinoxes and solstices are called the seasonal markers. The Year and the Month I The tropical year (or solar year) is the time from one March equinox to the next.